美團儲存雲原生探索和實踐
本文根據楊立明老師在【第十三屆中國資料庫技術大會(DTCC2022)】線上演講內容整理而成。
本文摘要:儲存計算分離架構是雲原生技術在業務落地的底層重要支撐技術之一,本次分享將介紹美團基礎技術部儲存團隊在儲存計算分離架構上的一些探索,重點是介紹美團的分散式儲存底座MStore的技術架構,以及基於MStore建設其他PaaS元件和業務系統的一些思考和實踐,幫助業務系統實現儲存計算分離架構的落地,提升整體系統的擴充套件能力。
雲原生簡述
雲原生技術使組織能夠在新式動態環境(如公有云、私有云和混合雲)中構建和執行可縮放的應用程式。容器、服務網格、微服務、不可變基礎結構和宣告性API便是此方法的範例。
這些技術實現了可復原、可管理且可觀察的鬆散耦合系統。它們與強大的自動化相結合,使工程師能夠在儘量減少工作量的情況下,以可預測的方式頻繁地進行具有重大影響力的更改。——“雲原生計算基金會”
總結來說,雲原生技術具有敏捷性、靈活性、可靠性、可伸縮等特點,為企業提供了巨大的生產力,這也是公司近幾年基礎架構的迭代方向。
儲存計算分離與雲原生
當前,美團基礎架構為存算一體架構,儲存系統正面臨如下問題:
儲存擴充套件能力弱:在計算資源達到瓶頸需要擴容時,仍然需要遷移資料,遷移資料的時間跟資料量線性相關,所以,對於資料量較大的業務,擴容操作時間會很長。
機器成本高:儲存計算資源耦合在一起,如果叢集因為CPU計算能力達到瓶頸,我們就需要擴容,而往往這時節點的硬碟空間還很空閒。反之亦然,儲存和計算資源經常會有一方存在機器資源浪費。
重複研發和運維成本高:這些儲存元件基本上要考慮副本冗餘、副本資料一致性、資料正確性校驗,副本缺失補副本,擴容縮容等問題,因此存在著重複研發和運維問題。
不能很好的滿足業務多樣化需求:比如我們現在需要提供一個分散式檔案系統服務,基本上我們需要從零開始研發,研發進度會很慢,不能很好的滿足業務的需要。
以上這些問題阻礙了公司雲原生的建設,因此,我們設計並建設了儲存與計算分離的系統,來更好的滿足雲原生的迭代。
存算分離架構的優勢和挑戰
優勢:
擴充套件能力強:上層儲存服務模組實現無狀態化設計,可實現秒級擴縮容,無需資料遷移。
產品快速迭代:基於底座,可以最大程度複用其通用儲存能力,來適應業務需求,快速開發出新的儲存產品
降本增效:儲存計算分離,避免了叢集的儲存、計算資源錯配造成的資源浪費。統一底座服務使得上層儲存無需重複研發資料分佈、副本、容災等機制,大幅降低研發成本。
挑戰:
