大資料開發的儲存技術探索與實踐
導讀:本期分享一種新的儲存方式。過去十幾年大資料場景中儲存層使用最多的是 HDFS,然而最近幾年面對存算分離場景又無一例外選擇了物件儲存。為解決物件儲存在大資料平臺實際開發中遇到的問題,從 2017 年起我們啟動了 JuiceFS 專案。
01 Data Lake 和 Lakehouse 從何而來?
1. 什麼是 Data Lake

Wikipedia 上關於 Data Lake 的介紹是:A data lake is a system or repository of data stored in its natural/raw format, usually object blobs or files.
這段話的核心是 nature/raw format。Data Lake 和傳統資料倉儲的不同點是 Data Lake 能夠儲存更原始格式的資料,可以儲存結構化、半結構化、非結構資料。而傳統數倉需要將資料匯聚起來,並且在不同業務線上構建不同的數倉。
今天我們希望把更多的原始資料匯聚到一起,解決資料孤島、多業務多格式資料統一等問題。為了實現高效儲存,儲存計算分離成為必然;為了更快地看到資料,需要將資料先入湖,將 ETL 環節後置。
2. 什麼是 Lakehouse

2020 年,Databricks 公司提出了 Lakehouse 概念,意思是 Data Lake 不是想替代掉數倉,而是想成為一家人,所以數倉仍然存在,只是後置了。傳統的資料倉儲需要做 T+1 的 batch ETL 工作,導致資料倉儲生產的資料具有滯後性。隨著技術升級和業務發展,我們需要更實時地處理資料、更高效地分析資料。由於機器學習和深度學習所需的資料可以存放於資料倉儲或者資料湖中,因此資料平臺不僅要服務於 BI 和報表,還要實現大資料場景和 AI 場景的資料融合。Data bricks 公司針對 Lakehouse 引入了 ACID 事務、多版本資料、索引、零複製等特性,這些常出現在資料庫領域裡的特性在 Data Lake 階段是沒有提及的。所以 Lakehouse 對儲存的要求更高了。
02 HDFS 與物件儲存適合麼
1. 儲存系統比較
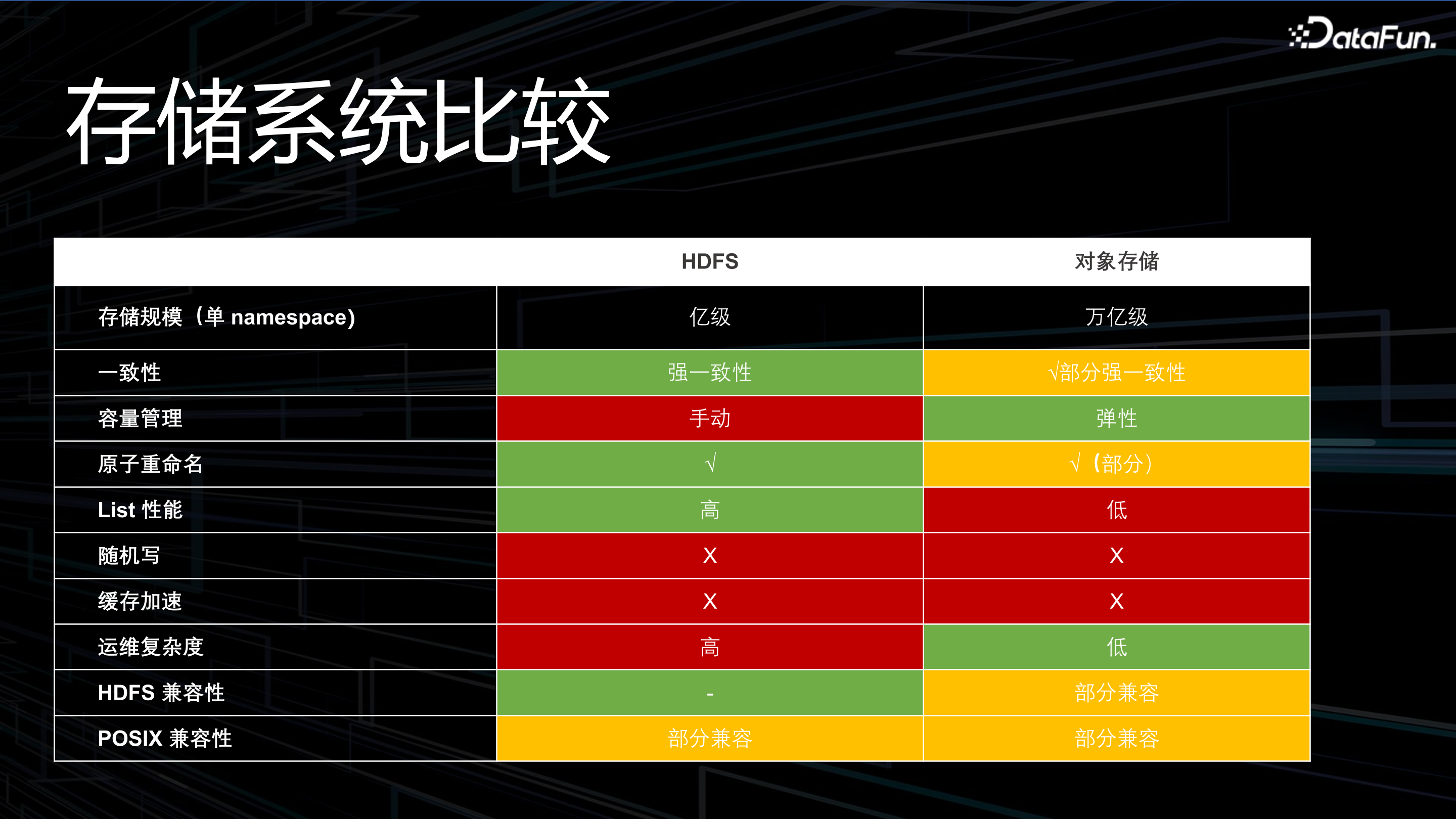
無論業務架構怎麼構建,最底層的儲存系統常見選項是 HDFS 和物件儲存。針對這兩種儲存進行比較,左側是比較的維度。
單個 namespace 的儲存規模,HDFS 通常做到億級,行業實踐中單個 HDFS 叢集 3 億以內的檔案運維是比較輕鬆的,5 億以上需要考慮到 Federation(聯邦)機制。但是物件儲存在私有化部署中可以達到千億級,公有云可以達到萬億級的物件規模。
在一致性方面,HDFS 是強一致性的檔案系統,物件儲存大部分則是最終一致性。最終一致性在 ETL 過程中會引入一些問題,這也是應用開發者會忽略的部分,後面會再具體解釋。
容量管理方面,HDFS 是手工運維的,需要手工的容量規劃、擴容;物件儲存是彈性的,沒有了容量規劃的過程。
原子重新命名能力,在檔案系統中這是個基本功能,但物件儲存裡沒有。後面會再講到在物件儲存裡如何實現最簡單的物件或者目錄改名的功能,很多應用開發者並沒有關注過這個差異。
List 的效能,在檔案系統裡執行 ls 命令是日常操作,在物件儲存中執行該操作效能會差 100 倍。
