大模型在新能源汽車行業的應用與實踐
本次分享的主題為大模型在汽車工業化的實踐與應用,主要聚焦於工業製造相關的案例和落地經驗。總共分為五部分:1. ChatGPT 發展歷程;2. 大模型底層原理;3. 大模型賦能新型工業化;4. 工業化中的實踐與探索。
01 ChatGPT 發展歷程
首先為大家簡單梳理下 ChatGPT 的發展歷程。

早在 2018 年 OpenAI 就釋出了 GPT,但是從 GPT-1 到 GPT-3 生成模型的效果並不是很理想。直到 GPT-3.5 開始,生成模型完成了 NLP 各種問題的統一解法,在生成文字、回答問題、翻譯文字等方面具有非常出色的表現,甚至在一些任務上能夠達到人類水平。同時 ChatGPT 可以直接使用自然語言的方式進行互動,更加符合人的習慣,隨著發展,GPT4 支援多模態輸入,能夠完成看圖作答、角色扮演、圖表分析、程式設計、專業考試等各種各樣的複雜任務。
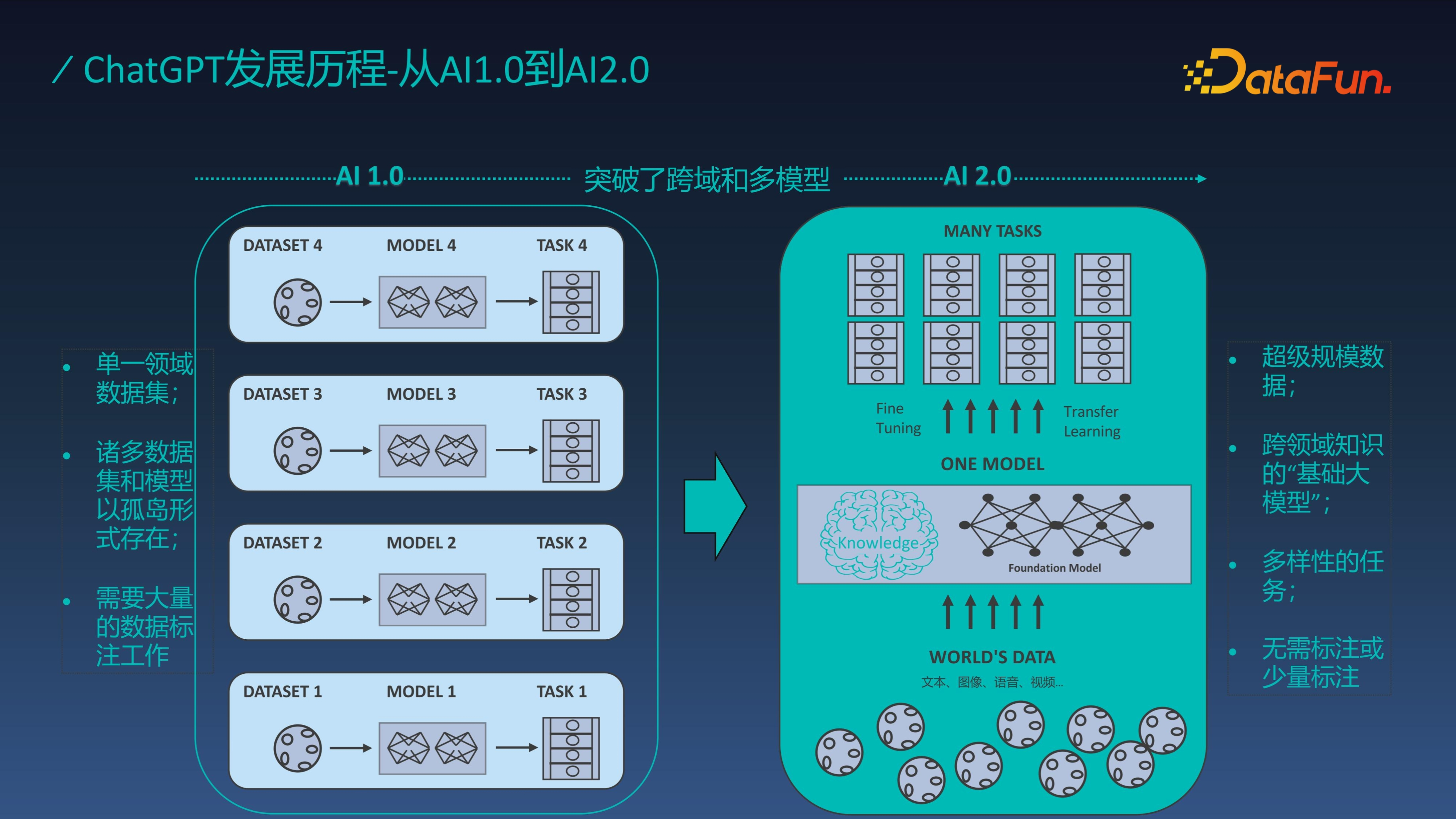
我們知道人工智慧的發展經歷了兩個時代,從 AI1.0 小模型時代到 AI2.0 大模型時代。作為大模型的代表作,ChatGPT 突破了跨域和多模型,資料集由單一領域擴充套件到了通用領域,從需要大量標註到無需標註或少量標註,這是人工智慧普遍落地的基礎。比如在工業視覺質檢領域中,圖片資料的積累非常緩慢,大模型只需要少量標註就可以達到與小模型大量樣本相同的效果,這樣就能加速整個工業智慧化的落地。
02 大模型底層原理
1. BERT 和 GPT 的區別
網路結構區別:BERT 類似於 Transformer 的 Encoder 部分;GPT 類似於 Transformer 的 Decoder 部分。