穩定性:作為其他儲存底層的底座儲存,一旦出現穩定性問題,將會影響其他所有儲存服務,進而影響到上層業務。
效能:分層架構後,相對於存算一體的服務,增加了一跳的網路延遲。儲存底座的吞吐很大程度上也決定了上層儲存服務的吞吐。
Mstore總體介紹
針對上述優勢和挑戰,最終我們採用了分散式儲存底座MStore的技術架構。MStore設計目標是為各種儲存服務抽象出公共底座,提供似Posix的簡單檔案介面,對接塊儲存系統、檔案儲存系統、物件儲存、表格儲存、資料庫、大資料等業務。
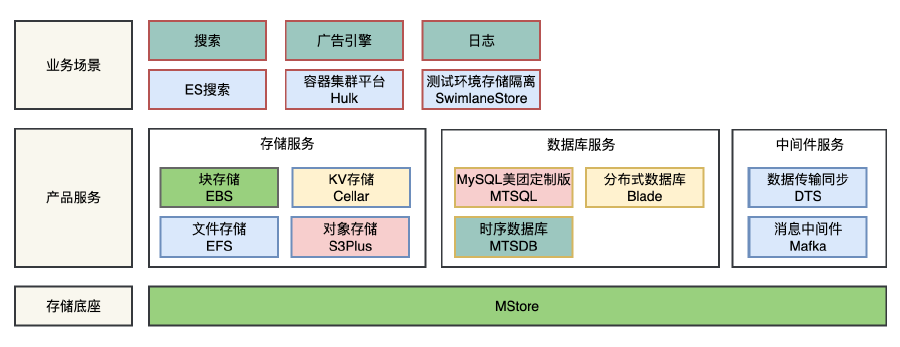
Mstore整體架構
MStore儲存系統有4個子系統:RootServer、MetaServer、ChunkServer、SDK。
RootServer:叢集的入口,管理著整個叢集中資源資訊,包括MetaServer、ChunkServer、磁碟等資訊。
MetaServer:管理著使用者資料的元資訊,包括Blob、Blob由哪些Chunk構成,Chunk和ChunkServer的對映關係等。MetaServer在叢集中可以有多組,使得元資訊管理能水平擴充套件。
ChunkServer:使用者資料儲存服務,對使用者資料的序列化儲存、校驗。接受使用者讀寫請求,接受MetaServer資料複製、負載均衡等請求。
SDK:提供給使用者的Library,使用者可以透過連結這個Library訪問MStore的儲存服務,類檔案系統API。
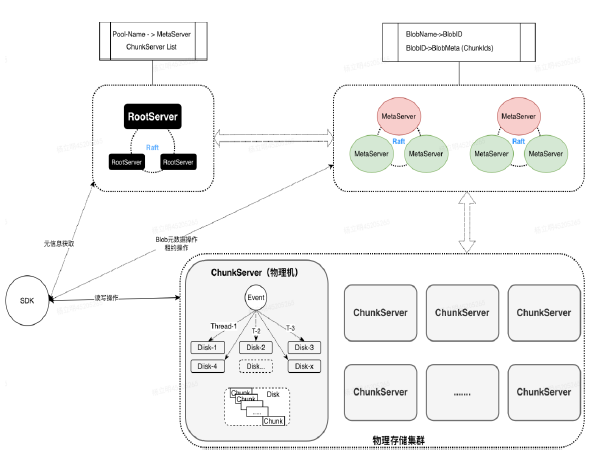
Mstore的Blob
Blob是Mstore提供給使用者使用的物件,類似於檔案。Blob是由多個Chunk組成,以便將Blob做分散式儲存,Chunk的大小預設為64M。
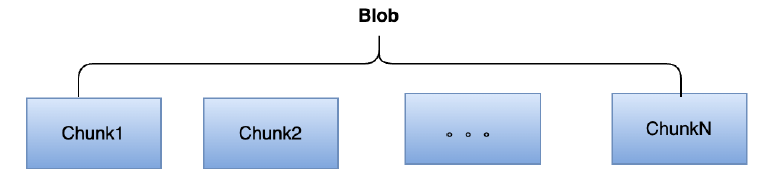
為了滿足不用的應用場景,目前我們提供兩種型別的Blob,LogBlob用於支援追加寫、ExtentBlob用於支援隨機寫。系統通常是將資料寫到LogBlob,然後後臺回刷到ExtentBlob。
Mstore後設資料
後設資料主要分為兩類:資源資訊和使用者資料。RootServer管理所有的硬體資源,整個叢集只有一組。MetaServer管理使用者資料,可以有多組,可以水平擴充套件。後設資料節點透過Raft機制保證資料的可靠性、高可用。

Mstore資源管理
叢集資源由RootServer(RS)統一管理,RS是資源增刪和分配的入口。主要的資源資訊包括:MetaServer組資訊、ChunkServer資訊、磁碟資訊、PhysicalPool資訊、LogicalPool資訊。
