1. 網路爬蟲的型別
現在我們已經基本瞭解了網路爬蟲的組成,那麼網路爬蟲具體有哪些型別呢?
網路爬蟲按照實現的技術和結構可以分為通用網路爬蟲、聚焦網路爬蟲、增量式網路爬蟲、深層網路爬蟲等型別。在實際的網路爬蟲中,通常是這幾類爬蟲的組合體。
1.1 通用網路爬蟲
首先我們為大家介紹通用網路爬蟲(General Purpose Web Crawler)。通用網路爬蟲又叫作全網爬蟲,顧名思義,通用網路爬蟲爬取的目標資源在全網際網路中。
通用網路爬蟲所爬取的目標資料是巨大的,並且爬行的範圍也是非常大的,正是由於其爬取的資料是海量資料,故而對於這類爬蟲來說,其爬取的效能要求是非常高的。這種網路爬蟲主要應用於大型搜尋引擎中,有非常高的應用價值。
通用網路爬蟲主要由初始URL集合、URL佇列、頁面爬行模組、頁面分析模組、頁面資料庫、連結過濾模組等構成。通用網路爬蟲在爬行的時候會採取一定的爬行策略,主要有深度優先爬行策略和廣度優先爬行策略。
1.2 聚焦網路爬蟲
聚焦網路爬蟲(Focused Crawler)也叫主題網路爬蟲,顧名思義,聚焦網路爬蟲是按照預先定義好的主題有選擇地進行網頁爬取的一種爬蟲,聚焦網路爬蟲不像通用網路爬蟲一樣將目標資源定位在全網際網路中,而是將爬取的目標網頁定位在與主題相關的頁面中,此時,可以大大節省爬蟲爬取時所需的頻寬資源和伺服器資源。
聚焦網路爬蟲主要應用在對特定資訊的爬取中,主要為某一類特定的人群提供服務。
聚焦網路爬蟲主要由初始URL集合、URL佇列、頁面爬行模組、頁面分析模組、頁面資料庫、連結過濾模組、內容評價模組、連結評價模組等構成。內容評價模組可以評價內容的重要性,同理,連結評價模組也可以評價出連結的重要性,然後根據連結和內容的重要性,可以確定哪些頁面優先訪問。
聚焦網路爬蟲的爬行策略主要有4種,即基於內容評價的爬行策略、基於連結評價的爬行策略、基於增強學習的爬行策略和基於語境圖的爬行策略。關於聚焦網路爬蟲具體的爬行策略,我們將在下文中進行詳細分析。

1.3 增量式網路爬蟲
增量式網路爬蟲(Incremental Web Crawler),所謂增量式,對應著增量式更新。
增量式更新指的是在更新的時候只更新改變的地方,而未改變的地方則不更新,所以增量式網路爬蟲,在爬取網頁的時候,只爬取內容發生變化的網頁或者新產生的網頁,對於未發生內容變化的網頁,則不會爬取。
增量式網路爬蟲在一定程度上能夠保證所爬取的頁面,儘可能是新頁面。
1.4 深層網路爬蟲
深層網路爬蟲(Deep Web Crawler),可以爬取網際網路中的深層頁面,在此我們首先需要了解深層頁面的概念。
在網際網路中,網頁按存在方式分類,可以分為表層頁面和深層頁面。所謂的表層頁面,指的是不需要提交表單,使用靜態的連結就能夠到達的靜態頁面;而深層頁面則隱藏在表單後面,不能透過靜態連結直接獲取,是需要提交一定的關鍵詞之後才能夠獲取得到的頁面。
