序言
2、MySQL的資料型別(CHAR、VARCHAR、BLOB,等),
本節比較重要,對資料表資料進行查詢操作,其中可能大家不熟悉的就對於INNER JOIN(內連線)、LEFT JOIN(左連線)、RIGHT JOIN(右連線)等一些複雜查詢。 通過本節的學習,可以讓你知道這些基本的複雜查詢是怎麼實現的,但是建議還是需要多動手去敲,雖然理解了什麼是內連線等,但是從理解到學會,是完全不一樣的感覺。
--WH
一、單表查詢
1.1、查詢所有欄位
1.2、查詢指定欄位
1.3、查詢指定記錄
1.4、帶IN關鍵字的查詢
1.5、帶BETWEEN AND 的範圍查詢
1.6、帶LIKE的字元匹配查詢
1.7、查詢空值
1.8、帶AND的多條件查詢
1.9、帶OR的多條件查詢
1.10、關鍵字DISTINCT(查詢結果不重複)
1.11、對查詢結果排序
1.12、分組查詢(GROUP BY)
1.13、使用LIMIT限制查詢結果的數量
集合函式查詢
1.14、COUNT()函式
1.15、SUM()函式
1.16、AVG()函式
1.17、MAX()函式
1.18、MIN()函式
二、多表查詢
小知識
為表取別名
為欄位取別名
基於兩張表
2.1、普通雙表連線查詢
2.2、內連線查詢
2.3、外連線查詢
2.3.1、左外連線查詢
2.3.2、右外連線查詢
2.4、複合條件連線查詢
子查詢
2.5、帶ANY、SOME關鍵字的子查詢
2.6、帶ALL關鍵字的子查詢
2.7、帶EXISTS關鍵字的子查詢
2.8、帶IN關鍵字的子查詢
2.9、帶比較運算子的子查詢
合併結果查詢
2.10、UNION[ALL]的使用
三、使用正規表示式查詢
3.1、查詢以特定字元或字串開頭的記錄
3.2、查詢以特定字元或字串結尾的記錄
3.3、用符號"."來替代字串中的任意一個字元
3.4、使用"*"和"+"來匹配多個字元
3.5、匹配指定字串
3.6、匹配指定字元中的任意一個
3.7、匹配指定字元以外的字元
3.8、使用{n,}或者{n,m}來指定字串連續出現的次數
四、綜合案例 練習資料表查詢操作
4.1、搭建環境
省略
4.2、查詢操作
省略
4.3、在已經建立好的employee表中進行如下操作
4.3.1、計算所有女員工(F)的年齡
4.3.2、使用LIMIT查詢從第3條記錄開始到第六條記錄
4.3.3、查詢銷售人員(SALSEMAN)的最低工資
4.3.4、查詢名字以字母N或者S結尾的記錄
4.3.5、查詢在BeiJing工作的員工的姓名和職務
4.3.6、使用左連線方式查詢employee和dept表
4.3.7、查詢所有2001~2005年入職的員工的資訊,查詢部門編號為20和30的員工資訊並使用UNION合併兩個查詢結果
4.3.8、使用LIKE查詢員工姓名中包含字母a的記錄
4.3.9、使用REGEXP查詢員工姓名中包含T、C或者M 3個字母中任意1個的記錄
想直接做題的,跳過講解,直接到練習區。
這張講解的目錄就是想上面這樣,可以直接看自己感興趣的部分,而不用從最基礎的看起,接下來就一步步實現這上面龐大的工作量了。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
一、單表查詢
建立查詢環境
CREATE TABLE fruits(
f_id CHAR(10) NOT NULL,
s_id INT NOT NULL,
f_name char(255) NOT NULL,
f_price DECIMAL(8,2) NOT NULL,
PRIMARY KEY(f_id)
);
解釋:
f_id:主鍵 使用的是CHAR型別的字元來代表主鍵
s_id:這個其實是批發商的編號,也就是代表該水果是從哪個批發商那裡過來的,寫這個欄位的目的是為了方便後面擴增表。
f_name:水果的名字
f_price:水果的價格,使用的是DECIMAL這個資料型別,如果不清楚這個型別去檢視一下上面一篇講解資料型別的文章。
新增資料。
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES
('a1' , 101 , 'apple' , 5.2),
('b1' , 101 , 'blackberry' , 10.2),
('bs1' , 102 , 'orange' , 11.2),
('bs2' , 105 , 'melon' , 8.2),
('t1' , 102 , 'banana' , 10.3),
('t2' , 102 , 'grape' , 5.3),
('o2' , 103 , 'coconut' , 9.2),
('c0' , 101 , 'cherry' , 3.2),
('a2' , 103 , 'apricot' , 2.2),
('l2' , 104 , 'lemon' , 6.4),
('b2' , 104 , 'berry' , 7.6),
('m1' , 106, 'mango' , 15.6),
('m2' , 105 , 'xbabay' , 2.6),
('t4' , 107, 'xbababa' , 3.6),
('m3' , 105 , 'xxtt' , 11.6),
('b5' , 107, 'xxxx' , 3.6 );
blackberry:黑莓 melon:甜瓜 grape:葡萄 coconut:椰子 cherry:櫻桃 apricot:杏子 berry:漿果 mango:芒果 後面幾個xbabay都是為了測試所編寫的,沒有實際意義。
注意:在複製我的程式碼到cmd視窗時,應注意語句之間不能有空格,不然會報錯,我這裡是為了使你們觀看更清楚,所以每行前面度加有空格,
1.1、查詢所有欄位
SELECT * FROM fruits;
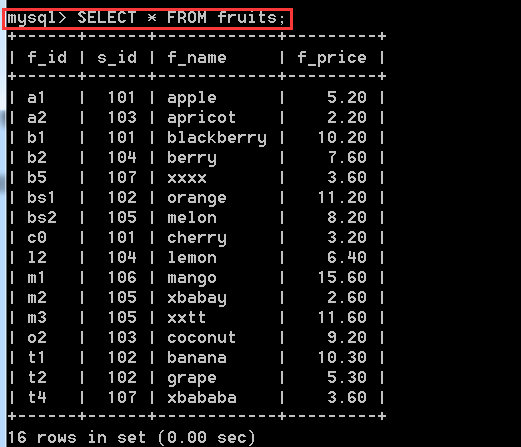
解釋:* 代表所有欄位,也就是從表中將所有欄位下面的記錄度查詢出來
1.2、查詢指定欄位
查詢f_name 和 f_price 欄位的記錄
SELECT f_name, f_price FROM fruits;
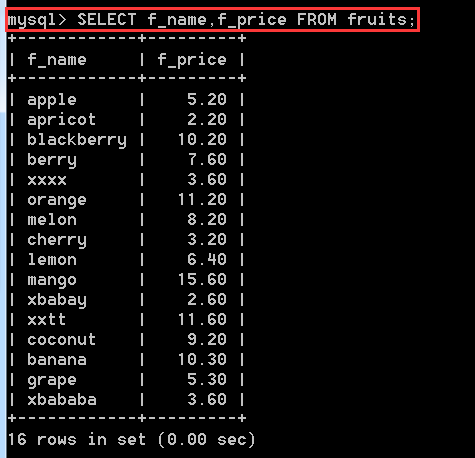
1.3、查詢指定記錄
指定記錄:也就是按條件進行查詢,將滿足一定條件的記錄給查詢出來,使用WHERE關鍵字
SELECT * FROM fruits WHERE f_name = 'apple'; //將名為apple的記錄的所有資訊度查詢出來
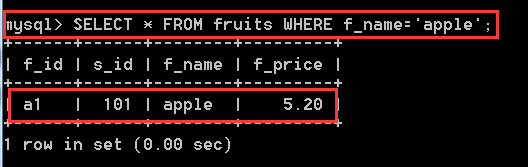
SELECT * FROM fruits WHERE f_price > 15; //將價格大於15的記錄的所有欄位 查詢出來
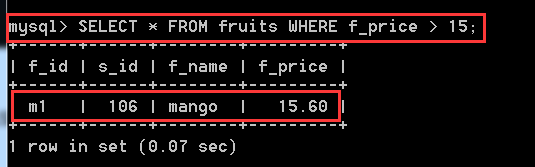
1.4、帶IN關鍵字的查詢
IN關鍵字:IN(xx,yy,...) 滿足條件範圍內的一個值即為匹配項
SELECT * FROM fruits WHERE f_name IN('apple','orange');
SELECT * FROM fruits WHERE s_id IN(101, 105); //s_id 為101 或者 105 的記錄
SELECT * FROM fruits WHERE s_id NOT IN(101,105); //s_id 不為101或者105的記錄
1.5、帶BETWEEN AND 的範圍查詢
BETWEEN ... AND ... : 在...到...範圍內的值即為匹配項,
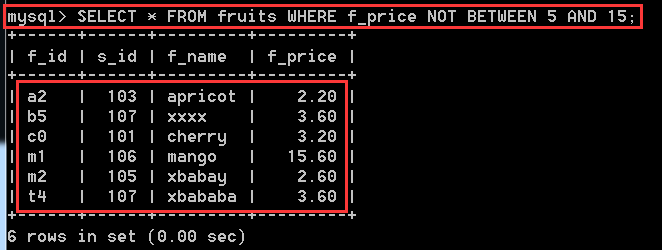
SELECT * FROM fruits WHERE f_price BETWEEN 5 AND 15; //f_price 在5到15之間,包括5和15。
SELECT * FROM fruits WHERE f_price NOT BETWEEN 5 AND 15; //f_price 不在5到15之間。
1.6、帶LIKE的字元匹配查詢
LIKE: 相當於模糊查詢,和LIKE一起使用的萬用字元有 "%"、"_"
"%":作用是能匹配任意長度的字元。
"_":只能匹配任意一個字元
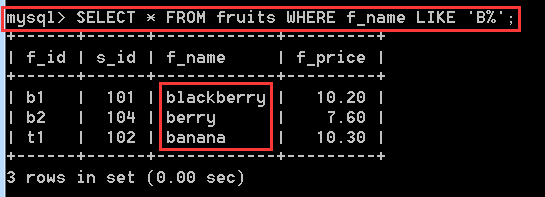
SELECT * FROM fruits WHERE f_name LIKE 'b%'; //f_name以b字母開頭的所有記錄
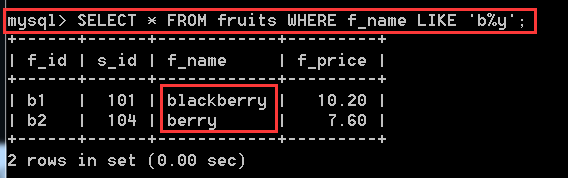
SELECT * FROM fruits WHERE f_name LIKE 'b%y'; //f_name以b字母開頭,y字母結尾的所有記錄
SELECT * FROM fruits WHERE f_name LIKE '____y'; //此處有四個_,說明要查詢以y字母結尾並且y之前只有四個字元的記錄

總結:'%'和'_'可以在任意位置使用,只需要記住%能夠表示任意個字元,_只能表示一個任意字元
1.7、查詢空值
空值不是指為空字串""或者0,一般表示資料未知或者在以後在新增資料,也就是在新增資料時,其欄位上預設為NULL,也就是說,如果該欄位上不插入任何值,就為NULL。此時就可以查詢出來。