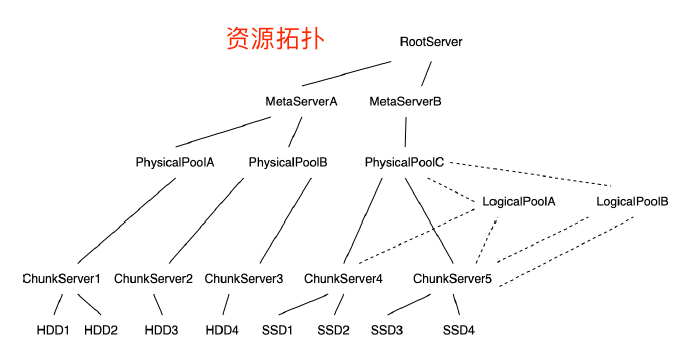
Mstore資源控制
PhysicalPool是物理磁碟的集合,一個叢集可以包含多個物理Pool,一般一個Pool中的資源規格是一樣的。
LogicalPool是對物理資源上的邏輯劃分,一個物理Pool中可以建立多個邏輯Pool。
LogicalPool概念是暴露給使用者的,使用者可以根據自己的需要對業務做邏輯Pool的劃分。
LogicalPool為單位定義QoS,包括服務能力的上限、下限、權重等。
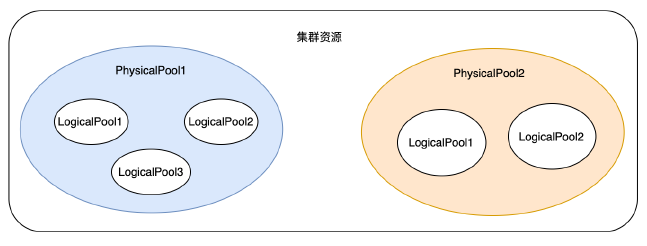
Mstore使用者資料
使用者資料,需要MetaServer決定放置在哪塊盤上,放置策略需要考慮的因素主要有:保證一個rack只能有一個副本,寫本地一份,遠端多份的需求,機器和磁碟容量大小,同城多機房的需求。
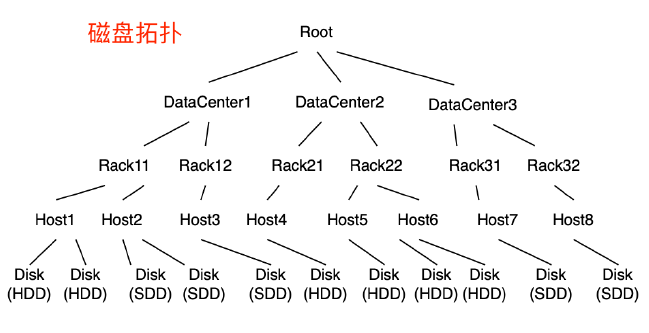
Mstore星型寫
控制流方向,SDK不會頻繁和RootServer和MetaServer互動,只有在申請新Chunk是才去互動。
資料流方向,SDK採用併發同步寫三副本的方式,保證資料強一致,架構上更簡單,相比Raft等共識協議減少了網路一跳,降低延遲。
星型寫不支援多點,上層服務需要控制對其資料的多點讀寫請求。
快速切換技術,在星型寫三副本失敗時,不需要馬上修復資料,透過快速重定向到新的三副本使得故障瞬間恢復。

Mstore一次IO技術
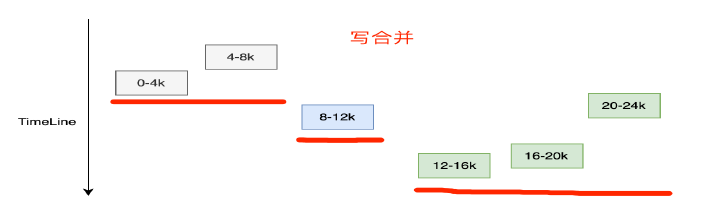
為了減少對磁碟的IO佔用,我們對寫請求做了合併,讓多使用者請求轉換成一次磁碟請求。

對磁碟儲存格式的最佳化設計,使得每次磁碟請求只產生一次IO,這是效能優於Ceph的原因。
使用者請求邊界儲存在儲存格式的Header結構中,使得異常恢復時能區分請求的邊界,實現寫請求的原子性。
此外儲存格式的Header中還儲存了資料的CRC資訊,保證資料的正確性。
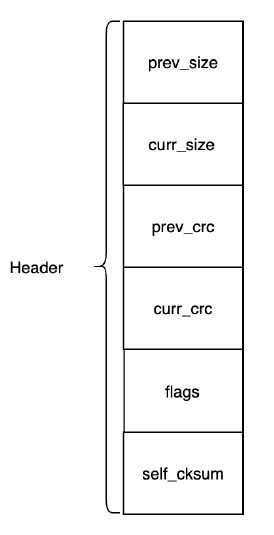
Mstore——儲存格式Header
儲存格式Header包含以下欄位:
1.prev_size前一個請求的size
2.curr_size當前請求的size
3.prev_crc前一個請求的checksum
4.curr_crc當前請求的checksum