在隨機寫上,HDFS 和物件儲存都不支援隨機寫。
快取加速,在這兩個系統裡也都預設沒有帶。
在運維複雜度上,物件儲存在公有云上不需要運維;HDFS 的運維複雜度較高,經過十幾年迭代後,雖然已經積累了很多經驗和優秀實踐,但是仍然需要專業的、經驗豐富的運維人員來維護。
在 HDFS 相容性上,HDFS 本身相容性很好;物件儲存其實在適配整個 Hadoop 生態時是有一些痛點的。今天我們看所有公有云上的半托管的大資料服務,比如各家提供的 EMR 或類似產品裡能提供的計算元件是非常有限的。儘管 Hadoop 上層元件很豐富,有幾十個,但是大部分公有云上提供的只有 Spark、Hive、Presto 等,Impala、Trino 等計算元件公有云大部分都沒有提供適配,提供的 Spark、Hive 和 Presto 的版本也是有限的,這是因為這些雲廠商在上層計算引擎和自己的物件儲存之間的 Connector 及引擎之間做了深度的修改工作,導致雲廠商在對接每一種引擎和物件儲存時工作量較大,沒法去對接所有引擎,無法跟進所有社群版本,這就會給上層元件的選擇帶來限制。使用社群的 Hadoop 的生態還是雲廠商提供的生態,不同公司有不同的選擇。
在結合機器學習場景時,POSIX 介面是一個必要的訪問方式。機器學習和深度學習框架,如 PyTorch、TensorFlow 等對 HDFS 的 API 相容並不好,對 S3 能夠相容,但效能上不能滿足模型訓練的需求,因此在訓練時,通常需要將資料先複製到另外一個 POSIX 的檔案系統裡,再去跑訓練,這增加了系統使用複雜度。
2. 儲存系統的阿克琉斯之踵

比較了兩個儲存系統之後,再講一下它們的共性問題--阿克琉斯之踵。這來源於一個希臘神話,阿克琉斯是一位非常厲害的戰士,他唯一的“死穴”是腳後跟。和阿克琉斯一樣,強大的 HDFS 和物件儲存都存在各自的致命弱點。
3. HDFS 阿克琉斯之踵--NameNode
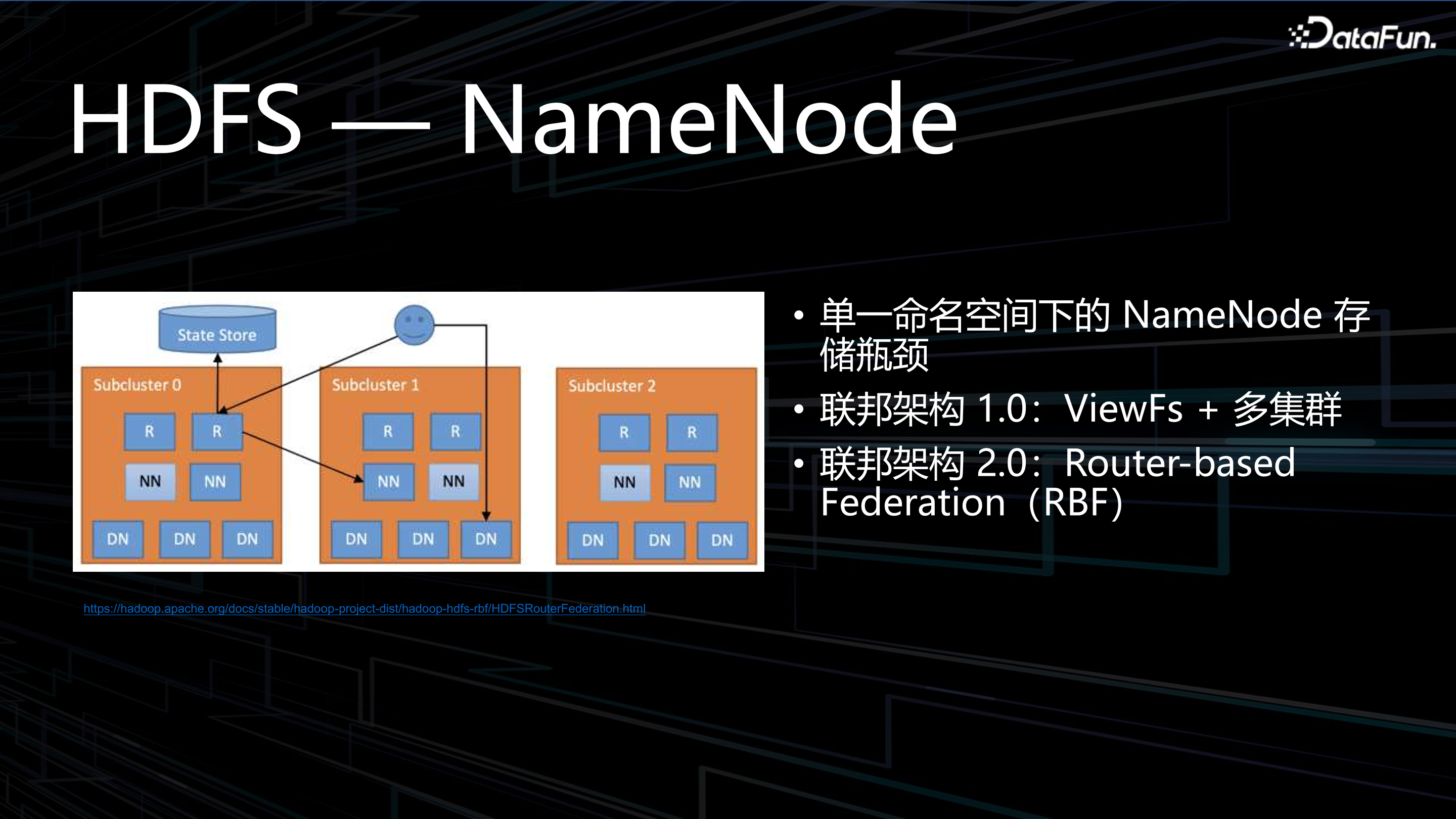
HDFS 最大的弱點是 NameNode。HDFS 最開始設計時並沒有考慮到今天的資料規模,NameNode 一直以來都是垂直擴充套件方案。在 Scale Up 的擴充套件模式下,隨著單個 HDFS 叢集、單個 NameSpace 檔案數量增加,NameNode 記憶體開銷也在增大。由於單個節點記憶體是有上限的,因此常用的解決方法是增加記憶體,例如將記憶體擴容到 1TB。儘管聽起來可行,但是 1T 記憶體的 NameNode 運維是很恐怖的,Failover 需要耗時兩到三個小時。因此,在高可靠性、高可用性場景下,NameNode 是不會做到這麼大例項的。
業界常用的解決辦法是:聯邦架構 1.0,ViewFs+多叢集;聯邦架構 2.0 ,Router-based Federation(RBF) 聯邦方案。這兩種方案表面上解決了橫向擴充套件難題,對使用者而言並不是完全透明的。針對路徑感知、擴縮容感知等情況,仍然需要知道 Router 的細節。因此,並沒有透明的、簡單的橫向擴充套件方案實現 HDFS 單個 NameSpace 對 10 億、100 億檔案的管理。
4. 物件儲存阿克琉斯之踵--後設資料