使用上的區別:BERT 用 CLS 對應的 Output 作為 Embedding 的結果,然後根據不同的任務進行對應的操作來 fine-tuning;GPT 接近於人類的使用方式,可以透過對話的方式得到問題的答案。
預訓練任務區別:BERT 採用 Masking Input,使用“填空題”的方式;GPT 採用 Predict Next Token,預測下一個 token。
2. 基於 InstructGPT 的 ChatGPT 改進

ChatGPT 是基於 InstructGPT 發展而來的,主要改進在於:使用了人類偏好的大量對話語料;引入了強化學習。這兩點保證了 ChatGPT 的回答更貼近人類的喜好,同時可以讓模型不斷逼近最好的效果。
3. ChatGPT 訓練過程
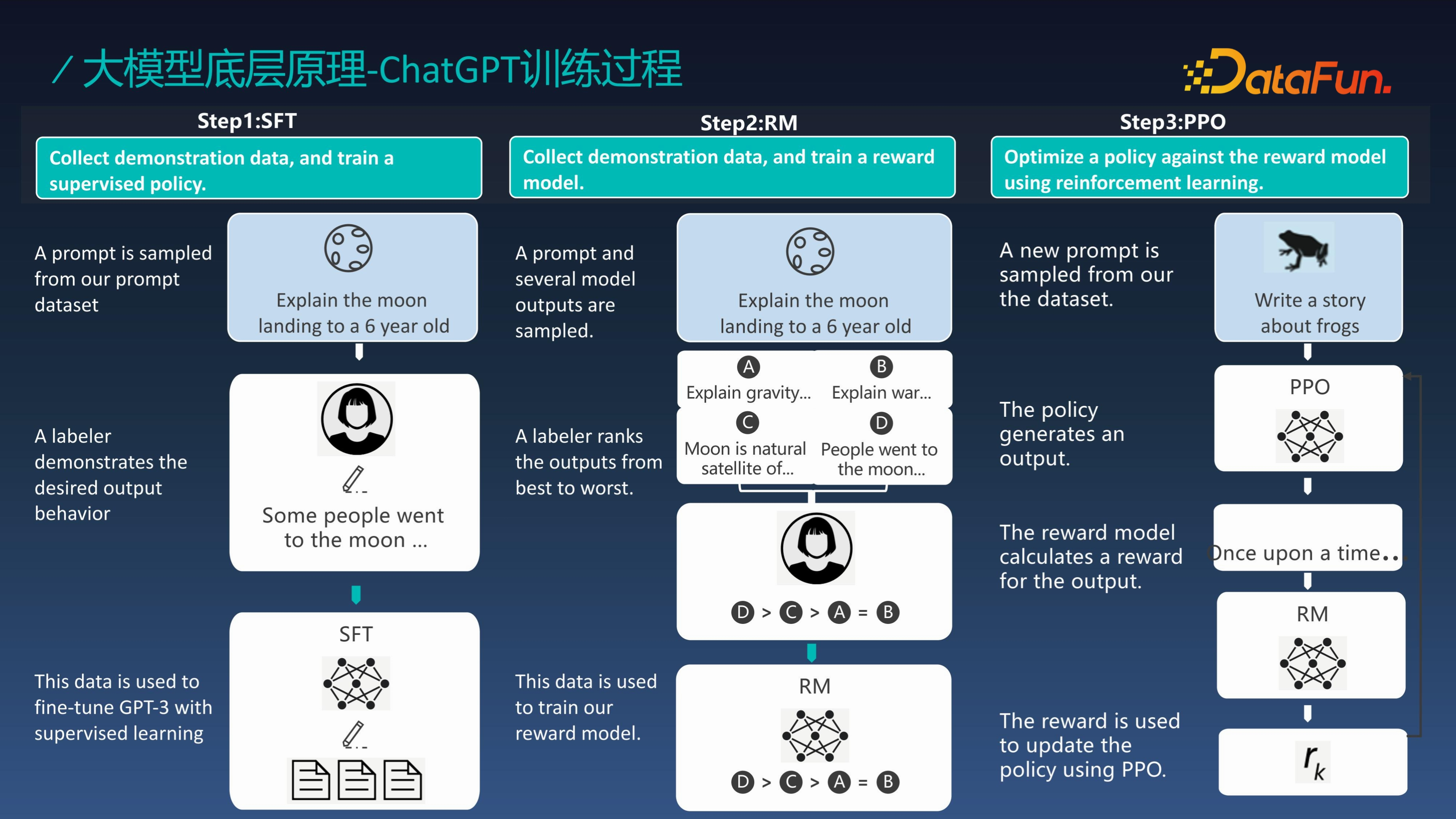
ChatGPT 的訓練過程主要分為三步:
第一步,收集資料訓練監督策略模型
第二步,收集資料訓練獎勵模型
第三步,透過PPO對獎勵模型進行強化學習
這裡講 ChatGPT 的訓練過程是突出一種思想,這種思想也會在後面的 Agent 閉環中得到應用,因此這裡不僅僅是 ChatGPT 的訓練過程,更是一種實現模型、Agent 持續增強的完美方案。
03 大模型賦能新型工業化
1. 實現路徑
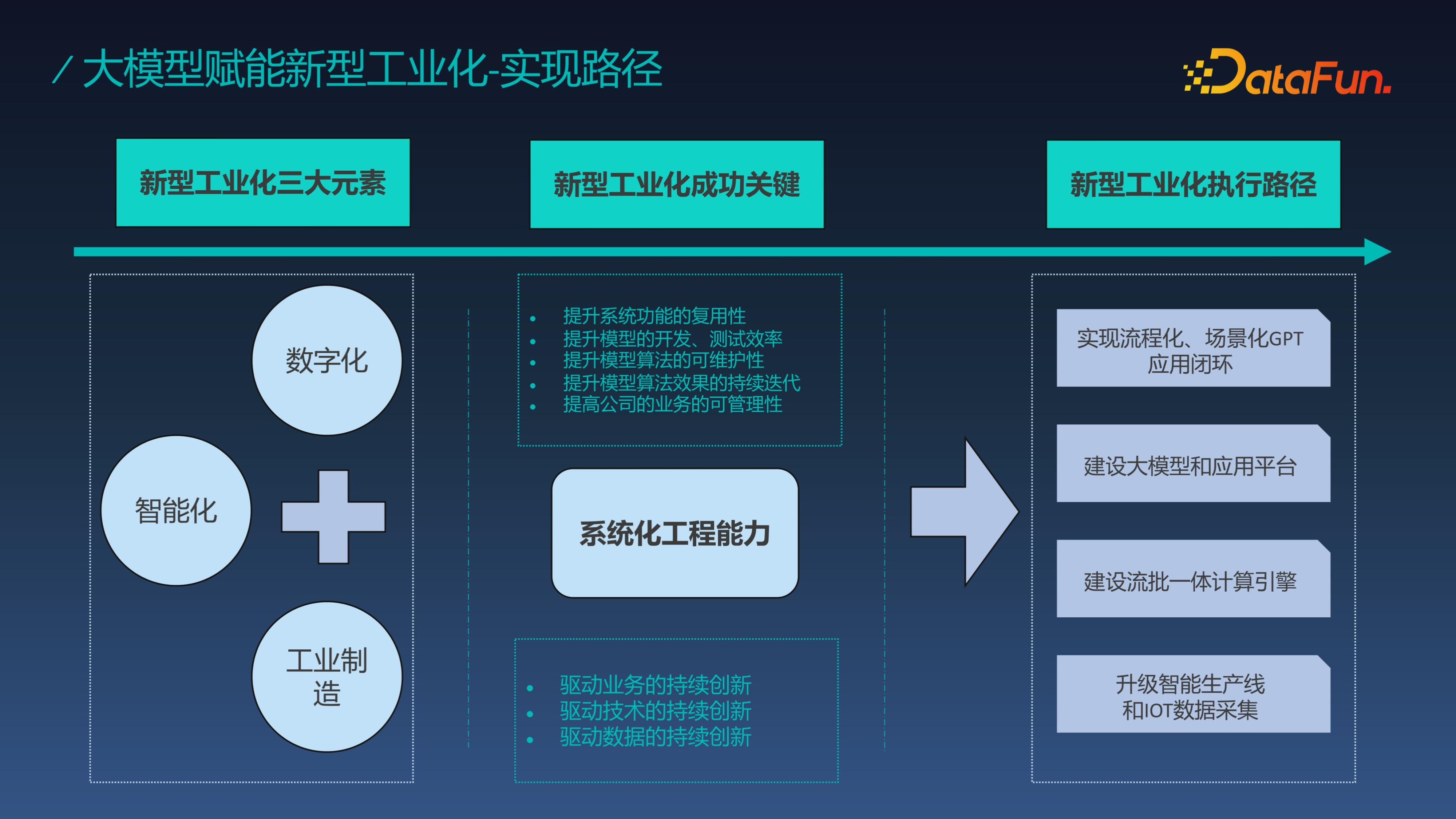
新型工業化是指將工業製造科技能力融入數字化能力和智慧化能力,解決供應鏈和產業鏈的問題,增強其柔性,同時能夠驅動整個工業化產業的技術創新。新型工業化成功的關鍵在於系統化的工程能力,在大模型發展的今天,新型工業化執行路徑可以透過構建如訂單系統、排產系統、分析系統、計劃系統等的數字系統和建設包含整個 IOT 裝置資料的資料系統,並基於數字系統、資料系統和大模型形成 GPT 解決方案平臺。再基於 GPT 平臺生成的各個 Agent 服務於下游各類業務。
