直播混沌工程之故障演練實踐總結
01 混沌工程
1.1 背景
近年來,隨著系統架構逐漸向微服務架構演進,開發效率以及系統擴充套件性大幅提高,服務之間的依賴所帶來的不確定性也成指數級增長,在這樣的服務呼叫網中,任何一環出現的正常或者異常的變化,都有可能對其他服務造成類似蝴蝶效應一般的影響。傳統的測試方法已經不能全面理解和覆蓋系統所有可能的行為,測試的有效性被大打折扣,為此Netflix從混亂猴子開始,從主動出擊的思維方式衍生出混沌工程,讓系統在每一次失敗中獲益,然後不斷進化,促使開發者在開發軟體時必須選擇將防禦性內建在系統中。
1.2 實踐原理

設定穩態假設:向系統注入的事情不會導致系統穩定狀態發生明顯的變化,以直播進房場景來說,當每個時間點的每秒成功進去直播間的次數大於一個閾值時,該服務處於穩定狀態。
控制爆炸半徑:將線上實驗影響控制在最小範圍,並且能夠根據穩態的變化實時自動停止實驗,即最小化爆炸半徑。
自動化持續執行:透過每天自動執行這樣的實驗,確保任何後續對系統的變更都不會引入新的系統行為盲點。
故障事件

網際網路微服務中,自頂向下故障發生的機率越來越小,但是故障影響面是越來越大,具體我們在生產環境選擇重放什麼型別的事件時,需要結合業務的具體實現,通常考慮的事件有以下幾類:
異地多活,某個機房不可用,備用機房是否可以承載業務流量
資源耗盡:比如DB連線數打滿、訊息佇列積壓、快取熱點
硬體故障,比如某個k8s prod突然down掉
網路延遲
下游依賴故障
歷史故障等等
1.3 價值所在
混沌工程的業務價值並不適合用過程指標(比如模擬了多少種實驗場景、發起了都少次例項)來衡量。比如前期可以選擇對歷史故障進行復現,確保故障改進的有效性;中期可以選擇監控發現率,驗證故障發現能力和監控的完備程度;後期可以考慮引入一些複雜的MTTR(Mean time to repair)度量指標,從故障“發現-定位-恢復時長“這種綜合性指標,最終的目標還是希望透過混沌工程來提供系統彈性。
1.4 混沌工程和故障演練的區別
混沌工程的思維方式是主動去找故障,是探索性的,不知道摘掉一個節點、關閉一個服務會發生故障,雖然按計劃做好了降級預案,但是關閉節點時引發了上游服務異常,進而引發雪崩,這不是靠故障注入能發現的。而故障演練首先是知道會發生故障,然後一個個的注入,然而在複雜分散式系統中,想要窮舉所有可能得故障,本身就是一種奢望。故障演練更像平時做的測試,在測試中需要進行斷言:給定一個特定的條件,系統會輸出一個特定的結果,驗證這個結果是真還是假,從而判定測試是否透過,這個並不能讓我們發掘出系統未知的或尚不明確的認知。
02 故障注入系統設計
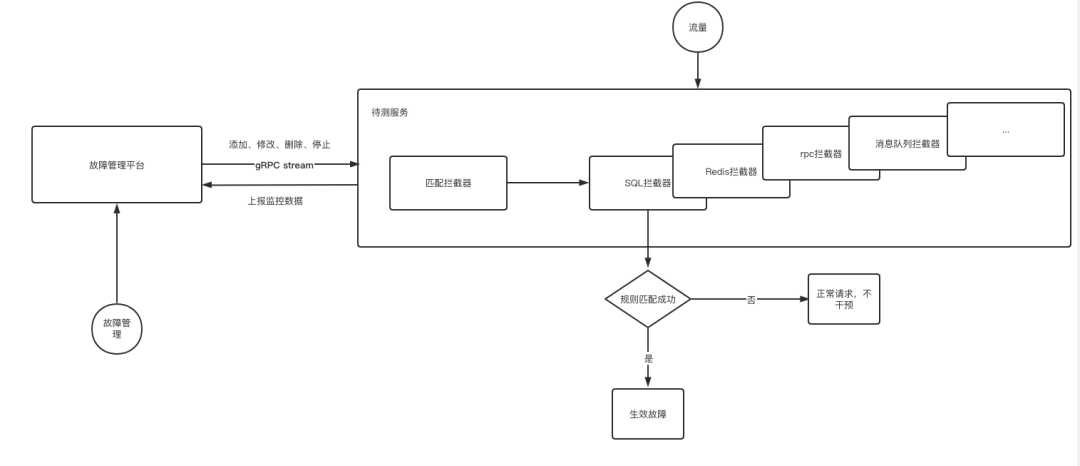
故障注入測試FIT(Failure Injection Testing)在業務正常處理之前,透過切面在系統層面加了一層攔截器,請求在正常處理之前,都將先嚐試匹配攔截器,對不匹配的業務是無感知的,系統設計的時候主要考慮如下三個方面:
輕量:輕量級接入,極低的接入成本
高效能:線上上演練時不增加記憶體佔用和延遲
低耦合:SDK與控制面低耦合,SDK負責底層能力,控制面負責高層應用場景
P.S.
S12技術保障內幕揭秘-如何實現“喝茶保障”2.5.3章節混沌工程也有關於FIT架構的描述,感興趣可透過連結前往。
2.1 實現細節
待測服務啟動時初始化故障演練SDK,只需要改動一行程式碼就可以接入:
# main.gofunc main() { flag.Parse() log.Init(nil) defer log.Close() fault.Init(nil) // 此行:初始化故障演練模組 //... other logic}
初始化後,故障演練SDK將會劫持所有業務元件的處理過程,根據平臺配置的匹配規則進行故障注入。
為了使平臺操作更快的下發給客戶端節點,元件選擇了採用雙向gRPC streaming的方案,客戶端實時的將演練資訊上報給服務端,服務端也將配置透過gRPC通道實時下發。
在與服務端的通訊協議上:我們定義了標準化的故障宣告,將一次故障注入分成目標、匹配條件、行為、引數幾種基本屬性,以滿足不同故障、不同場景下的需求,受益於統一協議,與控制面約定好支援的行為後,不同元件可以並行開發迭代。同時客戶端使用的SDK版本作為元資訊上報給服務端,服務端會針對不同的客戶端版本做好故障注入前的檢查工作。
message Fault { // 目標: redis/mc/mysql/bm/warden TARGET target = 1; // 匹配型別: 某個埠 某個sql型別等 map<string, string> matchers = 2; // 行為名稱 如: ecode timeout string action = 3; //引數 具體錯誤碼和超時等配置 map<string, string> action_args = 4;}
2.1.1 故障匹配流程
使用者流量進入後,首先在入口側被故障注入模組攔截,根據當前使用者、介面的資訊進行故障匹配,判斷當前是否有需要進行注入的故障,如匹配到,則將故障資訊注入到請求上下文中去,在業務邏輯執行到各個子元件後,使用上下文資訊對元件行為做更細粒度的操控。
P.S.
目前已實現的攔截器有:
gRPC客戶端和服務端
HTTP客戶端和服務端
Redis和Memcached
非同步框架Fanout
訊息佇列
MySQL、ES、Taishan(KV)
2.1.2 資料上報
在請求處理結束,業務側介面會實時返回,而此次故障注入的細節會進入資料上報模組,在模組內部的執行緒池中,綜合請求資訊和各個子元件的資訊會形成一個詳細的注入行為資料,這份資料會在記憶體暫存一會,用於合併同類項以及等待旁路的執行緒處理結束,隨後會將演練資料壓縮上報給服務端,用以在平臺實時展示故障影響範圍和相關細節。
2.2 故障配置演示
配置故障

控制爆炸半徑
03 S12賽事故障演練實踐
從今年8月份開始S12賽事的質量保障工作時,故障演練是作為一個大的主題來展開的,在前期方案制定上,我們從uat染色環境小範圍的驗收故障演練工具是否能有效的控制最小化爆炸半徑,再到線上環境進行常規故障注入測試,再擴充套件為線上紅藍演練,評估開發者是否能夠在規定的時候內發現故障並且定位故障,以及恢復時長來評估整個演練的結果。
業務場景選擇
針對此次S12賽制,設定了多個場景的保障預案,因故障演練需要佔用研發和測試人員的大量時間,所以從最核心幾個業務場景出發,優先演練業務優先高並且人力有保障的場景,最終確定的場景如下:
直播首頁
直播進房
直播彈幕
直播營收
故障注入實驗設計
確定了場景後,接下來就要梳理各場景的業務邏輯,然後根據業務場景,梳理出故障場景(核心場景應至少覆蓋L0/L1介面),以下列舉了部分故障場景:

P.S.
報警配置一般都是一段時間內的錯誤閾值是不是已經到了預期,在測試的時候如果依賴人工一次次請求,效率會大受影響,所以一般都會結合壓力工具設定一個合理的QPS範圍;
整個故障演練遵循從小範圍uat環境測試,然後在生產環境執行並且控制好爆炸半徑,越接近生產環境,對實驗外部有效性的威脅就越少,對實驗結果的信心就越足。
線上問題彙總
送禮服務快取超時,查快取不回源時,禮物皮膚不展示
送禮下游建立訂單order服務不可用【強依賴】,金瓜子、銀瓜子、包裹送禮都正常,預期金瓜子送禮失敗
android ios web三端不一致:獲取使用者錢包餘額資訊服務不可用時,送禮成功,但是客戶端不展示電池、銀瓜子數;Web端正常展示
ios粉版進房後,顯示報錯資訊,高能榜tab點選會顯示介面500
進房服務獲取初始化資料失敗
android進房場景未載入背景圖
直播首頁服務出現故障,直播首頁不展示我的關注模組
送禮下游服務不可用,web端不展示大航海專屬的預設圖,Android不展示icon
...
P.S.
發現的每一個問題,會有負責的同學來評估是否修改,修改的排期是哪個版本,如果不修改的話,原因是因為什麼。整個演練結束後,總發現問題22例,影響面大的問題一共有3例:分別是熱門房間快取無法構建、送禮服務快取超時,查快取不回源時,禮物皮膚不展示、進房場景下,ios和android雙端不一致,嚴重問題佔比14%,剩下的問題在正常的專案迭代中進行修復和驗證。
紅藍演練
紅藍演練按照上面介紹的混沌工程的MTTR(Mean time to repair)的思想來實踐的,從故障“發現-定位-恢復時長“來衡量整個系統的彈性。前期透過故障演練已經在生產環境進行了小範圍測試,整個測試階段從場景設計到預期結果研發都參與了,但是我們知道線上的故障都是不可預期的,我們進行故障演練無法覆蓋方方面面,那如果在s12賽事期間,線上有使用者反饋或者告警後,研發人員怎麼能快速的止損了,使故障帶來的影響降到最低,所以我們考慮透過紅藍演練的模式,線上隨機的觸發故障(故障評估無大的級聯風險,範圍可控),在定義的評估時間範圍內看研發同學是否能準確的定位以及恢復故障。經過平時的演練,真的有故障發生的時候,不會手忙腳亂,處理的毫無章法。
紅藍規則定義:
紅方:攻守方,由業務同學擔任
藍方:攻擊方,由測試同擔任,在預定時間內,隨機從故障池注入故障
判定標準:藍方注入故障後若紅方1分鐘內收到準確無誤的告警並且5分鐘內定位到故障原因,10分鐘內解決故障,則紅方勝,反之藍方勝出
演練位置:紅藍雙方選擇一個會議室來進行,防止線上出了意外情況時,藍方可以第一時間停止故障
演練內容:研發同學不知道會有什麼故障,演練內容對研發是保密的,能這樣做的前提是在故障演練階段我們已經積累了足夠的信心,由藍方從故障池隨機選擇故障
下圖顯示了在紅藍過程中,實時記錄的資料,只擷取了其中部分資料,演練結束後,結果是紅方勝利,符合設定的判定標準。

3.1 後續計劃
自動分析應用強弱依賴
在微服務的場景下,一次請求可能涉及到幾十個不同的後端服務,十多種元件依賴,靠人工梳理費時費力不說,辛苦梳理的資料也常隨著業務程式碼的迭代而過期,為此我們正在實現一套更加完善的的依賴分析、自動故障注入功能,首先會用在分析業務應用的強弱依賴。
在規範的業務介面請求處理的場景下,強弱依賴的定義是比較明確的,強依賴會導致介面報錯和返回特定資料,弱依賴會忽略或者使用一些降級資料,不會對介面本身造成影響,根據這個特徵,我們就可以實現強弱依賴的自動識別,相對的如果業務邏輯不是那麼規範也可以加以人工輔助確認的環節。
流程:

在故障注入上按一次請求的粒度進行,以至多幾次請求報錯為代價,實現線上環境的真實依賴驗證。
故障演練自動化測試
故障演練完成一次,需要耗費很多時間去梳理業務邏輯,涉及測試方案,以及到最後的執行,如果能將整個過程隨時隨地的執行,那將節省大量的時間。例如強弱依賴的場景最合適做自動化,因為結果都是可預期的,強依賴的服務有故障,但最終表象肯定是某個介面會返回錯誤或者兜底資料,並且測試結果後可以自動停止故障,就跟業務測試的自動化一樣的。
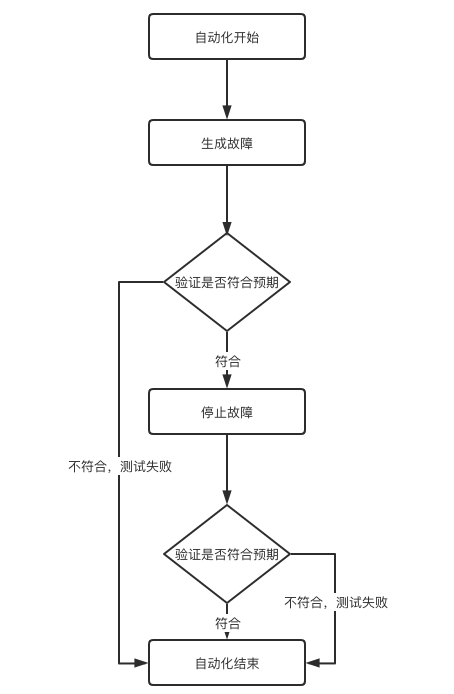
故障注入作為常規測試
故障演練絕非是每次大型活動前的質量保障專利,更應該作為一種常規的測試手段應用於平時的業務測試中。根據的時序圖所示,客戶端的請求到達服務A,服務A是我們的待測服務,服務A弱依賴服務B,所以即使服務B返回報錯或者超時,都不影響服務A繼續請求服務C,並能正常返回正確的資料。如果沒有故障注入工具,要測試強弱依賴,我們是怎麼樣做的呢?

業務虛擬碼如下:
func (s *serviceA)Process(ctx context.Context,userID int64,roomID int64) (rsp *RoomRsp,err error) {rsp=&RoomRsp{}//服務B 弱依賴if num,err:=rpc_B.Process(ctx, roomID);err!=nil{log.Errorf(ctx,"err:%+v",err)return nil,err}//服務Cif num,err:=rpc_C.Process(ctx, roomID);err!=nil{log.Errorf(ctx,"err:%+v",err)return nil,err}/* 其他業務邏輯*/ return rsp,nil}
按照上述說的,服務B是一個弱依賴的錯誤,程式碼不應該直接給上游返回報錯資訊。要測試這種場景,你可以直接關閉服務B,讓網路不可達,但是在實際測試工作中,有可能多個業務都在使用服務B,所以簡單粗暴的關閉服務B,會影響其他人員的使用,那有了故障注入工具,我們可以直接在平臺上注入rpc超時故障,並且控制爆炸半徑隻影響這一個使用者就可以了。
04 總結
分散式系統天生包含大量的互動、依賴點,可能出錯的地方數不勝數。硬碟故障,網路不同,流量激增壓垮某些元件...,可以不停的列舉下去。這都是每天要面臨的常事,任何一次處理不好就有可能導致業務停滯、效能低下,所以儘可能多的識別出導致這些異常的、系統脆弱、易出故障的環節,就可以針對性的對系統進行加固、防範,不斷打造更具彈性的系統,從而避免故障發生時所帶來點的嚴重後果。
來自 “ 嗶哩嗶哩技術 ”, 原文作者:董小兵&王旭;原文連結:http://server.it168.com/a2022/1123/6776/000006776635.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 混沌演練實踐(一)
- 實時數倉混沌演練實踐
- 雲原生背景下故障演練體系建設的思考與實踐—雲原生混沌工程系列之指南篇
- B站故障演練平臺實踐
- 混沌工程最佳實踐 - 尋交流
- 聲網的混沌工程實踐
- React Hooks工程實踐總結ReactHook
- Netflix 混沌工程手冊 Part 3:實踐方法
- MinIO線上故障演練
- 混沌工程在創業公司的實踐 - 陸蓉蓉創業
- 混沌實踐訪談:混沌工程和系統可觀測性密不可分
- redis的sentinel模式故障演練Redis模式
- Spring Cloud 應用在 Kubernetes 上的最佳實踐 — 高可用(混沌工程)SpringCloud
- 在 Ali Kubernetes 系統中,我們這樣實踐混沌工程
- ChaosBlade混沌測試實踐
- FT-FMEA融合混沌演練,零售運營系統韌性架構線上驗證實踐架構
- Now直播iOS Flutter混合工程實踐iOSFlutter
- springcloud之hystrix原理和實踐總結SpringGCCloud
- 虎牙直播在微服務改造方面的實踐和總結微服務
- Kotlin 初嘗之專案實踐總結Kotlin
- 滴滴 NewSQL 演進之 Fusion 實踐SQL
- Linux實踐總結Linux
- 如何讓混沌工程實驗降本增效
- 當Prometheus遇到混沌工程Prometheus
- 混沌工程入門指南
- Apache Kafka的4個混沌工程實驗 | IDCFApacheKafka
- Gin實戰演練
- 前端自動化混沌測試實踐前端
- RESTful API實踐總結RESTAPI
- 2019年終總結之SAP專案實踐篇
- 2018年終總結之SAP專案實踐篇
- 披荊斬棘:論百萬級伺服器反入侵場景的混沌工程實踐伺服器
- 美團機器學習實踐第二章-特徵工程總結機器學習特徵工程
- 飛豬Flutter技術演進及業務改造的實踐與思考總結Flutter
- Bumblebee之負載、限流和故障處理實踐負載
- kubernetes實踐之五十三:Service中的故障排查
- 小程式初實踐總結
- Known框架實戰演練——進銷存資料結構框架資料結構