影像搜尋的新紀元:Milvus與CLIP模型相伴的搜圖引擎
1 背景介紹
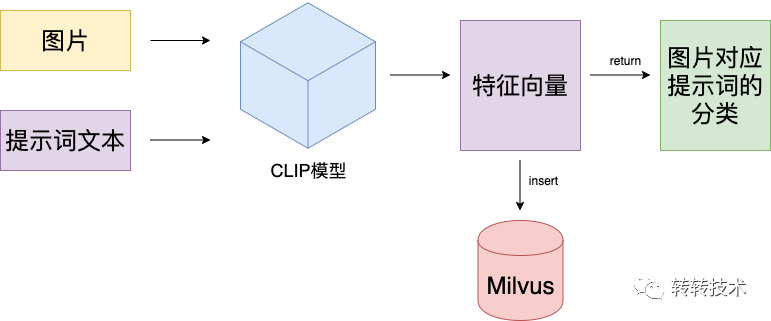
作為電商公司的風控部門,承擔著維護平臺內容安全的職責。因為政策的調整,或者一些突發情況,我們需要回溯線上歷史的商品圖片、使用者頭像資訊等,確保平臺的圖片內容的合規性。 在以前我們會讓演算法同學離線將平臺資料用相關的模型跑一遍,但是這會用到大量的計算資源,並且會花費幾天甚至更長的時間。 我們是否有更便捷的辦法對圖片做搜尋,比如像普通的資料庫那樣,透過內容甚至另一張圖去搜尋圖片呢?可否將文字、圖片等資訊轉換成另一種可以對比,可以計算的形式呢? 解決方案:可以透過深度模型提取出影像的特徵向量,建立向量庫,然後用目標文字或圖片的特徵向量進行搜尋匹配,得出最接近的結果。CLIP模型提供了生成文字和圖片特徵向量的能力,Milvus向量資料庫提供了對海量向量的儲存、管理和檢索能力。

2 CLIP模型
2.1 關於CLIP模型
CLIP(Contrastive Language-Image Pretraining)模型是一種由OpenAI開發的多模態預訓練模型,結合了影像和文字的理解能力。CLIP的目標是讓模型能夠理解圖片和文字之間的關聯關係,從而能夠在語言和視覺任務上表現出色。CLIP模型的主要作用是在影像和文字領域實現多模態的交叉理解能力,擴充了計算機視覺和自然語言處理的邊界,為各種任務提供了更全面和準確的解決方案。
2.2 CLIP模型的應用
轉轉風控主要使用CLIP對影像根據文字提示詞進行分類風險識別,同時因為CLIP模型輸出為特徵向量,所以同時使用Milvus向量資料庫儲存這些圖片的特徵向量。
3 Milvus
3.1 什麼是Milvus
Milvus是一款雲原生向量資料庫,它具備高可用、高效能、易擴充的特點,用於海量向量資料的實時召回。Milvus 基於 FAISS、Annoy、HNSW 等向量搜尋庫構建,核心是解決稠密向量相似度檢索的問題。
3.2 Milvus核心概念
非結構化資料:非結構化資料指的是資料結構不規則,沒有統一的預定義資料模型,不方便用資料庫二維邏輯表來表現的資料,包括文字、音訊、影片等。非結構化資料可以使用深度學習模型或者機器學習模型轉化為向量後進行處理。特徵向量:向量又稱為embedding vector,是指由embedding技術從離散變數轉變而來的連續向量。在數學表示上,向量是一個由浮點數或者二值型資料組成的n維陣列。向量相似度檢索:相似度檢索是指將目標物件與資料庫中資料進行比對,並召回最相似的結果。同理,向量相似度檢索返回的是最相似的向量資料。近似最近鄰搜尋(ANN)演算法能夠計算向量之間的距離,從而提升向量相似度檢索的速度。如果兩條向量十分相似,這就意味著他們所代表的源資料也十分相似。Collection-集合:包含一組Entity,可以等價於關係型資料庫系統中的表。Entity-實體:包含一組Field。Field與實際物件相對應。對應關係型資料庫中的行。Field-欄位:Entity的組成部分。Field可以是結構化資料,例如數字和字串,也可以是向量。對應關係型資料庫中的表欄位。Partition-分割槽:分割槽是集合(Collection)的一個分割槽。Milvus 支援將收集資料劃分為物理儲存上的多個部分。索引:索引基於原始向量資料構建,可以提高對Collection資料搜尋的速度。支援倒排列表、k-d樹以及高維雜湊等。這種索引結構可以在大規模向量資料集中高效地定位相似向量。
3.3 相似性計算原理
常用的向量相似度度量方法包括餘弦相似度、歐氏距離、漢明距離等。此處以歐氏距離為例:中學學過的二維空間的歐氏距離:
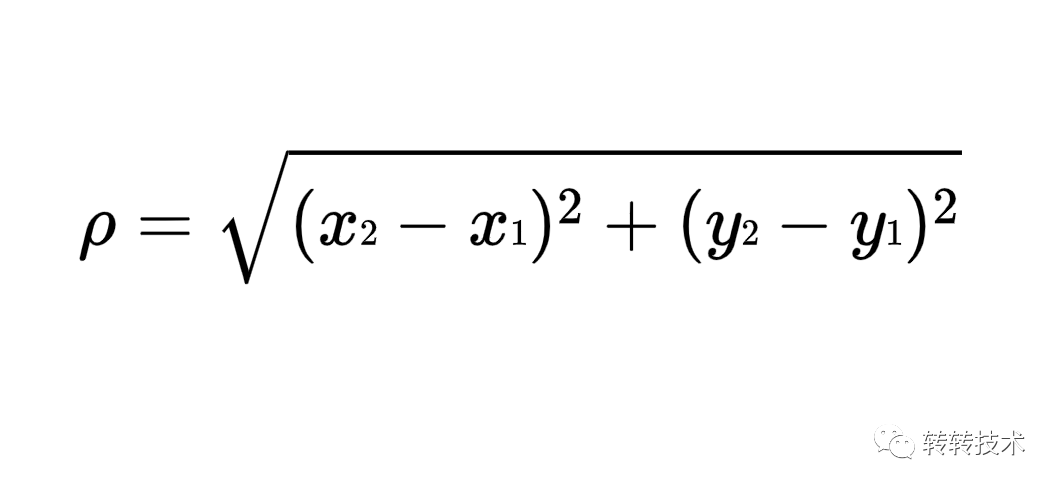
三維空間的歐式距離:
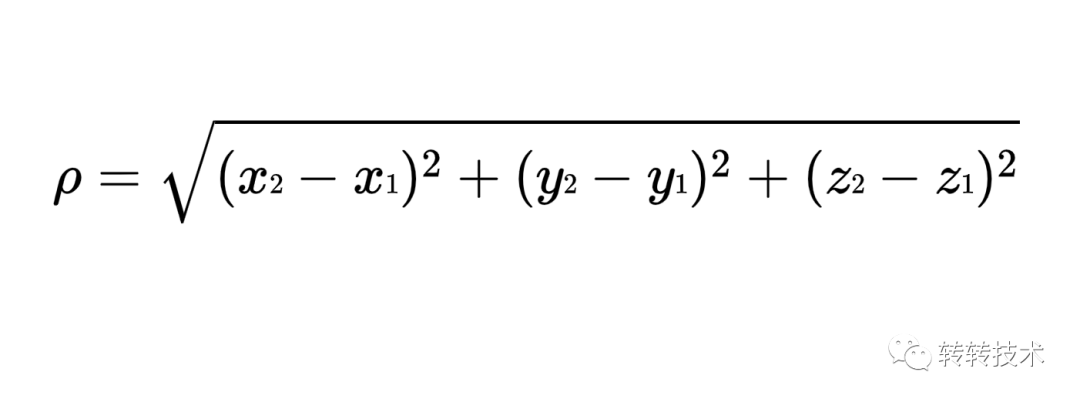
以此類推,多維空間的歐式距離:
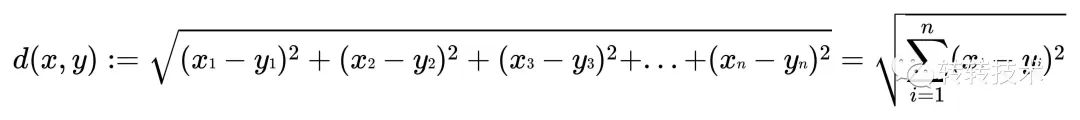
3.4 Milvus系統架構
Milvus 2.0 是一款雲原生向量資料庫,採用儲存與計算分離的架構設計,所有元件均為無狀態元件,極大地增強了系統彈性和靈活性。
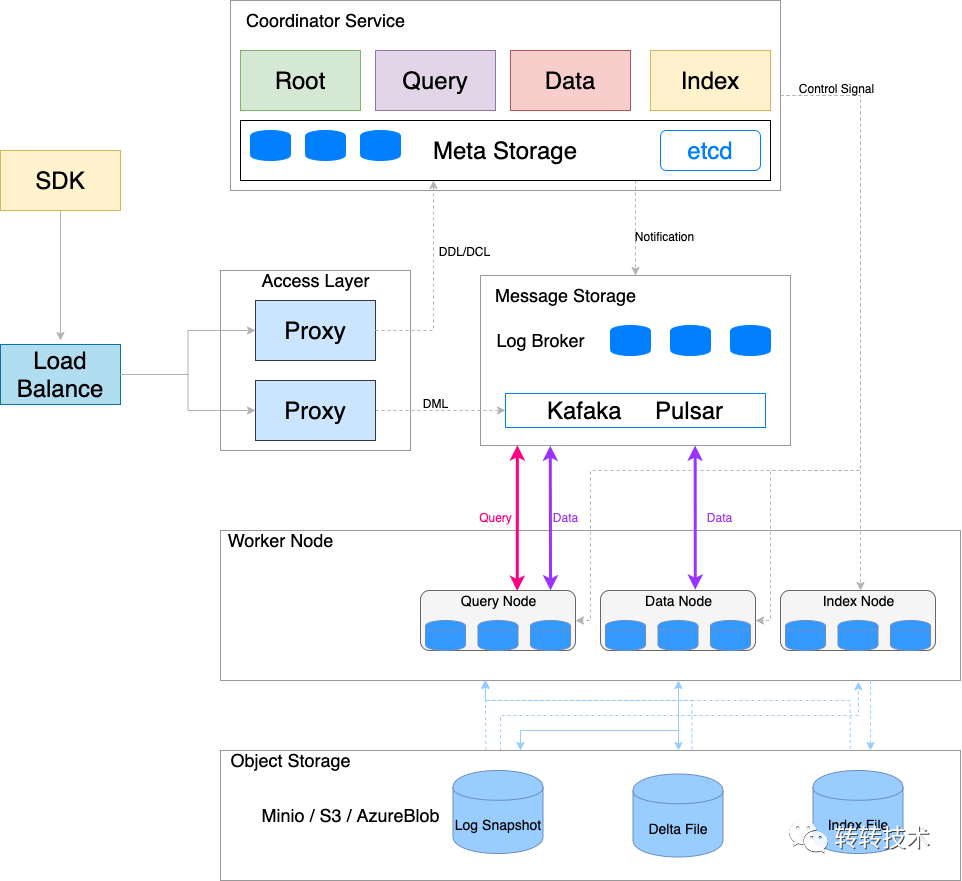
