咳咳,看了鹹魚這篇《萬萬沒想到——flutter這樣外接紋理》的文章,我們瞭解到flutter提供一種機制,可以將native的紋理共享給flutter來進行渲染。但是,由於flutter獲取native紋理的資料型別是CVPixelBuffer,導致native紋理需要經過GPU->CPU->GPU的轉換過程消耗額外效能,這對於需要實時渲染的音視訊類需求,是不可接受的。
閒魚這邊的解決方案是修改了flutter engine的程式碼,將flutter的gl環境和native的gl環境通過ShareGroup來聯通,避免2個環境的紋理傳遞還要去cpu記憶體繞一圈。此方案能夠解決記憶體拷貝的效能問題,但暴露flutter的gl環境,畢竟是一個存在風險的操作,給以後的flutter渲染問題定位也增加了複雜度。所以,有沒有一個完美、簡便的方案呢?答案就是利用CVPixelBuffer的共享記憶體機制。
flutter外接紋理的原理
先回顧下前置知識,看看官方提供的外接紋理機制究竟是怎樣執行的。
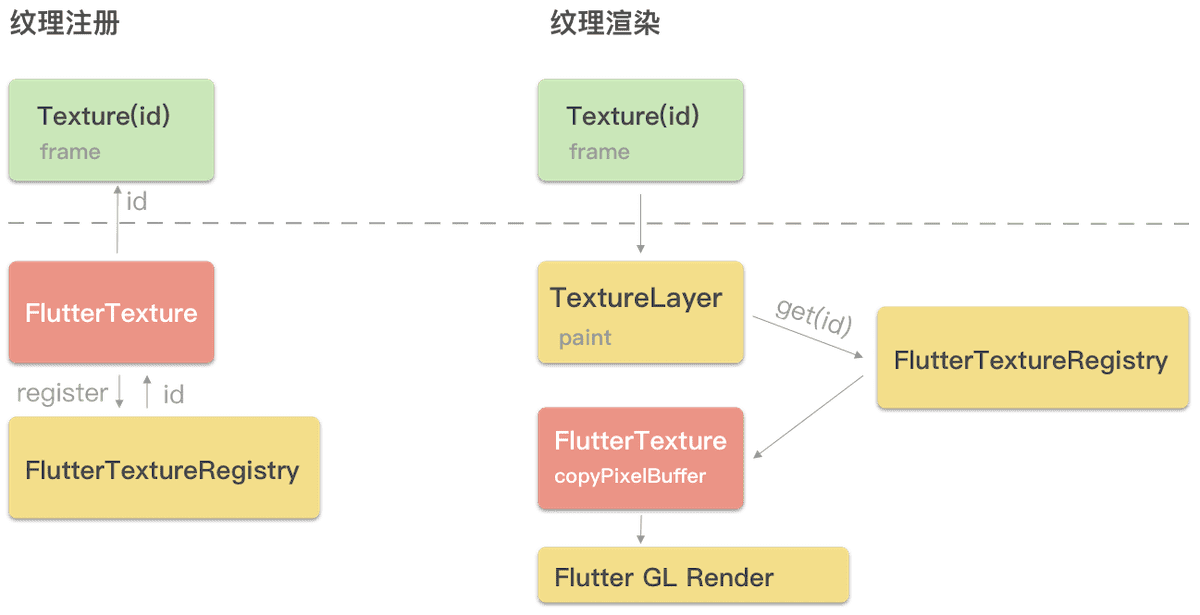
圖中紅色塊,是我們自己要編寫的native程式碼,黃色是flutter engine的內部程式碼邏輯。整體流程分為註冊紋理,和整體的紋理渲染邏輯。
註冊紋理
- 建立一個物件,實現
FlutterTexture協議,該物件用來管理具體的紋理資料 - 通過
FlutterTextureRegistry來註冊第一步的FlutterTexture物件,獲取一個flutter紋理id - 將該id通過channel機制傳遞給dart側,dart側就能夠通過
Texture這個widget來使用紋理了,引數就是id
紋理渲染
- dart側宣告一個
Texturewidget,表明該widget實際渲染的是native提供的紋理 - engine側拿到layerTree,layerTree的
TextureLayer節點負責外接紋理的渲染 - 首先通過dart側傳遞的id,找到先註冊的
FlutterTexture,該flutterTexture是我們自己用native程式碼實現的,其核心是實現了copyPixelBuffer方法 - flutter engine呼叫
copyPixelBuffer拿到具體的紋理資料,然後交由底層進行gpu渲染
CVPixelBuffer格式分析
一切問題的根源就在這裡了:CVPixelBuffer。從上面flutter外接紋理的渲染流程來看,native紋理到flutter紋理的資料互動,是通過copyPixelBuffer傳遞的,其引數就是CVPixelBuffer。而前面鹹魚文章裡面說的效能問題,就來自於紋理與CVPixelBuffer之間的轉換。
那麼,如果CVPixelBuffer能夠和OpenGL的紋理同享同一份記憶體拷貝,GPU -> CPU -> GPU的效能瓶頸,是否就能夠迎刃而解了呢?其實我們看一下flutter engine裡面利用CVPixelBuffer來建立紋理的方法,就能夠得到答案:
| |
flutter engine是使用CVOpenGLESTextureCacheCreateTextureFromImage這個介面來從CVPixelBuffer物件建立OpenGL紋理的,那麼這個介面實際上做了什麼呢?我們來看一下官方文件
This function either creates a new or returns a cached
CVOpenGLESTextureReftexture object mapped to theCVImageBufferRefand associated parameters. This operation creates a live binding between the image buffer and the underlying texture object. The EAGLContext associated with the cache may be modified to create, delete, or bind textures. When used as a source texture orGL_COLOR_ATTACHMENT, the image buffer must be unlocked before rendering. The source or render buffer texture should not be re-used until the rendering has completed. This can be guaranteed by callingglFlush().
