本文是一個基於 NebulaGraph 上圖演算法、圖資料庫、機器學習、GNN 的推薦系統方法綜述,大部分介紹的方法提供了 Playground 供大家學習。
基本概念
推薦系統誕生的初衷是解決網際網路時代才面臨的資訊量過載問題,從最初的 Amazon 圖書推薦、商品推薦,到電影、音樂、影片、新聞推薦,如今大多數網站、App 中都有至少一個基於推薦系統生成的供使用者選擇的物品列表介面。而這些物品的推薦基本都是基於使用者喜好、物品的特徵、使用者與物品互動歷史和其他相關上下文去做的。
一個推薦系統會包含以下幾個部分:
- 資料、特徵的處理
- 從特徵出發,生成推薦列表
- 過濾、排序推薦列表
這其中,過濾的核心方法主要有兩種:基於內容的過濾 Content-Based Filtering、與協同過濾 Collaborative Filtering,相關論問介紹可參考延伸閱讀 1、2。
基於內容的過濾
內容過濾方法的本質是給使用者的偏好做畫像,同時對所有待推薦的物品計算特徵,做使用者的畫像與待推薦物品特徵之間的距離運算,過濾得到相近的物品。。
內容過濾的方法的好處有:
- 清晰的可解釋性,無論是對使用者的畫像分析,還是對物品的運算本身天然帶來了排序、過濾的可解釋性;
- 使用者資料輸入的獨立性,對指定的待推薦使用者來說,只需要單獨分析他們的畫像和歷史評分就足夠了;
- 規避新物品冷啟動問題,對於新的新增的物品,即使沒有任何歷史的使用者評價,也可以做出推薦;
同時,基於內容過濾的推薦也有以下弊端:
- 特徵提取難度,比如:照片、影片等非純文字資料,它們的特徵提取依賴領域專家知識。舉個例子,電影推薦系統需要抽出導演、電影分類等領域知識作為特徵;
- 難以打破舒適圈,發掘使用者的潛在新興趣點;
- 新使用者冷啟動資料缺失問題,新使用者個人資訊少難以形成使用者畫像,進而缺少做物品畫像、特種距離運算的輸入;
基於協同過濾
協同過濾的本質是結合使用者與系統之間的互動行為去推薦物品。
協同過濾的方法又分為基於記憶 memory-based 的協同過濾與基於模型 model-based 的協同過濾。
基於記憶的協同過濾主要有物品與物品之間的協同過濾 ItemCF 和使用者與使用者之間的協同過濾 UserCF。ItemCF 簡單來說是,推薦和使用者之前選擇相似的物品,即:根據行為找物品之間的相似性;UserCF 則推薦與使用者有共同愛好的人所喜歡的物品,即:根據行為找使用者之間的相似性。
基於模型的協同過濾主要根據使用者喜好的歷史資訊、利用統計與機器學習方法訓練模型,對新使用者的偏好進行推理。
協同過濾的方法的好處有:
- 無需對非結構化物品進行特徵分析,因為協同過濾關注的是使用者和物品之間的協同互動,這繞過了對物品領域知識處理的需求;
- 對使用者的個性化定製程度更強、更細,基於行為的分析使得對使用者偏好的劃分本質上是連續的(相比來說,對使用者做畫像的方法則是離散的),這樣的推薦結果會更加“千人千面”。同時,也會蘊含內容過濾、有限的畫像角度之下的“驚喜”推薦。
但,它的缺點有以下方面:
- 有新使用者和新物件上的冷啟動問題,因為它們身上都缺少歷史喜好行為的資訊;
我們總結一下,兩種過濾方式各有利弊,也存在互補的地方。比如,新物件的冷啟動上,基於內容的過濾有優勢;對於個性化、推薦驚喜度方面,協同過濾有優勢。所以,在實操中,推薦系統大多演變都比上面的歸類複雜得多,而且常常伴隨著多種方法的融合。
基於圖的個性推薦
圖技術、圖資料庫技術在推薦系統中的應用是多方面的,在本章節中我們會從圖資料庫的出發點上給出多種應用例子。
建立圖譜
在開始之前,我簡單地介紹下本文使用的圖資料集。
為了給出更接近實際情況的例子,我從兩個公開的資料集 OMDB 和 MovieLens 中分別抽取了所需資訊,組成了一個既包含電影的卡司(導演、演員)和型別,又包含使用者對電影評分記錄的知識圖譜。
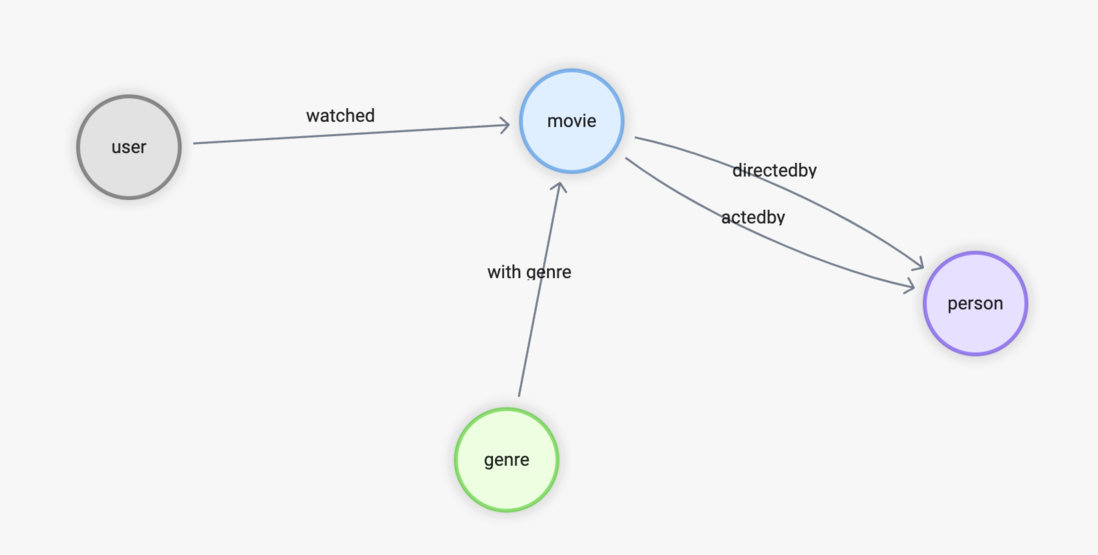
Schema 如下:
頂點:
- user(user_id)
- movie(name)
- person(name, birthdate)
- genre(name)
邊:
- watched(rate(double))
- with_genre
- directed_by
- acted_by
這個資料的準備、ETL 過程會在另外的文章裡詳細介紹,在進入下一章節之前,我們可以用 Nebula-Up 一鍵搭起一個測試的 NebulaGraph 單機叢集,再參考資料集的 GitHub 倉庫,一鍵匯入所需資料,資料集參考延伸閱讀 4。
具體操作步驟:
- 用 Nebula-Up 安裝 NebulaGraph;
- 克隆 movie-recommendation-dataset;
- 匯入資料集 NebulaGraph;
curl -fsSL nebula-up.siwei.io/install.sh | bash
git clone https://github.com/wey-gu/movie-recommendation-dataset.git && cd movie-recommendation-dataset
docker run --rm -ti \
--network=nebula-net \
-v ${PWD}:/root/ \
-v ${PWD}/dbt_project/to_nebulagraph/:/data \
vesoft/nebula-importer:v3.2.0 \
--config /root/nebula-importer.yaml基於內容的過濾
CBF,內容過濾的思想是利用領域知識、歷史記錄、後設資料分別對使用者和物件做畫像、打標籤,最終根據使用者的標籤與待推薦物件之間的距離評分進行排序給出相關推薦。
對使用者的畫像不涉及其他使用者的資訊,但是輸入的特徵可能來源於後設資料(生日、國籍、性別、年齡)、歷史記錄(評論、打分、購買、瀏覽)等等,在這些基礎之上對使用者進行標籤標註、分類、聚類。
對物件的畫像輸入的特徵可能是基於語言處理(NLP、TF-IDF、LFM)、專家標註、多媒體處理(視覺到文字再 NLP、音訊風格處理、音訊到文字再 NLP)等。
有了使用者畫像與物件的畫像特徵、對使用者涉及的畫像進行相關畫像物件中新物件的近似度計算,再評分加權,就可以獲得最終的推薦排序了。其中的近似度計算常見的有 KNN、餘弦相似度、Jaccard 等演算法。