物件儲存的弱點是後設資料管理。比如,如何實現檔案目錄改名?如果在硬碟上或者檔案系統中執行 mv 命令則可以把目錄改名,在檔案系統執行這個命令的過程中是原子操作,只需要找到這個目錄名字對應的 inode 改名即可。在物件儲存中沒有原生目錄,只是把目錄路徑看作一個字串作為物件的 key,所有物件都是平鋪的,彼此之間沒有任何關聯的資料結構。在物件儲存中儲存物件要先建立一個 bucket,這個 bucket 的名字其實非常形象,意味著裝進去的那些物件沒有任何層次結構。
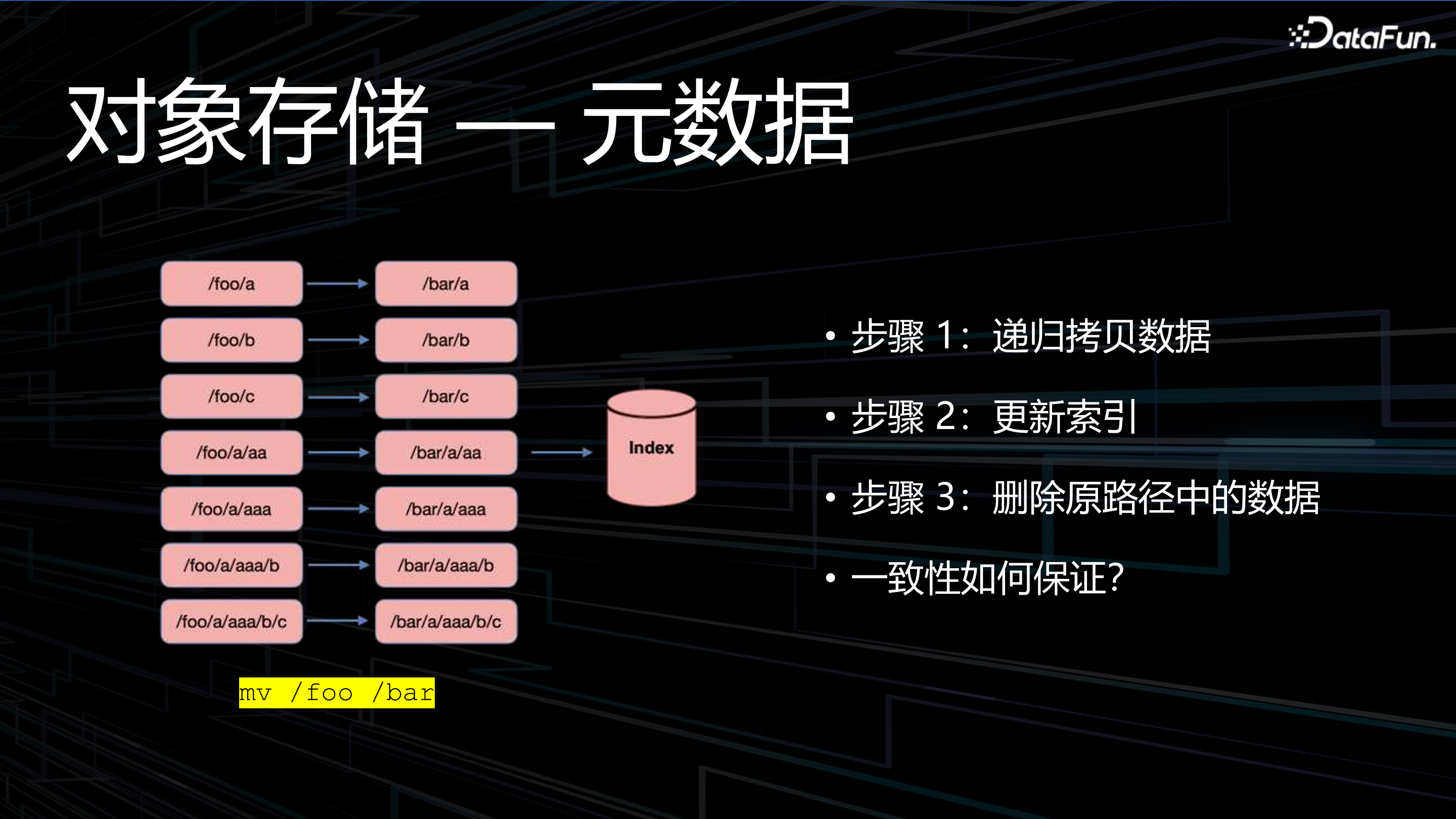
假設以 /foo 字首的 key 有 100 萬個物件,如果要想把 /foo 改個名,會對後設資料做全量索引搜尋,找到所有以 /foo 為字首的物件,可能是 10 個、10 萬個、100 萬...取決於 key 的命名,找到全部符合 key 字首的物件後做一次完整的 IO 複製,資料可能是 1G、100G、100T...取決於這些物件的資料量,使用新名字複製為一批新的物件完成後,再去刪掉舊的物件。這就是在物件儲存裡面完成一個 rename 的過程。
Mv 這個命令在檔案系統裡面是個原子操作,在物件儲存中顯然不是原子操作,它有多個步驟,並且這些步驟的執行是沒有事務保障的,實際上這個過程是分階段完成的。因此可能會引起兩個問題:第一,假如執行到一半出現當機,重啟後只能去重新執行 rename 操作,重新複製、重新刪除,時間代價是很高的;第二,機器沒掛,但是過程中消耗 IO 量比較大,需要幾秒、幾分鐘、幾小時、甚至更長的時間,在這個過程中若別的程式同時在訪問資料,則會引起資料不一致的問題,這也是物件儲存大多是最終一致性的原因。物件儲存僅僅對最終一致性負責,過程中的耗時情況、開始時間、結束時間等對開發者也是不可見的。執行在這個過程中的問題是無法復現的,因為當我們想復現的時候,過程已經執行結束了。
什麼時候要改名呢?舉個 ETL 的例子。比如在執行 Spark 任務時,在進行 map reduce 計算時,有一些分支結束後會先提交到臨時目錄中,當所有的 worker 都結束時,最後要將臨時目錄改名。在 HDFS 裡最後提交的過程是可以忽略不計的;在雲上用物件儲存執行同樣的任務,commit 時可能會持續很長一段時間,就是 rename 過程的開銷有很大不同。

執行 ls 命令的效率在不同儲存系統上也有質的差別。大家會有意識的不在單一目錄下放太多檔案,比如某個目錄下有 100 萬檔案執行 ls 時會卡、1000 萬檔案執行 ls 會卡更久。
在物件儲存裡是什麼樣的?在檔案系統中,整個目錄樹對應了一個樹形的資料結構,在物件儲存中所有物件是平鋪的,沒有樹型資料結構,會把所有的 key 的字串字首做個全文索引,上圖展示了針對不同檔案數量在物件儲存 S3 中執行 listing 帶來時延的差別。在 Hudi 文件測試中,100 個檔案 50ms、100K 個檔案 9s,在物件儲存裡面對大量物件做 listing 遍歷時,效能代價是不能忽視的。為了解決這個問題,Hudi 提出了 Metadata Table 改進方案用於獨立記錄所有後設資料,因此不需要在物件儲存裡直接調 ls 了,使用 Metadata Table 會更快。
