Mysql資料庫學習(三):表的crud操作、完整性約束、select各種查詢
一、表的crud操作
指增加(Create)、查詢(Retrieve)(重新得到資料)、更新(Update)和刪除(Delete)
// select 查詢後面再講
SQL Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
create table tb_test2 select * from db_test.tb_test;
// insert into .. select
create table t_emp(empno int, ename varchar(20), esex char(2));
alter table t_emp modify ename varchar(30); alter table t_emp drop esex; alter table t_emp add esex char(2); insert into t_emp(empno, ename, esex) values(1000, 'tom', 'm'); insert into t_emp values(1000, 'maggie', 'f'); /* 還沒設定主鍵,故empno可以相同 */ insert into t_emp(empno, ename) values(1002, 'john'); insert into t_emp(empno, ename, esex) values(1003, null, 'm'); insert into t_emp values(1004, '張三', '男'); show variables like 'character_set%'; /* 檢視字符集設定 */ set character_set_database=utf8; /* 也可設定配置檔案 */ set names gbk; /* 支援插入中文 */ update t_emp set empno=1001 where ename='maggie'; delete from t_emp where esex is null; delete from t_emp; /* 表結構還在 */ truncate table t_emp;// 比較快 drop table t_emp; /* 整表刪除 */ |
二、完整性約束
表完整性約束
主鍵 (constraint)外來鍵 (constraint)使用者自定義完整性約束 (check)
SQL Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
create table t_emp(empno int not null primary key, ename varchar(20), esex char(2)); /* 建立時設定主鍵*/
create table t_emp(empno int, ename varchar(20), esex char(2), primary key (empno)); create table t_emp(empno int, ename varchar(20), esex char(2), constraint PK_EMPNO primary key(empno)); /* 設定主鍵*/ create table t_emp(empno int, ename varchar(20), esex char(2)); alter table t_emp add constraint PK_EMPNO primary key(empno); /* 這種方式也可以設定主鍵 */ insert into t_emp values(1000, 'john', 'm'); insert into t_emp values(1000, 'lily', 'f'); /* error,empno不能相等 */ insert into t_emp values(null, 'lily', 'f'); /* error,主鍵不能為空 */ create table t_emp(empno int, deptno int, ename varchar(20), esex char(2)); alter table t_emp add constraint PK_EMPNO primary key(empno); create table t_dept(deptno int, dname varchar(20)); alter table t_dept add constraint PK_DEPTNO primary key(deptno); alter table t_emp add constraint FK_DEPTNO foreign key(deptno) references t_dept(deptno); /*設定t_emp 的外來鍵為t_dept 的主鍵 */ set names gbk; insert into t_dept values(2001, '人事部'); insert into t_dept values(2002, '技術部'); insert into t_emp values(1001, 2001, 'john', 'm'); insert into t_emp values(1003, 2003, 'john', 'm'); create table t_test1(id int auto_increment primary key, name varchar(30), age int default 20); insert into t_test1 values(null, 'aaa'); insert into t_test1 values(null, 'aaa', null); insert into t_test1 (name) values( 'bbb'); create table t_test2(id int, name varchar(30), age int); alter table t_test2 add constraint CC_AGE check (age >=18 and age<=60); /* 實際上現在mysql不支援check限制 */ alter table t_test2 add constraint CC_AGE check (length(name)>2); |
增加/刪除unique key
ALTER TABLE Persons
ADD CONSTRAINT uc_PersonID UNIQUE (Id_P,LastName)
ALTER TABLE Persons
DROP INDEX uc_PersonID
此時insert ignore 如果插入的資料中有重複的primary key or unique 索引,則忽略不插入
mysql 中常用的四種插入資料的語句:
insert into 表示插入資料,資料庫會檢查主鍵,如果出現重複會報錯;
replace into 表示插入替換資料,需求表中有Primary Key,或者unique索引,如果資料庫已經存在資料,則用新資料替換,如果沒有資料效果則和
insert into 一樣;
insert ignore 表示,如果中已經存在完全相同的記錄,或者primary key/ unique 索引衝突, 則忽略當前新資料,但不會出現錯誤
insert into ... ON DUPLICATE KEY UPDATE 如果插入行後會導致在一個UNIQUE索引或PRIMARY KEY中出現重複值,則執行舊行UPDATE
MySQL MyIsAm 儲存引擎在建立索引的時候,索引鍵長度是有一個較為嚴格的長度限制的,索引鍵最大長度總和不能超過1000(注意:utf8 為 3bytes),innodb
引擎則不受限制。查詢系統是否支援 innodb,可以 執行如下命令:
SHOW variables like "have_%"
顯示結果中會有如下3種可能的結果:
have_innodb YES
have_innodb NO
have_innodb DISABLED
這 3 種結果分別對應:
已經開啟 InnoDB 引擎
未安裝 InnoDB 引擎
未啟用 InnoDB 引擎
針對第二種未安裝,只需要安裝即可;針對第三種未啟用,則開啟mysql 配置檔案,找到 skip-innodb 項,將其改成 #skip-innodb,之後重啟 mysql 服務即可。
SHOW variables like "have_%"
顯示結果中會有如下3種可能的結果:
have_innodb YES
have_innodb NO
have_innodb DISABLED
這 3 種結果分別對應:
已經開啟 InnoDB 引擎
未安裝 InnoDB 引擎
未啟用 InnoDB 引擎
針對第二種未安裝,只需要安裝即可;針對第三種未啟用,則開啟mysql 配置檔案,找到 skip-innodb 項,將其改成 #skip-innodb,之後重啟 mysql 服務即可。
三、select 查詢
練習前先匯入資料:
create database scott;
use scott;
source C:\scott.sql scott.sql
點這下載
或者 mysql -uxxx -pxxx scott < scott.sql1.select 單表查詢:
SQL Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
select empno,ename,job from emp;
select * from emp; SELECT empno as '工號',ename '姓名' FROM emp; /* as 後面是別名 */ SELECT empno, '暨南大學' FROM emp; /* 常量列查詢 */ SELECT empno, concat(ename,'#') FROM emp; /* concat連線 */ SELECT empno, ename||'#' FROM emp; /* oracle可以用||作為連線符 */ SELECT empno, ename, job FROM emp WHERE ename = 'SMITH' SELECT empno, ename, job FROM emp WHERE ename <> 'SMITH' /* 也可以使用!= */ SELECT empno, ename, sal FROM emp WHERE sal>= 1500 SELECT * FROM emp WHERE deptno=30 and sal>1500; /* and */ SELECT * FROM emp WHERE job='MANAGER' or job='SALESMAN' /* or */ SELECT * FROM emp where sal BETWEEN 800 and 1500; SELECT * FROM emp where sal >= 800 and sal <= 1500; SELECT empno, ename, sal, comm FROM emp WHERE comm is null SELECT empno, ename, sal, comm FROM emp WHERE comm is not null /* not */ SELECT * FROM emp where sal not BETWEEN 800 and 1500; /* between */ SELECT * FROM emp where ename in ('SMITH', 'KING'); /* in */ SELECT * FROM emp where ename like 'S%'; /* 模糊查詢 萬用字元: ‘%’(0個多個字元); 萬用字元: ‘_’ (單個字元) */ SELECT * FROM emp where ename like 'S_ITH'; SELECT * FROM emp ORDER BY ename desc; /* order by 預設是升序 asc */ SELECT empno, ename, job FROM emp ORDER BY 2 desc; SELECT * FROM emp ORDER BY job asc, sal desc; |
如果我就真的要查%或者_,怎麼辦呢?使用escape,轉義字元後面的%或_就不作為萬用字元了,注意前面沒有轉義字元的%和_仍然起萬用字元作用
select username from gg_user where username like '%xiao/_%' escape '/';
select username from gg_user where username like '%xiao/%%' escape '/';
select username from gg_user where username like '%xiao/_%' escape '/';
select username from gg_user where username like '%xiao/%%' escape '/';
在like 裡面為了查詢 “\”,必須指定它為 “\\\\” 。
SQL Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