2. 應用正規化

大模型賦能新型工業化有三種基本應用正規化:
正規化 1:指令提示:使用自然語言互動的模式,告知裝置或者系統來完成指定任務。例如可以透過語義裝置發出指令,讓機械手臂完成指定工作,也可以透過指令讓大模型生成邏輯控制程式碼。
正規化 2:輔助決策:透過資料驅動模式而不是人工進行互動,如在智慧質檢場景中,智慧攝像機可以透過大模型判斷鑄件是否有缺陷,如果有缺陷則會給出有缺陷的機率,之後再交由人工判斷確認。
正規化 3:自主決策:無需人工輔助,常見場景如自動駕駛和自動分揀。
04 工業化中的實踐與探索
接下來,詳細講解大模型在蔚來的優秀實踐。
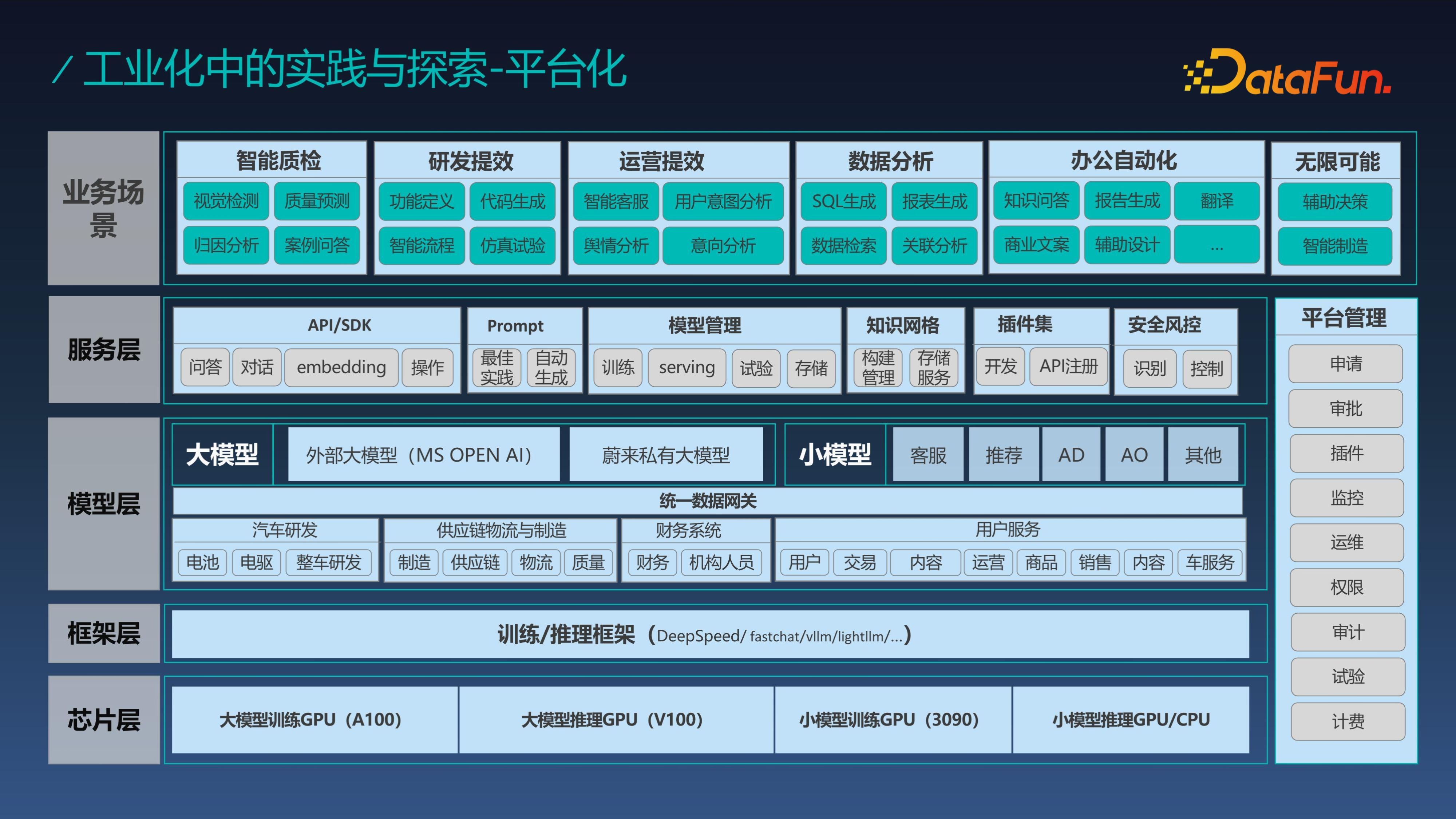
首先是平臺化,在蔚來,幾乎所有業務大模型AI應用都是基於這個 GPT 平臺進行編織的,這裡提到的 AI 應用就是一個 AI Agent,應用的編織過程實際就是 Agent 的構建過程。平臺的架構整體分為晶片層、框架層、模型層、服務層,最上面是業務場景。服務層所有的能力都是圍繞著建立 Agent 形成的。模型層中模型和資料是一體的,之所以如此,是因為資料和模型是不分家的,這也是新型架構的思路。過去資料的應用方式是建設資料庫,然後透過 SQL 訪問數倉。有了大模型之後,完全可以透過自然語言互動的方式直接訪問資料,資料隱藏在模型底層,是模型的一部分,直接面向使用者的就是模型層的能力,我們再也不需要直接面向資料進行分析和使用。
1. Agent 邏輯架構
人工智慧領域,現在最火的毫無爭議是 Agent,那 Agent 是什麼,其構件又是怎樣的呢?下面就來介紹一下蔚來是如何設計 Agent 的。
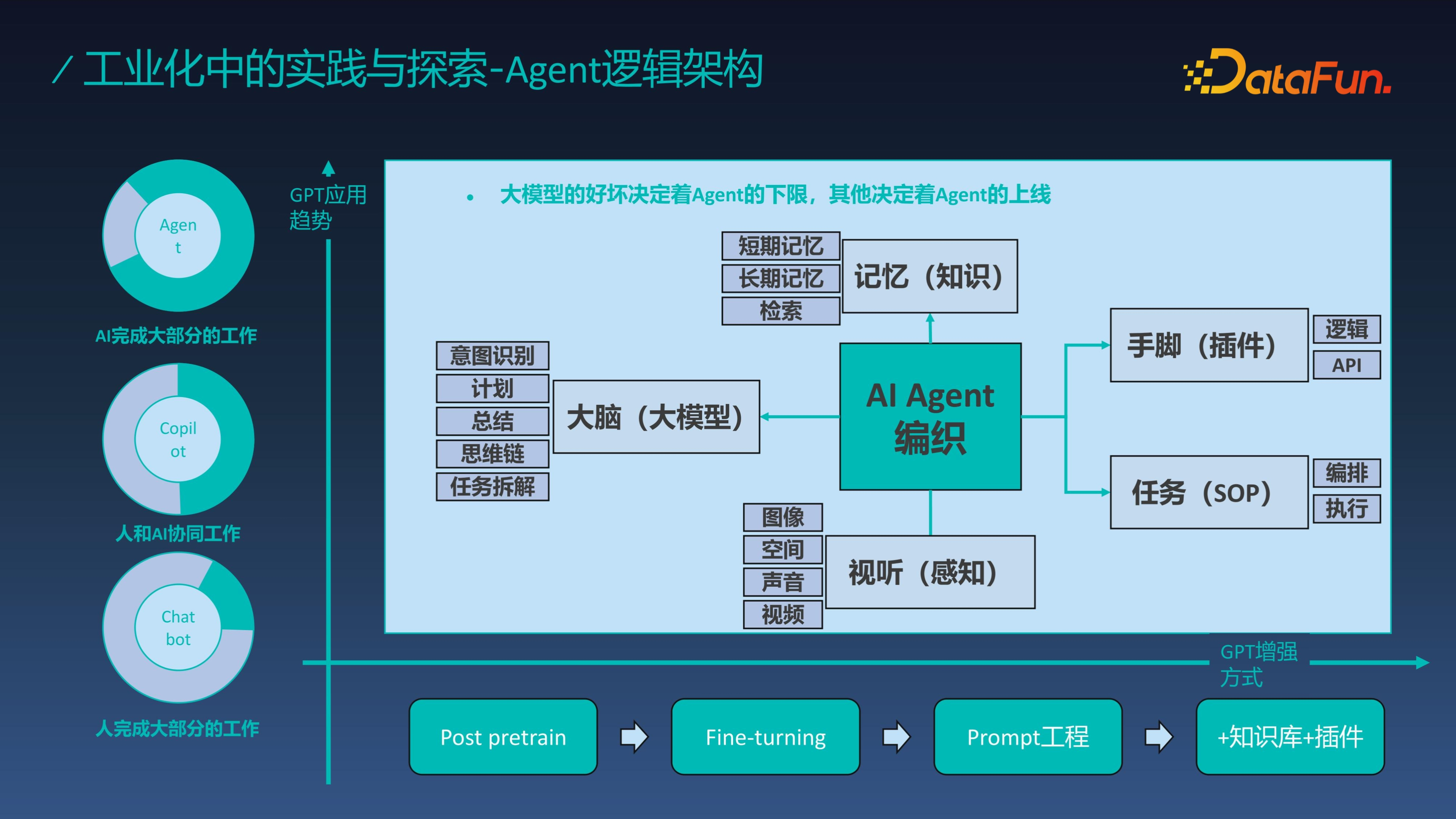
大模型應用分為三個階段,第一個階段是人類完成大部分工作,模型輔助人決策;第二階段是人和 AI 協同工作,GPT 能力融入軟體併成為軟體的一部分,但這個階段並沒有改變整個系統的產品形態,還需要人類提供基礎產品,AI 也只能成為原產品的輔助;第三個階段是 AI 完成大部分的工作即 AI Agent 階段,人類只需要給出指令並設定目標、給出資源(如系統介面資源),AI Agent 會自動完成目標。
那到底什麼是 Agent 呢?其實 Agent 就是模擬人的思考模型、行動模型來工作的,整體分為四個元件:大腦、記憶、感知引擎、規劃和任務執行,GPT 充當大腦,外掛成為手和腳連線資料和系統,記憶以知識的方式進行儲存,感知模型實現視聽感知並透過外掛和智慧體進行對接,最後透過任務執行來完成工作。
2. 三大閉環
為了實現 AI Agent 的持續增強,我們提出了三大閉環:資料閉環、模型閉環和 Agents 閉環。資料閉環和模型閉環是中間態,為最終的 Agents 閉環服務。
(1)資料閉環
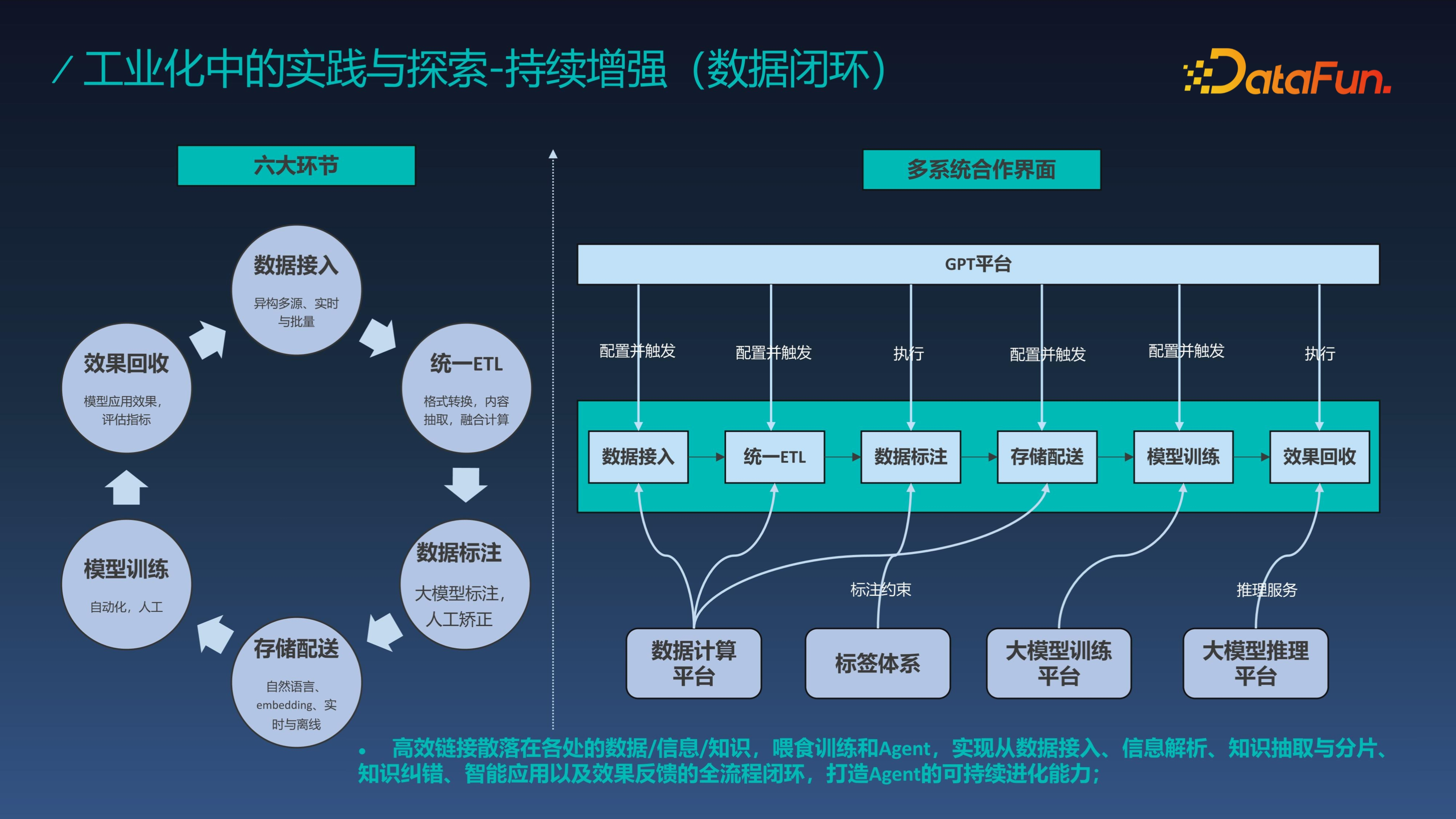
資料閉環分為六大環節,資料接入、統一 ETL、資料標註、儲存配送、模型訓練、效果回收,效果回收後會進一步修正資料。其中資料標註是由大模型來完成的,依賴給定範圍內的標籤體系。透過整個資料閉環可持續完善知識和資料,如果底層資料是語料,模型回答的問題一直是有偏的,則反映出訓練語料有問題,需要修正;在基於 prompt 工程進行知識問答的時候,回答的問題一直不對,也可透過回溯修改知識。資料閉環能夠高效連結散落在各處的資料、資訊、知識,餵食訓練模型和 Agent,整個閉環實現從資料接入、資訊解析、知識抽取與分片、知識糾錯、智慧應用以及效果反饋的全流程閉環,從而打造 Agent 的可持續進化能力。
(2)模型閉環

模型閉環也是分為六大環節,語料、模型、訓練、評估、A/B Test、上線,透過人工反饋的機制,當語料積攢到一定程度會觸發模型再次訓練,當評估達標之後上線。模型閉環實現的目標是模型持續增強,驅動 Agent 自動增強,這裡是透過複用訓練平臺和大資料平臺的能力,在這兩大基礎平臺能力之上實現從語料構建、語料儲存、模型託管、模型微調、模型測試、模型上線的全流程閉環。
(3)Agents 閉環
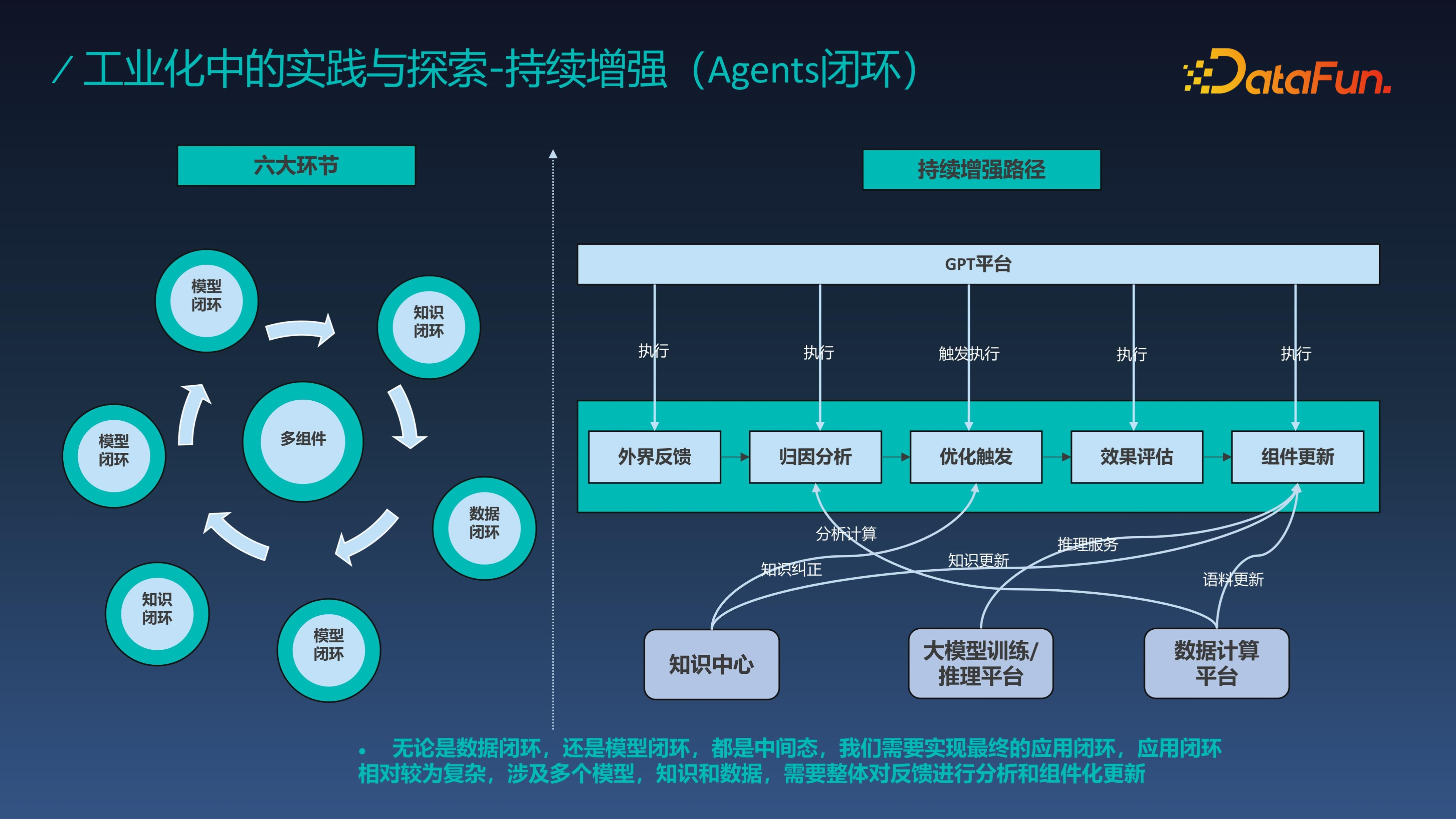
前文中提到,我們的終極目標是實現 Agent 的持續增強,下面就來介紹 Agents 閉環。
其涉及多個模型閉環、知識閉環和資料閉環的過程,其中資料閉環和知識閉環是分開的,資料閉環主要關注的是模型訓練的過程,即語料閉環,知識閉環主要關心知識更新。為了實現 Agents 的閉環需要構建一個完整的流程,同時能夠感知到外界反饋,然後經過歸因分析觸發相應最佳化,最佳化後經過效果評估,評估達標後再更新元件。
基於資料閉環和模型閉環,透過反覆迭代不斷地強化學習過程。這就是我前面講到的 ChatGPT 訓練方案的又一次再現,基於此思路我們實現了 Agent 閉環。
3. 應用案例
(1)三位一體智慧質檢
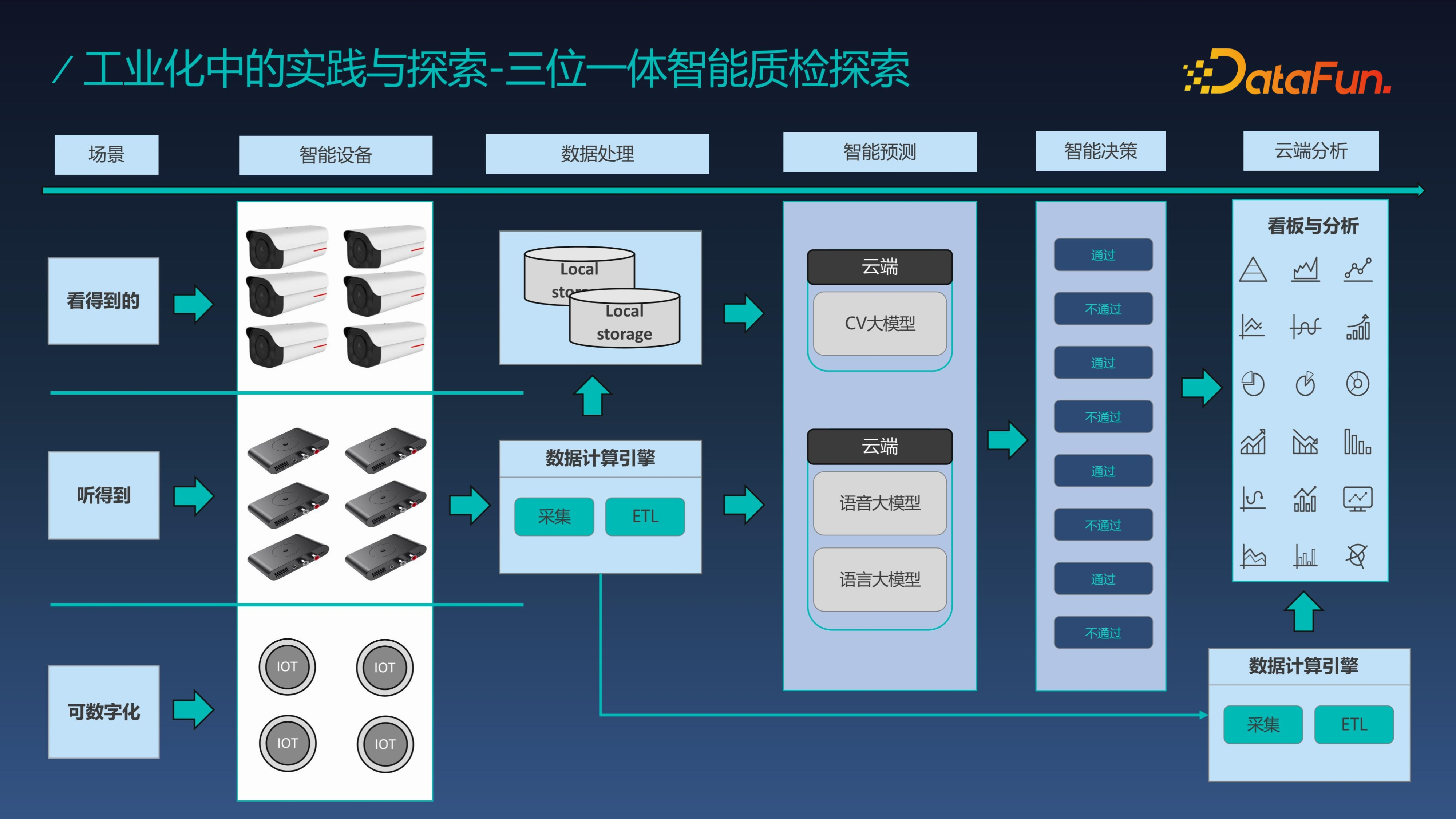
質檢是工業製造中質量的保證,對於工業製造非常重要,我們提出了三位一體的智慧檢測方案,對於質檢我們可以從三個方向實現突破,即看得到的、聽得到的、可數字化的,對於“看得到的”可以透過 CV 大模型替代人工檢測,由於大模型擁有跨域知識能力,能在缺少圖片資料的場景中降低冷啟成本;對於“聽得到的”可以透過聲音模型進行分析識別異響;對於可數字化的,可以透過大模型進行分析預測,比如和標準結果進行對比分析,看是否匹配。
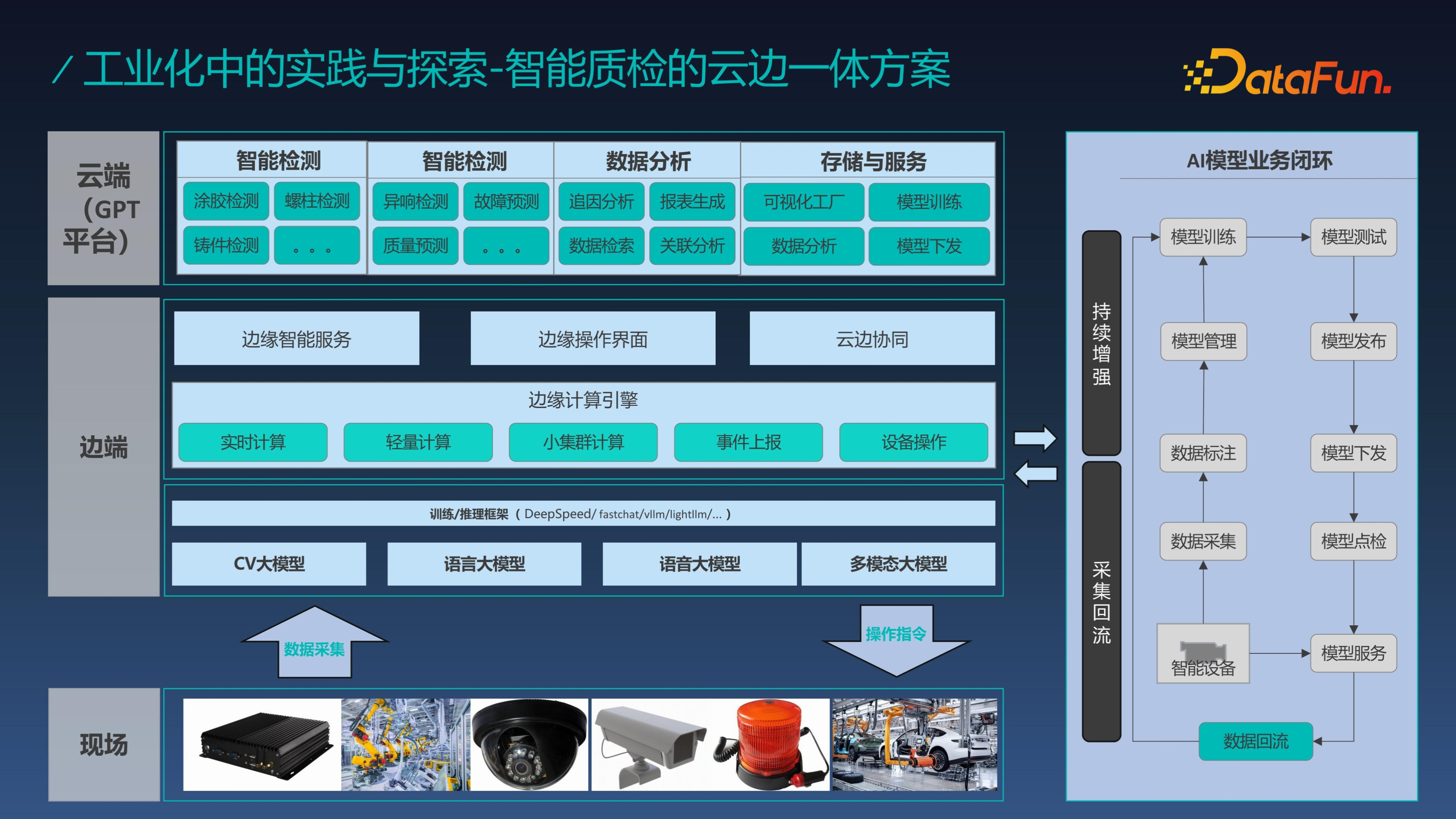
我們知道在實際的生產中,產線側的系統不可能完全依賴於雲端,由於一旦停網可能會影響生產,所以產線內無法完全依賴外網,我們提出了雲邊一體的架構,邊端系統一般需要部署在產線旁邊。邊端系統的主要任務是檢測,同時將資料上傳到雲端,雲端系統主要是實現整體模型訓練的閉環。雲邊一體的架構結合在一起,能實現邊端系統的持續增強和雲端視覺化與綜合分析。
雲端的閉環訓練流程對於每個場景都是獨立存在的,需要資料持續累積。雲端模型會根據持續新增的資料量來決定是否重新訓練模型,在模型的指標評估、點檢實驗等都透過後模型才能上線,從而實現持續化的模型迭代。
(2)G8D Agents
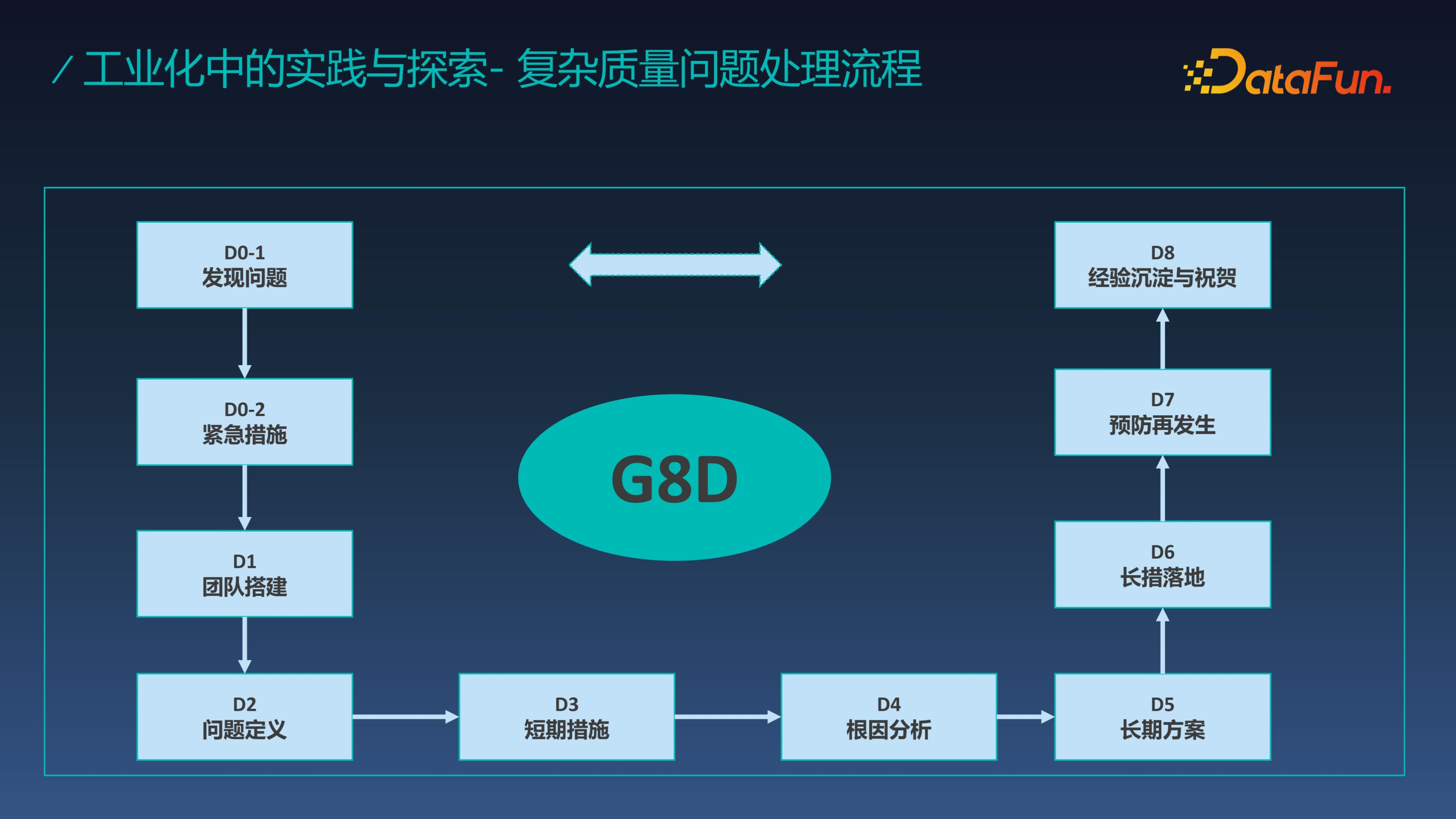
最後我們看一下如何解決工業生產過程中的複雜質量問題。在行業內,質量的處理流程一般採用 G8D 的方案來解決這類問題。G8D 主要分為八個模組:發現問題、緊急措施、團隊搭建、問題定義、短期措施、根因分析、長期方案、長措落地、預防再發生、經驗沉澱與祝賀。