整個系統分為四個層次:接入層(Access Layer):系統的門面,由一組無狀態 proxy 組成。對外提供使用者連線的 endpoint,負責驗證客戶端請求併合並返回結果。協調服務(Coordinator Service):系統的大腦,負責分配任務給執行節點。協調服務共有四種角色,分別為 root coord、data coord、query coord 和 index coord。執行節點(Worker Node):系統的四肢,負責完成協調服務下發的指令和 proxy 發起的資料操作語言(DML)命令。執行節點分為三種角色,分別為 data node、query node 和 index node。儲存服務 (Storage):系統的骨骼,負責 Milvus 資料的持久化,分為後設資料儲存(meta store)、訊息儲存(log broker)和物件儲存(object storage)三個部分。各個層次相互獨立,獨立擴充套件和容災。
3.5 選擇Milvus的理由
高效能:效能高超,可對海量資料集進行向量相似度檢索。Milvus不但整合了業界成熟的向量搜尋技術如Faiss和SPTAG,Milvus也實現了高效的NSG圖索引。同時,Milvus團隊針對Faiss IVF索引進行了深度最佳化,實現了CPU與多GPU的融合計算,大幅提高了向量搜尋效能。Milvus可以在單機環境下完成SIFT1b十億級向量搜尋任務。高可用、高可靠:Milvus支援在雲上擴充套件,其容災能力能夠保證服務高可用。混合查詢:Milvus支援在向量相似度檢索過程中進行標量欄位過濾,實現混合查詢。開發者友好:支援多語言、多工具的Milvus生態系統。Milvus提供了向量資料管理服務,以及整合的應用開發SDK(Java/Python/C++/RESTful API)。相比直接呼叫Faiss和SPTAG那樣的程式庫,Milvus開發使用更便捷,資料管理更簡單。
4 轉轉風控的實踐
4.1 Milvus的部署方式