select * from emp ORDER BY sal limit 5; /*limit可用於分頁查詢*/
select * from emp ORDER BY sal limit 0,5; /* 0表示offet, 5表示從0開始的5條記錄*/ select * from emp ORDER BY sal limit 5,5; select * from emp ORDER BY sal limit 10,5; select job,deptno from emp; select all job,deptno from emp; /* 預設是all */ select distinct job,deptno from emp; /* 去除重複記錄 */ select * from dept where deptno in (SELECT DISTINCT deptno from emp); /* 查詢有員工的部門資訊 */ /* UNION (無重複並集):當執行UNION 時,自動去掉結果集中的重複行,並以第一列的結果進行升序排序。*/ select empno,ename,job from emp where job='SALESMAN' union /* union即聯合查詢 */ select empno,ename,job from emp where job='MANAGER'; select empno,ename,job from emp where job='SALESMAN' or job='MANAGER' /* 比較結果 */ /* UNION ALL (有重複並集):不去掉重複行,並且不對結果集進行排序。*/ select job, sal from emp where empno=7902 union all select job, sal from emp where empno=7788; select job, sal from emp where empno=7902 union select job, sal from emp where empno=7788; |
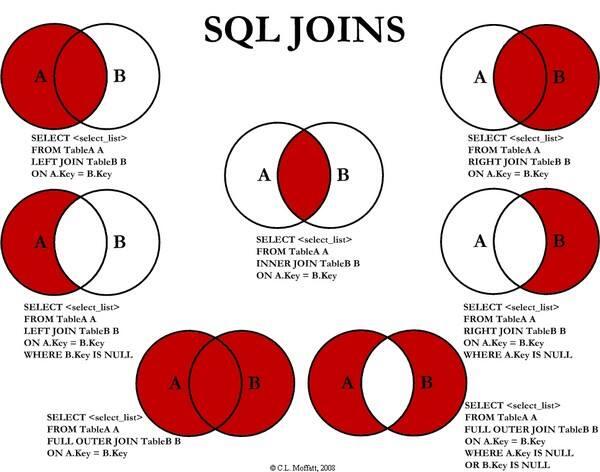
2.select 多表查詢:
多表查詢
交叉連線內連線自身連線外連線
左外連線右外連線全連線
自然連線
交叉連線是不帶WHERE子句的多表查詢,它返回被連線的兩個表所有資料行的笛卡爾積。返回到結果集合中的資料行數等於第一個表中符合查詢條件的資料行數乘以第二個表中符合查詢條件的資料行數。
內連線(等值連線):在連線條件中使用等於號(=)運算子比較被連線列的列值,其查詢結果中列出被連線表中的所有列,包括其中的重複列。
內連線(不等連線):在連線條件使用除等於運算子以外的其它比較運算子比較被連線的列的列值。這些運算子包括>、>=、<=、<、!>、!<和<>
內連線(自身連線)
外連線(左連線):返回包括左表中的所有記錄和右表中聯結欄位相等的記錄;即左外連線就是在等值連線的基礎上加上主表中的未匹配資料(被連線
表欄位為 NULL)。
外連線(右連線):返回包括右表中的所有記錄和左表中聯結欄位相等的記錄;即右外連線是在等值連線的基礎上加上被連線表的不匹配資料(連線表欄位為 NULL)。
外連線(全連線):全外連線是在等值連線的基礎上將左表和右表的未匹配資料都加上。mysql 不支援 full outer join。
SQL Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
select * from emp,dept /*交叉連線 */
SELECT * FROM emp INNER JOIN dept ON emp.deptno = dept.deptno; /*內連線(等值連線) */ select * from emp,dept where emp.deptno=dept.deptno; select * from emp INNER JOIN dept on emp.deptno > dept.deptno; /* 內連線(不等連線)*/ select * from emp,dept where emp.deptno > dept.deptno; select A.ename 員工, B.ename 領導 from emp A, emp B where A.mgr = B.empno; /*內連線(自身連線) */ SELECT * FROM emp INNER JOIN dept ON emp.deptno = dept.deptno; select * from emp left join dept on emp.deptno=dept.deptno /*外連線(左連線) */ /* scott.sql並未設定emp表的外來鍵為deptno,故這裡可以插入在dept表中不存在的deptno值*/ /* 主要是為了演示左連線和右連線的區別 */ insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno) values (9999, 'XXXX', 'CLERK', 7782, '1982-01-23', 1300, null, 90); select * from emp right outer join dept on emp.deptno=dept.deptno /* 外連線(右連線) */ select * from emp left join dept on emp.deptno=dept.deptno /* 自然連線會合並deptno一項,而外連線不會 */ SELECT * FROM emp NATURAL JOIN dept; SELECT * FROM emp NATURAL LEFT JOIN dept; SELECT * FROM emp NATURAL RIGHT JOIN dept; |
3.子查詢/any/all./exists
子查詢即一個查詢語句嵌到另一個查詢語句的子句中;可以出現在另一個查詢的列中,where子句中,from子句中等。
<any,小於子查詢中的某個值。等價於<max
>any,大於子查詢中的某個值。等價於>min
>all,大於子查詢中的所有值。等價於>max
<all,小於子查詢中的所有值。等價於<min
exists 存在性條件判斷: 若內層查詢非空,則外層的where子句返回真值,否則返回假。not exists相反。
SQL Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
/* 查詢員工及其領導名稱 */
