k-均值聚類簡介
k-均值聚類:將訓練集分成k個靠近彼此的不同樣本聚類。因此我們可以認為該演算法提供了k-維的one-hot編碼向量h以表示輸入x。當x屬於聚類i時,有hi=1,h的其它項為零。k-均值聚類提供的one-hot編碼也是一種稀疏表示,因為每個輸入的表示中大部分元素為零。one-hot編碼是稀疏表示的一個極端示例,丟失了很多分散式表示的優點。one-hot編碼仍然有一些統計優點(自然地傳達了相同聚類中的樣本彼此相似的觀點),也具有計算上的優勢,因為整個表示可以用一個單獨的整數表示。
k-均值聚類初始化k個不同的中心點{μ(1),…,μ(k)},然後迭代交換兩個不同的步驟直到收斂。步驟一,每個訓練樣本分配到最近的中心點μ(i)所代表的聚類i。步驟二,每一箇中心點μ(i)更新為聚類i中所有訓練樣本x(j)的均值。
關於聚類的一個問題是聚類問題本身是病態的。這是說沒有單一的標準去度量聚類的資料在真實世界中效果如何。我們可以度量聚類的性質,例如類中元素到類中心點的歐幾里得距離的均值。這使我們可以判斷從聚類分配中重建訓練資料的效果如何。然而我們不知道聚類的性質是否很好地對應到真實世界的性質。此外,可能有許多不同的聚類都能很好地對應到現實世界的某些屬性。我們可能希望找到和一個特徵相關的聚類,但是得到了一個和任務無關的,同樣是合理的不同聚類。例如,假設我們在包含紅色卡車圖片、紅色汽車圖片、灰色卡車圖片和灰色汽車圖片的資料集上執行兩個聚類演算法。如果每個聚類演算法聚兩類,那麼可能一個演算法將汽車和卡車各聚一類,另一個根據紅色和灰色各聚一類。假設我們還執行了第三個聚類演算法,用來決定類別的數目。這有可能聚成了四類,紅色卡車、紅色汽車、灰色卡車和灰色汽車。現在這個新的聚類至少抓住了屬性的資訊,但是丟失了相似性資訊。紅色汽車和灰色汽車在不同的類中,正如紅色汽車和灰色卡車也在不同的類中。該聚類演算法沒有告訴我們灰色汽車和紅色汽車的相似度比灰色卡車和紅色汽車的相似度更高。我們只知道它們是不同的。這些問題說明了一些我們可能更偏好於分散式表示(相對於one-hot表示而言)的原因。分散式表示可以對每個車輛賦予兩個屬性----一個表示它顏色,一個表示它是汽車還是卡車。目前仍然不清楚什麼是最優的分散式表示(學習演算法如何知道我們關心的兩個屬性是顏色和是否汽車或卡車,而不是製造商和年齡?),但是多個屬性減少了演算法去猜我們關心哪一個屬性的負擔,允許我們通過比較很多屬性而非測試一個單一屬性來細粒度地度量相似性。
k-均值演算法源於訊號處理中的一種向量量化方法,現在則更多地作為一種聚類分析方法流行於資料探勘領域。k-均值聚類的目的是:把n個點(可以是樣本的一次觀察或一個例項)劃分到k個聚類中,使得每個點都屬於離它最近的均值(此即聚類中心)對應的聚類,以之作為聚類的標準。
k-均值聚類與k-近鄰演算法之間沒有任何關係。
k-均值聚類演算法描述:已知觀測集(x1,x2,…,xn),其中每個觀測都是一個d-維實向量,k-均值聚類要把這n觀測劃分到k個集合中(k≤n),使得組內平方和(WCSS within-cluster sum of squares)最小。換句話說,它的目標是找到使得下式滿足的聚類Si:其中μi是Si中所有點的均值。
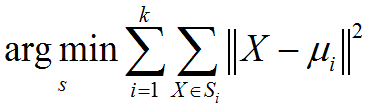
k-均值聚類標準演算法:最常用的演算法使用迭代優化的技術。它被稱為k-均值演算法而廣為使用,有時也被稱為Lloyd演算法(尤其在電腦科學領域)。已知初始化的k個均值點m1(1),…,mk(1),演算法按照下面兩個步驟交替進行:
(1)、分配(Assignment):將每個觀測分配到聚類中,使得組內平方和(WCSS)達到最小。因為這一平方和就是平方後的歐式距離,所以很直觀地把觀測分配到離它最近的均值點即可:
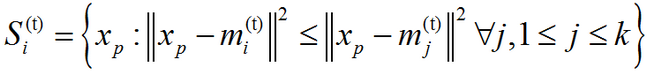
其中每個xp都只被分配到一個確定的聚類St中,儘管在理論上它可能被分配到2個或者更多的聚類。
(2)、更新(Update):對於上一步得到的每一個聚類,以聚類中觀測值的質心(centroids)作為新的均值點:
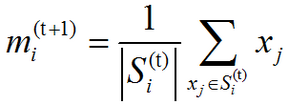
因為算術平均是最小二乘估計,所以這一步同樣減少了目標函式組內平方和(WCSS)的值。這一演算法將在對於觀測的分配不再變化時收斂。由於交替進行的兩個步驟都會減少目標函式WCSS的值,並且分配方案只有有限種,所以演算法一定會收斂於某一(區域性)最優解。注意:使用這一演算法無法保證得到全域性最優解。
這一演算法經常被描述為”把觀測按照距離分配到最近的聚類”。標準演算法的目標函式是組內平方和(WCSS),而且按照”最小二乘和”來分配觀測,確實是等價於按照最小歐氏距離來分配觀測的。如果使用不同的距離函式來代替(平方)歐氏距離,可能使得演算法無法收斂。然而,使用不同的距離函式,也能得到k-均值聚類的其他變體,如球體k-均值演算法和k-中心點演算法。