在網際網路中,深層頁面的數量往往比表層頁面的數量要多很多,故而,我們需要想辦法爬取深層頁面。
爬取深層頁面,需要想辦法自動填寫好對應表單,所以,深層網路爬蟲最重要的部分即為表單填寫部分。
深層網路爬蟲主要由URL列表、LVS列表(LVS指的是標籤/數值集合,即填充表單的資料來源)、爬行控制器、解析器、LVS控制器、表單分析器、表單處理器、響應分析器等部分構成。
深層網路爬蟲表單的填寫有兩種型別:
- 第一種是基於領域知識的表單填寫,簡單來說就是建立一個填寫表單的關鍵詞庫,在需要填寫的時候,根據語義分析選擇對應的關鍵詞進行填寫;
- 第二種是基於網頁結構分析的表單填寫,簡單來說,這種填寫方式一般是領域知識有限的情況下使用,這種方式會根據網頁結構進行分析,並自動地進行表單填寫。
以上,為大家介紹了網路爬蟲中常見的幾種型別,希望讀者能夠對網路爬蟲的分類有一個基本的瞭解。
2. 爬蟲擴充套件——聚焦爬蟲
由於聚焦爬蟲可以按對應的主題有目的地進行爬取,並且可以節省大量的伺服器資源和頻寬資源,具有很強的實用性,所以在此,我們將對聚焦爬蟲進行詳細講解。圖1-2所示為聚焦爬蟲執行的流程,熟悉該流程後,我們可以更清晰地知道聚焦爬蟲的工作原理和過程。
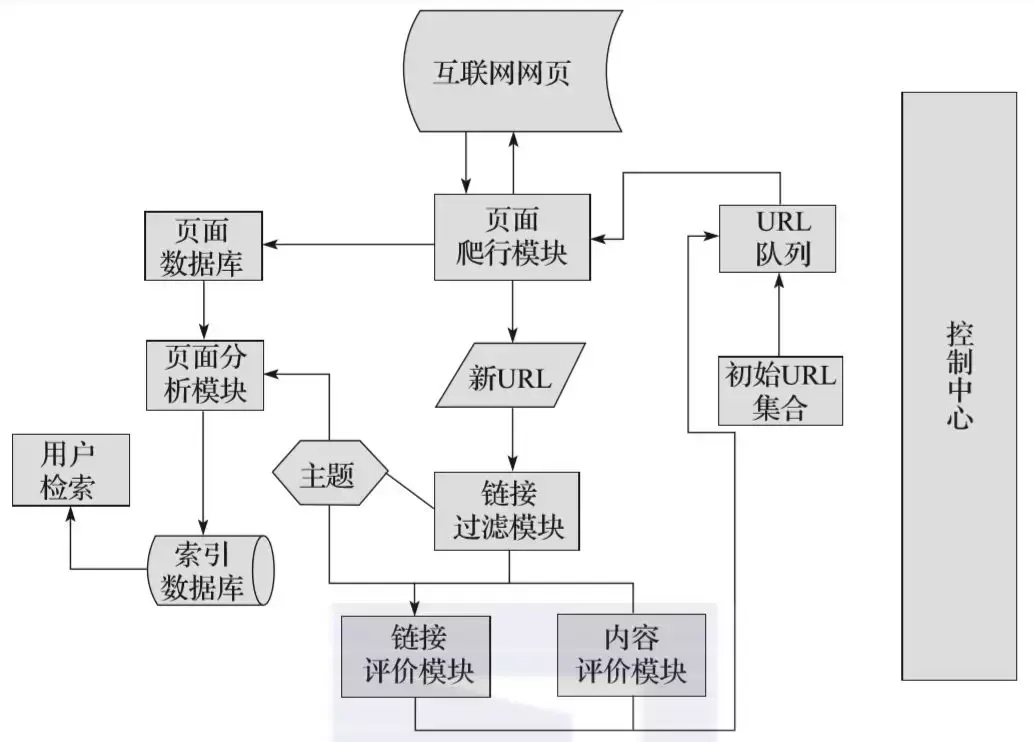
▲圖2-2 聚焦爬蟲執行的流程
首先,聚焦爬蟲擁有一個控制中心,該控制中心負責對整個爬蟲系統進行管理和監控,主要包括控制使用者互動、初始化爬行器、確定主題、協調各模組之間的工作、控制爬行過程等方面。
然後,將初始的URL集合傳遞給URL佇列,頁面爬行模組會從URL佇列中讀取第一批URL列表,然後根據這些URL地址從網際網路中進行相應的頁面爬取。
爬取後,將爬取到的內容傳到頁面資料庫中儲存,同時,在爬行過程中,會爬取到一些新的URL,此時,需要根據我們所定的主題使用連結過濾模組過濾掉無關連結,再將剩下來的URL連結根據主題使用連結評價模組或內容評價模組進行優先順序的排序。完成後,將新的URL地址傳遞到URL佇列中,供頁面爬行模組使用。
另一方面,將頁面爬取並存放到頁面資料庫後,需要根據主題使用頁面分析模組對爬取到的頁面進行頁面分析處理,並根據處理結果建立索引資料庫,使用者檢索對應資訊時,可以從索引資料庫中進行相應的檢索,並得到對應的結果。
這就是聚焦爬蟲的主要工作流程,瞭解聚焦爬蟲的主要工作流程有助於我們編寫聚焦爬蟲,使編寫的思路更加清晰。
02 網路爬蟲技能總覽
在上文中,我們已經初步認識了網路爬蟲,那麼網路爬蟲具體能做些什麼呢?用網路爬蟲又能做哪些有趣的事呢?在本章中我們將為大傢俱體講解。