英文原文:César Souza 本文由@Thomas花園 翻譯並投遞於伯樂線上
K-均值聚類是流行、經典、簡單的聚類方法之一。聚類是非監督學習的一種方法,也是常用的統計資料分析技術,應用領域很廣,涉及機器學習、資料探勘、模式識別、影像分析和生物資訊學等。
●下載原始碼
●下載樣例程式
上面的原始碼是Accord.NET Framework的一部分.Accord.NET Framework是一個開發機器學習,計算機視覺,計算機音訊,統計和數學應用的框架.它是基於已有的強大AForge.NET Framework開發的.請參考starting guide瞭解更多細節.最新的框架包擴了最新的下載原始碼並帶有很多其他的統計和機器學習工具(statistics and machine learning tools.).
介紹
在統計和機器學習中, K-均值演算法是一種聚類分析方法,它將n個觀察物件分類到k個聚類,每個觀察物件將被分到與均值最接近的聚類中.在其最常見的形式中.K-均值是一種通過反覆迭代直至收斂到確定值的迭迭代貪婪演算法.
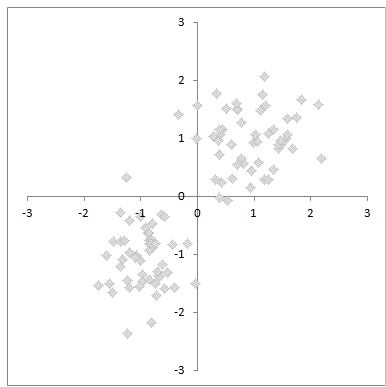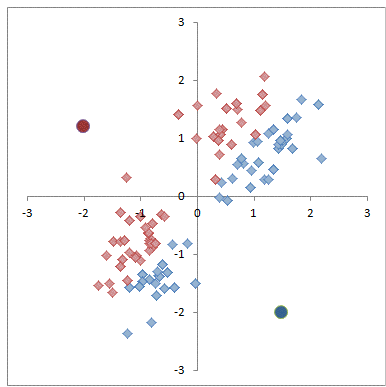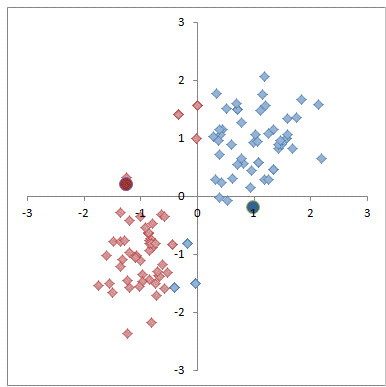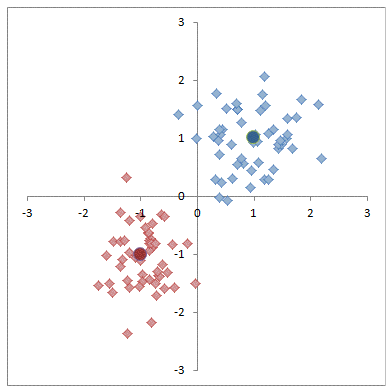
圖解K-均值演算法
演算法如下:
1)首先為聚類任意選出k個初始化的的質心.每個個觀察物件被分類到與質心最近的聚類中,
2)接著使用委派的觀察物件聚類的均值重新計算質心.
3)用新計算出的質心對觀察物件重新聚類如1)那樣分派到與質心最近的聚類中.
4)重複2) , 3)步驟直至聚類質心不再變化,或者小於給定的閾值.
(注:意譯,本意請參考原文)
上面是K-均值聚類演算法常見的形式。還有其他的改進和擴充的演算法,稱作勞合社的演算法Lloyd’s algorithm.
勞合社演算法
1.把k個點表示被聚類的物件位置,這些點表示相應初始組質心
2.分配每個物件到離質心最近的組裡
3.當所有的物件被分配完後,重新計算k個質心的位置
4.重複2,3步驟直到質心不再移動.