在公有云物件儲存上,所有訪問都是透過 HTTP API 呼叫的,並有 QPS 限制,以 S3 舉例,它在每個字首上預設的 get 請求 QPS 是 5000,put 請求 QPS 是 3500,如果達到 QPS 上限則返回 400 錯誤碼,但是它會在一段時間後使用字首進行再分配,慢慢地增加這個 QPS,這可能是在系統沒有達到一定負載程度下開發者難以注意的問題,等碰上了想解決這個問題時,就會發現已經很困難了,因為整個 prefix 字首可能已經按照業務最理想的表達方式寫過了。為了解決這個問題,在 Iceberg 裡做了最佳化,設定一個引數宣告一下,如果是物件儲存,可以 enable 這個開關,後面也會進一步講到。
5. Lakehouse 對檔案系統的需要

Lakehouse 文件中,對檔案系統提出三個具體的需求:一、原子語義,比如上文提到的物件儲存上 rename 是沒有原子語義的,但希望 Lakehouse 下面的儲存系統是有原子語義的;二、併發寫的能力;三、強一致性的能力,比如上文提到的在對大量物件改名的過程中做 listing 出現不一致的情況是不符合一致性要求的。
03 JuiceFS 的設計
2016 年,我們有了做 Juice FS 的想法。當時在 Databricks 內部的 S3 儲存平臺上跑批大量的大資料任務時碰到了很多痛點,當時還沒有提出 Data Lake、Lakehouse 等概念,因此我們開始思考能否把檔案系統的能力和雲上 S3 的優勢結合起來。比如檔案系統裡面有原生的目錄樹、有一套使用方便的 API、有強一致性保障等;S3 有彈性伸縮、免運維等好處。於是我們提出將這兩種儲存系統的優勢在雲上融合,為開發者提供更適合大資料使用的儲存方案。
1. 什麼是 JuiceFS

實際使用中,S3 雖然解決了一些規模上的瓶頸,但還有後設資料效能差、沒有原子 rename、沒有強一致性保證、併發寫入限制、API QPS 限制、API 呼叫成本高等痛點。比如,將一個 HDFS 的叢集搭起來後,無論如何使用它,都不會為每一個 request 付錢,但是 S3 上的每一個 request 是要交錢的,並且費用是不同的,分兩類計費。其中 Listing API 是 Get API 價格的十倍。在 ETL 的過程中需要大量使用 Listing API 做資料發現,成本極高。如何解決客戶使用物件儲存的痛點、難點是當時和今天仍然迫切的需求。
無論是 Data Lake,還是 Lakehouse,還是其他的概念,底層都需要有一個更好用、更適合的檔案系統,才能解決今天這個資料規模上的各種痛點。

從 2017 年起,JuiceFS 專案啟動,當時還不是開源的,以服務雲上客戶為核心,透過雲服務方式做了 6 年。在這個過程中,我們發現不僅大資料上有檔案儲存需求,其他很多場景也有同樣的需求,因此我們在 2021 年釋出了開源社群版,為開發者提供了更開放的選擇,在不同的場景中可以做一些自定義組合。不論是商業版還是社群版使用的使用者都有很多,主要圍繞著 AI 和大資料這兩個場景。
2. JuiceFS 架構

社群版架構圖如上圖左所示。圖中三個虛線框分別代表了檔案系統中最主要的三個核心元素,左下角是後設資料引擎、右下角是資料持久化引擎、上面是用來訪問資料的客戶端。這三個元件和 2005 年 Google 發表的第一篇 Google File System 論文裡的頂層架構是一樣的。那篇論文的第一個開源實現就是 HDFS,同樣在這篇論文的方向的指導下,我們設計出了更適合雲環境使用的 JuiceFS。