SELECT * FROM 表名 WHERE 欄位名 IS NULL; //查詢欄位名是NULL的記錄
SELECT * FROM 表名 WHERE 欄位名 IS NOT NULL; //查詢欄位名不是NULL的記錄
這裡由於沒有合適的資料,就不自己在建立表,新增資料,然後來測試這條語句了,很簡單,看一下就應該懂了
1.8、帶AND的多條件查詢
AND: 相當於"邏輯與",也就是說要同時滿足條件才算匹配
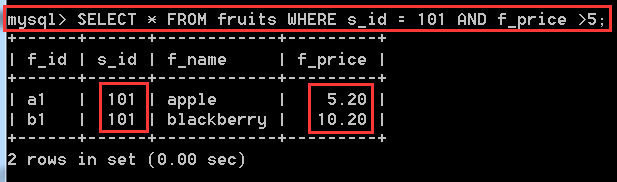
SELECT * FROM fruits WHERE s_id = 101 AND f_price > 5; //同時滿足s_id = 101、f_price >5 這兩個條件才算匹配。
1.9、帶OR的多條件查詢
OR: 相當於"邏輯或",也就是說只要滿足其中一個條件,就算匹配上了,跟IN關鍵字效果差不多
SELECT * FROM fruits WHERE s_id = 101 OR f_price > 10; //s_id =101 或者 f_price >10 ,只要符合其中一個條件,就算匹配
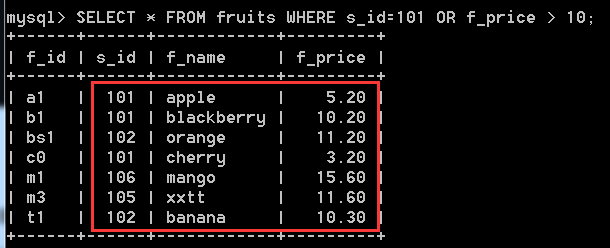
可以看到,查詢出來的記錄,f_price有低於10的,那麼其肯定s_id=101,s_id不等於101的,其f_price肯定大於10,這就說明了OR的效果。只要滿足其中一個條件,就算匹配。
1.10、關鍵字DISTINCT(查詢結果不重複)
SELECT s_id FROM fruits; //查詢所有的s_id,會出現很多重複的值。
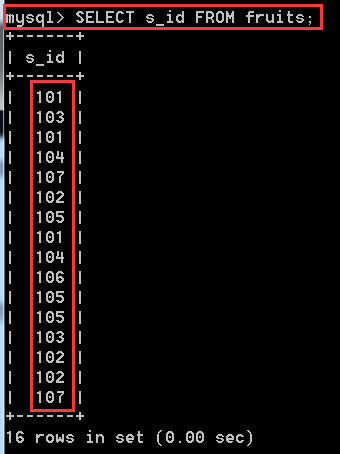
使用DISTINCT就能消除重複的值
SELECT DISTINCT s_id FROM fruits;
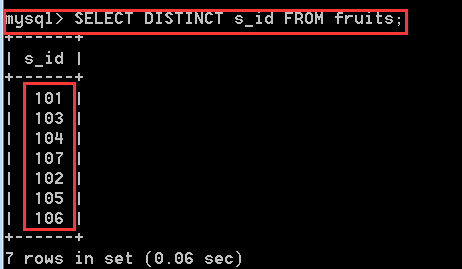
將重複的值刪除後,就只留下7條記錄了。
1.11、對查詢結果排序(ORDER BY)
看上面輸出的值沒順序,可以給他們進行排序。使用關鍵字 ORDER BY,有兩個值供選擇 DESC 降序 、 ASC 升序(預設值)
SELECT DISTINCT s_id FROM fruits ORDER BY s_id; //預設就是升序,

SELECT DISTINCT s_id FROM fruits ORDER BY s_id DESC; //使用降序,也就是從高到底排列
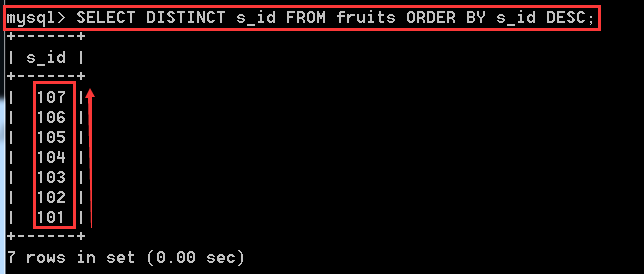
1.12、分組查詢(GROUP BY)
分組查詢很多人不知道什麼意思,一開始我也是很蒙圈的,所以沒關係,一起來看看。
分組查詢就是將相同的東西分到一個組裡面去,現實生活中舉個例子,廁所分男女,這也是一個分組的應用,在還沒有分男女廁所前,大家度共用廁所,後面通過分男女性別,男的跟男的分為一組,女的和女的分為一組,就這樣分為了男女廁所了。這就是分組的意思, 在上面對s_id進行查詢的時候,發現很多重複的值,我們也就可以對它進行分組,將相同的值分為一組,
SELECT s_id FROM fruits GROUP BY s_id; //將s_id進行分組,有實際意義,按批發商進行分組,從101批發商這裡拿的水果度會放在101這個組中
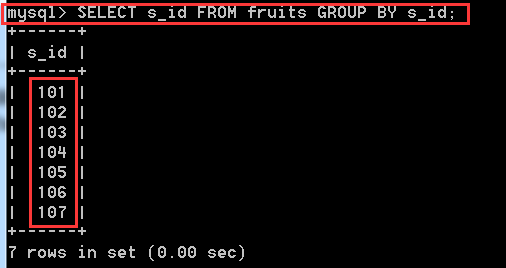
解釋:將s_id分組後,就沒有重複的值了,因為重複的度被分到一個組中去了,現在在來看看每個組中有多少個值
SELECT s_id, COUNT(f_name), GROUP_CONCAT(f_name) FROM fruits GROUP BY s_id;
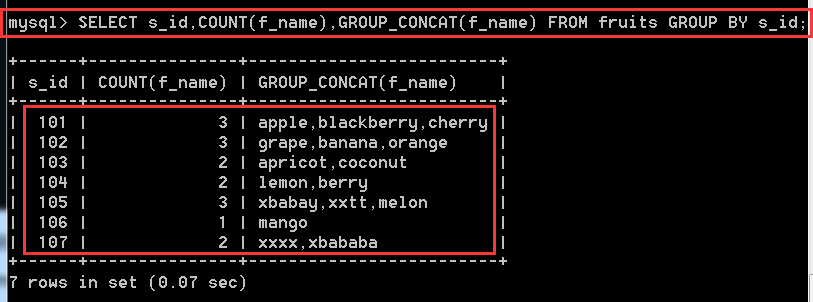
解釋:
COUNT():這個是下面要講解到的一個函式,作用就是計算有多少條記錄,
GROUP_CONCAT(): 將分組中的各個欄位的值顯示出來
SELECT s_id, COUNT(f_name), GROUP_CONCAT(f_name), GROUP_CONCAT(f_price) FROM fruits GROUP BY s_id;
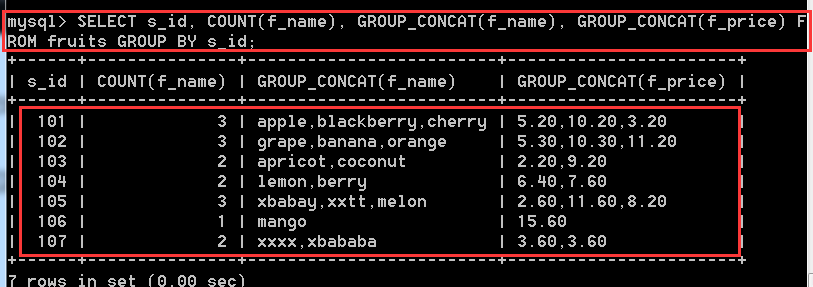
分組之後還可以進行條件過濾,將不想要的分組丟棄,使用關鍵字 HAVING
SELECT s_id,COUNT(f_name),GROUP_CONCAT(f_name) FROM fruits GROUP BY s_id HAVING COUNT(f_name) > 1;//他能夠過s_id分組,然後過濾出水果種類大於1的分組資訊。
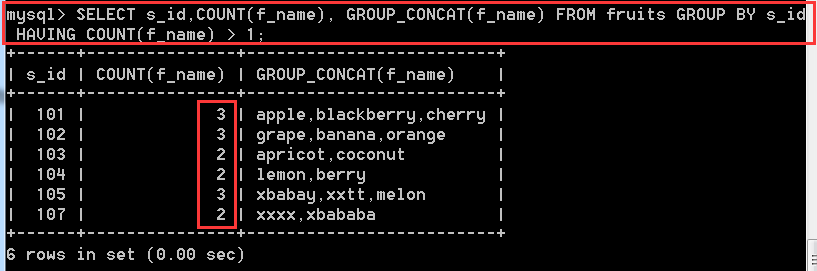
總結:
知道GROUP BY的意義,並且會使用HAVING對分組進行過濾, HAVING和WHERE都是進行條件過濾的,區別就在於 WHERE 是在分組之前進行過濾,而HAVING是在分組之後進行條件過濾。
1.13、使用LIMIT限制查詢結果的數量
LIMIT[位置偏移量] 行數 通過LIMIT可以選擇資料庫表中的任意行數,也就是不用從第一條記錄開始遍歷,可以直接拿到 第5條到第10條的記錄,也可以直接拿到第12到第15條的記錄。 具體看下面例子
SELECT * FROM fruits LIMIT 4; //沒有寫位置偏移量,預設就是0,也就是從第一條開始,往後取4條資料,也就是取了第一條資料到第4條的資料。
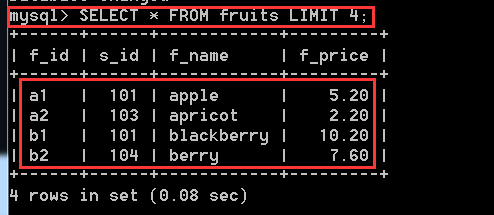
SELECT * FROM fruits LIMIT 4,3; //從第5條資料開始,往後取3條資料,也就是從第5條到第8條
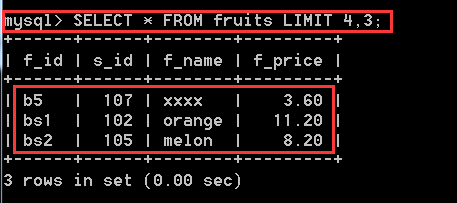
注意:LIMIT的第一個引數不寫預設就是0,也就是說,第一條記錄的索引是0,從0開始的,第二個引數的意思是取多少行的記錄,需要這兩個才能確定一個取記錄的範圍
集合函式查詢
1.14、COUNT()函式
這個函式在上面其實用過,作用是統計資料表中包含的記錄行的總數,或者根據查詢結果返回列中包含的資料行數,
COUNT(*):計算表中的總的行數,不管某列有數值或者為空值,因為*就是代表查詢表中所有的資料行
COUNT(欄位名):計算該欄位名下總的行數,計算時會忽略空值的行,也就是NULL值的行。
SELECT COUNT(*) FROM fruits;
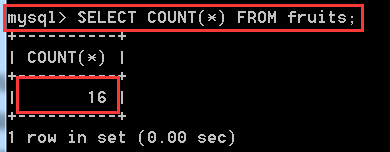
SELECT COUNT(f_name) FROM fruits; //查詢fruits表中f_name欄位名下有多少個行數,
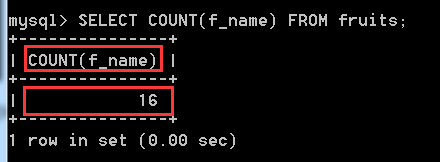
沒有空值,所以計算出來的行數和總的記錄行數是一樣的。
1.15、SUM()函式
SUM()是一個求總和的函式,返回指定列值的總和
SELECT SUM(f_price) FROM fruits; //這個沒有實際的意義,只是測試SUM()函式有求總和的能力
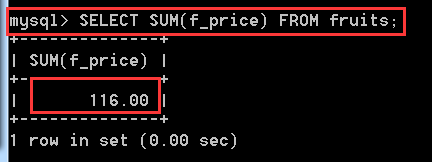
如果有人覺得這個測試的不準,可以手動去加一下所有的f_price。然後來進行對比,反正我是信了。
1.16、AVG()函式
AVG()函式通過計算返回的行數和每一行資料的和,求的指定列資料的平均值(列資料指的就是欄位名下的資料,不要搞不清楚列和行,搞不清就對著一張表搞清楚哪個是列哪個是行),通俗點講,就是將計算得來的總之除以總的記錄數,得出一個平均值,
SELECT AVG(f_price) FROM fruits;
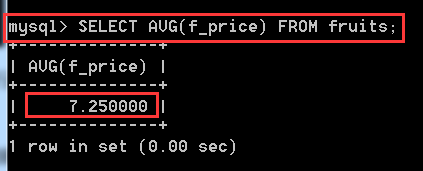
就相當於 116/16 = 7.25
1.17、MAX()函式
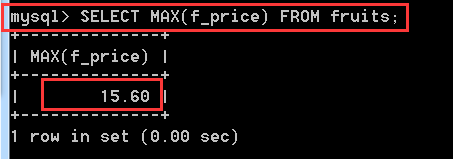
MAX()返回指定列中的最大值
SELECT MAX(f_price) FROM fruits;
1.18、MIN()函式
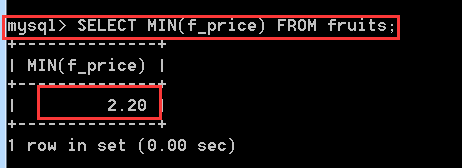
MIN()返回查詢列中的最小值
SELECT MIN(f_price) FROM fruits;
二、多表查詢
小知識
為表取別名
因為是對兩張表進行查詢了,那麼每次寫表名的話就有點麻煩,所以用一個簡單別名來代表表名
格式:表名 AS 別名
在下面的例子中會用的到,到時候不要不認識
為欄位取別名
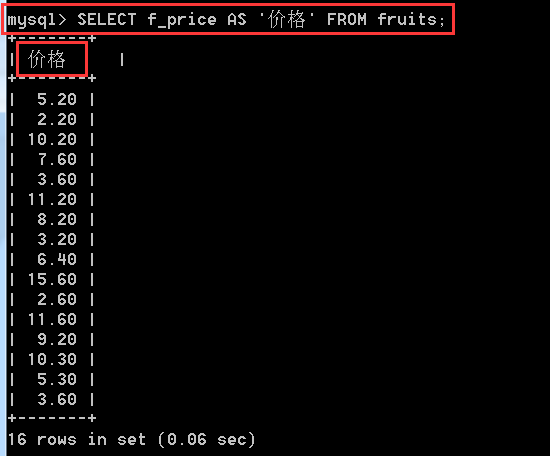
給欄位名取別名的原因是有些欄位名是為了顯示更加清楚,比如
SELECT f_price AS '價格' FROM fruits;
語句執行順序問題
一、sql執行順序 、
(1)from
(2) on
(3) join
(4) where
(5)group by
(6) avg,sum....