select A.ename 員工, B.ename 領導 from emp A, emp B where A.mgr = B.empno; /* 子查詢,同上 */ select ename 員工, (select ename from emp where empno = e.mgr) 領導 from emp e; /* 列出所有“CLERK”(辦事員)的姓名及其部門名稱 */ select ename, dname from emp,dept where job='CLERK' and emp.deptno = dept.deptno; /* 子查詢,同上 */ select ename, (select dname from dept where deptno=e.deptno) dname from emp e where job='CLERK' and deptno in (select deptno from dept); /* 子查詢,同上 */ select ename, dname from (select ename, (select dname from dept where deptno=e.deptno) dname from emp e where job='CLERK') a where dname is not null; /* 子查詢,多出deptno=90的行 */ select ename, (select dname from dept where deptno=e.deptno) dname from emp e where job='CLERK'; /* 同上 */ select ename, dname from emp LEFT JOIN dept on emp.deptno = dept.deptno where job='CLERK'; /* 列出薪金比'SMITH'高的員工*/ select * from emp where sal > (select sal from emp where ename='SMITH'); /* 列出受僱日期早於其直接上級的所有員工*/ select * from emp e where hiredate < (select hiredate from emp where empno=e.mgr); /* 查詢薪金小於銷售員某個員工的員工資訊*/ select * from emp WHERE sal < any (select sal from emp where job='SALESMAN'); select * from emp WHERE sal < (select max(sal) from emp where job='SALESMAN'); /* 查詢薪金大於所有銷售員的員工資訊 */ select * from emp WHERE sal > all (select sal from emp where job='SALESMAN'); /* 列出與“SCOTT”從事相同工作的所有員工 */ select * from emp e where EXISTS ( select * from emp where ename='SCOTT' and e.job = job ); select * from emp where job =(select job from emp where ename='SCOTT'); |
4.聚合函式/group by/having/group by與子查詢
聚合函式一般用於統計,常用如下:
count(field) //記錄數avg(field) //平均值min(field) //最小值max(field) //最大值sum(field) //總和
group by/having:分組查詢通常用於統計,一般和聚合函式配合使用
select 分組欄位或聚合函式
from 表
group by 分組欄位 having 條件
order by 欄位
from 表
group by 分組欄位 having 條件
order by 欄位
SQL Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
select count(comm) as 記錄數 from emp; /* 非 NULL 則計數 */
select count(*) as 記錄數 from emp; select count(0) as 記錄數 from emp; select count(empno) as 記錄數 from emp; select avg(sal) as 平均薪金, max(sal) as 最高薪金, min(sal) as 最低薪金, sum(sal) as 薪金總和 from emp; /* 列出各部門各有多少人 */ select deptno, count(*) from emp group by deptno; /* 列出各部門人數大於3的 並按人數降序排列 */ select deptno, count(*) cn from emp group by deptno HAVING cn > 3 ORDER BY cn desc; /* 列出在dept表中出現過的部門各有多少人 */ select *, (select count(*) from emp group by deptno HAVING deptno = dept.deptno) total from dept; /* 如果人數為NULL 賦值為 0 */ select *, ifnull((select count(*) from emp group by deptno HAVING deptno = dept.deptno), 0) total from dept; /* 查詢出薪金成本最高的部門的部門號和部門名稱 */ select dept.deptno, dept.dname from dept, emp where dept.deptno=emp.deptno group by dept.deptno, dept.dname HAVING sum(sal) >= all (select sum(sal) from emp group by deptno); select dept.deptno, dept.dname from dept, emp where dept.deptno=emp.deptno group by dept.deptno, dept.dname HAVING sum(sal) >= ( select max(t.total) from (select sum(sal) total from emp group by deptno) t ); |
