JVM調優
什麼時候JVM調優
要對Java應用程式進行調優,最佳化JVM並不是第一選擇。我們首先應該考慮軟體架構和程式碼最佳化等方面,這方面的最佳化可能會取得更大的進步空間。因此假設我們已經對於軟體架構、程式碼最佳化、資料庫最佳化等等做過了一些努力,接著我們希望透過JVM調優來做一些事情,那麼我們可以接著往下讀。
效能最佳化的一些方式:
JVM調優指標
我們對JVM調優有哪些指標呢?一般來說有下面三點:
- 吞吐量(Throughput):is the percentage of time the VM spends executing the application versus time spent performing garbage collection.
- 延時(Latency):is the amount of time required to run a garbage collection event.
- 資源佔用(Footprint):is the amount of memory required by the garbage collector to run smoothly.
如果能增加資源投入,提高CPU、記憶體等,自然可以提高吞吐量和減少延時。
對於吞吐量和延時,我們一般透過調節垃圾收集引數來做權衡。而對於吞吐量和延時的不同的統計方式,可能會得到不同的結果。
對於垃圾收集對應用程式請求的影響的計算方法,可以參考美團文章。透過統計一分鐘內請求受影響的佔比,來判斷GC影響時間是否減少。
我們還可以開啟GC日誌,來看每次垃圾收集的時間、頻率,來判斷GC總時間是否減少。
當我們進行各種壓力測試,基準測試後,拿到這個測試資料,才能判斷是否達到了我們預設的指標。
獲取JVM監控資料
開啟GC log
-XX:+PrintGC
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-Xloggc:<filename>
- -Xloggc specifies where the file is located
- -XX:+PrintGCDetails – includes additional details in the garbage collector log
- -XX:+PrintGCTimeStamps – prints the timestamps to the log
0.134: [GC (Allocation Failure) [PSYoungGen: 65536K->10720K(76288K)] 65536K->40488K(251392K), 0.0190287 secs] [Times: user=0.13 sys=0.04, real=0.02 secs]
0.193: [GC (Allocation Failure) [PSYoungGen: 71912K->10752K(141824K)] 101680K->101012K(316928K), 0.0357512 secs] [Times: user=0.27 sys=0.06, real=0.04 secs]
0.374: [GC (Allocation Failure) [PSYoungGen: 141824K->10752K(141824K)] 232084K->224396K(359424K), 0.0809666 secs] [Times: user=0.58 sys=0.12, real=0.08 secs]
0.455: [Full GC (Ergonomics) [PSYoungGen: 10752K->0K(141824K)] [ParOldGen: 213644K->215361K(459264K)] 224396K->215361K(601088K), [Metaspace: 2649K->2649K(1056768K)], 0.4409247 secs] [Times: user=3.46 sys=0.02, real=0.44 secs]
0.984: [GC (Allocation Failure) [PSYoungGen: 131072K->10752K(190464K)] 346433K->321225K(649728K), 0.1407158 secs] [Times: user=1.28 sys=0.08, real=0.14 secs]
1.168: [GC (System.gc()) [PSYoungGen: 60423K->10752K(190464K)] 370896K->368961K(649728K), 0.0676498 secs] [Times: user=0.53 sys=0.05, real=0.06 secs]
1.235: [Full GC (System.gc()) [PSYoungGen: 10752K->0K(190464K)] [ParOldGen: 358209K->368152K(459264K)] 368961K->368152K(649728K), [Metaspace: 2652K->2652K(1056768K)], 1.1751101 secs] [Times: user=10.64 sys=0.05, real=1.18 secs]
2.612: [Full GC (Ergonomics) [PSYoungGen: 179712K->0K(190464K)] [ParOldGen: 368152K->166769K(477184K)] 547864K->166769K(667648K), [Metaspace: 2659K->2659K(1056768K)], 0.2662589 secs] [Times: user=2.14 sys=0.00, real=0.27 secs]
開啟GClog可得到如上日誌,不同的垃圾收集器可能形式略有差異,但都大致相同。上面寫了由於記憶體分配失敗而導致full GC。顯示了新生代,老年代,堆記憶體,元空間垃圾收集前和後的空間大小的變化。垃圾收集時間,使用者態時間、核心態時間、真正用時等。
關於gclog 檔案的分析,可以參考https://sematext.com/blog/java-garbage-collection-logs/#parallel-and-concurrent-mark-sweep-garbage-collectors。至於好用的免費視覺化工具沒有發現,如果有人知道可評論區指出。
jmap
此命令可以獲得當前堆快照,我使用JProfiler來檢視堆資訊。官方操作檔案
先使用 jps -v檢視Java程式程式id,然後使用jmap -dump:live,format=b,file=<filename> <PID>,filename可以起名為xxx.hprof