5.flags一些標識位
6.self_cksumHeader本身的checksum
Mstore資料版本
Mstore儲存的使用者資料是有版本的,根據資料的版本可以實現:版本號遞增,寫請求透過版本保證請求的連續性;讀取資料帶上版本號,保證讀取的副本是新的;資料巡檢服務根據資料版本保證合法的副本。

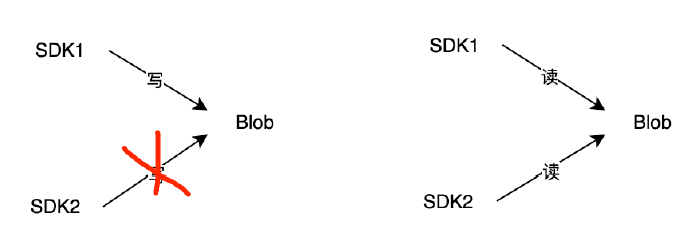
Mstore資料讀寫規則
Blob只能單點寫,透過租約機制做互斥。
Blob支援多點讀,由使用者負責同步多個節點的版本。
Mstore可觀測性
Mstore系統已經擁有完善的監控、告警體系。為了讓系統能夠以更加白盒的方式線上上運營,我們實現了Trace能力,目的是能觀測Mstore系統以及其依賴的系統的每次請求各個階段的執行情況。這也有利於後續我們對系統效能做最佳化。Trace已經可以對接美團的Mtrace平臺。

Mstore的Run To Complete執行緒模型
為了最大化降低延遲,我們採用了Run To Complete(RTC)執行緒模型,即:一個請求在生存週期內都由一個執行緒處理。以下為ChunkServer的整體結構。
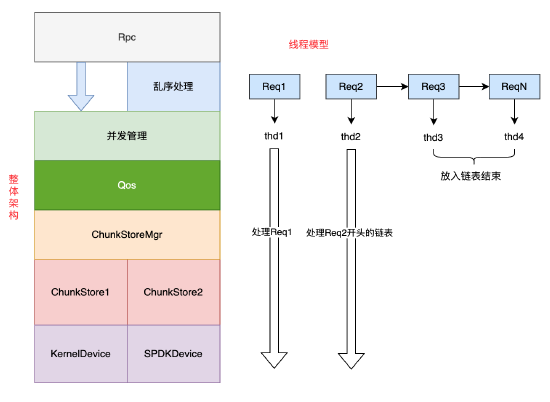
為了增加系統併發度,RTC模型仍然是多執行緒的。不需要互斥的請求(Req1),在本執行緒執行完畢。
需要互斥的請求(Req2、Req3、Req4),這些請求由第一個請求所線上程處理。程式保持簡單,模組從上到下以同步的方式呼叫。
利用C++的RAII技術,在請求析構過程回撥執行連結串列下一個請求,將非同步動作收斂在一處。
Mstore的裸盤系統
經過我們對ChunkServer的效能測試,發現軟體棧中大部分的耗時來自檔案系統操作磁碟,其次是網路IO。下圖是我們使用Trace系統得到的延遲資訊。
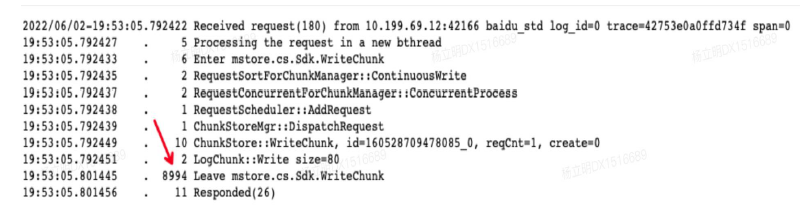
基於以上結論,我們研發了使用者態檔案系統(裸盤系統),它設計成針對Blob特點的磁碟管理方式,簡單、高效。我們在裸盤系統下抽象出BlockDevice層,使其能適配不同的裝置,如SPDK、IOuring等。目前我們使用SPDK作為磁碟驅動,實現ChunkServer全棧使用者態。
裸盤系統的後設資料包括,SuperBlock區、BlockTable區、ChunkTable區,Padding區是預留的未使用空間,剩下的是資料區。
SuperBlock區:裸盤系統的整體資訊,磁碟號、是否格式化、Block數量、Chunk數量等。