從文件裡面,我們瞭解到幾個關鍵點:
- 返回的紋理物件,是直接對映到了CVPixelBufferRef物件的記憶體的
- 這塊buffer記憶體,其實是可以同時被CPU和GPU訪問的,我們只需要遵循如下的規則:
- GPU訪問的時候,該
CVPixelBuffer,不能夠處於lock狀態。
使用過pixelbuffer的同學應該都知道,通常CPU操作pixelbuffer物件的時候,要先進行lock操作,操作完畢再unlock。所以這裡也容易理解,GPU使用紋理的時候,其必然不能夠同時被CPU操作。 - CPU訪問的時候,要保證GPU已經渲染完成,通常是指在
glFlush()呼叫之後。
這裡也容易理解,CPU要讀寫這個buffer的時候,要保證關聯的紋理不能正在被OpenGL渲染。
- GPU訪問的時候,該
我們用instrument的allocation來驗證一下:
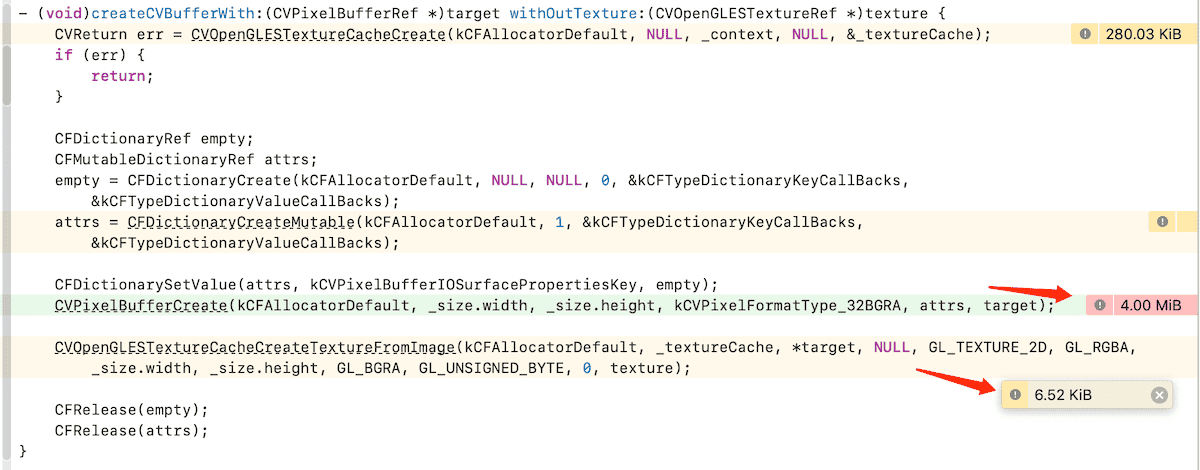
instrument的結果,也能夠印證文件中的結論。 只有在建立pixelBuffer的時候,才分配了記憶體,而對映到紋理的時候,並沒有新的記憶體分配。
這裡也能印證我們的結論,建立pixelBuffer的時候,才分配了記憶體,對映到紋理的時候,並沒有新的記憶體分配。
共享記憶體方案
既然瞭解到CVPixelBuffer物件,實際上是可以橋接一個OpenGL的紋理的,那我們的整體解決方案就水到渠成了,可以看看下面這個圖
![]()
關鍵點在於,首先需要建立pixelBuffer物件,並分配記憶體。然後在native gl環境和flutter gl環境裡面分別對映一個紋理物件。這樣,在2個獨立的gl環境裡面,我們都有各自的紋理物件,但實際上其記憶體都被對映到同一個CVPixelBuffer上。在實際的每一幀渲染流程裡面,native環境做渲染到紋理,而flutter環境裡面則是從紋理讀取資料。
Demo演示
這裡我寫了個小demo來驗證下實際效果,demo的主要邏輯是以60FPS的幀率,渲染一個旋轉的三角形到一個pixelBuffer對映的紋理上。然後每幀繪製完成之後,通知flutter側來讀取這個pixelBuffer物件去做渲染。

核心程式碼展示如下:
| |
關鍵程式碼都新增了註釋,這裡就不分析了
我們從上面的gif圖上可以看到整個渲染過程是十分流暢的,最後看displayLink的幀率也能夠達到60FPS。該demo是可以套用到其他的需要CPU與GPU共享記憶體的場景的。
完整的demo程式碼:
原文連結: