最佳化 Java Spark 服務忙了整整一週,嘗試了各種辦法和各種引數組合。
為什麼要最佳化
現網有個spark服務,白天資料量大,積壓資料,夜間資料量小,再把積壓的資料處理完,雖然達到了平衡,保證了每天的資料能處理完,但白天的資料處理延遲比較大。
資料積壓的原因
接手這個服務以來,我一直以為是因為下載圖片耗時長導致的資料處理速度慢。這周測試發現,儲存圖片的時候,判斷圖片是否存在,不存在則儲存圖片到本機資料夾,這兩個步驟有時耗時幾十毫秒,有時甚至耗時十幾分鍾!
難點
資料處理並行度小了不行,會導致資料處理速度慢;並行度大了也不行,會導致上述兩個步驟有機率出現特別慢的情況,從而有機率嚴重拖慢spark任務;透過測試發現,並行度無論怎麼設定,都會有機率出現特別慢的情況。
解決辦法
- 透過spark.streaming.kafka.maxRatePerPartition引數和JavaStreamingContext建構函式的batchDuration引數,控制資料流量
- 開啟spark推測執行,並設定合適的引數
- 透過redis分散式鎖控制並行度
關鍵程式碼如下:
spark.streaming.kafka.maxRatePerPartition引數設定:
sparkConf.set("spark.streaming.kafka.maxRatePerPartition", "1");
推測執行引數設定:
sparkConf.set("spark.speculation", "true");
sparkConf.set("spark.speculation.interval", "5s");
sparkConf.set("spark.speculation.quantile", "0.1");
sparkConf.set("spark.speculation.multiplier", "6");
batchDuration引數設定:
JavaStreamingContext jssc = new JavaStreamingContext(jsc, Durations.milliseconds(10000));
Redis分散式鎖tryLock定義:
public static boolean tryLock(String key) {
String r = RedisClusterUtil.getJedis().set(redisKeyPre + key, "value", "NX", "PX", 10);
if ("OK".equals(r)) {
return true;
} else {
return false;
}
}
Redis分散式鎖tryLock使用
try {
String key = String.valueOf(partitionId % 8);
while (!RedisLock.tryLock(key)) {
Thread.sleep(5);
}
} catch (InterruptedException e) {
log.error("獲取Redis鎖異常!!!");
}
說明:鎖超時釋放,沒有使用unlock手動釋放
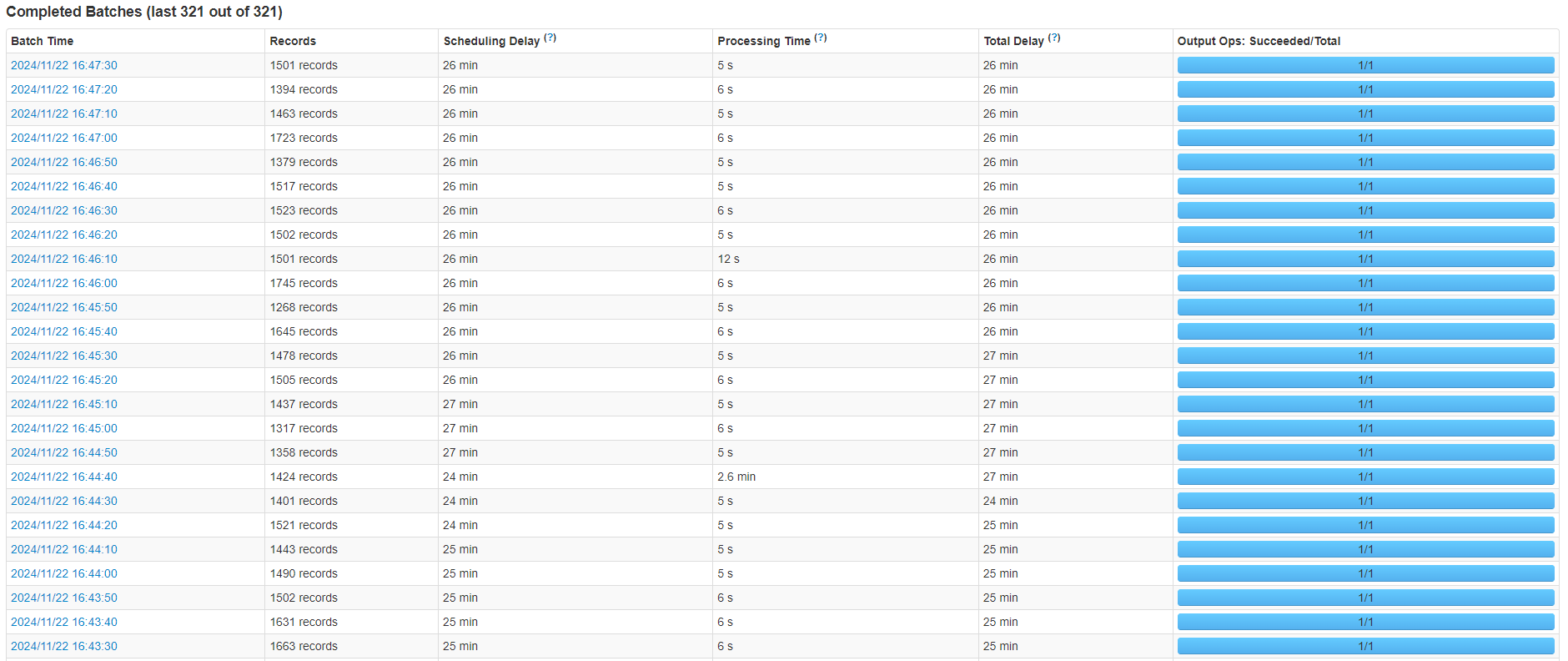
最佳化效果
透過以上方法,降低了判斷圖片檔案是否存在和儲存圖片這兩個步驟出現長耗時的機率和出現長耗時時的耗時時長。
但是依然有機率會出現特別慢的情況。如下圖所示:
Spark截圖1
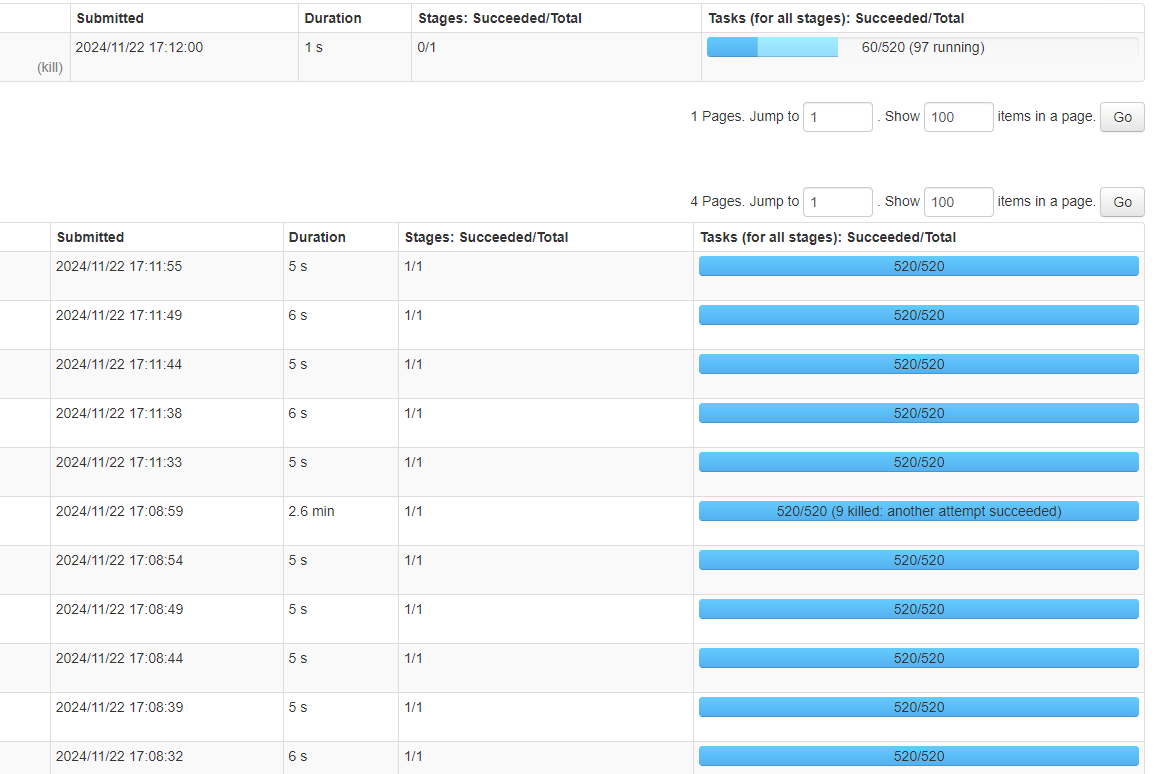
Spark截圖2