(7)having
(8) select
(9) distinct
(10) order by
也就是說,我們每次執行的SQL語句,都是從FROM開始的。
基於兩張表
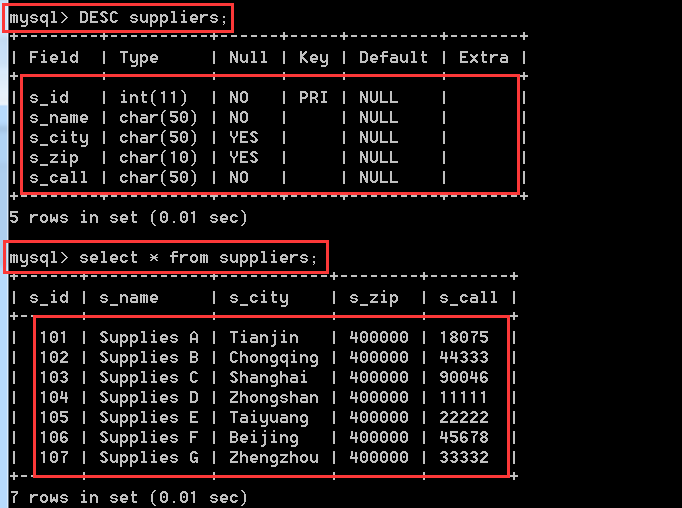
搭建查詢環境,前面已經有一張表了,現在在增加一張suppliers(供應商)表和前面哪個fruits表建立練習,也就是說 讓fruits中s_id欄位值指向suppliers的主鍵值,建立一個外來鍵約束關係。
CREATE TABLE suppliers
(
s_id INT NOT NULL,
s_name CHAR(50) NOT NULL,
s_city CHAR(50) NULL,
s_zip CHAR(10) NULL,
s_call CHAR(50) NOT NULL,
PRIMARY KEY(s_id)
);
其實這裡並沒有達到真正的外來鍵約束關係,只是模擬,讓fruits中的s_id中的值 能匹配到 suppliers 中的主鍵值,通過手動新增這種資料,來達到這種關係,反正是死資料,也不在新增別的資料,就不用建立外來鍵約束關係了,這裡要搞清楚
INSERT INTO suppliers(s_id,s_name,s_city,s_zip,s_call)
VALUES
(101,'Supplies A','Tianjin','400000','18075'),
(102,'Supplies B','Chongqing','400000','44333'),
(103,'Supplies C','Shanghai','400000','90046'),
(104,'Supplies D','Zhongshan','400000','11111'),
(105,'Supplies E','Taiyuang','400000','22222'),
(106,'Supplies F','Beijing','400000','45678'),
(107,'Supplies G','Zhengzhou','400000','33332');
2.1、普通雙表連線查詢
問題:查詢水果的批發商編號,批發商名字,水果名稱,水果價格
分析:看下要求,就知道要查詢兩張表,如果需要查詢兩張表,那麼兩張表的關係必定是外來鍵關係,或者類似於外來鍵關係(類似於也就是說兩張表並沒有真正加外來鍵約束,但是其特點和外來鍵是一樣的,就像上面我們手動建立的兩張表一樣,雖然沒有設定外來鍵關聯關係,但是其特性跟外來鍵關係是一樣的。)
SELECT s.s_id,s.s_name,f.f_name,f.f_price FROM fruits AS f, suppliers AS s WHERE f.s_id = s.s_id;
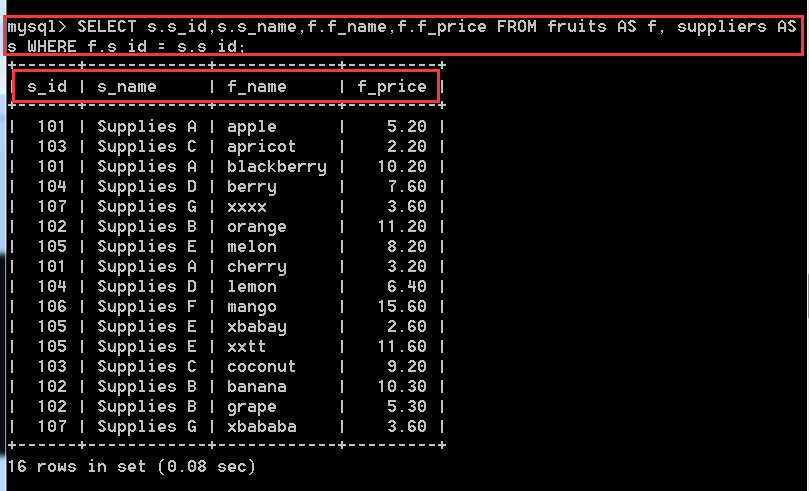
解釋:這裡使用了表別名,並且這裡是連線兩張表的關係是在於 fruits中的s_id 等於 suppliers中的s_id。 這個大家度能理解把,也就是水果中記錄了批發商的編號,通過該編號就能在suppliers表中找到對應的批發商的詳細資訊,就這樣,兩張表就聯絡起來了。
注意:第一個執行的是FROM,所以上面為表取別名,在語句的任何地方的可以使用。
2.2、內連線查詢
知道了上面兩張表基本的連線查詢後,內連線查詢就很簡單了,因為內連線跟上面的作用是一樣的,唯一的區別就是語法的不一樣
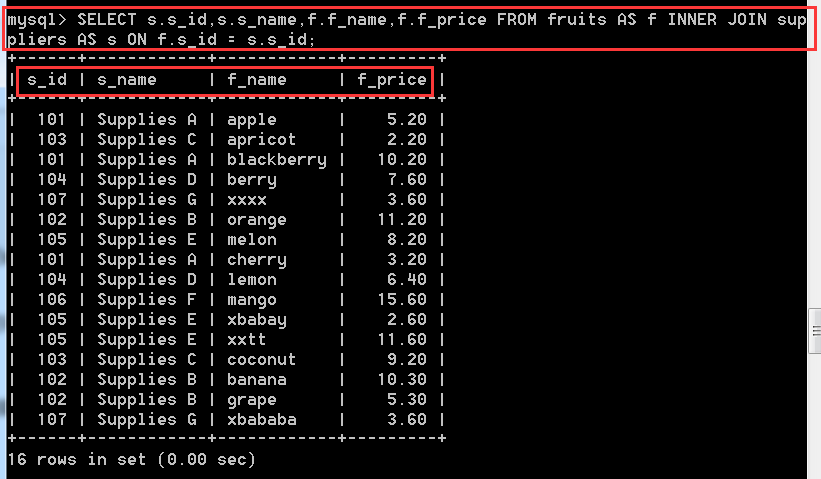
格式:表名 INNER JOIN 表名 ON 連線條件
問題:查詢水果的批發商編號,批發商名字,水果名稱,水果價格
SELECT s.s_id,s.s_name,f.f_name,f.f_price
FROM fruits AS f INNER JOIN suppliers AS s
ON f.s_id = s.s_id;
不知道這樣寫sql語句會不會讓你們看的更清楚
還需要知道一個特殊一點的東西,那就是自連線查詢,什麼是自連線查詢?就是涉及到的兩張表都是同一張表。
問題:查詢供應f_id='a1'的水果供應商提供的其他水果種類?
SELECT f2.f_id,f2.f_name
FROM fruits AS f1 INNER JOIN fruits AS f2
ON f1.s_id = f2.s_id AND f1.f_id = 'a1';
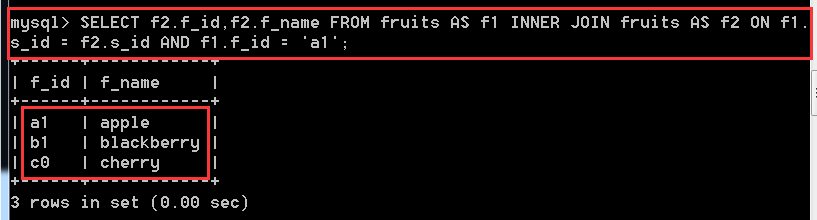
解釋:把fruits表分開看成是兩張完全一樣的表,在f1表中找到f_id='a1'的s_id,然後到f2這張表中去查詢和該s_id相等的記錄,也就查詢出來了問題所需要的結果。還有另一種方法,不用內連線查詢,通過子查詢也可以做到,下面會講解,這裡先給出答案,到時可以回過頭來看看這個題。
SELECT f_id,f_name
FROM fruits
WHERE s_id = (SELECT s_id FROM fruits WHERE f_id='a1');
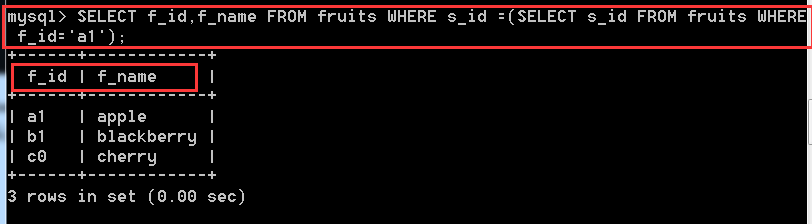
效果和內連線是一樣的,其實原理度是一樣的,還是藉助的兩張表,只是這個更容易讓人理解,可以通過這個來去理解上面那個自連線查詢。
2.3、外連線查詢
內連線是將符合查詢條件(符合連線條件)的行返回,也就是相關聯的行就返回。
外連線除了返回相關聯的行之外,將沒有關聯的行也會顯示出來。
為什麼需要將不沒關聯的行也顯示出來呢?這就要根據不同的業務需求了,就比如,order和customers,顧客可以有訂單也可以沒訂單,現在需要知道所有顧客的下單情況,而我們不能夠只查詢出有訂單的使用者,而把沒訂單的使用者丟在一邊不顯示,這個就跟我們的業務需求不相符了,有人說,既然知道了有訂單的顧客,通過單表查詢出來不包含這些有訂單顧客,不就能達到我們的要求嗎,這樣是可以,但是很麻煩,如何能夠將其一起顯示並且不那麼麻煩呢?為了解決這個問題,就有了外連線查詢這個東西了。
2.3.1、左外連線查詢
格式: 表名 LEFT JOIN 表名 ON 條件; 返回包括左表中的所有記錄和右表中連線欄位相等的記錄,通俗點講,就是除了顯示相關聯的行,還會將左表中的所有記錄行度顯示出來。用例子來展示一下所說效果把。
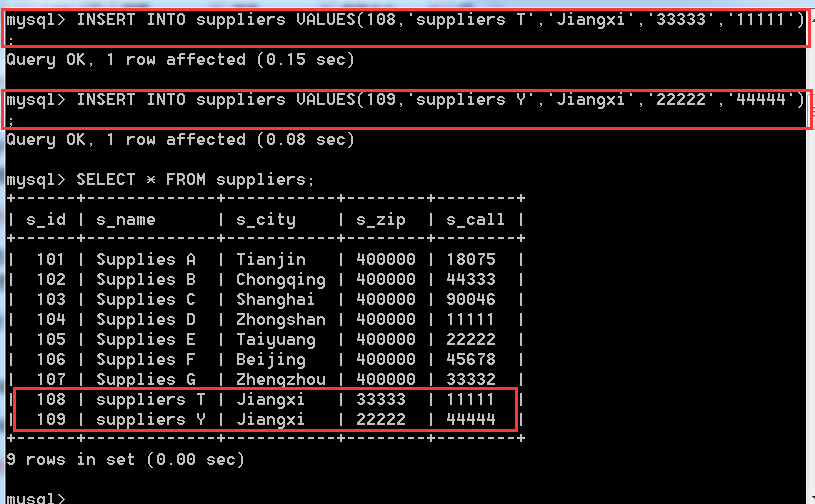
由於上面我們所用到的fruits和suppliers中的記錄都是設計好的,並沒有哪個供應商沒有提供水果,現在為了體現左外連線的效果,在suppliers中增加兩條記錄,fruits中並沒有對應這兩條記錄得水果資訊,
INSERT INTO suppliers VALUES(108,'suppliers T','Jiangxi','33333','11111');
INSERT INTO suppliers VALUES(109,'suppliers Y','Jiangxi','22222','44444');
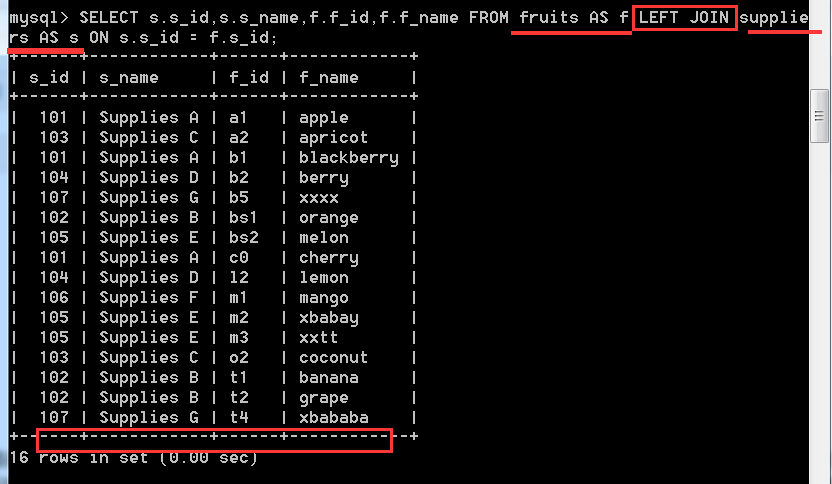
SELECT s.s_id,s.s_name,f.f_id,f.f_name
FROM suppliers AS s LEFT JOIN fruits AS f
ON s.s_id = f.s_id;
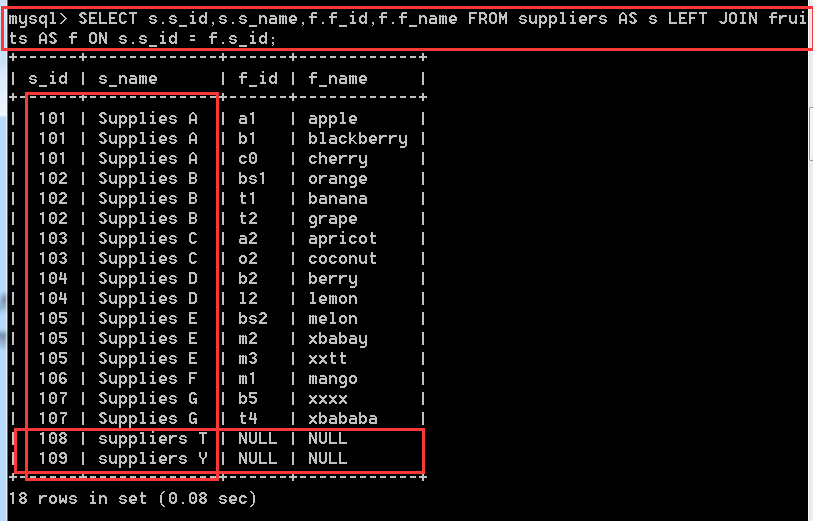
解釋:
suppliers表是在LEFT JOIN的左邊,所以將其中所有記錄度顯示出來了,有關聯項的,也有沒有關聯項的。這就是左外連線的意思,將左邊的表所有記錄都顯示出來(前提是按照我們所需要的欄位,也就是SELECT 後面所選擇的欄位)。如果將suppliers表放LEFT JOIN的右邊,那麼就不會在顯示108和109這兩條記錄了。來看看
SELECT s.s_id,s.s_name,f.f_id,f.f_name
FROM fruits AS f LEFT JOIN suppliers AS s
ON s.s_id = f.s_id;
2.3.2、右外連線查詢
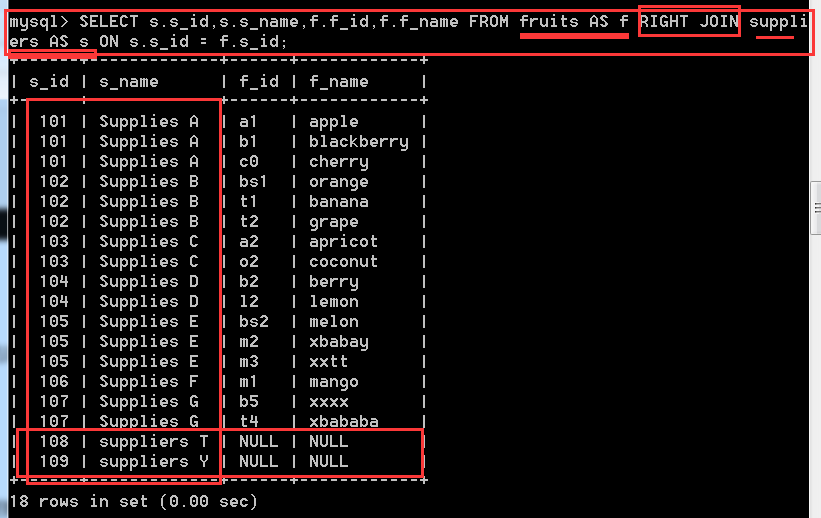
格式: 表名 RIGHT JOIN 表名 ON 條件 返回包括右表中的所有記錄和右表中連線欄位相等的記錄
其實跟左外連線差不多,就是將右邊的表給全部顯示出來
SELECT s.s_id,s.s_name,f.f_id,f.f_name
FROM fruits AS f RIGHT JOIN suppliers AS s
ON s.s_id = f.s_id; //這條語句出來的結果是跟上面左外連線一樣,就是調換了一下位置,其實效果還是一樣的。
注意:
LEFT JOIN 和 RIGHT JOIN這只是一種寫法,其中還有另一種寫法 LEFT OUTER JOIN 和 RIGHT OUTER JOIN .
一般寫這種複雜查詢的時候,寫sql語句的順序應該是先從FROM
2.4、複合條件連線查詢
在連線查詢(內連線、外連線)的過程中,通過新增過濾條件,限制查詢的結果,使查詢的結果更加準確,通俗點講,就是將連線查詢時的條件更加細化。
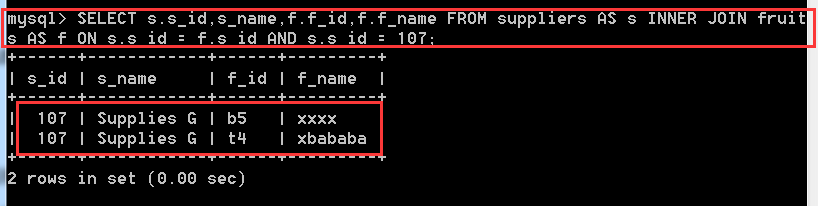
問題一:在fruits和suppliers表中使用INNER JOIN語法查詢suppliers表中s_id為107的供應商的供貨資訊?
SELECT s.s_id,s.s_name,f.f_id,f.f_name
FROM suppliers AS s INNER JOIN fruits AS f
ON s.s_id = f.s_id AND s.s_id = 107;
問題二:在fruits表和suppliers表之間,使用INNER JOIN語法進行內連線查詢,並對查詢結果進行排序
SELECT s.s_id,s.s_name,f.f_id,f.f_name
FROM suppliers AS s INNER JOIN fruits AS f
ON s.s_id = f.s_id
ORDER BY f.s_id; //對f.s_id進行升序。預設的是ASC,所以不用寫。
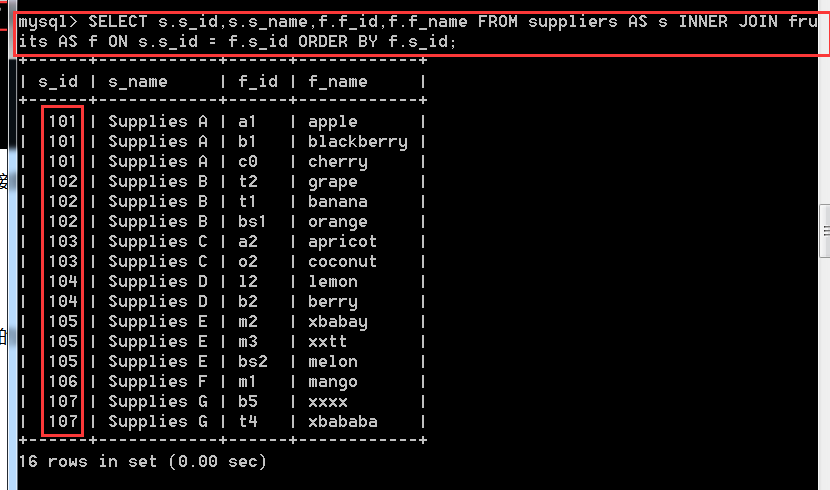
對f.s_id進行排序其實也就是對s.s_id進行排序,效果是一樣的,因為條件就是f.s_id=s.s_id。
子查詢
子查詢,將查詢一張表得到的結果來充當另一個查詢的條件,這樣巢狀的查詢就稱為子查詢
2.5、帶ANY、SOME關鍵字的子查詢
搭建環境
CREATE TABLE tb11 (num1 INT NOT NULL);
CREATE TABLE tb12 (num2 INT NOT NULL);
INSERT INTO tb11 VALUES(1),(5),(13),(27);
INSERT INTO tb12 VALUES(6),(14),(11),(20);
ANY關鍵字接在一個比較操作符的後面,表示若與子查詢返回的任何值比較為TRUE,則返回TRUE,通俗點講,只要滿足任意一個條件,就返回TRUE。
SELECT num1 FROM tb11 WHERE num1 > ANY(SELECT num2 FROM tb12);//這裡就是將在tb12表中查詢的結果放在前一個查詢語句中充當條件引數。只要num1大於其結果中的任意一個數,那麼就算匹配。
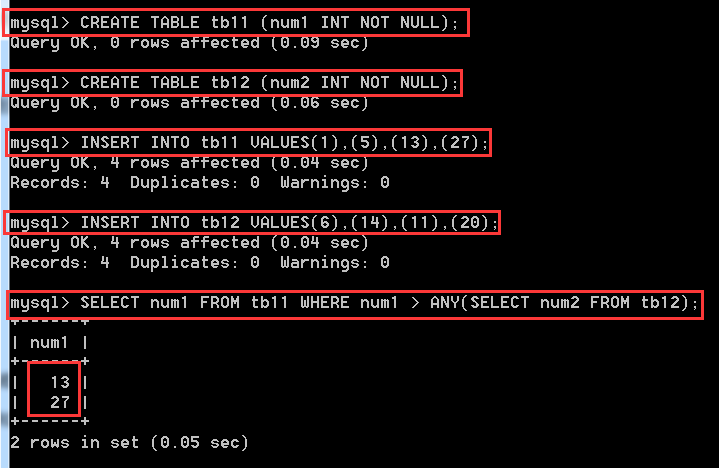
SOME關鍵字和ANY關鍵字的用法一樣,作用也相同,這裡不做多講解了。
2.6、帶ALL關鍵字的子查詢
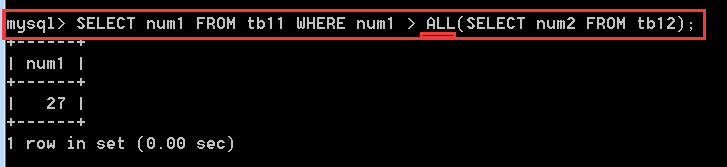
使用ALL時表示需要同時滿足所有條件。
SELECT num1 FROM tb11 WHERE num1 > ALL(SELECT num2 FROM tb12); //num1需要大於所有的查詢結果才算匹配
2.7、帶EXISTS關鍵字的子查詢
EXISTS關鍵字後面的引數是任意一個子查詢,如果子查詢有返回記錄行,則為TRUE,外層查詢語句將會進行查詢,如果子查詢沒有返回任何記錄行,則為FALSE,外層查詢語句將不會進行查詢。
SLEECT * FROM tb11 WHERE EXISTS(SELECT * FROM tb12 WHERE num2 = 3); //查詢tb12中有沒有num2=3的記錄,有的話則會將tb11的所有記錄查詢出來,沒有的話,不做查詢
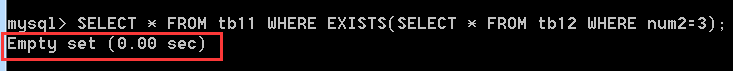
2.8、帶IN關鍵字的子查詢
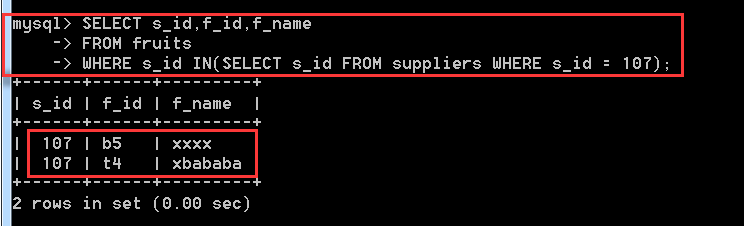
這個IN關鍵字的作用跟上面單表查詢的IN是一樣的,不過這裡IN中的引數放的是一個子查詢語句。
SELECT s_id,f_id,f_name
FROM fruits
WHERE s_id IN(SELECT s_id FROM suppliers WHERE s_id = 107);
2.9、帶比較運算子的子查詢
除了使用關鍵字ALL、ANY、SOME等之外,還可以使用普通的比較運算子。來進行比較。比如我們上面講解內連線查詢的時候,就用過子查詢語句,並且還是用的=這個比較運算子,這裡就不做多解釋了,可以往上面看一下
合併結果查詢
利用UNION關鍵字,可以將查詢出的結果合併到一張結果集中,也就是通過UNION關鍵字將多條SELECT語句連線起來,注意,合併結果集,只是增加了表中的記錄,並不是將表中的欄位增加,僅僅是將記錄行合併到一起。其顯示的欄位應該是相同的,不然不能合併。
2.10、UNION[ALL]的使用
UNION:不使用關鍵字ALL,執行的時候會刪除重複的記錄,所有返回的行度是唯一的,
UNION ALL:不刪除重複航也不對結果進行自動排序。
格式:
SELECT 欄位名,... FROM 表名
UNION[ALL]
SELECT 欄位名,... FROM 表名
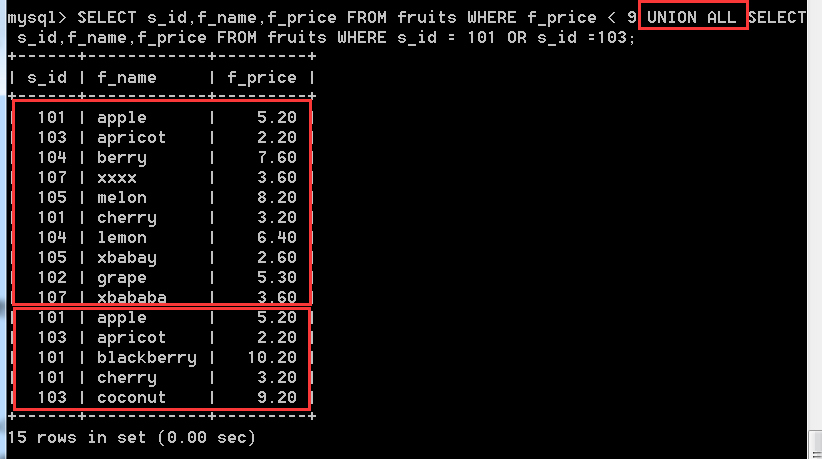
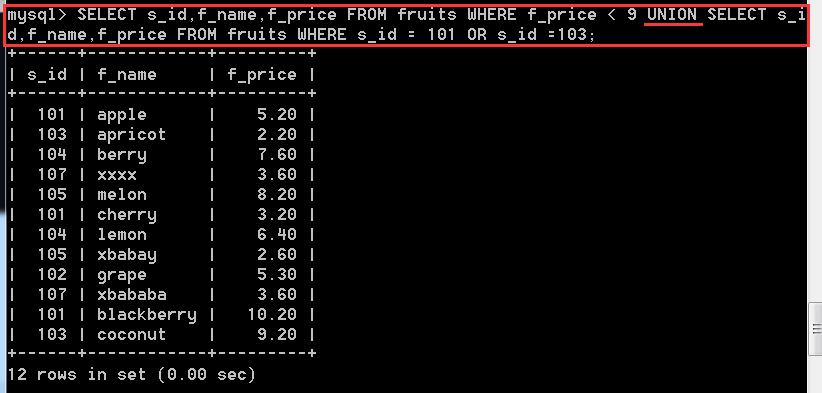
問題一:查詢所有價格小於9的水果的資訊,查詢s_id等於101個103所有水果的資訊,使用UNION連線查詢結果
SELECT s_id,f_name,f_price FROM fruits WHERE f_price < 9
UNION ALL
SELECT s_id,f_name,f_price FROM fruits WHERE s_id = 101 OR s_id=103;
解釋:顯示的欄位都是s_id,f_name,f_price,只是將兩個的記錄行合併到一張表中。僅僅增加的是記錄行,而顯示的欄位還是那三個,沒有增加,
使用UNION,而不用UNION ALL的話,重複的記錄就會被刪除掉。
三、使用正規表示式查詢
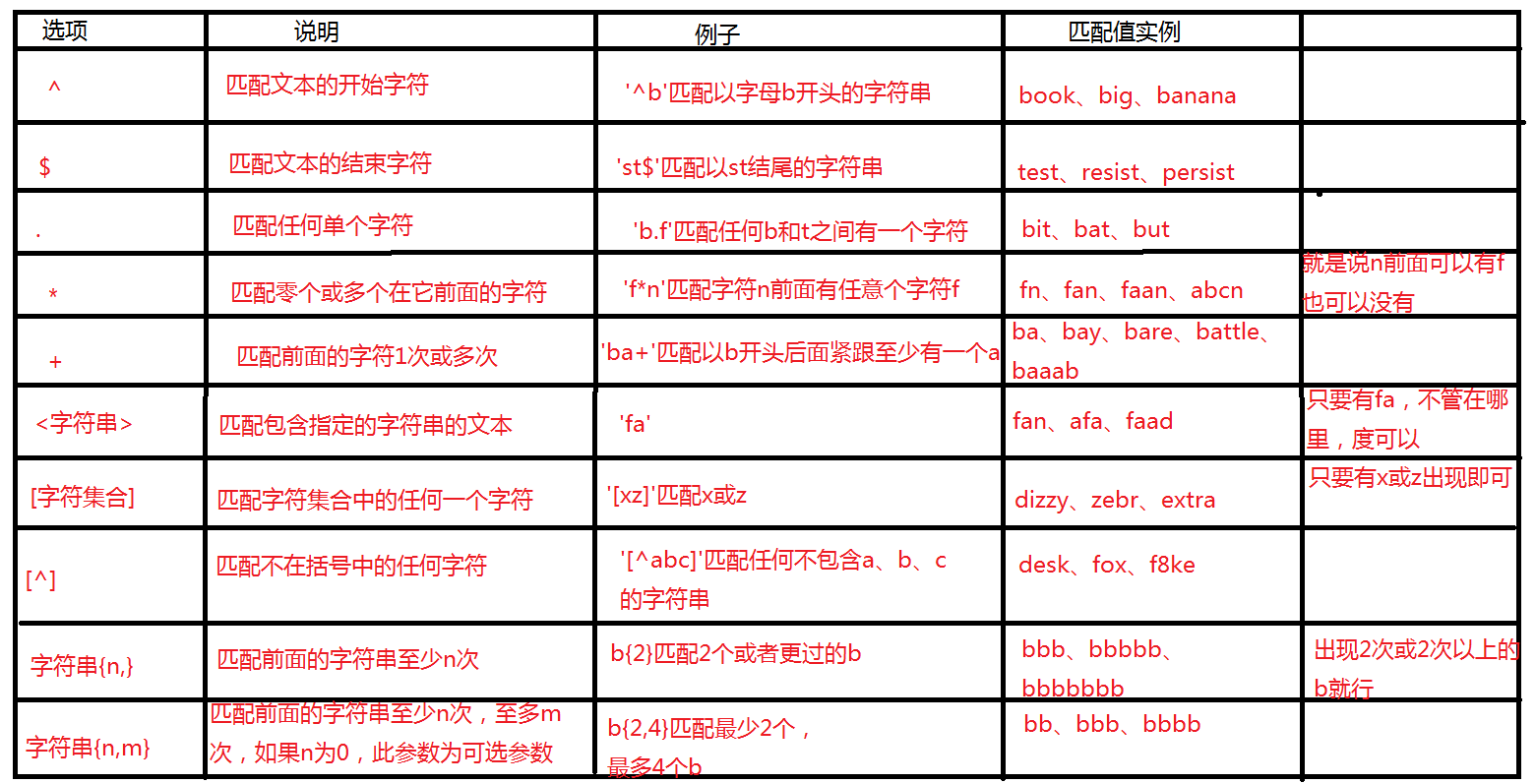
這個非常簡單,就是使用REGEXP關鍵字來指定正規表示式,畫一張表格,就能將下面所有的度覆蓋掉。
3.1、查詢以特定字元或字串開頭的記錄
SELECT * FROM fruits WHERE f_name REGEXP '^b'; //以b開頭的記錄
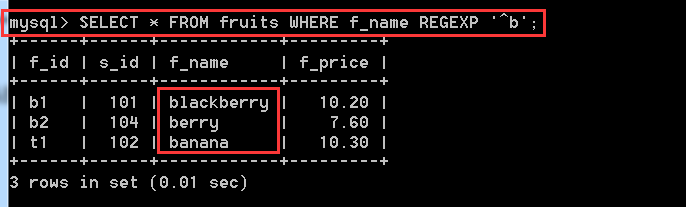
就講解這一個,下面這些的形式跟這個一模一樣,唯一的差別就在正規表示式不一樣,一般使用這種模糊查詢,使用MySQL中的'_'和'%'就已經足夠了。
3.2、查詢以特定字元或字串結尾的記錄
3.3、用符號"."來替代字串中的任意一個字元
3.4、使用"*"和"+"來匹配多個字元
3.5、匹配指定字串
3.6、匹配指定字元中的任意一個
3.7、匹配指定字元以外的字元
3.8、使用{n,}或者{n,m}來指定字串連續出現的次數
四、綜合案例 練習資料表查詢操作
4.1、搭建環境
兩張表: employee(員工)表和dept(部門)表。
CREATE TABLE dept
(
d_no INT NOT NULL PRIMARY KEY AUTO_INCREMENT, //部門編號
d_name VARCHAR(50), //部門名稱
d_location VARCHAR(100) //部門地址
);
CREATE TABLE employee
(
e_no INT NOT NULL PRIMARY KEY, //員工編號
e_name VARCHAR(100) NOT NULL, //員工姓名
e_gender CHAR(2) NOT NULL, //員工性別
dept_no INT NOT NULL, //部門編號
e_job VARCHAR(100) NOT NULL, //職位
e_salary SMALLINT NOT NULL, //薪水
hireDate DATE, //入職日期
CONSTRAINT dno_fk FOREIGN KEY(dept_no) REFERENCES dept(d_no)
);
表結構
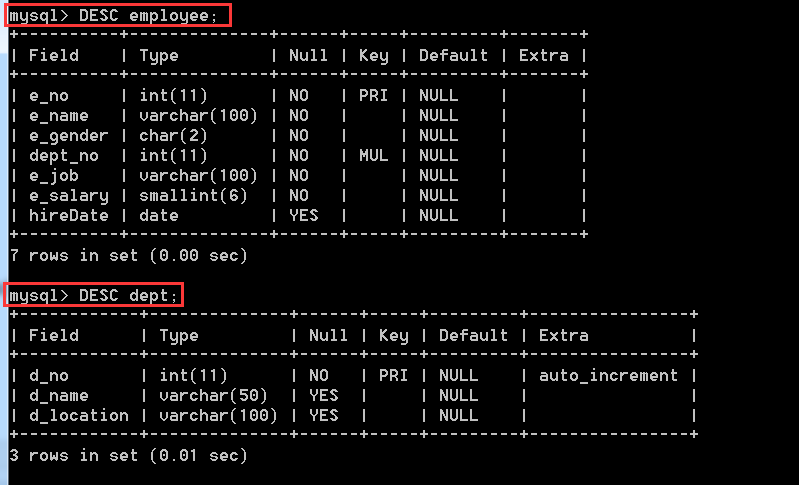
插入資料
INSERT INTO dept
VALUES
(10,'ACCOUNTING','ShangHai'),
(20,'RESEARCH','BeiJing'),
(30,'SALES','ShenZhen'),
(40,'OPERATIONS','FuJian');
單詞解釋:ACCOUNTING:會計部門 RESEARCH:研發部 SALES:銷售部 OPERATIONS:實踐部
INSERT INTO employee
VALUES
(1001, 'SMITH' , 'm' , 20 , 'CLERK' , 800 , '2005-11-12'),
(1002, 'ALLEN' , 'f' , 30 , 'SALESMAN' , 1600, '2003-05-12'),
(1003, 'WARD' , 'f' , 30 , 'SALESMAN' , 1250, '2003-05-12'),
(1004, 'JONES' , 'm' , 20 , 'MANAGER' , 2975, '1998-05-18'),
(1005, 'MARTIN' , 'm' , 30 , 'SALESMAN' , 1250, '2001-06-12'),
(1006, 'BLAKE' , 'f' , 30 , 'MANAGER' , 2850, '1997-02-15'),
(1007, 'CLARK' , 'm' , 10 , 'MANAGER' , 2450, '2002-09-12'),
(1008, 'SCOTT' , 'm' , 20 , 'ANALYST' , 3000, '2003-05-12'),
(1009, 'KING' , 'f' , 10 , 'PRESIDENT' , 5000, '1995-01-01'),
(1010, 'TURNER' , 'f' , 30 , 'SALESMAN' , 1500, '1997-10-12'),
(1011, 'ANAMS' , 'm' , 20 , 'CLERK' , 1100, '1999-10-15'),
(1012, 'JAMES' , 'f' , 30 , 'CLERK' , 950, '2008-06-15');
單詞解釋:SALESMAN:銷售員 CLERK:普通職員 MANAGER:經理 PRESIDENT:董事長 ANALYST:分析師 m:male 男性 f:female 女性
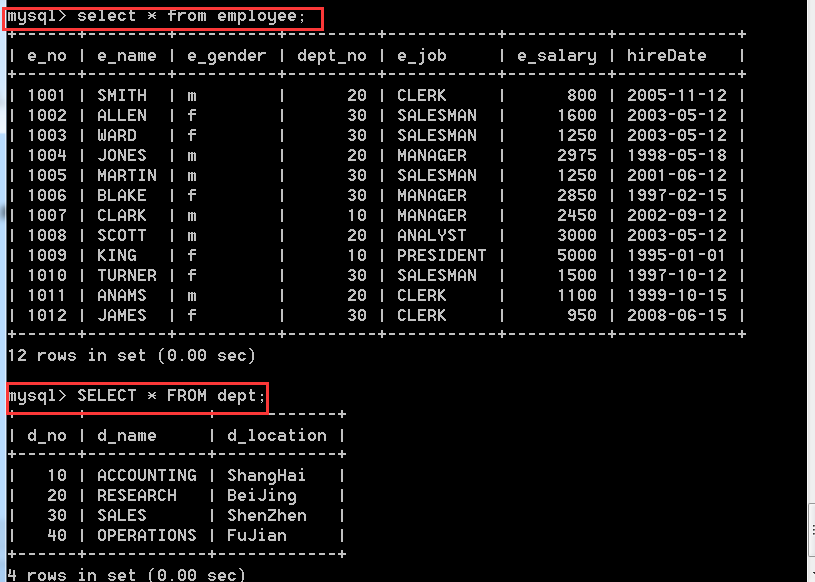
4.2、查詢操作
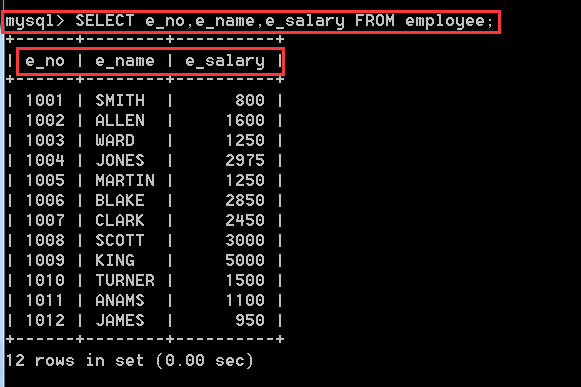
4.2.1、在employee表中,查詢所有記錄的e_no,e_name和e_salary欄位值
SELECT e_no,e_name,e_salary FROM employee;
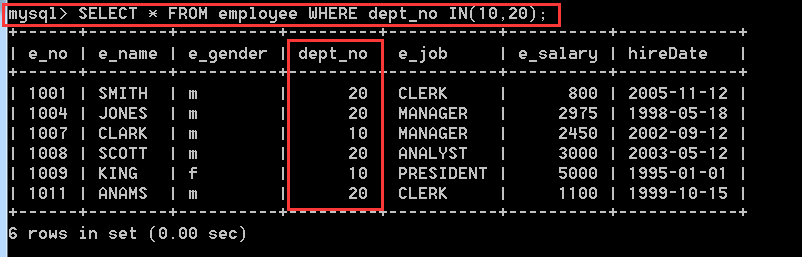
4.2.2、在employee表中,查詢dept_no等於10和20的所有記錄
方式一:SELECT * FROM employee WHERE dept_no IN(10,20);
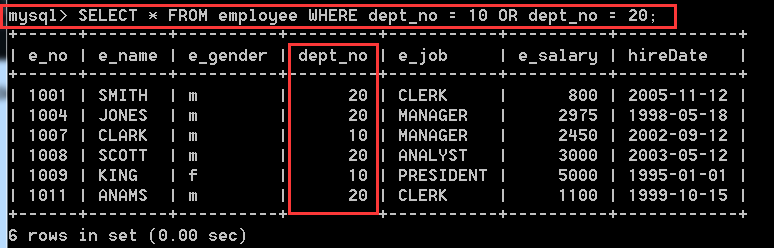
方式二:SELECT * FROM employee WHERE dept_no = 10 OR dept_no = 20;
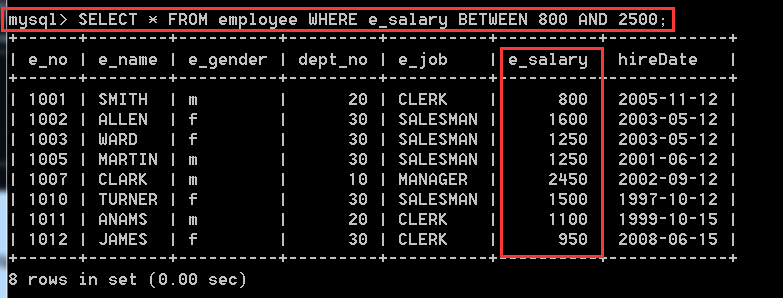
4.2.3、在employee表中,查詢工資範圍在800~2500之間的員工資訊
SELECT * FROM employee WHERE e_salary BETWEEN 800 AND 2500;
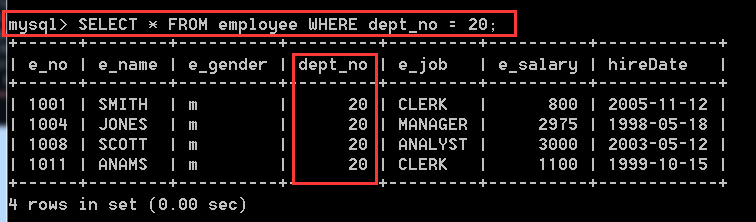
4.2.4、在employee表中,查詢部門編號為20的部門中的員工資訊
SELECT * FROM employee WHERE dept_no = 20;
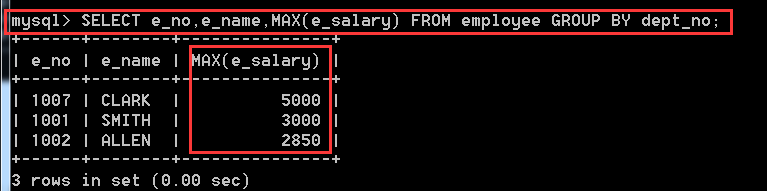
4.2.5、在employee表中,查詢每個部門最高工資的員工資訊
分析:每個員工都可能處於不同的部門,要先找出每個部門中的所有員工,應該想到分組,將相同部門的員工分為一組。然後在使用MAX()函式比較最大的salary。注意不要MAX(GROUP_CONCAT(e_salary)), 這樣寫就會報錯,GROUP_CONCAT(e_salary)是將分組中所有的e_salary顯示出來,我們直接MAX(e_salary)就會將該分組中所有的e_salary進行比較,拿到最大的一份。
SELECT e_no,e_name,MAX(e_salary) FROM employee GROUP BY dept_no;
我嘗試過其他方法,但是最終還是要對在相同部門中的員工做比較,只有通過分組才能對相同部門中的員工做比較,如果不分組,那麼將對全部的記錄進行比較。
4.2.6、查詢員工BLAKE所在部門和部門所在地
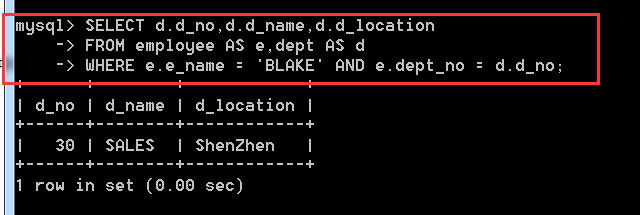
分析:看下題目就應該知道是兩張表,也就應該使用連線查詢,找出是用內連線還是外連線,然後找出連線條件,
方式一:SELECT d.d_no,d.d_name,d.d_location
FROM employee AS e,dept AS d
WHERE e.e_name = 'BLAKE' AND e.dept_no = d.d_no;
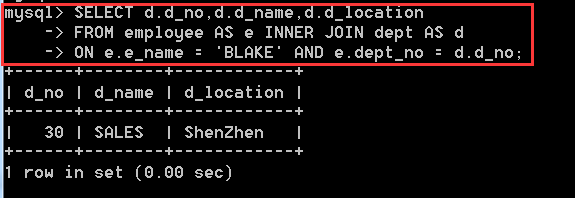
方式二:SELECT d.d_no,d.d_name,d.d_location
FROM employee AS e INNER JOIN dept AS d
ON e.e_name = 'BLAKE' AND e.dept_no = d.d_no;
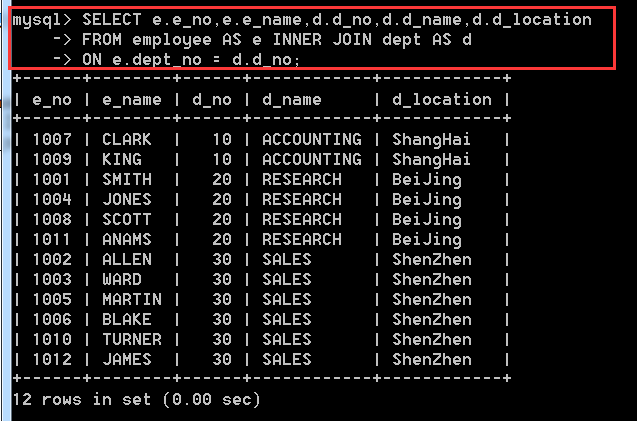
4.2.7、使用連線查詢,查詢所有員工的部門和部門資訊
分析:這個題跟上面哪個題差不多,使用內連線
SELECT e.e_no,e.e_name,d.d_no,d.d_name,d.d_location
FROM employee AS e INNER JOIN dept AS d
ON e.dept_no = d.d_no;
4.2.8、在employee中,計算每個部門各有多少員工
分析:每個部門用分組
SELECT COUNT(e.e_name)
FROM employee AS e
GROUP BY e.dept_no
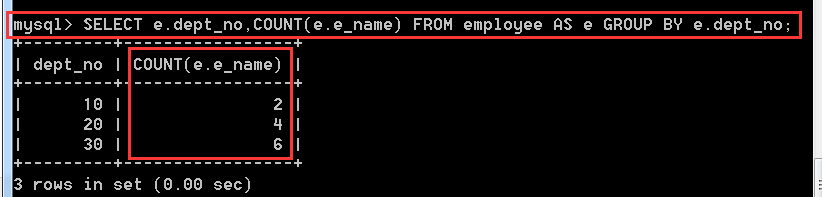
注意:SUM()和COUNT()要分清楚,SUM()是計算數值總和的,COUNT()是計算總的記錄行數的。
4.2.9、在employee表中,計算不同型別職員的總工資數
分析:對員工職位型別進行分組
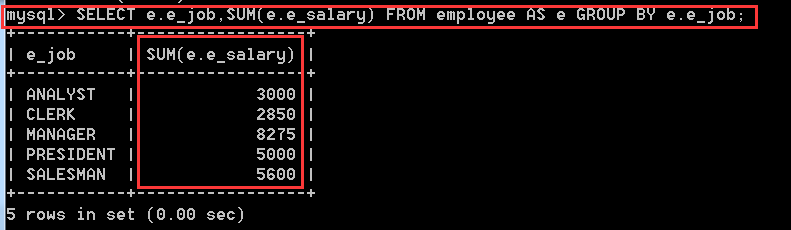
SELECT e.e_job,SUM(e.e_salary)
FROM employee AS e
GROUP BY e.e_job;
4.2.10、在employee表中,計算不同部門的平均工資
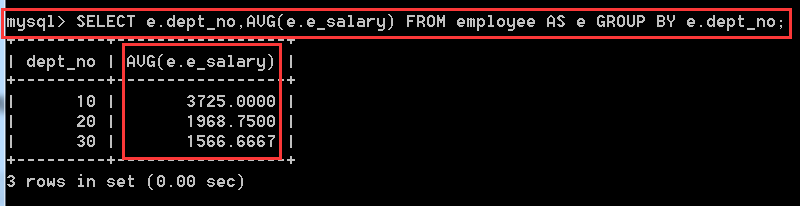
分析:對部門進行分組
SELECT e.dept_no,AVG(e.e_salary)
FROM employee AS e
GROUP BY e.dept_no;
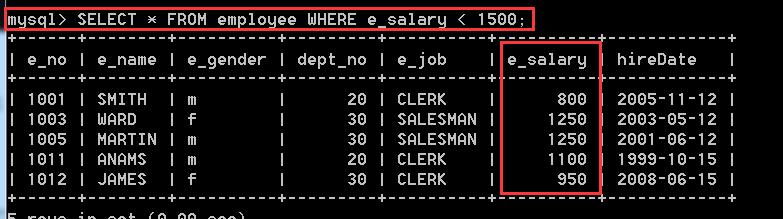
4.2.11、在employee表中,查詢工資低於1500的員工資訊
SELECT * from employee WHERE e_salary < 1500;
4.2.12、在employee表中,將查詢記錄先按部門編號由高到低排列,再按員工工資由高到低排列
SELECT * FROM employee ORDER BY dept_no DESC,e_salary DESC;

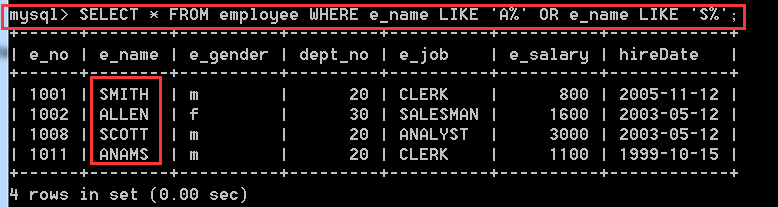
4.2.13、在employee表中,查詢員工姓名以字母A或S開頭的員工資訊
方式一: SELECT * FROM employee WHERE e_name LIKE 'A%' OR e_name LIKE 'S%';
方式二:SELECT * FROM employee WHERE e_name REGEXP '^A' OR e_name REGEXP '^S';
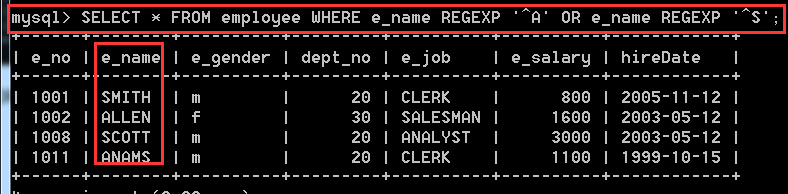
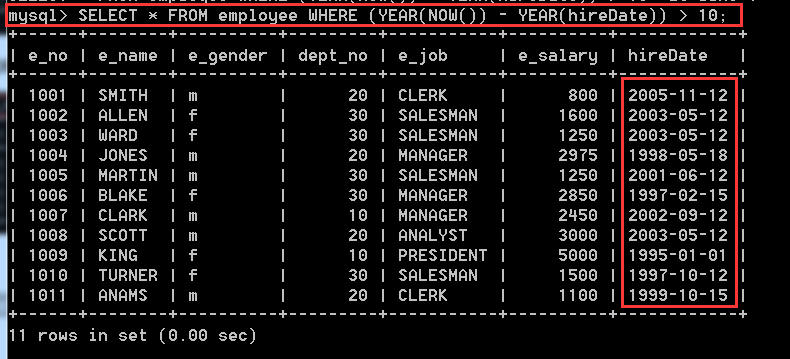
4.2.14、在employee表中,查詢到目前為止,工齡大於等於10年的員工資訊
方式一:SELECT * FROM employee WHERE (YEAR(NOW()) - YEAR(hireDate)) > 10;
方式二:SELECT * FROM employee WHERE (YEAR(CURDATE()) - YEAR(hireDate)) > 10;
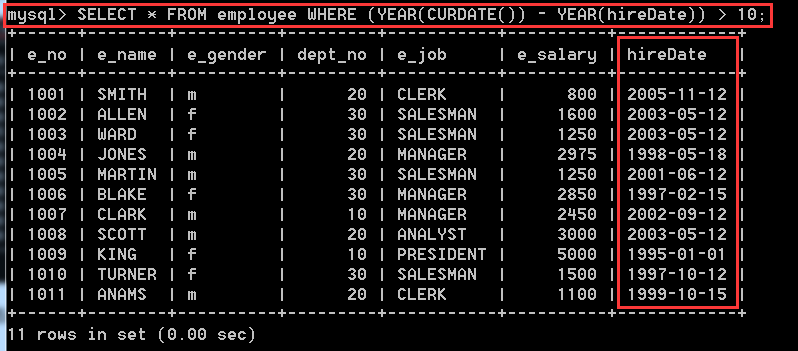
解釋:記得我們前一節學的資料型別嗎,其中CURDATE()代表的是YYYY-MM-DD, NOW()代表的是YYYY-MM-DD HH:MM:SS,所以這裡兩個度能用,只要將其擷取為為YEAR,然後相減,就能得到相差幾年了。
4.3、在已經建立好的employee表中進行如下操作
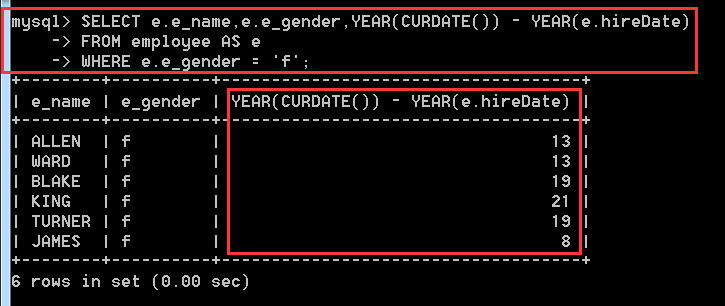
4.3.1、計算所有女員工(F)的年齡(從入職到現在的時間)
SELECT e.e_name,e.e_gender,YEAR(CURDATE()) - YEAR(e.hireDate)
FROM employee AS e
WHERE e.e_gender = 'f';
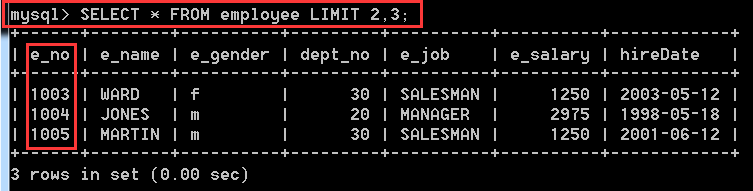
4.3.2、使用LIMIT查詢從第3條記錄開始到第六條記錄
SELECT * FROM employee LIMIT 2,3;
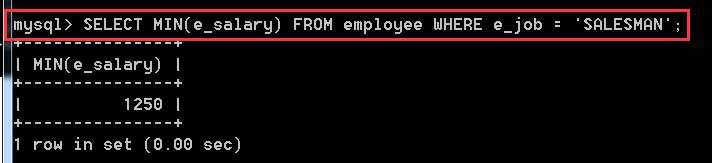
4.3.3、查詢銷售人員(SALSEMAN)的最低工資
SELECT MIN(e_salary)
FROM employee
WHERE e_job = 'SALESMAN';
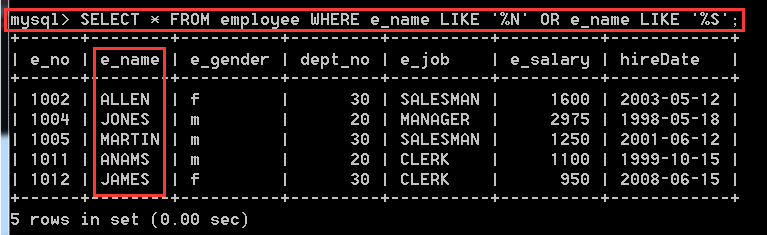
4.3.4、查詢名字以字母N或者S結尾的記錄
方式一:
SELECT * FROM employee WHERE e_name LIKE '%N' OR e_name LIKE '%S';
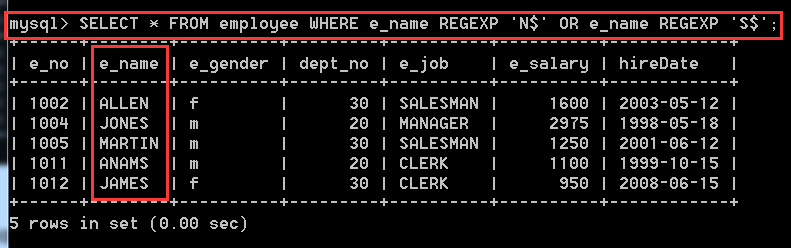
方式二:
SELECT * FROM employee WHERE e_name REGEXP 'N$' OR e_name REGEXP 'S$';
4.3.5、查詢在BeiJing工作的員工的姓名和職務
方式一:SELECT e_name,e_job FROM employee WHERE dept_no = (SELECT d_no FROM dept WHERE d_location = 'BeiJing');
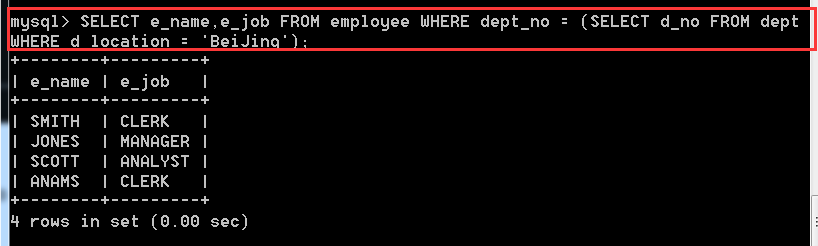
方式二:SELECT e.e_name, e.e_job FROM employee AS e,dept AS d WHERE e.dept_no = d.d_no AND d.d_location = 'BeiJing';
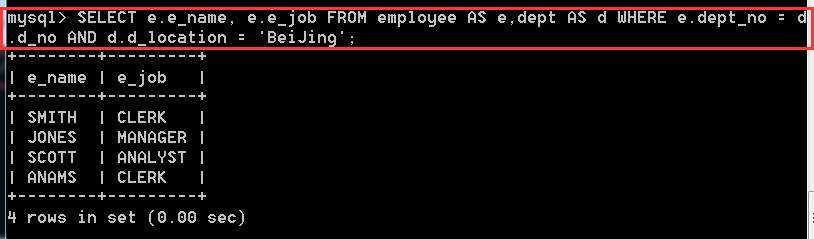
方式三:SELECT e.e_name,e.e_job FROM employee AS e INNER JOIN dept AS d ON e.dept_no = d.d_no AND d.d_location = 'BeiJing';
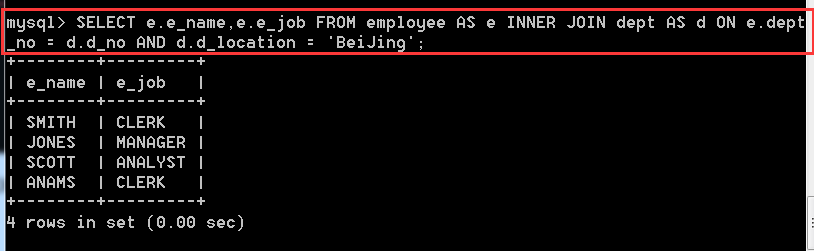
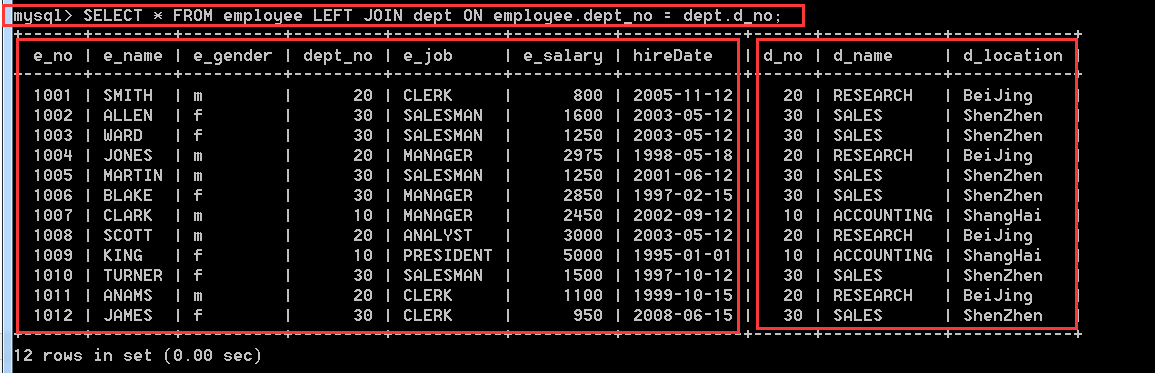
4.3.6、使用左連線方式查詢employee和dept表
SELECT * FROM employee LEFT JOIN dept ON employee.dept_no = dept.d_no;
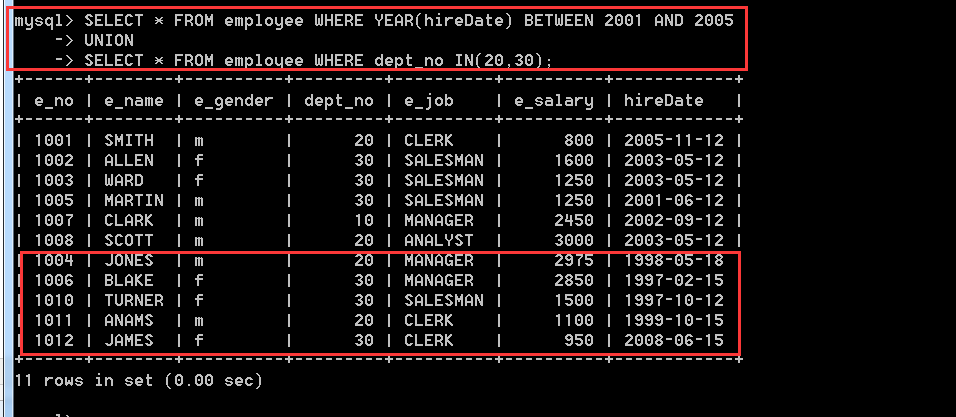
4.3.7、查詢所有2001~2005年入職的員工的資訊,查詢部門編號為20和30的員工資訊並使用UNION合併兩個查詢結果
SELECT * FROM employee WHERE YEAR(hireDate) BETWEEN 2001 AND 2005
UNION
SELECT * FROM employee WHERE dept_no IN(20,30);
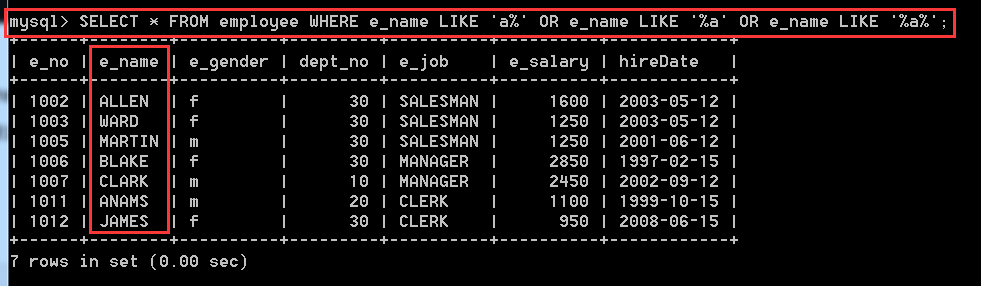
4.3.8、使用LIKE查詢員工姓名中包含字母a的記錄
SELECT * FROM employee WHERE e_name LIKE 'a%' OR e_name LIKE '%a' OR e_name LIKE '%a%';
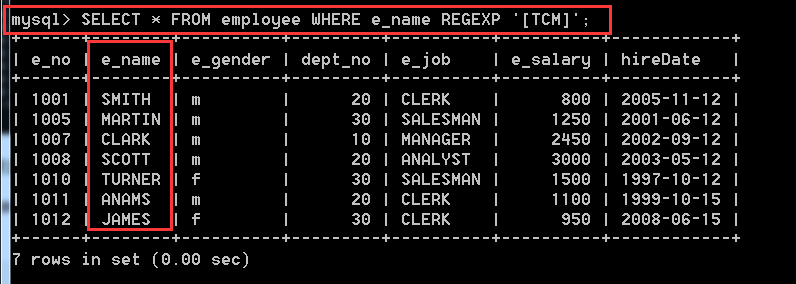
4.3.9、使用REGEXP查詢員工姓名中包含T、C或者M 3個字母中任意1個的記錄
SELECT * FROM employee WHERE e_name REGEXP '[TCM]';
總結:
花了我一天多的時間寫這篇文章,收穫很大,總結以下幾點
1、在寫複雜查詢的時候,也就是涉及到兩張表時,先寫FROM,然後在寫別的,要知道SQL語句的執行順序
2、單表查詢不是很難,記住幾個特點的,LIKE、GROUP BY很重要。記住他的用法
3、兩張表的查詢也就是內連線、外連線,外連線包括左外連線和右外連線,理解了這幾個,基本上就沒什麼難處
4、多練,把我寫的全部自己實現一遍,基本上你就能夠全部理解透徹了,並且在做題的過程中慢慢就會自己總結一些做題的經驗。
希望能對大家有所幫助,如果有幫助,就請順手點個推薦把,哈哈。