BlockTable區:記錄系統資料塊的分配情況。
ChunkTable區:記錄系統Chunk的分配情況。
Chunk在建立時候在ChunkTable申請一個儲存區域,記錄Chunk的元資訊,刪除Chunk的時候歸還這塊區域給ChunkTable。
Chunk在寫入資料的時候會在BlockTable裡面申請一個Block,刪除Chunk的時候會把Chunk的所有Block歸還給BlockTable。
Chunk的Block按照寫入的順序以鄰接表的形式儲存在BlockTable中。
Mstore的系統延遲
ChunkServer自身延遲約26us,其中spdk佔用11us,後續將對ChunkServer各個模組精細最佳化。
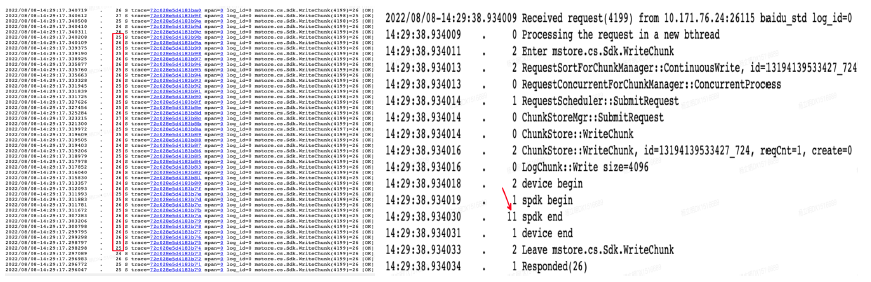
Mstore的系統吞吐
我們還做了ChunkServer的壓力測試對比,同等壓力下,寫吞吐幾乎是Ext4檔案系統的2倍,延遲比Ext4低很多;讀吞吐也高於Ext4,但是因為Ext4有檔案系統快取,所以相比之下Ext4的讀平均延遲要低一些。後續我們會看需求在裸盤系統基礎上利用OptaneSSD裝置實現快取。
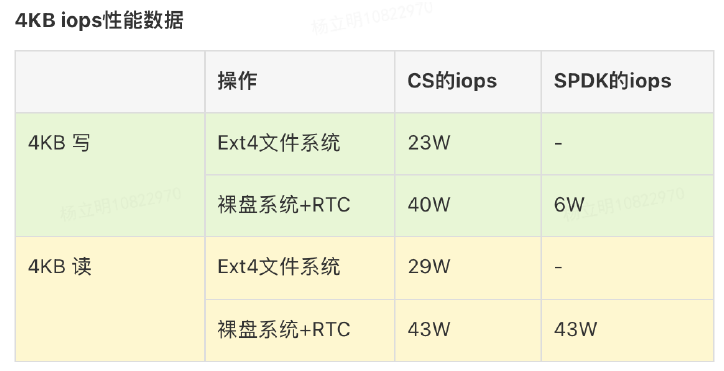
Mstore測試體系
建設Mstore之初我們就考慮系統穩定性的重要,因此我們建設了完善的測試體系。
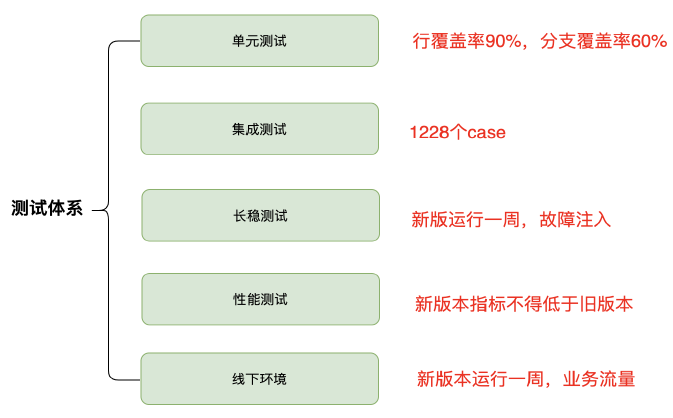
Mstore落地情況
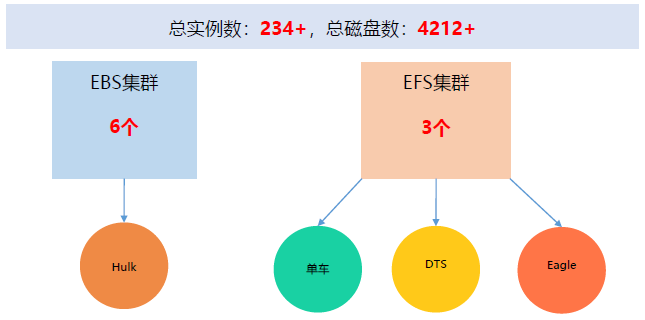
EBS整體架構
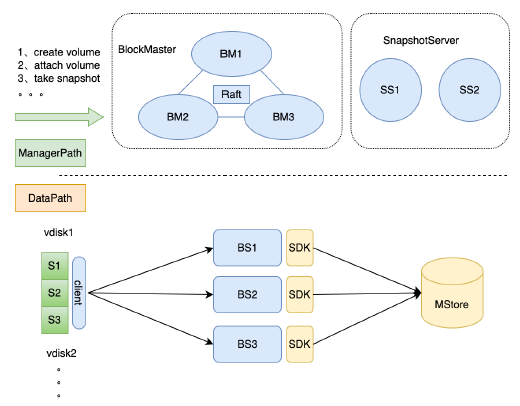
EBS系統(塊儲存)是應用在MStore的第一個專案。EBS有4個子系統:BlockMaster、BlockServer、Client、SnapshotServer。
BlockMaster:塊服務的管理節點,維護塊裝置的元資訊,分配BlockServer。簡稱BM。
BlockServer:塊服務的資料處理節點,接收塊裝置的所有IO。簡稱BS。
Client:塊裝置的客戶端。
SnapshotServer:塊服務的快照伺服器。簡稱SS。
業界對標:
EBS資料組織

一塊盤(Vdisk)被劃分成多個Segment,典型大小64G,一個Segment由某個BlockServer處理。