JuiceFS 與 HDFS、Ceph 等其他分散式檔案系統的區別是什麼?資料持久化這一層以前都是面向很多節點、很多磁碟的,需要先將這些節點和磁碟做一個管理服務,包括資料寫入方式、副本配置方式、IO 讀寫路徑等,類似 HDFS DataNode 的角色。JuiceFS 的實現並不是這樣,它藉助公有云已經提供的物件儲存作為基礎設施。
物件儲存管理海量硬碟的能力已經很強大了。我們將 S3 或者其他物件儲存看成一個無限容量、彈性伸縮的大硬碟,其中 Metadata Engine 相當於這塊硬碟的分割槽表,比如當我們的電腦需要增加硬碟時,首先要在電腦插上一塊硬碟,然後格式化一個分割槽格式。Metadata Engine 就相當於格式化出來的一個分割槽表,用於管理檔案系統裡面目錄樹、檔名、時間戳等資訊。
JuiceFS 的 Metadata Engine 引擎與以往的分散式檔案系統最大的不同是,JuiceFS 是一個外掛式架構,支援十幾種不同的開源儲存引擎,比如 KV 儲存、關係型資料庫等。JuiceFS 的 Metadata Engine 這樣設計可以藉助已成熟的儲存引擎為社群的開發者降低使用門檻,因為在社群中推廣自研的分散式引擎並讓使用者理解、掌握、積累運維經驗的過程是很漫長的,而如何運維好 Redis、MySQL 已經有非常豐富的經驗,而且在雲上有託管服務,不需要使用者自己運維。
儘管這些引擎經過了十幾年的驗證、成熟穩定,但是它們作為檔案系統使用不一定是最優的,要結合使用場景來看。JuiceFS 在開源之前已經做了三年多的商業化,在此期間我們發現市場上對於檔案儲存的應用有著非常廣泛的需求,不只是大資料和 AI 場景。
在不同的場景上,大家對於檔案規模、容量、效能、可靠性、可用性、成本這些維度的優先順序排序是不同的。我們認為架構的選擇上沒有銀彈,沒有哪一款引擎能夠完美解決所有場景需求,因此我們做一款更開放式的外掛引擎,使用者可以結合自己場景、經驗,選擇一個合適的儲存引擎做 JuiceFS 的 Metadata Engine。
Data Storage 持久化也是外掛式架構,相容了現在市場上所有的物件儲存服務。
Client 客戶端與以前的檔案系統的差別在於 JuiceFS 相容了三種最主流的標準:首先,提供了 POSIX 的完整相容,POSIX 從上個世紀 80 年代開始迭代到現在,是檔案系統標準的最大集,因此完整地支援 POSIX 標準就意味著已經能夠和過去 40 年的各種應用系統直接相容;其次,提供了 Java SDK 完整相容 HDFS API。在大資料生態裡面中只有 POSIX 是不夠的,JuiceFS 同時相容 HDFS 的 2 和 3 版本;最後,提供了 S3 API 相容,S3 從 2006 年釋出到現在也已經積累了大量用 S3 API 寫的程式碼。這樣,JuiceFS 完美解決了更換儲存系統需要改一遍程式碼的難題。
關於資料儲存在 S3 上面的效能最佳化問題,JuiceFS 在客戶端裡面做了快取層。意味著在大資料、AI 讀場景下,所有讀到的資料都可以在客戶端建立快取,下次再讀同樣資料的時候就可以在快取中找到了,在快取層可以用 SSD 做效能提升。因此,對於數倉查詢、AI 模型訓練等場景,讀快取發揮著非常重要的作用。
JuiceFS 內部的功能實現如上圖右側所示。很多使用者會問 JuiceFS 和 Alluxio 對比有什麼區別?
Alluxio 的定位是在現有的儲存系統之上提供快取加速層,在實際專案中儲存系統大多是物件儲存系統;JuiceFS 的定位是為雲環境設計的分散式檔案系統,可以透過快取機制加速資料訪問。在使用 JuiceFS 時,寫入檔案與 HDFS 類似,會做大檔案拆分,將檔案拆分後的資料塊儲存在物件儲存中,一般按 4M 的 block 塊儲存在物件儲存裡。這樣的架構設計提供了完整 POSIX 相容、資料儲存強一致性、覆蓋寫和追加寫、快取一致性保障等核心能力。JuiceFS 是一個檔案儲存的服務,而不是透明的快取加速層。
3. 儲存系統比較
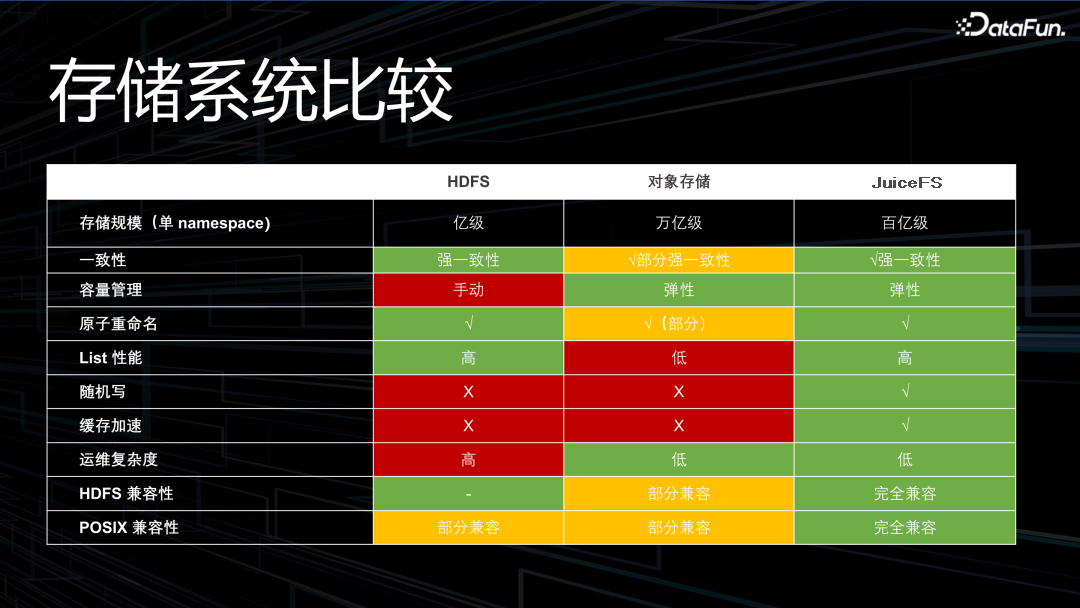
對 HDFS、物件儲存、JuiceFS 進行對比,如上圖所示。
宏觀上 JuiceFS 在單個 namespace 下可以存百億級的檔案。不過 JuiceFS 支援了十幾種不同的後設資料引擎,並不是每個引擎都能存百億。比如,TiKV 的社群使用者實踐有很多過百億的,我們自研的商業引擎也可以,但是 Redis 和 MySQL 不能。
一致性上實現了 Read-After-Close 強一致性保障。
容量管理上,基於 S3 的底層儲存是彈性的。在完整的 POSIX 相容情況下,原子重新命名、List 的效能等都得到了保障。
在相容性方面也做了很強的最佳化。通常相容性是選擇新系統時需要考慮的重要事情,即不用修改程式碼即可引入新系統。
4. JuiceFS 與 HDFS、物件儲存後設資料效能比較
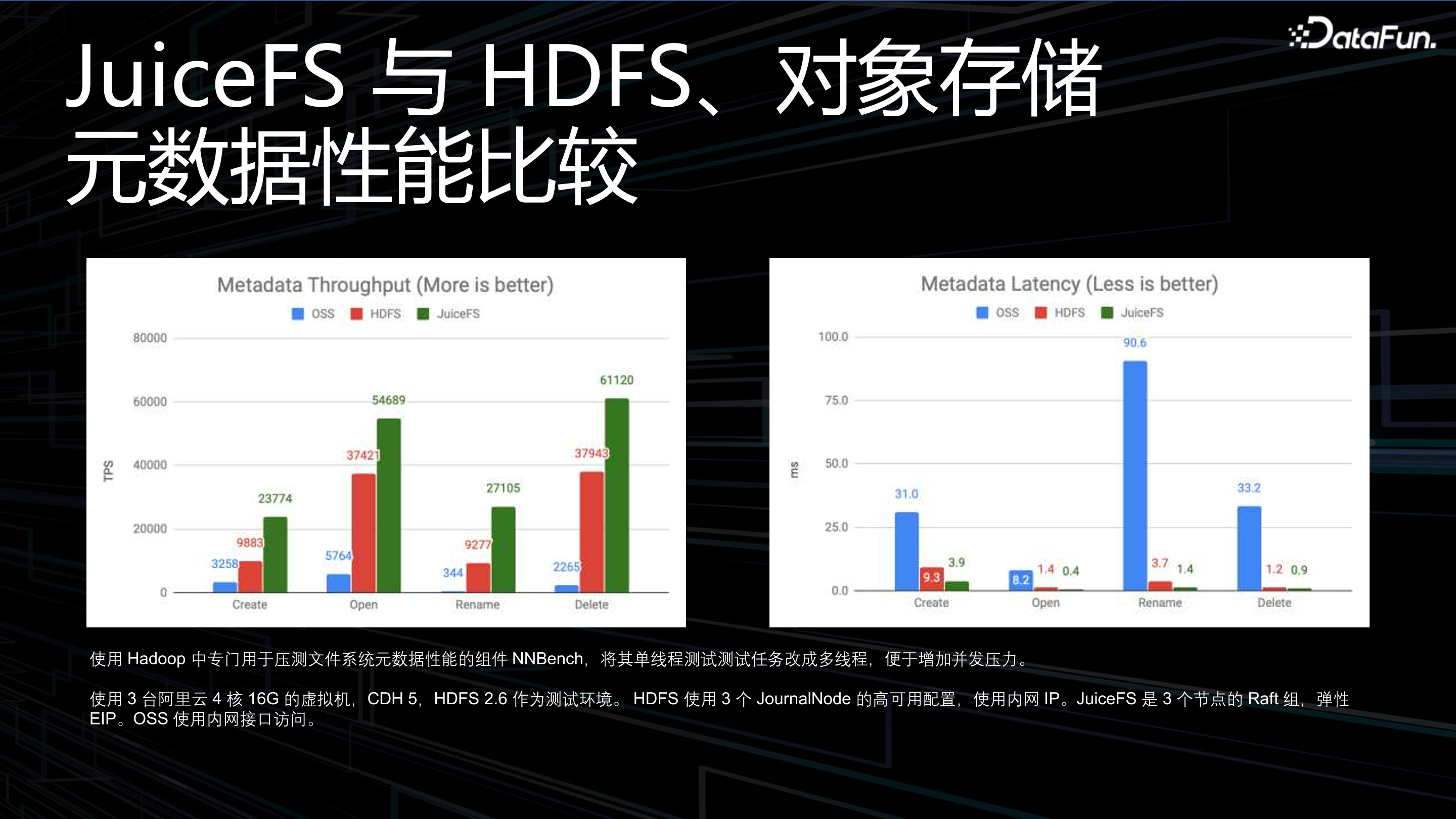
JuiceFS 與 HDFS、物件儲存後設資料效能比較,如上圖所示,比較點有兩個:吞吐和時延。在吞吐量上,JuiceFS 比物件儲存和 HDFS 更有優勢,在單機情況下或者同配置情況下 JuiceFS 可以獲得更高 QPS。在時延上,JuiceFS 執行 rename 操作時,時延優勢是最明顯的,物件儲存和檔案系統之間相差近 100 倍。
5. JuiceFS 快取加速與 HDFS 效能比較
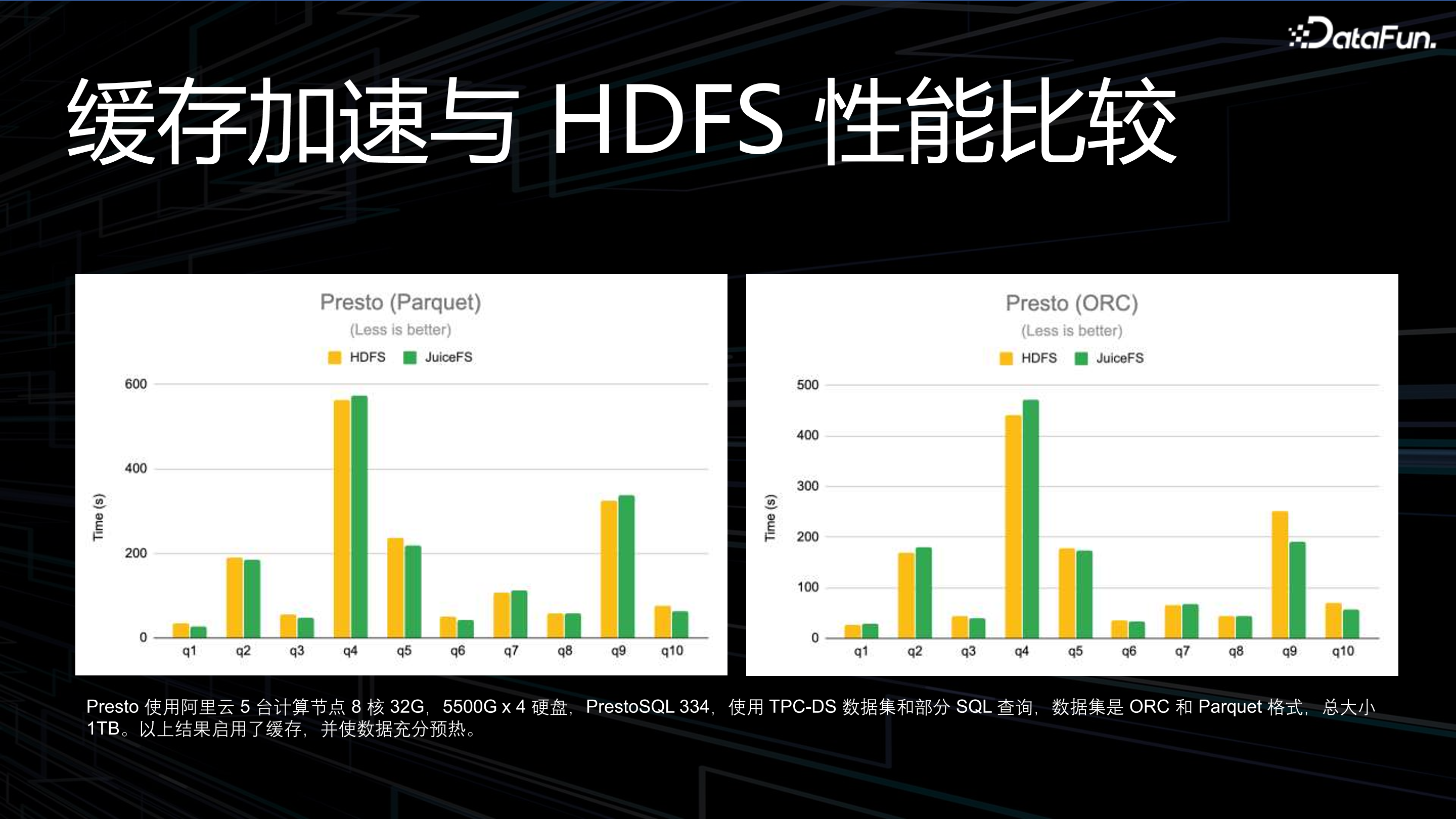
基於 TPC-DS 資料集,測試 HDFS 和 JuiceFS 查詢效能之間的比較,如上圖所示。HDFS 具備存算耦合、資料本地性的特徵,實現查詢效能加速。存算分離以後會下降多少呢?TPC-DS 前 10 個 query 重複執行,即資料預熱到快取中時,JuiceFS 與 HDFS 的表現是一樣的。
6. Lakehouse 對檔案系統的需要

在 QPS 限制上,S3 有自己的限制,其他公有云也有類似的限制。Iceberg 的做法是,在物件儲存場景中,在 key 前面去加一個隨機雜湊值。JuiceFS 自動將檔案切分成很多 block 後,形成多級的 prefix,這個多級的字首也能夠提升 API 的 QPS。
除此之外,因為有快取的存在,在資料讀取時,可以優先命中快取,進而降低了後端物件儲存在儲存和 QPS 的壓力。其次,listing、rename 等操作只發生在 JuiceFS 後設資料引擎中,不用再請求到物件儲存,因此,JuiceFS 對下面物件儲存的 API 依賴就只有 get、put、delete 這三個最基礎 API 了。
04 使用者案例分享
1. 使用者案例-某上市集團 K12 教育業務

某上市集團 K12 教育業務資料平臺。在資料湖場景上,透過 Hudi + JuiceFS 方式收集上游不同資料來源 CDC 的資料。以前在沒有資料湖情況下,ETL 是幾小時的時延;引入資料湖後,將原始資料 CDC 入湖,資料馬上就可以被查詢引擎使用,資料時延從幾小時縮短到 10 分鐘。
2. 使用者案例-豆瓣

豆瓣在 2019 年完成了將所有作業從機房遷移上雲的過程。在機房中使用的是 MooseFS ,它也是一款支援 POSIX 的檔案系統。上雲之後沒有選擇重建 MooseFS,而是用了雲上託管的 JuiceFS 服務。
由於兩個 POSIX 檔案系統之間很容易平移,所以它把日誌、CSV、數倉的列存檔案、演算法等這些各種各樣的資料都遷移了上來,並在數倉上增加了 Iceberg,與上一個案例類似,也是引入了資料庫 CDC 採集,為豆瓣的一些演算法提供更實時的資料訪問。今天使用者所有收藏、打分、點選等資料,都可以更快地進入資料湖裡供給演算法使用。
05 從 BI 到 AI

前文中分析了不同儲存系統之間的差異。從業務角度來看,在過去 6 年中我們發現越來越多的資料平臺將資料提供給演算法團隊使用,包括機器學習和深度學習。從最開始使用數倉解決搜尋、廣告、推薦等業務,資料更偏向於數值型,比如使用者畫像;到今天除了數值型以外,還有了更多非結構化資料,比如聲音、文字、圖片等等,都融入進來。
如何把這些非結構化、半結構化的資料統一地管理在一起?如上圖右所示,以前的解決方案是使用幾套不同的儲存系統。
在機器學習中,資料 pipeline 上分幾個不同的階段,從最開始的資料產生,到預處理,再到特徵工程、訓練,最後到模型出來後能夠做推理,整個過程中每一個環節都依賴於上游應用,每個過程都有用起來更舒服的資料訪問 API 偏好。
比如,資料生成團隊主要是把產生的資料儘快存下來,選用 S3 是最簡單的方案。資料做預處理時,很多人使用 Spark 或 Ray 分散式計算框架進行資料處理。特徵工程部分,大多使用 Python 寫程式碼,將圖片、聲音向量化。到了模型訓練時,PyTorch、TensorFlow 等訓練框架都對 POSIX 支援的很好。
在這個過程中,以前需要從物件儲存、檔案系統等不同系統來回搬運資料,資料交接效率比較低。而 JuiceFS 支援數倉資料、原始資料、非結構化資料存放到一起,每一個環節需要的訪問介面都可以直接對接上。
06 總結

最後,再回顧一下本次分享的核心內容。
JuiceFS 在大資料的生態裡面提供了 HDFS 2 & 3 完整的相容性。
在資料平臺裡面接入時,可以不用改程式碼而是直接透過改配置的方式接入進來,支援現存的 HDFS 和物件儲存體系共同使用。
在路徑上,比如 HDFS 路徑是 hdfs://,到 JuiceFS 上是 jfs://。
在數倉中可以按表、按列指定不同的 location,在實際使用中很多的使用者會先保持現有的 HDFS 不動,然後將 JuiceFS 作為溫冷資料儲存,溫冷的資料 partition 在後設資料裡改變 location 即可,這個過程對上層的使用者是完全無感的。
在資料湖方面,JuiceFS 已經支援了 Hudi、Iceberg、Deltalake。
前面介紹的案例中,使用者都是在保留原有數倉架構的情況下引入了 Hudi、Iceberg 等新的元件支援某些業務,進而更快地處理、呈現實時業務流資料。
當 AI 業務要做更深的資料融合時,JuiceFS 能夠給大家帶來更多的便利。
來自 “ DataFunTalk ”, 原文作者:蘇銳;原文連結:https://server.it168.com/a2024/0201/6838/000006838957.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 小米大資料儲存服務的資料治理實踐大資料
- CNCC技術論壇|分散式資料庫HTAP的探索與實踐分散式資料庫
- 雲原生技術領域的探索與實踐
- 資料庫儲存與索引技術(三)LSM樹實現案例資料庫索引
- Android的3種資料儲存技術(一)File儲存Android
- 大資料儲存平臺之異構儲存實踐深度解讀大資料
- OpenStack Cinder與各種後端儲存技術的整合敘述與實踐後端
- vivo直播應用技術實踐與探索
- 乾貨:PHP與大資料開發實踐PHP大資料
- 資料庫治理的探索與實踐資料庫
- 大眾點評搜尋相關性技術探索與實踐
- 詳解Android資料儲存技術Android
- 美團儲存雲原生探索和實踐
- 大模型儲存實踐:效能、成本與多雲大模型
- 前端資料層的探索與實踐(一)前端
- 前端資料層的探索與實踐(二)前端
- 衛星影像識別技術在高德資料建設中的探索與實踐
- 浪潮資訊孫斌:浪潮儲存系統設計的技術探索、選擇與思考
- B站在實時音影片技術領域的探索與實踐
- 大話儲存——磁碟原理與技術筆記(一)筆記
- 宜信OCR技術探索與實踐|直播速記
- 中國銀行雲原生技術探索與實踐
- 浪潮儲存以技術探索新資料時代,智慧未來讓人期待
- 資料儲存技術的演進趨勢研判
- Spring Boot資料儲存最佳實踐 - AhadSpring Boot
- vivo資料庫與儲存平臺的建設和探索資料庫
- iOS開發資料儲存篇—iOS中的幾種資料儲存方式iOS
- OCR技術發展綜述與達觀資料的實踐經驗
- 技術集錦 | 大資料雲原生技術實戰及最佳實踐系列大資料
- 後臺開發 -- 核心技術與應用實踐
- Shopee ClickHouse 冷熱資料分離儲存架構與實踐架構
- 斷電也能儲存資料的MRAM技術精髓
- 大資料開發技術學習方向大資料
- 資料庫智慧運維探索與實踐資料庫運維
- 分散式系統中的資料儲存方案實踐分散式
- 區塊鏈技術應用資料上鍊儲存軟體系統開發區塊鏈
- 從Google Spanner漫談分散式儲存與資料庫技術XAGo分散式資料庫
- 文字輿情挖掘的技術探索和實踐