任務全鏈路診斷助雲音樂大規模計算資源最佳化
計算資源vcore的最佳化不同於記憶體最佳化,vcore嚴重影響著任務的執行效率。如何在保證任務執行效率不變甚至提高的情況下,能進一步最佳化vcore的利用率?我們需要對任務做出全面的分析,給出不同的最佳化策略。這篇文章主要圍繞任務執行階段,介紹任務全鏈路診斷針對任務不同檢查項異常給予的最佳化策略,以及帶來的收益。
對於大資料離線任務來說,由於流轉服務節點較多、技術棧要求較高、資料採集難度大、指標複雜難懂等一系列原因,造成業務方對任務的掌控力非常差:不清楚異常出現在哪;不確定任務是否可以最佳化、如何最佳化。
目前大資料基礎設施組開發了一款EasyEagle產品,並透過其中的任務全鏈路診斷模組,幫助使用者去解決上述的問題。
本篇文章大致介紹任務全鏈路診斷模組,透過部分案例和資料,幫助使用者更好的瞭解該功能模組能帶來什麼樣的收益,以及如何簡單的使用。本篇文章僅涉及計算資源vcore的最佳化,對於異常定位會有其他文章進行介紹。
01 什麼是任務全鏈路診斷?
任務全鏈路,指的是任務從提交到產出結束,整個生命週期內流轉的各個服務、節點的集合。
診斷,指的是將上述整個鏈路,按照已有的運維經驗和特徵進行抽象劃分,細分成不同檢查項進行診斷定位。
總結起來就是:將任務從提交到產出結束(包括各個流轉節點以及流轉服務),抽象並劃分成不同階段,並對上述各個階段細分不同的檢查項進行診斷定位,提供相關專業化的最佳化以及解決建議,提高業務方對任務執行過程的掌控,包括任務執行效率的提升以及資源利用率的提升。
02 對業務能產生什麼價值?
主要的價值其實就一點:增加業務方對任務的掌控能力。這裡的掌控能力主要分以下幾個方面:
資源:指的是資源申請和實際使用是否合理,利用率是否正常
效率:任務執行效率是否可以提升,是否可以加快產出
異常定位:異常在哪,如何解決
配置:配置是否合理,不合理的配置如何修改
在目前的系統中,業務方提交任務之後,直至結束,對任務的整個執行完全屬於一個摸黑狀態。任務全鏈路診斷就能解決這種摸黑狀態,並且提升業務方上述幾個方面的掌控能力,達到降本增效的目的。
說到這裡,可能有的小夥伴會問,這是真的嗎??那我們就直接貼圖以及資料來展示~
目前內部我們針對音樂進行了一次任務計算資源的最佳化,最佳化時間範圍為0-7點(業務高峰期),最佳化任務數量為前200的任務,總體統計資料均只包含該時間段(0-7點)。
整體最佳化效果如圖:
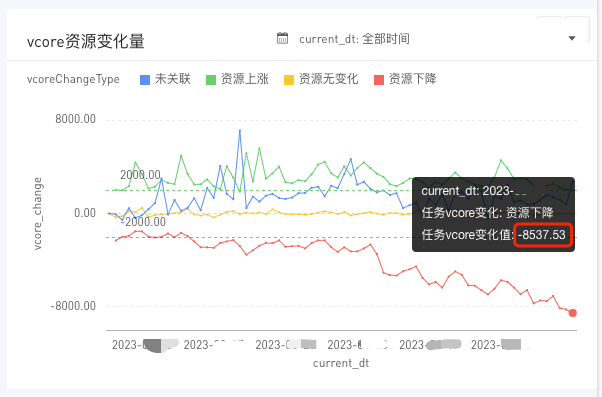
在針對0-7點的前200任務最佳化後,vcore的資源水位下降如上所示。
對於一個只有5.3w的vcore的叢集而言,前200的任務佔叢集43%的資源,能夠達到上述的最佳化效果,還是非常可觀的,並且音樂業務方本身對於任務的最佳化情況就較好。
單個任務的最佳化效果如圖:
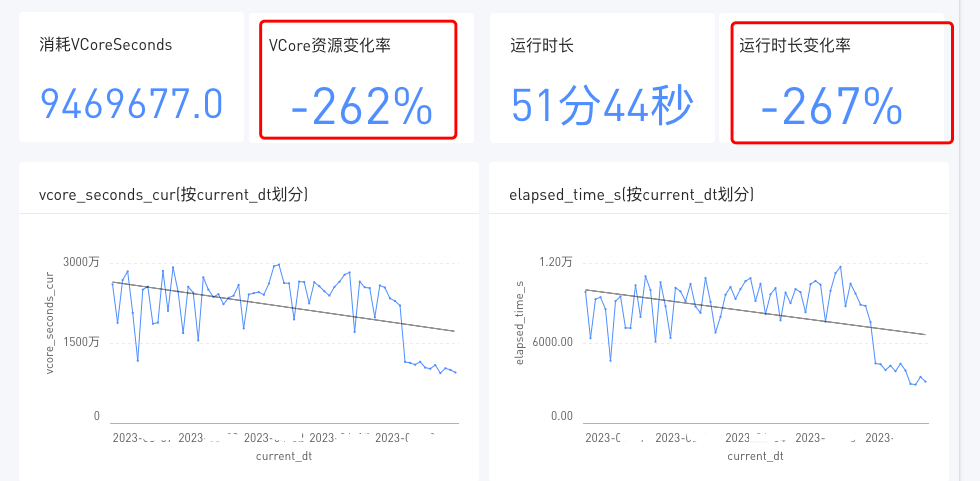
單個任務的最佳化效果如上所示,不言而喻。
看到這裡,小夥伴對於任務全鏈路診斷這塊對於業務方是否能帶來收益,是否還有疑問?
03 任務全鏈路診斷我們是怎麼做的?
首先,我們將任務生命週期大致分為三個階段,如下所示:

任務準備階段,主要是指資源的初始化、本地化等一系列的前期準備。涉及到yarn的排程、資源、本地節點、hdfs等。
任務執行階段,主要是指任務按照既定邏輯執行。
任務產出階段,主要是指任務具體邏輯執行完畢後,資料持久化或其他的一系列操作。涉及到hdfs、metastore等。
針對每個階段,我們再根據內部運維相關經驗以及特徵,抽象劃分成不同的檢查項對其進行診斷。如果診斷出異常,會附加相關的標籤。標籤會攜帶異常原因、異常表象、最佳化建議等。
看到這裡,大家可能會有個疑問:任務根據標籤按照最佳化建議最佳化後,就能加快產出、提高資源的利用率嗎?
答案是可以的。因為每個檢查項的評判標準都是時長和資源,所有的最佳化最終的表現都可以透過時長和資源兩個維度進行衡量。
下面我們會詳細說明下各個階段的檢查項劃分。
3.1 任務準備階段
針對這一階段,我們對其進行了抽象劃分,分為如下各個檢查項:
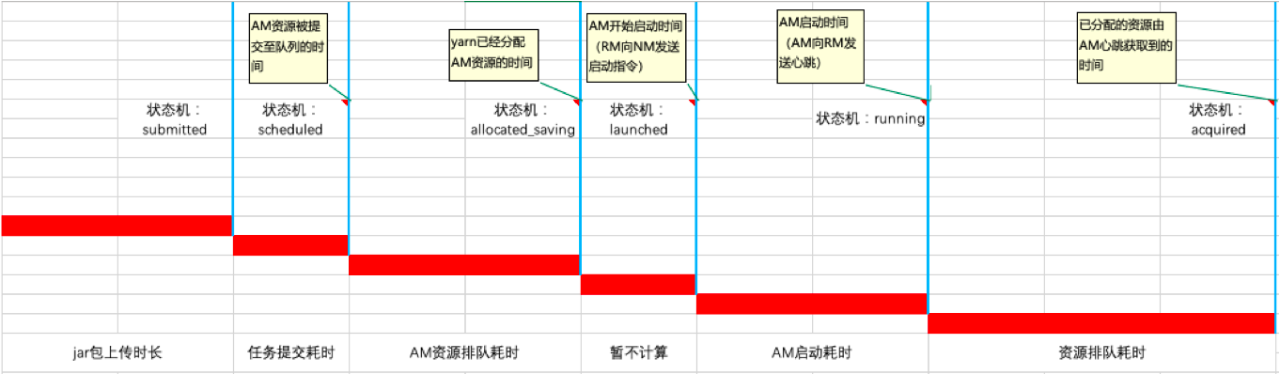
該階段,我們透過對不同型別container的狀態機變化的間隔時長,進行檢查項劃分。上述的各個檢查項,也可以關聯相關節點和服務。
在這之前,這個階段基本上對於所有的業務方來說,甚至開發,都是屬於完全不瞭解、不掌控的階段。實際監控後,發現很多工在該階段都存在問題。
目前在產品中,我們將其檢查項提取成4組標籤,展示如下:

上述檢查項的最佳化,主要帶來的是任務產出時長的最佳化。這裡我們簡單的舉一個例子來說明下我們是如何做的。
AM分配耗時過長
以AM分配耗時這個檢查項為例,判斷的依據如下:
獲取任務該檢查項的耗時
與叢集AM分配速率以及該任務此檢查項的歷史水平進行對比
如發現不匹配叢集的分配速率或超出歷史統計模型設定的上限,則檢查任務提交佇列的資源水位
如該佇列資源水位已滿,則告知業務方由於佇列資源不足造成;如該佇列資源水位正常,但是AM資源已滿,則告知業務方由於AM資源不足造成,建議修改AM資源配比
如該檢查項異常,業務方可以根據給出的相關建議進行處理,加快任務的產出。
3.2 任務執行階段
針對這一階段,我們也將spark任務進行了一個大概的抽象,如下所示:
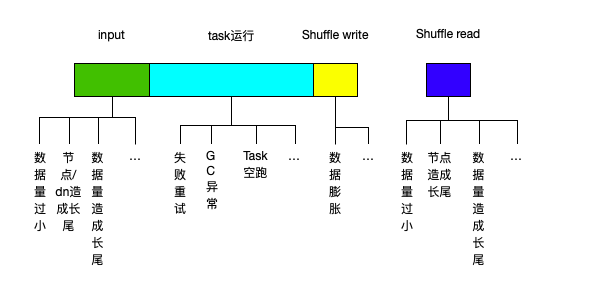
該階段,我們主要透過實時統計分析spark的event指標進行檢查項的診斷。
當前此階段檢查項的劃分還處於增長的狀態,目前大致已有20餘項,部分檢查項標籤如下所示:

上述檢查項的最佳化,為什麼能帶來資源利用率的提升以及執行效率的提升?我們以幾個簡單的檢查項來舉例說明一下。
(1)Input Task數量檢查
該檢查項主要是針對input階段task數量過多,但是input資料量不大的情況(這裡不大,是指的小於等於目前我們診斷配置的閾值,一般預設為128Mb)。
在目前生產環境中,我們發現很多input階段的stage存在10W+的task在執行。這裡很多人會認為,這些任務應該會很快產出,任務沒啥問題。
但是我們透過實際的資料分析後發現以下規則:
input階段的stage存在巨量的task,一般會伴隨GC檢查項異常,GC耗時佔整個stage執行時長超過10%以上
相同任務相同階段的task處理資料量增加,並不會使task的執行時長呈現等比例的增長。因為排程開銷以及序列化會有部分消耗,另外input階段網路以及磁碟IO對task執行時長的影響較大
這種含有巨量task的stage,不可能一輪就能執行完畢
因此針對input階段的stage,存在巨量的task執行並不是一個很好的主意。
針對該檢查項,我們一般會建議使用者將spark.sql.files.maxPartitionBytes配置提高,例如由預設的128Mb提高至512Mb。我們可以簡單的計算下,大致對於該階段的stage資源以及時長能節約多少:
原先每個task處理資料量:128Mb
原先input階段stage的task數量:16w
該任務同時最大task執行數量:2w
原先一輪task執行耗時:t
現每個task處理資料量:512Mb
現input階段stage的task數量:4w
該任務同時最大task執行數量:2w
資料量增長後,task耗時增長倍數:2.5(資料量提升4倍後,大致為2-3倍的耗時增加)
資源:
該階段vcore資源下降比例:37.5% = (2w * 16w/2w * t - 2w * 4w/2w * 2.5t) / (2w * 16w/2w * t)
如果算上GC耗時的降低,該階段vcore資源下降比例應為:40%+
時長:
該階段執行時長下降比例:37.5% = (16w/2w * t - 4w/2w * 2.5t) / (16w/2w * t)
如果算上GC耗時的降低,該階段執行時長同樣下降比例應為:40%+
(2)ExecutorCores空跑檢查
該檢查項主要是針對Executor只有少量的core在執行task,其他大量的core在空跑的情況。
在目前的生產環境中,我們發現一些任務存在Executor只有不到一半的core在執行task,其他的core均在空跑。造成這個現象的原因,主要是Spark任務在執行過程中每個Stage的task數量均會變化,若某個Stage的task數量驟減,且該數量小於當前可用的core數量,在認為每個task佔用一個core的情況下,會存在大量Exeucotors的core出現空跑。因為在當前生產環境中,一個Executors經常會被分配4個core,若其中只有一個core被佔用,那麼這個executors既不會被釋放,且另外的3個core也處於空跑浪費的情況。
該現象會造成任務大量的佔用叢集的vcore計算資源,但是卻沒有使用,降低任務以及該叢集的資源利用率。
針對該檢查項,我們一般會建議使用者將spark.executor.cores降低一半,以及將spark.locality.wait.process配置調大以保證更多的task能分配至一個executor中。我們也可以簡單的計算下,該操作大致對於該階段的stage資源能節約多少:
原該stage執行的executor數量:2000
原每個executor配置的vcore數量:4
現該stage執行的executor數量:2000
現每個executor配置的vcore數量:2
資源:
該階段vcore資源下降比例:50% = (2000 * 4 - 2000 * 2) / (2000 * 4)
3.3 任務產出階段
任務產出階段,目前診斷的比較簡單。主要透過資料量、時長的統計,來判斷是否存在問題。如果存在問題,關聯hdfs以及metastore進行問題的進一步定位。
在此不進一步進行介紹了。
04 業務方是怎麼使用這塊功能並最佳化的?
在目前的EasyEagle產品中,業務方進行上述的最佳化操作其實非常簡單。根據任務執行概覽中的可最佳化任務列表展示的最佳化建議進行相關處理即可,如下所示:

該列表目前暫時只能展示所選標籤下的任務列表(已排序,按照該標籤打分進行排序)。後續版本將會以任務維度,透過任務執行時長以及資源消耗排序展示任務全部異常標籤。
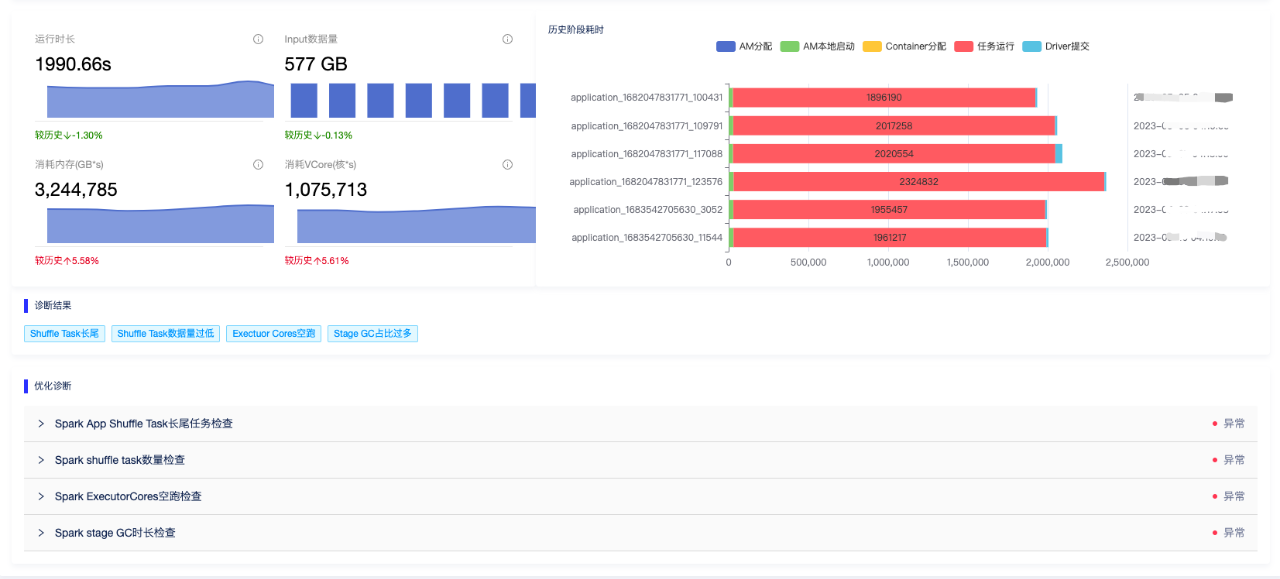
業務方在點選具體app id時,可以跳轉至任務的全鏈路診斷詳情頁面,該頁面會將任務全部的異常檢查項進行展示,並會歷史相關資料進行對比展示。讓使用者也進一步瞭解最佳化前後的資源、時長情況。
05 背不足思考
業務方的確可以非常方便的透過可最佳化任務列表獲取相關任務以及最佳化建議,但是最佳化操作其實對於使用者並不友好,需要使用者進行手動配置修改。
平臺側對於週期提交的任務,是否可以透過目前我們EasyEagle提供的最佳化建議,進行自動的配置調優,而不依賴使用者手動性的行為?
來自 “ 網易有數 ”, 原文作者:葉翔;原文連結:https://server.it168.com/a2023/0517/6804/000006804065.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 阿里大規模業務混部下的全鏈路資源隔離技術演進阿里
- 如何透過鏈路追蹤進行定時任務診斷
- 用更雲原生的方式做診斷|大規模 K8s 叢集診斷利器深度解析K8S
- 雲端計算規模大嗎?可靠嗎?
- 網易雲音樂全鏈路埋點管理平臺建設
- 網易雲音樂資料全鏈路基線治理實踐
- 京東科技全鏈路故障診斷智慧運維實踐運維
- Oracle診斷案例-Job任務停止執行Oracle
- Apache DolphinScheduler大規模任務排程系統對大資料實時Flink任務支援Apache大資料
- 專屬雲資源包計算規格探秘
- 大規模文字相似度計算
- [平臺建設] Spark任務的診斷調優Spark
- 雲音樂實時數倉建設以及任務治理實踐
- 雲音樂影片搜尋最佳化之旅
- 螞蟻集團宣佈雲原生大規模叢集化機密計算框架 KubeTEE 開源框架
- OPPO大資料診斷平臺設計與實踐大資料
- 計算機網路 | 資料鏈路層計算機網路
- 阿里雲大資料計算服務MaxCompute使用教程阿里大資料
- 打造全鏈路資料隱私合規平臺
- 雲端計算的資源管理特性及服務型別型別
- 計算機網路之資料鏈路層計算機網路
- Android開源音樂播放器之高仿雲音樂黑膠唱片Android播放器
- 風機故障診斷學習資源(更新中)
- 十億節點大規模圖計算降至「分鐘」級,騰訊開源圖計算框架柏拉圖框架
- 雲端計算學習路線教程大綱課件:使用自建源
- 媒體聲音|阿里雲資料庫:一站式全鏈路資料管理與服務,引領雲原生2.0時代阿里資料庫
- 深度揭秘阿里雲函式計算非同步任務能力阿里函式非同步
- 託管資料中心vs.雲端計算:保障關鍵任務資料安全
- 雲伺服器用MTR診斷Ubuntu網路問題方法伺服器Ubuntu
- PingCAP Clinic 服務:貫穿雲上雲下的 TiDB 叢集診斷服務PingCAPTiDB
- Mac OSX網路診斷命令Mac
- 網路診斷工具的使用
- 藉助 Turbolinks 實現不間斷的網頁音樂播放器網頁播放器
- 開源模式下的雲端計算和大資料現狀模式大資料
- 透過雲效 CI/CD 實現微服務全鏈路灰度微服務
- 40萬獎池 + 頂級雲服務資源,雲端計算大賽系列公開課正式開播
- 雲端計算的三大服務模式模式
- .Net Core服務診斷排查