設想當 G8D 和大模型結合時,會碰撞出怎樣的火花呢?我們據此又提出了 G8D Agents 的複雜問題解決方案,這裡需要構建 8 個 Agent,每個 Agent 對於 G8D 的每一個 D 承擔相應的任務。當把 8 個 Agents 構建成一個 team 的時候,就可以完成整體複雜問題的分析與處理。當然這其中需要對接資料系統和質量分析系統,並沉澱經驗給上游系統(如質量分析、質量案例池等)從而能夠回饋到整個系統中。
在沒有 G8D Agents 之前,質量分析過度依賴工程師的經驗,其經驗也沒有很好地沉澱下來,而 G8D Agents 系統不單實現了質量問題的快速分析處理,同時能快速沉澱經驗。最後 G8D Agent 系統可以跟各個系統打通或是成為系統的重要組成部分,相當於各系統擁有 8D Agents 的能力,可以避免沉重的數字化系統建設,以輕量的 Agent 解決方案節約開發成本,全面加速問題解決效率。
來自 “ DataFunTalk ”, 原文作者:黃帥;原文連結:https://server.it168.com/a2024/0301/6841/000006841095.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 大資料在車聯網行業的實踐與應用大資料行業
- Apache Flink 在汽車之家的應用與實踐Apache
- 探索Photoneo相機|Scanner L在新能源汽車電池焊接行業的應用行業
- 大資料在快狗叫車中的應用與實踐大資料
- 一汽集團資料專家分享:實時資料技術在汽車行業的應用與實踐經驗行業
- MBSE諮詢服務與工具——MBSE在汽車行業的應用行業
- 雲流化技術在汽車行業中的應用行業
- 移動端VIN碼識別在汽車行業中的前景與應用行業
- 工業元宇宙在能源及汽車行業應用示例元宇宙行業
- 一文看懂新能源汽車行業如何踐行智慧製造行業
- 淺析大模型在銀行業客服中心的應用大模型行業