select url, get_keys, post_keys, count(distinct url, get_keys, post_keys) from sec_tmp_after_task1_step10 group by url, get_keys, post_keys
select url, get_keys, post_keys, wm_concat(distinct url_source, ",", "asc") as url_source_all from sec_tmp_luascan_task_step1 group by url, get_keys, post_keys
5.MySQL函式
控制流程函式字串函式數值函式日期和時間函式
nowdate_add/adddatedatediffdate_format
聚合函式
SQL Code
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
CASE value WHEN [compare-value] THEN result [WHEN [compare-value] THEN result ...] [ELSE result] END
CASE WHEN [condition] THEN result [WHEN [condition] THEN result ...] [ELSE result] END SELECT CASE 1 WHEN 1 THEN 'one' WHEN 2 THEN 'two' ELSE 'more' END; SELECT CASE WHEN 1>0 THEN 'true' ELSE 'false' END; select a.cgi from ( select case when port=443 then concat('https://', url) else concat('http://', url) as cgi from t_url) a; /* 查詢員工的薪金等級 */ select ename 員工, sal 薪金, case grade when 1 then '一級' when 2 then '二級' when 3 then '三級' when 4 then '四級' when 5 then '五級' end 等級 from emp, salgrade where sal between losal and hisal; SELECT ASCII('2a'); SELECT ASCII('a2'); SELECT BIN(12); SELECT BIT_LENGTH('text'); SELECT CHAR(77,121,83,81,'76'); SELECT CHAR(77,121,83,81,76); SELECT 3+5; SELECT 3/5; SELECT ABS(-32); select now(); SELECT DATE_ADD('1998-02-02', INTERVAL 31 DAY); SELECT DATE_ADD('1998-02-02', INTERVAL 28 DAY); SELECT adddate('1998-02-02', INTERVAL 28 DAY); SELECT adddate('1998-02-02', 28); select DATEDIFF(now(),'2014-02-01'); select DATEDIFF('2014-02-01','2014-03-01'); select DATE_FORMAT(now(), '%H:%i:%s'); select DATE_FORMAT(now(), '%Y%M%D'); select DATE_FORMAT(now(), '%Y%m%d'); |
工作中常用的時間函式還有 time_to_sec, date_format, str_to_date, addtime, timestampdiff 等,注意 NULL 資料做什麼運算結果都是NULL,不為真,為此可以用 ifnull(exp1, exp2) 指定預設值。
參考:
《資料庫系統概論》
mysql 5.1 參考手冊
《資料庫系統概論》
mysql 5.1 參考手冊
相關文章
- MySQL(三) 資料庫表的查詢操作【重要】MySql資料庫
- Oracle資料庫開發——表(資料完整性約束)Oracle資料庫
- 資料完整性約束:主鍵、外來鍵、各種約束的建立刪除語句
- [求助][資料庫]表間約束的刪除完整性?資料庫
- mysql資料庫操作之------查的各種小細節MySql資料庫
- mysql資料庫連表查詢的幾種方法MySql資料庫
- 資料庫學習(三)基本查詢資料庫
- MySQL之完整性約束MySql
- mysql 各種級聯查詢後更新(update select).MySql
- MySQL——表的約束,資料型別,增刪查改MySql資料型別
- MySQL學習筆記4:完整性約束限制欄位MySql筆記
- 查詢MySQL資料庫,MySQL表的大小MySql資料庫
- mysql~資料完整性考慮~外來鍵約束MySql
- 資料庫系統之實體完整性約束資料庫
- 資料庫學習筆記之查詢表資料庫筆記
- MySql、SqlServer、Oracle 三種資料庫查詢分頁方式MySqlServerOracle資料庫
- 查詢oracle表的資訊(表,欄位,約束,索引)Oracle索引
- SQL Server實戰三:資料庫表完整性約束及索引、檢視的建立、編輯與刪除SQLServer資料庫索引
- 南大通用GBase 8s資料庫的約束查詢資料庫
- sql: 查詢約束SQL
- 【從零開始學習 MySql 資料庫】(5) 約束檢視與索引MySql資料庫索引
- Golang 學習寶庫,各種資料收集Golang
- 各種學習資料
- 資料庫學習與複習筆記--資料庫概念和不同類資料庫CRUD操作(1)資料庫筆記
- python資料庫-MySQL資料庫高階查詢操作(51)Python資料庫MySql
- 【從零開始學習 MySql 資料庫】(1) 建表與簡單查詢MySql資料庫
- mysql三表關聯查詢練習MySql
- MySQL查詢資料庫中沒有主鍵的表MySql資料庫
- MySQL資料庫學習筆記02(事務控制,資料查詢)MySql資料庫筆記
- 資料庫學習(五)子查詢資料庫
- mysql 資料庫或者表空間使用查詢MySql資料庫
- MySQL資料庫:6、約束的概述及語法MySql資料庫
- 查詢emp表上的所有約束的詳細資訊
- 資料庫常用約束資料庫
- MySQL學習(三) SQL基礎查詢MySql
- 資料庫約束有什麼作用?linux運維工程師MySQL學習資料庫Linux運維工程師MySql
- 資料庫學習(四)連線查詢資料庫
- mysql查詢表的資料體積MySql