BlockServer會將一個Segment的所有請求以Writeaheadlog(WAL)的形式寫到MStore的LogBlob。
每個Segment又劃分成多個Entry,每個Entry對應MStore的一個ExtentBlob。
這樣組織資料的好處是:
1、將多個Entry的隨機寫轉化成一路順序寫,起到group commit的作用。
2、每個Entry對應一個ExtentBlob,這樣多個Entry之間沒有聯絡,回刷能並行執行。
3、在讀取的時候如果一個請求跨越幾個Entry,這幾個Entry之間也可以併發的去讀。
EBS索引
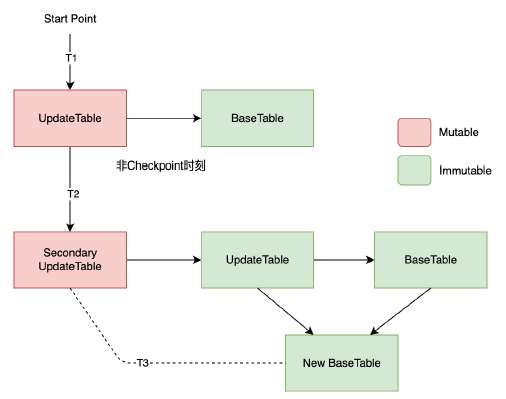
BlockServer處理請求先將資料寫入WAL之後回刷到Entry裡面,為了保證回刷前的資料可讀到,需要在WAL之上建立索引。
索引是全記憶體快取的,索引結構由UpdateTable+BaseTable組成。UpdateTable是可以讀寫的(Mutable),BaseTable是隻讀的(Immutable)。
定期做Checkpoint有利於系統重啟快速恢復,會生成一個新的SecondaryUpdateTable,舊的UpdateTable變為只讀,和原來的BaseTable合併生成一個新的BaseTable。
這麼設計索引的好處是,BlockServer的操作都針對只讀的BaseTable操作,簡化程式處理,減少操作BaseTable的鎖競爭,有利於效能。
EBS回刷WAL

BlockServer會定期把WAL的資料回刷到Entry裡面,按照LogBlob從頭到尾順序回刷。實現過程要注意幾個時間點,才能保證各子系統能正確工作:
1、最舊的Log點、2、Dump的起始點、3、Dump的結束點、4、索引Checkpoint點、5、最新Log點。時間順序:1<=2<=3<=4<=5。
Log回收區:【最舊的Log點,Dump的起始點),這個區間的Log可以隨時被回收掉。
Dump資料區:【Dump的起始點,Dump的結束點),這個區間是Dump操作正在作用的區間。
索引BaseTable表示的區間:【最舊的Log點,Checkpoint點),這個區間表示Checkpoint點之前的所有資料的索引,涉及WAL+Entry。
索引UpdateTable表示的區間:【Checkpoint點,最新Log點),這個區間表示Checkpoint點之後的所有資料的索引,只涉及WAL。
|嘉賓介紹|

楊立明
美團儲存技術中心技術專家