Milvus支援基於Docker Compose的單例部署模式,以及基於k8s的叢集部署模式。目前我們使用的是單例部署模式,1是對於我們的使用場景而言,單機效能目前沒有問題;2是單例部署模式更簡單易上手。
4.2 特徵向量的生成
前文已經說過我們使用CLIP模型來進行特徵向量的生成。原因主要有2個,1是節省計算資源,CLIP模型已經線上上應用,再用其它模型進行特徵向量生成需要再進行一次計算,浪費計算資源;2是CLIP模型本身提供了非常好的文字和圖片交叉理解能力,為文搜圖提供了基礎。
4.3 索引結構的選擇
索引的選擇對於向量召回的效能至關重要,Milvus支援了Annoy,FAISS,HNSW,DiskANN等多種不同的索引,使用者可以根據對延遲,記憶體使用和召回率的需求進行選擇。對於我們的使用場景,我們對響應時長要求不高,主要為離線或後臺使用,但是要求100%召回,不能漏召回,所以使用近似查詢的壓縮索引都不符合要求,只能使用FAISS的Flat索引。
4.4 資料過濾的實現
基於產品的使用的資料過濾需求,以及需要對歷史資料進行定期清理的目標,目前我們是根據時間以及資料來源型別建立的分割槽。 為什麼沒有使用Milvus的標量過濾特性去做過濾呢? 主要是基於效能考量,Milvus使用的是前過濾,即先做標量過濾生成Bitset,在向量檢索的過程中基於Bitset去除掉不滿足條件的Entity。在一些場景下標量過濾不僅不會加速查詢反而會導致效能變差。而且目前我們的過濾場景很確定,用指定分割槽來實現資料過濾的方式可以獲得更好的效能。
4.5 一次搜尋結果展示
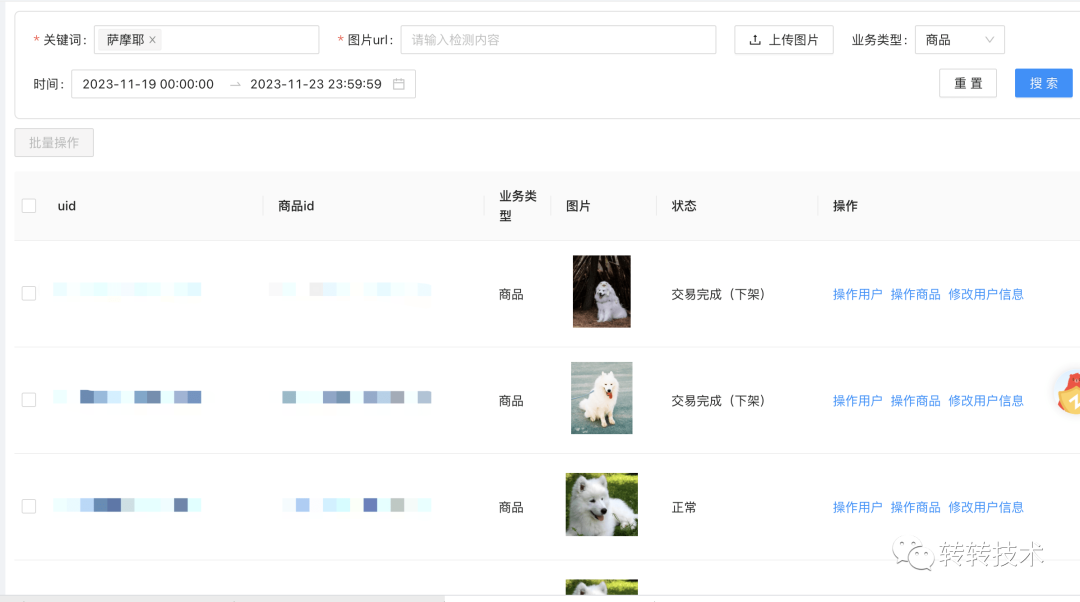
圖片為以薩摩耶為搜尋詞,搜尋2023-11-19至2023-11-23的商品資料得出的相似度最高的top20的結果。
來自 “ 轉轉技術 ”, 原文作者:許作紅;原文連結:https://server.it168.com/a2023/1130/6831/000006831717.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- Django單元測試與搜尋引擎Django
- 搜尋引擎es-分詞與搜尋分詞