CBF 的方法中沒有限定具體實現方式。如前邊介紹,可能是基於機器學習、Elasticsearch、圖譜等不同方法。為切合本章的主題,這裡我給出一個基於圖資料庫、圖譜上的 CBF 的例子,做一個電影推薦系統,能讓讀者理解這個方法的思想。同時,也能熟悉圖資料庫、知識圖譜的方法。
實操部分的使用者特徵直接利用歷史電影評價記錄,而推薦物件「電影」的畫像則來自於領域中的知識。這些知識有:電影風格、電影的卡司、導演。近似度演算法則採用圖譜中基於關係的 Jaccard 相似度演算法。
Jaccard Index
Jaccard Index 是一個描述兩個集合距離的定義公式,非常簡單、符合直覺地取兩者的交集與並集測度的比例,它的定義記為:
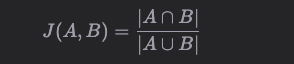
這裡,我們把交集理解為 A 與 B 共同連線的點(有共同的導演、電影型別、演員),並集理解為這幾種關係下與 A 或者 B 直連的所有點,而測度就直接用數量表示。
CBF 方法在 NebulaGraph 中的實現
CBF 方法分如下四步:
- 找出推薦使用者評分過的電影;
- 從使用者評分過的電影,經由導演卡司、電影型別找到新的待推薦電影;
- 對看過的電影與新的電影,藉由導演、卡司、電影型別的關係,在圖上做 Jaccard 相似性運算,得出每一對看過的電影和待推薦新電影之間的 Jaccard 係數;
- 把使用者對看過電影的評分作為加權係數,針對其到每一個新電影之間的 Jaccard 係數加權評分,獲得排序後的推薦電影列表;
// 使用者 u_124 看過的電影
MATCH (u:`user`)-[:watched]->(m:`movie`) WHERE id(u) == "u_124"
WITH collect(id(m)) AS watched_movies_id
// 根據電影的標註關係找到備選推薦電影,刨除看過的,把評分、交集關聯鏈路的數量傳下去
MATCH (u:`user`)-[e:watched]->(m:`movie`)-[:directed_by|acted_by|with_genre]->(intersection)<-[:directed_by|acted_by|with_genre]-(recomm:`movie`)
WHERE id(u) == "u_124" AND NOT id(recomm) IN watched_movies_id
WITH (e.rate - 2.5)/2.5 AS rate, m, recomm, size(COLLECT(intersection)) AS intersection_size ORDER BY intersection_size DESC LIMIT 50
// 計算 Jaccard index-------------------------------------------------
// 針對每一對 m 和 recomm:
// 開始計算看過的電影,集合 a 的部分
MATCH (m:`movie`)-[:directed_by|acted_by|with_genre]->(intersection)
WITH rate, id(m) AS m_id, recomm, intersection_size, COLLECT(id(intersection)) AS set_a
// 計算推薦電影,集合 b 的部分
MATCH (recomm:`movie`)-[:directed_by|acted_by|with_genre]->(intersection)
WITH rate, m_id, id(recomm) AS recomm_id, set_a, intersection_size, COLLECT(id(intersection)) AS set_b
// 得到並集數量
WITH rate, m_id, recomm_id, toFloat(intersection_size) AS intersection_size, toSet(set_a + set_b) AS A_U_B
// 得到每一對 m 和 recomm 的 Jaccard index = A_N_B/A_U_B
WITH rate, m_id, recomm_id, intersection_size/size(A_U_B) AS jaccard_index
// 計算 Jaccard index-------------------------------------------------
// 得到每一個被推薦的電影 recomm_id,經由不同看過電影推薦鏈路的相似度 = 評分 * jaccard_index
WITH recomm_id, m_id, (rate * jaccard_index) AS score
// 對每一個 recomm_id 按照 m_id 加權求得相似度的和,為總的推薦程度評分,降序排列
WITH recomm_id, sum(score) AS sim_score ORDER BY sim_score DESC WHERE sim_score > 0
RETURN recomm_id, sim_score LIMIT 50上邊查詢的執行結果擷取出來是:
| recomm_id | sim_score |
|---|---|
| 1891 | 0.2705882352941177 |
| 1892 | 0.22278481012658227 |
| 1894 | 0.15555555555555556 |
| 808 | 0.144 |
| 1895 | 0.13999999999999999 |
| 85 | 0.12631578947368421 |
| 348 | 0.12413793103448277 |
| 18746 | 0.11666666666666668 |
| 628 | 0.11636363636363636 |
| 3005 | 0.10566037735849057 |
視覺化分析
我們把上面過程中的部分步驟查詢修改一下為 p=xxx 的方式,並渲染出來,會更加方便理解。
例子 1,使用者 u_124 看過的、評分過的電影:
// 使用者 u_124 看過的電影
MATCH p=(u:`user`)-[:watched]->(m:`movie`) WHERE id(u) == "u_124"
RETURN p
例子 2,找到使用者 u_124 看過的那些電影在相同的演員、導演、電影型別的關係圖譜上關聯的所有其他電影:
// 使用者 u_124 看過的電影
MATCH (u:`user`)-[:watched]->(m:`movie`) WHERE id(u) == "u_124"
WITH collect(id(m)) AS watched_movies_id
// 根據電影的標註關係找到備選推薦電影,刨除看過的,把評分、交集關聯鏈路的數量傳下去
MATCH p=(u:`user`)-[e:watched]->(m:`movie`)-[:directed_by|acted_by|with_genre]->(intersection)<-[:directed_by|acted_by|with_genre]-(recomm:`movie`)
WHERE id(u) == "u_124" AND NOT id(recomm) IN watched_movies_id
RETURN p, size(COLLECT(intersection)) AS intersection_size ORDER BY intersection_size DESC LIMIT 500可以看到使用者 u_124 看過電影經由演員、型別擴散出好多新的電影

在得到待推薦電影以及推薦路徑後,透過 Jaccard 係數與使用者路徑第一條邊的評分綜合評定之後,得到了最終的結果。
這裡,我們把結果再視覺化一下:取得它們和使用者之間的路徑並渲染出來。
// 使用者 u_124 看過的電影
MATCH (u:`user`)-[:watched]->(m:`movie`) WHERE id(u) == "u_124"
WITH collect(id(m)) AS watched_movies_id
// 根據電影的標註關係找到備選推薦電影,刨除看過的,把評分、交集關聯鏈路的數量傳下去
MATCH (u:`user`)-[e:watched]->(m:`movie`)-[:directed_by|acted_by|with_genre]->(intersection)<-[:directed_by|acted_by|with_genre]-(recomm:`movie`)
WHERE id(u) == "u_124" AND NOT id(recomm) IN watched_movies_id
WITH (e.rate - 2.5)/2.5 AS rate, m, recomm, size(COLLECT(intersection)) AS intersection_size ORDER BY intersection_size DESC LIMIT 50
// 計算 Jaccard index-------------------------------------------------
// 針對每一對 m 和 recomm:
// 開始計算看過的電影,集合 a 的部分
MATCH (m:`movie`)-[:directed_by|acted_by|with_genre]->(intersection)
WITH rate, id(m) AS m_id, recomm, intersection_size, COLLECT(id(intersection)) AS set_a
// 計算推薦電影,集合 b 的部分
MATCH (recomm:`movie`)-[:directed_by|acted_by|with_genre]->(intersection)
WITH rate, m_id, id(recomm) AS recomm_id, set_a, intersection_size, COLLECT(id(intersection)) AS set_b
// 得到並集數量
WITH rate, m_id, recomm_id, toFloat(intersection_size) AS intersection_size, toSet(set_a + set_b) AS A_U_B
// 得到每一對 m 和 recomm 的 Jaccard index = A_N_B/A_U_B
WITH rate, m_id, recomm_id, intersection_size/size(A_U_B) AS jaccard_index
// 計算 Jaccard index-------------------------------------------------
// 得到每一個被推薦的電影 recomm_id,經由不同看過電影推薦鏈路的相似度 = 評分 * jaccard_index
WITH recomm_id, m_id, (rate * jaccard_index) AS score
// 對每一個 recomm_id 按照 m_id 加權求得相似度的和,為總的推薦程度評分,降序排列
WITH recomm_id, sum(score) AS sim_score ORDER BY sim_score DESC WHERE sim_score > 0
WITH recomm_id, sim_score LIMIT 10
WITH COLLECT(recomm_id) AS recomm_ids
MATCH p = (u:`user`)-[e:watched]->(m:`movie`)-[:directed_by|acted_by|with_genre]->(intersection)<-[:directed_by|acted_by|with_genre]-(recomm:`movie`)
WHERE id(u) == "u_124" AND id(recomm) in recomm_ids
RETURN p哇,我們可以很清晰地看到推薦的理由路徑:喜歡星戰的使用者透過多條共同的型別、演員、導演的邊引匯出未觀看的幾部星戰電影。這其實就是 CBF 的優勢之一:天然具有較好的可解釋性。

基於記憶的協同過濾
前邊我們提過了,協同過濾主要可以分為兩種:
- User-User CF 基於多個使用者對物件的歷史行為,判定使用者之間的相似性,再根據相似使用者的選擇推薦新的物件;
- Item-Item CF 判斷物件之間的相似性,給使用者推薦他喜歡的物品相似的物品。
這裡,ItemCF 看起來和前邊的 CBF 有些類似,核心區別在於 CBF 找到相似物件的方式是基於物件的“內容”本身,是領域知識的畫像,而 ItemCF 的協同則是考慮使用者對物件的歷史行為。
ItemCF
這個方法分如下四步:
- 找出推薦使用者評分過的電影;
- 經由使用者的高評分電影,找到其他給出高評分使用者所看過的新的高評分電影;
- 透過使用者的評分對看過的電影與新的電影在圖上做 Jaccard 相似性運算,得出每一對看過的電影和待推薦新電影之間的 Jaccard 係數;
- 把使用者對看過電影的評分作為加權係數,針對其到每一個新電影之間的 Jaccard 係數加權評分,獲得排序後的推薦電影列表。
// 使用者 u_124 看過的並給出高評分的電影
MATCH (u:`user`)-[e:watched]->(m:`movie`) WHERE id(u) == "u_124" AND e.rate > 3
WITH collect(id(m)) AS watched_movies_id
// 根據同樣也看過這些電影,並給出高評分的使用者,得出待推薦的電影
MATCH (u:`user`)-[e:watched]->(m:`movie`)<-[e0:watched]-(intersection:`user`)-[e1:watched]->(recomm:`movie`)
WHERE id(u) == "u_124" AND NOT id(recomm) IN watched_movies_id AND e0.rate >3 AND e1.rate > 3
WITH (e.rate - 2.5)/2.5 AS rate, m, recomm, size(COLLECT(intersection)) AS intersection_size ORDER BY intersection_size DESC LIMIT 50
// 計算 Jaccard index-------------------------------------------------
// 針對每一對 m 和 recomm:
// 開始計算看過的電影,集合 a 的部分
MATCH (m:`movie`)<-[e0:watched]-(intersection:`user`)
WHERE e0.rate >3
WITH rate, id(m) AS m_id, recomm, intersection_size, COLLECT(id(intersection)) AS set_a
// 計算推薦電影,集合 b 的部分
MATCH (recomm:`movie`)<-[e1:watched]-(intersection:`user`)
WHERE e1.rate >3
WITH rate, m_id, id(recomm) AS recomm_id, set_a, intersection_size, COLLECT(id(intersection)) AS set_b
// 得到並集數量
WITH rate, m_id, recomm_id, toFloat(intersection_size) AS intersection_size, toSet(set_a + set_b) AS A_U_B
// 得到每一對 m 和 recomm 的 Jaccard index = A_N_B/A_U_B
WITH rate, m_id, recomm_id, intersection_size/size(A_U_B) AS jaccard_index
// 計算 Jaccard index-------------------------------------------------
// 得到每一個被推薦的電影 recomm_id,經由不同看過電影推薦鏈路的相似度 = 評分 * jaccard_index
WITH recomm_id, m_id, (rate * jaccard_index) AS score
// 對每一個 recomm_id 按照 m_id 加權求得相似度的和,為總的推薦程度評分,降序排列,只取正值
WITH recomm_id, sum(score) AS sim_score ORDER BY sim_score DESC WHERE sim_score > 0
RETURN recomm_id, sim_score LIMIT 50結果:
| recomm_id | sim_score |
|---|---|
| 832 | 0.8428369424692955 |
| 114707 | 0.7913842214590154 |
| 64957 | 0.6924673321504288 |
| 120880 | 0.5775219768736295 |
| 807 | 0.497532028328161 |
| 473 | 0.4748322300870322 |
| 52797 | 0.2311965559170528 |
| 12768 | 0.19642857142857142 |
| 167058 | 0.19642857142857142 |
視覺化分析 ItemCF
同樣,我們把整個過程中的部分步驟查詢修改一下為 p=xxx 的方式,並渲染出來,看看有什麼有意思的的洞察。
步驟 1 的例子,找出推薦使用者評分過的電影:
// 使用者 u_124 看過的並給出高評分的電影
MATCH p=(u:`user`)-[e:watched]->(m:`movie`) WHERE id(u) == "u_124" AND e.rate > 3
RETURN p它們是:

步驟 2 的例子,經由使用者的高評分電影,找到其他給出高評分使用者所看過的新的高評分電影,修改結果為路徑:
// 使用者 u_124 看過的並給出高評分的電影
MATCH (u:`user`)-[e:watched]->(m:`movie`) WHERE id(u) == "u_124" AND e.rate > 3
WITH collect(id(m)) AS watched_movies_id
// 根據同樣也看過這些電影,並給出高評分的使用者,得出待推薦的電影
MATCH p=(u:`user`)-[e:watched]->(m:`movie`)<-[e0:watched]-(intersection:`user`)-[e1:watched]->(recomm:`movie`)
WHERE id(u) == "u_124" AND NOT id(recomm) IN watched_movies_id AND e0.rate >3 AND e1.rate > 3
WITH p, size(COLLECT(intersection)) AS intersection_size ORDER BY intersection_size DESC LIMIT 200可以看到待推薦的電影在路徑的右邊末端,中間連線著的都是其他使用者的推薦記錄,它的模式和 CBF 真的很像,只不過關聯的關係不是具體的內容,而是行為。

步驟 3 的例子,在得出每一對看過的電影和待推薦新電影之間的 Jaccard 係數之後,把使用者對看過電影的評分作為加權係數,針對其到每一個新電影之間的 Jaccard 係數加權評分,獲得排序後的推薦電影列表。這裡改造下最終的查詢為路徑,並渲染前 500 條路徑:
// 使用者 u_124 看過的並給出高評分的電影
MATCH (u:`user`)-[e:watched]->(m:`movie`) WHERE id(u) == "u_124" AND e.rate > 3
WITH collect(id(m)) AS watched_movies_id
// 根據同樣也看過這些電影,並給出高評分的使用者,得出待推薦的電影
MATCH (u:`user`)-[e:watched]->(m:`movie`)<-[e0:watched]-(intersection:`user`)-[e1:watched]->(recomm:`movie`)
WHERE id(u) == "u_124" AND NOT id(recomm) IN watched_movies_id AND e0.rate >3 AND e1.rate > 3
WITH (e.rate - 2.5)/2.5 AS rate, m, recomm, size(COLLECT(intersection)) AS intersection_size ORDER BY intersection_size DESC LIMIT 50
// 計算 Jaccard index-------------------------------------------------
// 針對每一對 m 和 recomm:
// 開始計算看過的電影,集合 a 的部分
MATCH (m:`movie`)<-[e0:watched]-(intersection:`user`)
WHERE e0.rate >3
WITH rate, id(m) AS m_id, recomm, intersection_size, COLLECT(id(intersection)) AS set_a
// 計算推薦電影,集合 b 的部分
MATCH (recomm:`movie`)<-[e1:watched]-(intersection:`user`)
WHERE e1.rate >3
WITH rate, m_id, id(recomm) AS recomm_id, set_a, intersection_size, COLLECT(id(intersection)) AS set_b
// 得到並集數量
WITH rate, m_id, recomm_id, toFloat(intersection_size) AS intersection_size, toSet(set_a + set_b) AS A_U_B
// 得到每一對 m 和 recomm 的 Jaccard index = A_N_B/A_U_B
WITH rate, m_id, recomm_id, intersection_size/size(A_U_B) AS jaccard_index
// 計算 Jaccard index-------------------------------------------------
// 得到每一個被推薦的電影 recomm_id,經由不同看過電影推薦鏈路的相似度 = 評分 * jaccard_index
WITH recomm_id, m_id, (rate * jaccard_index) AS score
// 對每一個 recomm_id 按照 m_id 加權求得相似度的和,為總的推薦程度評分,降序排列,只取正值
WITH recomm_id, sum(score) AS sim_score ORDER BY sim_score DESC WHERE sim_score > 0
WITH recomm_id LIMIT 10
WITH COLLECT(recomm_id) AS recomm_ids
MATCH p = (u:`user`)-[e:watched]->(m:`movie`)<-[e0:watched]-(intersection:`user`)-[e1:watched]->(recomm:`movie`)
WHERE id(u) == "u_124" AND id(recomm) in recomm_ids
RETURN p limit 500可以看出最推薦的兩部電影幾乎所有人看過,且是給過中高評分的使用者共同看過的電影:

關於”高評分“
這裡有個最佳化點,“高評分”其實是高於 3 的評分。這樣的設定會有失公允,更合理的方式是針對每一個使用者,取得這個使用者所有評分的平均值,再取得與平均值相差的比例或者絕對值判定高低。此外,在透過 Jaccard 相似性判斷每一部看過的電影和對應推薦電影的相似性時,並沒有考慮這層關聯關係:
(m:`movie`)<-[e0:watched]-(intersection:`user`)-[e1:watched]->(recomm:`movie`)e0 與 e1 的評分數值的作用因素只過濾了低評分的關係,可以做進一步最佳化。
Pearson Correlation Coefficient
皮爾遜積矩相關係數 Pearson Correlation Coefficient,就是考慮了關係中的數值進行相似性運算的方法。
Pearson Correlation Coefficient,縮寫 PCC。其定義為:
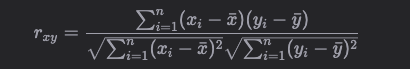
相比 Jaccard Index,它把物件之間關係中的數值與自身和所有物件的數值的平均值的差進行累加運算,在考慮了數值比重的同時考慮了數值基於物件自身的相對差異。
UserCF
下面,我們就利用 Pearson Correlation Coefficient 來舉例 UserCF 方法。
基於使用者的協同過濾方法分如下四步:
- 找出和推薦使用者同樣給出評分過的電影的使用者;
- 運算 Pearson Correlation Coefficient 得到和推薦使用者興趣接近的使用者;
- 透過興趣接近使用者得到高評分未觀看電影;
- 根據觀看使用者的 Pearson Correlation Coefficient 加權,排序得推薦電影列表;
// 找出和使用者 u_2 看過相同電影的使用者, 得電影評分
MATCH (u:`user`)-[e0:watched]->(m:`movie`)<-[e1:watched]-(u_sim:`user`)
WHERE id(u) == "u_2" AND id(u_sim) != "u_2"
WITH u, u_sim, collect(id(m)) AS watched_movies_id, COLLECT({e0: e0, e1: e1}) AS e
// 計算 u_2 和這些使用者的 pearson_cc
MATCH (u:`user`)-[e0:watched]->(m:`movie`)
WITH u_sim, watched_movies_id, avg(e0.rate) AS u_mean, e
MATCH (u_sim:`user`)-[e1:watched]->(recomm:`movie`)
WITH u_sim, watched_movies_id, u_mean, avg(e1.rate) AS u_sim_mean, e AS e_
UNWIND e_ AS e
WITH sum((e.e0.rate - u_mean) * (e.e1.rate - u_sim_mean) ) AS numerator,
sqrt(sum(exp2(e.e0.rate - u_mean)) * sum(exp2(e.e1.rate - u_sim_mean))) AS denominator,
u_sim, watched_movies_id WHERE denominator != 0
// 取 pearson_cc 最大的 50 個相似使用者
WITH u_sim, watched_movies_id, numerator/denominator AS pearson_cc ORDER BY pearson_cc DESC LIMIT 50
// 取相似使用者給出高評分的新電影,根據相似使用者個數對使用者相似程度 pearson_cc 加權,獲得推薦列表
MATCH (u_sim:`user`)-[e1:watched]->(recomm:`movie`)
WHERE NOT id(recomm) IN watched_movies_id AND e1.rate > 3
RETURN recomm, sum(pearson_cc) AS sim_score ORDER BY sim_score DESC LIMIT 50結果:
| recomm | sim_score |
|---|---|
| ("120880" :movie{name: "I The Movie"}) | 33.018868012270396 |
| ("167058" :movie{name: "We"}) | 22.38531462958867 |
| ("12768" :movie{name: "We"}) | 22.38531462958867 |
| ("55207" :movie{name: "Silence"}) | 22.342886447570585 |
| ("170339" :movie{name: "Silence"}) | 22.342886447570585 |
| ("114707" :movie{name: "Raid"}) | 21.384280909249796 |
| ("10" :movie{name: "Star Wars"}) | 19.51546960750133 |
| ("11" :movie{name: "Star Wars"}) | 19.515469607501327 |
| ("64957" :movie{name: "Mat"}) | 18.142639694676603 |
| ("187689" :movie{name: "Sin"}) | 18.078111338733557 |
視覺化分析 UserCF
再看看 UserCF 的視覺化結果吧:
步驟 1 的例子,找出和推薦使用者同樣給出評分過的電影的使用者:
// 找出和使用者 u_2 看過相同電影的使用者
MATCH p=(u:`user`)-[e0:watched]->(m:`movie`)<-[e1:watched]-(u_sim:`user`)
WHERE id(u) == "u_2" AND id(u_sim) != "u_2"
RETURN p
步驟 2 的例子,運算 Pearson Correlation Coefficient 得到和推薦使用者興趣接近的使用者,輸出這些接近的使用者:
// 找出和使用者 u_2 看過相同電影的使用者, 得電影評分
MATCH (u:`user`)-[e0:watched]->(m:`movie`)<-[e1:watched]-(u_sim:`user`)
WHERE id(u) == "u_2" AND id(u_sim) != "u_2"
WITH u, u_sim, collect(id(m)) AS watched_movies_id, COLLECT({e0: e0, e1: e1}) AS e
// 計算 u_2 和這些使用者的 pearson_cc
MATCH (u:`user`)-[e0:watched]->(m:`movie`)
WITH u_sim, watched_movies_id, avg(e0.rate) AS u_mean, e
MATCH (u_sim:`user`)-[e1:watched]->(recomm:`movie`)
WITH u_sim, watched_movies_id, u_mean, avg(e1.rate) AS u_sim_mean, e AS e_
UNWIND e_ AS e
WITH sum((e.e0.rate - u_mean) * (e.e1.rate - u_sim_mean) ) AS numerator,
sqrt(sum(exp2(e.e0.rate - u_mean)) * sum(exp2(e.e1.rate - u_sim_mean))) AS denominator,
u_sim, watched_movies_id WHERE denominator != 0
// 取 pearson_cc 最大的 50 個相似使用者
WITH u_sim, watched_movies_id, numerator/denominator AS pearson_cc ORDER BY pearson_cc DESC LIMIT 50
RETURN u_sim我們給它們標記一下顏色:

步驟 3 的例子,透過興趣接近使用者得到高評分未觀看電影,根據觀看使用者的 Pearson Correlation Coefficient 加權,排序得推薦電影列表。我們把結果輸出為這些相似使用者的高評分電影路徑:
// 找出和使用者 u_2 看過相同電影的使用者, 得電影評分
MATCH (u:`user`)-[e0:watched]->(m:`movie`)<-[e1:watched]-(u_sim:`user`)
WHERE id(u) == "u_2" AND id(u_sim) != "u_2"
WITH u, u_sim, collect(id(m)) AS watched_movies_id, COLLECT({e0: e0, e1: e1}) AS e
// 計算 u_2 和這些使用者的 pearson_cc
MATCH (u:`user`)-[e0:watched]->(m:`movie`)
WITH u_sim, watched_movies_id, avg(e0.rate) AS u_mean, e
MATCH (u_sim:`user`)-[e1:watched]->(recomm:`movie`)
WITH u_sim, watched_movies_id, u_mean, avg(e1.rate) AS u_sim_mean, e AS e_
UNWIND e_ AS e
WITH sum((e.e0.rate - u_mean) * (e.e1.rate - u_sim_mean) ) AS numerator,
sqrt(sum(exp2(e.e0.rate - u_mean)) * sum(exp2(e.e1.rate - u_sim_mean))) AS denominator,
u_sim, watched_movies_id WHERE denominator != 0
// 取 pearson_cc 最大的 50 個相似使用者
WITH u_sim, watched_movies_id, numerator/denominator AS pearson_cc ORDER BY pearson_cc DESC LIMIT 50
// 取相似使用者給出高評分的新電影,根據相似使用者個數對使用者相似程度 pearson_cc 加權,獲得推薦列表
MATCH p=(u_sim:`user`)-[e1:watched]->(recomm:`movie`)
WHERE NOT id(recomm) IN watched_movies_id AND e1.rate > 3
WITH p, recomm, sum(pearson_cc) AS sim_score ORDER BY sim_score DESC LIMIT 50
RETURN p得到的結果,我們增量渲染到畫布上可以得到:這些 UserCF 推薦而得的電影在路徑末端:

在視覺化中,相似使用者的高評分未觀看電影被推薦的思想是不是一目瞭然了呢?
混合的方法
在真實的應用場景裡,達到最好效果的方法通常是結合不同的協同方法,這樣既可以讓不同角度的有用資訊得到充分利用,又能彌補單一方法在不同資料量、不同階段的弱點。
具體的結合方法在工程上千差萬別,這裡就不做展開。不過,拋磚引玉我們來看一種基於模型的混合方式。
基於模型的方法
上面講過基於內容的(電影的領域知識、關係)、協同的(使用者與使用者、使用者與電影之間的互動關係)的演算法來直接進行相關推薦。但實際上,它們也可以作為機器學習的輸入特徵,用統計學的方法得到一個模型,用來預測使用者可能喜歡的物件(電影),這就是基於模型的方法。
基於模型的方法可以很自然地把以上幾種過濾方法作為特徵,本質上這也是混合過濾方法的一種實現。
基於模型、機器學習的推薦系統方法有很多,這裡著重同圖、圖資料庫相關的方法,講解其中基於圖神經網路 GNN 方法。
GNN 的方法可以將圖譜中的內容資訊(導演、演員、型別)和協同資訊(使用者-使用者、電影-電影、使用者-電影之間的相互關係)以知識的方式嵌入,並且方法中的訊息傳遞方式保有了圖中的區域性性(locality),這使得它可能成為一個非常新穎、有效的推薦系統模型方法。
GNN + 圖資料庫的推薦系統
為什麼需要圖資料庫?
GNN 的方法中,圖資料庫只是一個可選項,而我給的 GNN 方法的示例中,圖資料庫的關鍵作用是它帶來了實時性的可能。
一個實時性推薦系統要求在秒級響應下利用 GNN 訓練模型從近實時的輸入資料中進行推理,這給我們提出的要求是:
- 輸入資料可以實時、近實時獲取;
- 推理運算可以實時完成;
而利用歸納型 Inductive model 的模型從圖資料庫中實時獲取新的資料子圖作為推理輸入是一個滿足這樣要求可行的設計方式。
下邊是簡單的流程圖:
左邊是模型訓練,在圖譜的二分圖(user 和 item)之上建模
使用者和物件(movie)之間的關係除了互動關係之外,還有預先處理的關係,這些關係被查詢獲得後再寫回圖資料庫中供後續消費使用,關係有:
- 使用者間“相似”關係
- 物件間不同(共同演員、型別、導演)關係
- 利用 Nebula-DGL 將圖中需要的點、邊序列化為圖深度學習框架 DGL 可以消費的物件
- 在 DGL 中分割訓練、測試、驗證集,利用 PinSAGE 模型訓練
- 匯出模型給推薦系統使用
右邊是匯出的模型作為推理介面的推薦系統
- 基於相簿的實時圖譜上一直會有實時的資料更新,節點增減
- 當給定的使用者推薦請求過來的時候,相簿中以該使用者為起點的子圖會被獲取(1.)、作為輸入傳送給推理介面(2.)
- 推理介面把子圖輸入給之前訓練的模型,獲得該使用者在子圖中關聯的新物件中的評分排序(3.)作為推薦結果

由於篇幅關係,這裡不做端到端的例項程式碼展示,後續有機會我會出個 demo。
推薦系統可解釋性
在結束本章之前,最後舉一個圖資料庫在推薦系統中的典型應用:推薦理由。
下圖是美團、大眾點評中的一個常見的搜尋、推薦結果。現在推薦系統的複雜度非常高,一方面由實現方式的特性決定,另一方面最終推薦由多個協同系統組合生成最終排名,這使得系統很難對推薦結果進行解釋。
得益於被推薦使用者和物件、以及他們的各種各樣畫像最終形成的知識圖譜,我們只需要在圖譜中對推薦結果進行“路徑查詢”就可以獲得很有意義的解釋,像是如下截圖的“在北京喜歡北京菜的山東老鄉都說這家店很贊”就是這樣獲得的解釋。

圖片來源:美團案例分享
可解釋性的例子
回到我們們電影推薦的圖譜上,前邊的演算法中我們獲得過使用者 u_124 的推薦電影 1891(星球大戰),那麼我們可以透過這一個查詢獲得它的推薦解釋:
FIND NOLOOP PATH FROM "u_124" TO "1891" over * BIDIRECT UPTO 4 STEPS yield path as `p` | LIMIT 20我們可以很快獲得 20 條路徑:
(root@nebula) [moviegraph]> FIND NOLOOP PATH FROM "u_124" TO "1891" over * BIDIRECT UPTO 4 STEPS yield path as `p` | LIMIT 20
+-----------------------------------------------------------------------------------------------------+
| p |
+-----------------------------------------------------------------------------------------------------+
| <("u_124")-[:watched@0 {}]->("11")-[:with_genre@0 {}]->("g_49")<-[:with_genre@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:with_genre@0 {}]->("g_17")<-[:with_genre@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:with_genre@0 {}]->("g_10281")<-[:with_genre@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:acted_by@0 {}]->("p_4")<-[:acted_by@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:acted_by@0 {}]->("p_3")<-[:acted_by@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:acted_by@0 {}]->("p_24342")<-[:acted_by@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:acted_by@0 {}]->("p_2")<-[:acted_by@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("832")-[:with_genre@0 {}]->("g_1110")<-[:with_genre@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:with_genre@0 {}]->("g_1110")<-[:with_genre@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:acted_by@0 {}]->("p_13463")<-[:acted_by@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:acted_by@0 {}]->("p_12248")<-[:acted_by@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("47981")-[:with_genre@0 {}]->("g_10219")<-[:with_genre@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:acted_by@0 {}]->("p_6")<-[:acted_by@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("497")-[:with_genre@0 {}]->("g_104")<-[:with_genre@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("120880")-[:with_genre@0 {}]->("g_104")<-[:with_genre@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:with_genre@0 {}]->("g_104")<-[:with_genre@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:acted_by@0 {}]->("p_130")<-[:acted_by@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("497")-[:with_genre@0 {}]->("g_50")<-[:with_genre@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11635")-[:with_genre@0 {}]->("g_50")<-[:with_genre@0 {}]-("1891")> |
| <("u_124")-[:watched@0 {}]->("11")-[:with_genre@0 {}]->("g_50")<-[:with_genre@0 {}]-("1891")> |
+-----------------------------------------------------------------------------------------------------+
Got 20 rows (time spent 267151/278139 us)
Wed, 09 Nov 2022 19:05:56 CST我們在結果視覺化中可以很容易看出這個推薦的結果可以是:
- 曾經喜歡的星戰電影的大部分演職人員都也參與了這部和同樣是“奧斯卡獲獎”且“經典”的電影。

總結
圖資料庫可作為推薦系統中資訊的最終形式,儘管在很多推薦實現中,相簿不一定是最終落地系統方案的選擇,但圖資料庫所帶來的視覺化洞察的潛力還是非常大的。
同時,構建的綜合知識圖譜上的解釋、推理能力與一些實時要求高的圖方法中,比如:GNN的基於模型方法上能起到帶來獨一無二的作用。
延伸閱讀
- Content-based Recommender Systems: State of the Art and Trends
- A DYNAMIC COLLABORATIVE FILTERING SYSTEM VIA A WEIGHTED CLUSTERING APPROACH
- Nebula-UP:https://github.com/wey-gu/nebula-up
- 資料集倉庫:https://github.com/wey-gu/movie-recommendation-dataset
- Jaccard Index:https://en.wikipedia.org/wiki/Jaccard_index
- Pearson Correlation Coefficient:https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
- DGL 流行的圖深度學習礦建,專案官網:https://www.dgl.ai
- Nebula-DGL:https://github.com/wey-gu/nebula-dgl
- PinSAGE:https://arxiv.org/abs/1806.01973
- 美團案例分享:[https://tech.meituan.com/2021...](https://tech.meituan.com/2021...
)
謝謝你讀完本文 (///▽///)
要來近距離體驗一把圖資料庫嗎?現在可以用用 NebulaGraph Cloud 來搭建自己的圖資料系統喲,快來節省大量的部署安裝時間來搞定業務吧~ NebulaGraph 阿里雲端計算巢現 30 天免費使用中,點選連結來用用圖資料庫吧~
想看原始碼的小夥伴可以前往 GitHub 閱讀、使用、(^з^)-☆ star 它 -> GitHub;和其他的 NebulaGraph 使用者一起交流圖資料庫技術和應用技能,留下「你的名片」一起玩耍呢~