專注於kv儲存、資料庫、儲存等領域的研發工作,曾就職於京東、百度、頭條等網際網路公司。於2020年加入美團,致力於美團新一代統一儲存MStore的建設工作。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/28285180/viewspace-2951421/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 美團BERT的探索和實踐
- 火山引擎雲原生儲存加速實踐
- vivo雲原生容器探索和落地實踐
- 美團叢集排程系統的雲原生實踐
- 美團針對Redis Rehash機制的探索和實踐Redis
- 雲端儲存安全標準和最佳實踐
- 雲原生環境下的日誌採集、儲存、分析實踐
- 容器附加儲存(CAS)是雲原生儲存
- 美團多場景建模的探索與實踐
- 阿里雲OSS雲端儲存管理實踐阿里
- 雲原生技術領域的探索與實踐
- Kotlin程式碼檢查在美團的探索與實踐Kotlin
- 騰訊雲原生資料庫TDSQL-C架構探索和實踐資料庫SQL架構
- 雲原生體系下 Serverless 彈性探索與實踐Server
- 中國銀行雲原生技術探索與實踐
- Kubernetes雲原生儲存解決方案openebs部署實踐-3.10.0版本(helm部署)
- 美團搜尋多業務商品排序探索與實踐排序
- 雲原生儲存詳解:容器儲存與 K8s 儲存卷K8S
- 雲原生儲存編排器Rook
- 雲原生儲存系列文章(一):雲原生應用的基石
- 大資料開發的儲存技術探索與實踐大資料
- 美團知識圖譜問答技術實踐與探索
- 大模型儲存實踐:效能、成本與多雲大模型
- 阿里巴巴的雲原生應用開源探索與實踐阿里
- 在 Rainbond 上使用 Curve 雲原生儲存AI
- 美團外賣廣告智慧算力的探索與實踐(二)
- 雲端計算原生安全模型和實踐模型
- OSS雲端儲存管理實踐(體驗有禮)
- 雲原生灰度更新實踐
- Longhorn,Kubernetes 雲原生分散式塊儲存分散式
- Longhorn 雲原生容器分散式儲存 - Python Client分散式Pythonclient
- 深度學習在美團配送ETA預估中的探索與實踐深度學習
- 美團搜尋中查詢改寫技術的探索與實踐
- Druid SQL和Security在美團點評的實踐UISQL
- 美團外賣推薦情境化智慧流量分發的實踐與探索
- 異構廣告混排在美團到店業務的探索與實踐
- Portworx – 您的雲原生容器儲存解決方案
- 快速上手 Rook,入門雲原生儲存編排