初始化方法:通常使用的初始化方法有Forgy和隨機劃分(Random Partition)方法。Forgy方法隨機地從資料集中選擇k個觀測作為初始的均值點;而隨機劃分方法則隨機地為每一觀測指定聚類,然後執行”更新(Update)”步驟,即計算隨機分配的各聚類的中心,作為初始的均值點。Forgy方法易於使得初始均值點散開,隨機劃分方法則把均值點都放到靠近資料集中心的地方。隨機劃分方法一般更適用於k-調和均值和模糊k-均值演算法。對於期望-最大化(EM)演算法和標準k-均值演算法,Forgy方法作為初始化方法的表現會更好一些。
這是一個啟發式演算法,無法保證收斂到全域性最優解,並且聚類的結果會依賴於初始的聚類。又因為演算法的執行速度通常很快,所以一般都以不同的起始狀態執行多次來得到更好的結果。不過,在最差的情況下,k-均值演算法會收斂地特別慢。
注:把”分配”步驟視為”期望”步驟,把”更新”步驟視為”最大化步驟”,可以看到,這一演算法實際上是廣義期望--最大化演算法(GEM)的一個變體。
使得k-均值演算法效率很高的兩個關鍵特徵同時也被經常被視為它最大的缺陷:
(1)、聚類數目k是一個輸入引數。選擇不恰當的k值可能會導致糟糕的聚類結果。這也是為什麼要進行特徵檢查來決定資料集的聚類數目了。
(2)、收斂到區域性最優解,可能導致”反直觀”的錯誤結果。
k-均值演算法的一個重要的侷限性即在於它的聚類模型。這一模型的基本思想在於:得到相互分離的球狀聚類,在這些聚類中,均值點趨向收斂於聚類中心。 一般會希望得到的聚類大小大致相當,這樣把每個觀測都分配到離它最近的聚類中心(即均值點)就是比較正確的分配方案。k-均值聚類的結果也能理解為由均值點生成的Voronoi cells。
k-均值聚類(尤其是使用如Lloyd's演算法的啟發式方法的聚類)即使是在巨大的資料集上也非常容易部署實施。正因為如此,它在很多領域都得到的成功的應用,如市場劃分、機器視覺、 地質統計學、天文學和農業等。它經常作為其他演算法的預處理步驟,比如要找到一個初始設定。
在(半)監督學習或無監督學習中,k-均值聚類被用來進行特徵學習(或字典學習)步驟。基本方法是,首先使用輸入資料訓練出一個k-均值聚類表示,然後把任意的輸入資料投射到這一新的特徵空間。 k-均值的這一應用能成功地與自然語言處理和計算機視覺中半監督學習的簡單線性分類器結合起來。在物件識別任務中,它能展現出與其他複雜特徵學習方法(如自動編碼器、受限Boltzmann機等)相當的效果。然而,相比複雜方法,它需要更多的資料來達到相同的效果,因為每個資料點都只貢獻了一個特徵(而不是多重特徵)。
K-Means演算法概要:來自 酷 殼 – CoolShell ,因為表述的很形象,所以在這裡引用下

相關文章
- K-均值聚類分析聚類
- 用K-均值聚類來探索顧客細分聚類
- Python k-均值聚類演算法二維例項Python聚類演算法
- 演算法金 | K-均值、層次、DBSCAN聚類方法解析演算法聚類
- 聚類之K均值聚類和EM演算法聚類演算法
- 如何在BigQueryML中使用K-均值聚類來更好地理解和描述資料(附程式碼)聚類
- K-鄰近均值演算法演算法
- 機器學習經典聚類演算法 —— k-均值演算法(附python實現程式碼及資料集)機器學習聚類演算法Python
- K-最近鄰法(KNN)簡介KNN
- C均值聚類 C實現 Python實現聚類Python
- 第十篇:K均值聚類(KMeans)聚類
- 聚簇表簡介
- 部分聚類演算法簡介及優缺點分析聚類演算法
- 演算法雜貨鋪:k均值聚類(K-means)演算法聚類
- 《機器學習實戰》kMeans演算法(K均值聚類演算法)機器學習演算法聚類
- pyhanlp 文字聚類詳細介紹HanLP聚類
- 第5章 基於K均值聚類的網路流量異常檢測聚類
- 【機器學習】:Kmeans均值聚類演算法原理(附帶Python程式碼實現)機器學習聚類演算法Python
- 《機器學習實戰》二分-kMeans演算法(二分K均值聚類)機器學習演算法聚類
- Qt QApplication 類簡介--Qt 類簡介專題(四)QTAPP
- 股票種類簡介
- 分類 和 聚類聚類
- 【火爐煉AI】機器學習022-使用均值漂移聚類演算法構建模型AI機器學習聚類演算法模型
- 演算法金 | 一文讀懂K均值(K-Means)聚類演算法演算法聚類
- 聚類分析聚類
- 聚類(part3)--高階聚類演算法聚類演算法
- Vector3 類簡介
- 教你文字聚類聚類
- 《資料分析實戰-托馬茲.卓巴斯》讀書筆記第4章-聚類技巧(K均值、BIRCH、DBSCAN)筆記聚類
- 完整的FTP類 功能簡介FTP
- 聚類演算法聚類演算法
- 機器學習——dbscan密度聚類機器學習聚類
- 【scipy 基礎】--聚類聚類
- 機器學習(8)——其他聚類機器學習聚類
- 09聚類演算法-層次聚類-CF-Tree、BIRCH、CURE聚類演算法
- 聚類分析-案例:客戶特徵的聚類與探索性分析聚類特徵
- Java日期和時間類簡介Java
- Android提供的LruCache類簡介Android