這些過程將物件分類到不同組,組間的最小化度量可以計算出來
原始碼
原始碼使用了Accord.NET,而且是框架的一部分.在當前本版(2.1.2) ,如和k-均值演算法相關的類在theAccord. MachineLearning空間裡
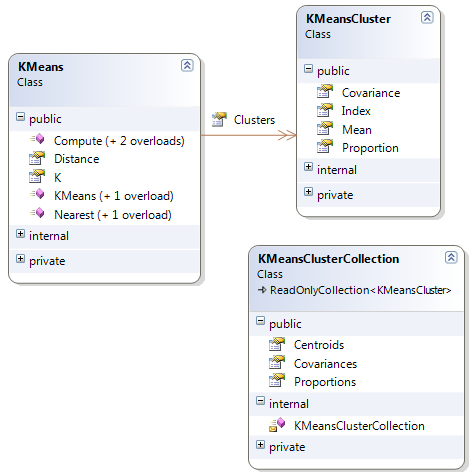
K-均值演算法的類圖
KMeans類k-均值演算法的主類,演算法在用Compute(double[][] data, double threshold)方法實現,Compute輸入是一系列的觀察物件和一個用來決定方法如何結束的收斂閾值
現實是直接明朗的,沒有使用特別的技術來避免收斂難題.以後更多的技術會加入實現.所以請為最新修訂的演算法原始碼下載最新的Accord.NET框架 使用原始碼為了使用原始碼,建立一個KMeans類新例項,傳遞期望的聚類給構造器.另外,你可能傳遞一個距離函式用來聚類距離度量.預設使用的是平方歐氏距離(square Euclidean distance).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// Declare some observations double[][] observations = { new double[] { -5, -2, -1 }, new double[] { -5, -5, -6 }, new double[] { 2, 1, 1 }, new double[] { 1, 1, 2 }, new double[] { 1, 2, 2 }, new double[] { 3, 1, 2 }, new double[] { 11, 5, 4 }, new double[] { 15, 5, 6 }, new double[] { 10, 5, 6 }, }; // Create a new K-Means algorithm with 3 clusters KMeans kmeans = new KMeans(3); // Compute the algorithm, retrieving an integer array // containing the labels for each of the observations int[] labels = kmeans.Compute(observations); // As a result, the first two observations should belong to the // same cluster (thus having the same label). The same should // happen to the next four observations and to the last three. |
樣例應用
在計算機視覺中, K-均值聚類演算法通常被用在影像分割(image segmentation).分割結果被用來邊界檢測(border detection) 和目標識別(object recognition).樣品應用使用標準平方歐氏距離度量RGB畫素顏色空間來分割影像.然而還有其他更好的距離度量方法來處理影像分割,如加權距離其他顏色空間.這裡就不列舉在應用中.
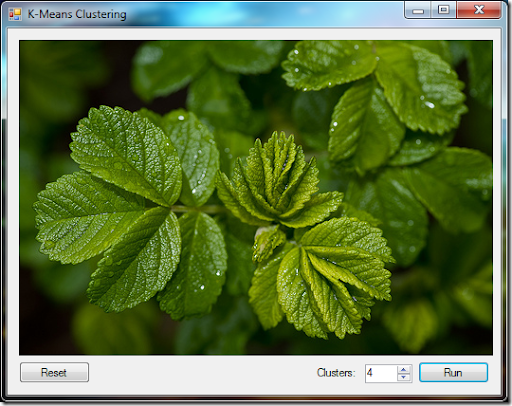
原圖(來自Ossi Petruska Flickr page*)
為了展示影像分割,首先將圖片變換成畫素值陣列.圖片會被一個個畫素的逐步讀進一個不規則陣列,陣列的型別的一個長度為三的雙精度浮點數陣列.每個雙精度浮點數陣列儲存著範圍在[-1, 1]的3個RGB值.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
/// /// Divides the input data into K clusters. /// public int[] Compute(double[][] data, double threshold) { int k = this.K; int rows = data.Length; int cols = data[0].Length; // pick K unique random indexes in the range 0..n-1 int[] idx = Accord.Statistics.Tools.Random(rows, k); // assign centroids from data set this.centroids = data.Submatrix(idx); // initial variables int[] count = new int[k]; int[] labels = new int[rows]; double[][] newCentroids; do // main loop { // Reset the centroids and the // cluster member counters' newCentroids = new double[k][]; for (int i = 0; i < k; i++) { newCentroids[i] = new double[cols]; count[i] = 0; } // First we will accumulate the data points // into their nearest clusters, storing this // information into the newClusters variable. // For each point in the data set, for (int i = 0; i < data.Length; i++) { // Get the point double[] point = data[i]; // Compute the nearest cluster centroid int c = labels[i] = Nearest(data[i]); // Increase the cluster's sample counter count[c]++; // Accumulate in the corresponding centroid double[] centroid = newCentroids[c]; for (int j = 0; j < centroid.Length; j++) centroid[j] += point[j]; } // Next we will compute each cluster's new centroid // by dividing the accumulated sums by the number of // samples in each cluster, thus averaging its members. for (int i = 0; i < k; i++) { double[] mean = newCentroids[i]; double clusterCount = count[i]; for (int j = 0; j < cols; j++) mean[j] /= clusterCount; } // The algorithm stops when there is no further change in // the centroids (difference is less than the threshold). if (centroids.IsEqual(newCentroids, threshold)) break; // go to next generation centroids = newCentroids; } while (true); // Compute cluster information (optional) for (int i = 0; i < k; i++) { // Extract the data for the current cluster double[][] sub = data.Submatrix(labels.Find(x => x == i)); // Compute the current cluster variance covariances[i] = Statistics.Tools.Covariance(sub, centroids[i]); // Compute the proportion of samples in the cluster proportions[i] = (double)sub.Length / data.Length; } // Return the classification result return labels; } |
在那個陣列畫素值進行聚類後,每個畫素有個相關的聚類標籤.標籤的值將會被其相應的聚類質心交換.當應用程式的Run按鈕被點選時,下面的程式碼就會被呼叫.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
private void btnRun_Click(object sender, EventArgs e) { // Retrieve the number of clusters int k = (int)numClusters.Value; // Load original image Bitmap image = Properties.Resources.leaf; // Transform the image into an array of pixel values double[][] pixels = image.ToDoubleArray(); // Create a K-Means algorithm using given k and a // square euclidean distance as distance metric. KMeans kmeans = new KMeans(k, Distance.SquareEuclidean); // Compute the K-Means algorithm until the difference in // cluster centroids between two iterations is below 0.05 int[] idx = kmeans.Compute(pixels, 0.05); // Replace every pixel with its corresponding centroid pixels.ApplyInPlace((x, i) => kmeans.Clusters.Centroids[idx[i]]); // Show resulting image in the picture box pictureBox.Image = pixels.ToBitmap(image.Width, image.Height); } |
在分割後,獲得如下圖片結果:
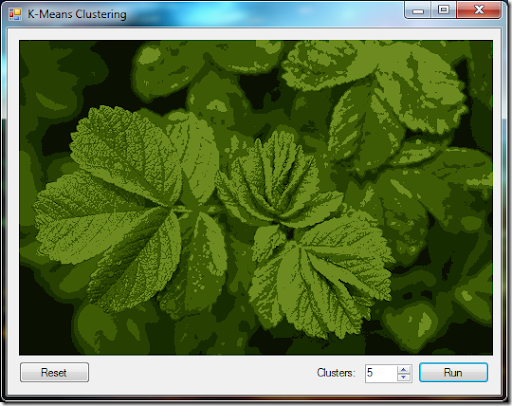
影像標本,在k = 5的K-均值聚類處理後
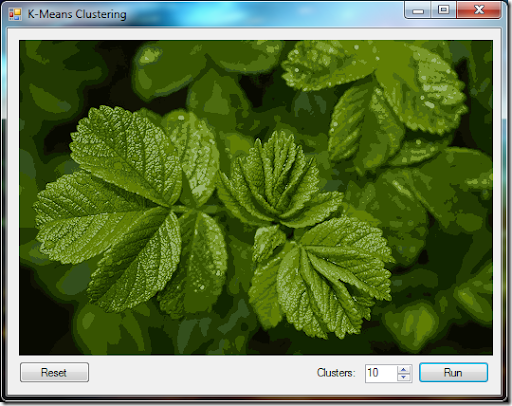
影像在k = 10的K-均值聚類處理後
以上樣本影像已經Ossi Petruska的Creative Commons Attribution-NonCommercial-ShareAlike 2.0 Generic授權
總結
K-均值聚類是一種非常簡單,流行的聚類方法,.這裡展現的樣品實現使用了in Accord.NET框架.就如所見.隨著通過代理函式或lambda表示式實現的自定義函式,聚類函式很容易被擴充.可以用到不同環境,如影像分割,而不用過多修改.一個關於改進的建議:正如Charles Elkan.的論文《使用三角不等式加速K-均值演算法》(“Using the triangle inequality to accelerate k-means”)所建議聚類方法可以變得更快.
在下一篇文章中,我們將會看到在高斯混合模型怎樣使用K-均值演算法來初始化期望-最大演算法來評估高斯混合密度.這些文章將會成為連續緻密隱馬爾可夫模型的基礎.
致謝
感謝Antonino Porcino提供了第一個版本的程式碼和其有價值的他演算法和方法。
參考文獻
●[1] Matteo Matteucci. “Tutorial on Clustering Algorithms,” Politecnico di Milano,http://home.dei.polimi.it/matteucc/Clustering/tutorial_html/kmeans.html(acessed October 4, 2010).
●[2] Teknomo, Kardi. “K-Means Clustering Tutorials,”http://people.revoledu.com/kardi/ tutorial/kMean/(acessed October 6, 2010).
●[3] Wikipedia contributors, “Cluster analysis,”Wikipedia, The Free Encyclopedia,http://en.wikipedia.org/wiki/Cluster_analysis(accessed October 4, 2010).
●[4] Wikipedia contributors, “K-means clustering,”Wikipedia, The Free Encyclopedia,http://en.wikipedia.org/wiki/K-means_clustering(accessed October 4, 2010).
英文原文:César Souza 本文由@Thomas花園 翻譯並投遞於伯樂線上
【如需轉載,請標註並保留原文連結、譯文連結和譯者等資訊,謝謝合作!】