- 搜尋引擎-03-搜尋引擎原理
- 搜尋引擎與前端SEO前端
- 海量資料搜尋---搜尋引擎
- Nebula 基於 ElasticSearch 的全文搜尋引擎的文字搜尋Elasticsearch
- 高效的使用搜尋引擎
- python 寫的搜尋引擎Python
- 知識圖譜——搜尋引擎的未來
- Mac上神奇的內建搜尋引擎——Spotlight(聚焦搜尋)Mac
- OpenAI新AI搜尋將顛覆谷歌等傳統搜尋引擎OpenAI谷歌
- 知乎搜尋/(引擎)的故事
- 使用Google百度等搜尋引擎的常用搜尋技巧Go
- 圖的遍歷:深度優先搜尋與廣度優先搜尋
- sphinx 全文搜尋引擎
- 高效利用搜尋引擎
- ElasticSearch全文搜尋引擎Elasticsearch
- python 寫的搜尋引擎 - 原始碼Python原始碼
- 直播開發app,實時搜尋、搜尋引擎框APP
- 揭秘淘寶搜尋API:打造你的專屬購物搜尋引擎!API
- Shodan搜尋引擎介紹
- 搜尋引擎優化(SEO)優化
- BTFILM電影搜尋引擎
- Django整合搜尋引擎ElasticserachDjangoAST
- 搜尋引擎框架介紹框架
- 認識搜尋引擎 ElasticsearchElasticsearch
- elasticsearch 搜尋引擎工具的高階使用Elasticsearch
- 使用開源搜尋引擎 YaCy 的技巧
- 過濾搜尋引擎的抓取資料
- 海量資料搜尋---demo展示百度、谷歌搜尋引擎的實現谷歌
- CV+NLP,使用tf.Keras構建影像搜尋引擎Keras
- 57_初識搜尋引擎_分散式搜尋引擎核心解密之query phase分散式解密
- 09 如何通過搜尋引擎尋找海量的免費商用圖片
- Tantivy與Quickwit:類似Lucene的Rust全文搜尋引擎庫UIRust
- Bing希望改變搜尋引擎發現新內容的方式
- 127盤搜網 網盤資源搜尋引擎
- win10如何更換edge預設搜尋引擎_win10 edge更改搜尋引擎的方法Win10
- 為什麼搜尋引擎搜不到我們想要的東西LEL