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./heapDump.hprof 此兩個引數當OOM發生後,會生成堆快照來幫助排查問題。
檔案如下:
JProfiler
至於JProfiler的安裝部署不贅述,只列幾張圖片看看大致監控的內容。
jstat
jstat可實時檢視堆狀態。
先jps -v得到Java程式程式號,再jstat -gcutil <pid> <time interval>(Example: jstat -gcutil 29218 3000 每隔三秒列印一次Java程式號為29218的gc資訊)。
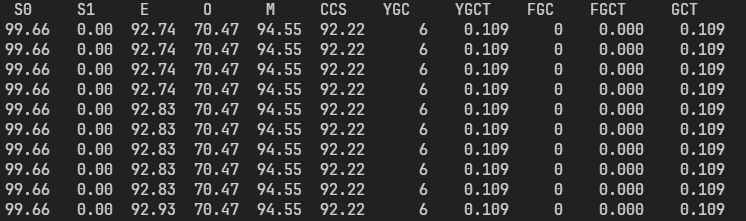
S0,S1:倖存者區
E:Eden區
O:Old 區
M:Metaspace
CCS:被編譯的類所佔元空間大小
YGC:Young GC 次數
YGCT:Young GC總時間
FGC,FGCT:Full GC次數,總時間
GCT:GC總時間
關於jstat -gc 和 jstat -gcutil 區別,主要是第一個顯示實際大小,比如多少k。第二個顯示百分比
Arthas
使用Arthas也可以監控cpu,記憶體,gc等情況,具體可參考官方檔案。也可參考我的這篇文章關於使用Arthas排查問題
無論使用什麼方式獲得JVM執行資訊,最終我們要得到幾組資料,用資料證明我們的調優確實有作用。
關於垃圾收集器
如果是JDK8,那麼會有人說CMS是延時低的,Parallel GC等是吞吐量高的。但實際上還要經過測試才能確定。
對於JDK大於8的,比如JDK17等,可以看看G1、ZGC等收集器,測試其是否合適。
GC progress from JDK 8 to JDK 17
JVM OPTs 樣例
-Duser.timezone=Asia/Shanghai
-Xms6G -Xmx6G
-XX:NewSize=3G -XX:MaxNewSize=3G
-XX:SurvivorRatio=10
-XX:MetaspaceSize=2G -XX:MaxMetaspaceSize=2G
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./heapDump.hprof
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log
Xms Xmx設定堆大小,兩者一樣可以避免擴容而導致一定延時
SurvivorRatio影響倖存者進入老年代的年齡閾值
MetaspaceSize設定一樣可以防止擴容而導致延時
HeapDumpOnOutOfMemoryError OOM後輸出堆快照
PrintGCDetails .... 列印GClog
JVM調優案例
例子大部分來自於《深入理解Java虛擬機器》,不說具體例子,只說造成結果
大物件直接進入老年代
導致老年代很快記憶體不夠,導致頻繁full GC,從而更多的延時
記憶體溢位
大量資料快取到Java的堆中得不到釋放,導致OOM。只要我們開啟HeapDumpOnOutOfMemoryError 檢視堆資訊,基本上就能知道快取了大量的什麼Java物件。
Direct Memory
我們一看到直接記憶體就能想到NIO,可以嘗試擴大Direct Memory
外部命令導致資源佔用
Java程式大量呼叫外部shell指令碼
socket 連線耗盡
傳送的http請求,而響應卻很慢才返回,導致socket耗盡
記憶體佔用過大
資料結構問題,比如我們想檢視某個人的一年的出勤率,我們可以看他未出勤的資料。比如我們就是要看一個人365天每一天的是否出勤,那麼可以用map存365個key、value,但使用一個365長度的01字串更節省空間。
safepoint
文中說JVM對for迴圈有safepoint,對於for int 的是整個執行完才過safepoint,對於for long的是每一個迴圈就有safepoint。由於一個for int 執行時間過長導致 STW 過長。
詳細可看:HBase實戰:記一次Safepoint導致長時間STW的踩坑之旅
總結
對於JVM調優,我們首先需要知道有什麼樣的問題,我們調優的目標是什麼。一般有三個指標,吞吐量,延時,資源(footprint)。明確我們需要提高哪項指標後,才可進行相應的手段進行最佳化。
並且還有一個前提條件,那就是對於系統架構和程式碼層面的最佳化也做過了,對於資料庫相關的最佳化也做過了,那麼我們可以嘗試調優JVM來最佳化相關指標。以為我們不能指望透過調優JVM來大幅提升效能。
僅僅從JVM角度說,如果我們要提高吞吐量,我們可以提高物理機效能,比如多開記憶體。或者換一個更注重吞吐量的垃圾收集器。當然也可以調節JVM引數來減少垃圾回收次數。
比如我們要減少延時,還是多開記憶體。或者換一個更注重降低延時的收集器。當然也是可以調節JVM引數減少垃圾回收次數等等。
如果我們要減少資源,如果可以忍受降低程式效能的話。那麼我們能做的可能就是調節新生代,老年代比例等,比如我們的應用是朝生夕滅多(調大新生代),還是永久的物件更多(調大老年代)。
Reference
[深入理解Java虛擬機器:JVM高階特性與最佳實踐(第3版)周志明.pdf]
[Guide to the Most Important JVM Parameters]: https://www.baeldung.com/jvm-parameters
[JVM Tuning: How to Prepare Your Environment for Performance Tuning]: https://sematext.com/blog/jvm-performance-tuning/
[從實際案例聊聊Java應用的GC最佳化]: https://tech.meituan.com/2017/12/29/jvm-optimize.html
[How to Properly Plan JVM Performance Tuning]: https://www.alibabacloud.com/blog/how-to-properly-plan-jvm-performance-tuning_594663
[Solving java.lang.OutOfMemoryError: Metaspace error]: https://www.mastertheboss.com/java/solving-java-lang-outofmemoryerror-metaspace-error/
[GC progress from JDK 8 to JDK 17]: https://kstefanj.github.io/2021/11/24/gc-progress-8-17.html
[HBase實戰:記一次Safepoint導致長時間STW的踩坑之旅]: https://juejin.cn/post/6844903878765314061