- Flink CDC 在易車的應用實踐
- 集度汽車 Flink on native k8s 的應用與實踐K8S
- 大模型在程式碼缺陷檢測領域的應用實踐大模型
- 行業分析| 智慧頭盔在快對講上的應用與實踐行業
- AI在汽車中的應用:實用深度學習AI深度學習
- 車輛動力學模型在模擬測試中的應用實踐模型
- 新能源汽車的產業重生產業
- AI大模型+低程式碼,在專案管理中的應用實踐AI大模型專案管理
- 探索Robotiq夾爪|FT 300-S在汽車行業中的應用行業
- Flink在美團的實踐與應用
- 行業實踐:RocketMQ 業務整合典型行業應用和實踐行業MQ
- 行業方案|數商雲新能源汽車行業SRM供應商管理解決方案行業
- 六大行業動向,給2021年新能源汽車行業畫下句點行業
- 應用FMEA工具助力新能源汽車質量提升
- CTR:新能源汽車行業報告(附下載)行業
- Flink 在中泰證券的實踐與應用
- Apache Flink 在鬥魚的應用與實踐Apache
- AI在汽車行業的六大令人興奮的用途AI行業
- TiDB 在摩拜單車的深度實踐及應用TiDB
- Apache Flink 在蔚來汽車的應用Apache
- 璞華AI大模型應用的探索之路:從AI大模型開發與運營平臺到應用寶庫的最佳實踐AI大模型
- 中國汽車流通協會:2023年1月新能源汽車行業月報行業
- 中國汽車流通協會:2021年9月新能源汽車行業月報行業
- 中國汽車流通協會:2022年10月新能源汽車行業月報行業
- 中國汽車流通協會:2021年1月新能源汽車行業月報行業
- 中國汽車流通協會 :2020年10月新能源汽車行業月報行業
- Redis在Web專案中的應用與實踐RedisWeb