推薦演算法在用例排序最佳化上的應用
01 背景
隨著持續整合和敏捷開發的不斷髮展,移動應用的釋出變得越來越頻繁。以B站應用為例,主站粉版APP每週都會發布一次新的版本,主站HD應用的Android端與ipad端每週交替釋出新的版本。在應用快速迭代的同時,QA需要在規定時間內進行大量的迴歸測試以保證應用的質量。一方面,大量的測試用例需要耗費較多的人力和時間,另一方面,BUG檢出時間的不確定性導致給予研發修復的時間並不是很充足。因此急需一種技術來幫助QA快速篩選出高風險用例,將BUG的發現時間提前,從而給研發更多時間去修復BUG。在此背景下,我們經過調研後,選擇了使用測試用例排序最佳化技術(Test Case Prioritization,以下簡稱TCP)來幫助QA對測試用例進行優先順序排序,提高測試效率。
02 相關技術
2.1 什麼是TCP
測試用例排序最佳化技術(Test Case Prioritization)最早由Rothermel[1]提出,他對測試最佳化問題給出瞭如下定義:

通俗地講,就是對測試用例集合 T 進行排列,找到一種最優排列 T' ,使得按照這種排列順序進行測試,能夠給到我們最大的收益。TCP的目標標準可能各不相同,在本文及實際應用中,我們希望經過排序後的測試集合能夠更早地發現BUG。換句話說,我們希望排列越靠前的用例,檢出BUG的機率能夠更高。這樣一來給予了研發充足的時間去修復BUG,二來幫助QA篩選出冗餘的用例,從而降低測試成本。
2.2 如何衡量TCP的效果
我們介紹了TCP技術的定義,但還沒有對評價函式 f 給出具體的實現方案。一般而言,評價函式 f 可以劃分為兩類:特定評價函式以及通用評價函式。針對前者,學術界提出了 APFD(Average Percentage of Fault Detection)[1]指標,這也是TCP問題最常用的評價函式,它的設計目標是衡量TCP技術發現BUG的時機。APFD的定義如下:

APFD的值越接近1,表示發現BUG的時機越早。
針對通用評價函式,我們採用了BUG召回率(recall)作為評價標準。但同時召回率指標又與測試數量高度相關,即如果所有測試用例都被執行,那召回率永遠都是100%,因為所有的BUG都被召回了。因此我們設計了 recall_p ,只針對部分測試用例計算其召回率,定義如下 :

recall越接近1,表示遺漏的BUG越少。
我們利用APFD來評估應用TCP技術後BUG發現的時機是否提前了,同時利用recall來觀察在僅使用部分測試用例的情況下BUG遺漏的情況。
2.3 推薦演算法
推薦演算法目前被廣泛地運用在廣告、搜尋等相關領域,業界也有不少成熟的解決方案。簡單地講,推薦演算法的輸入為使用者特徵和物品/廣告特徵,在經過特定模型計算後,演算法會給出一個推薦的物品/廣告列表。常用的推薦演算法包括協同過濾演算法、基於內容推薦以及混合推薦。
03 方法
3.1 問題對映
如何從成千上萬個測試用例中,挑選出具有高風險、容易出BUG的測試用例,這看上去是一個相當有挑戰的任務。傳統上大家都在對測試用例的特徵進行深入分析,希望發現那些具有高風險的用例具有的相同特徵。但實際上,應用是否出BUG,本質上取決於改動了什麼程式碼。也就是說,我們在分析測試用例特徵的同時,還需要對改動程式碼的特徵進行分析,而對程式碼的分析則更加具有難度。Pan[2]的研究顯示,大部分TCP技術針對程式碼的特徵都僅僅使用了程式碼行數這種比較淺顯、易獲取的特徵。
既然對程式碼的分析困難重重,那麼有沒有辦法可以減少甚至跳過對程式碼的分析呢?受到推薦系統的啟發,我們認為可以透過加入需求特徵的方式,跳過對程式碼特徵的分析。

如圖所示,在推薦系統中,使用者通常會有不同的喜好,不同的喜好對應可能不同的感興趣的物品。而這種喜好可能並不會顯示地告訴系統,因此推薦系統會根據使用者的特徵,結合物品的特徵對使用者進行推薦。
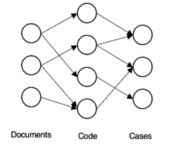
類似地,不同的需求通常會改動不同的程式碼,而這些程式碼則對應會影響某些測試用例。我們希望TCP能夠像推薦系統一樣,結合需求及用例特徵推薦測試用例。
為了將推薦演算法應用到TCP問題上,我們將TCP問題重新建模,進行如下定義:

這樣我們就將一個TCP問題轉化為推薦演算法問題,從而可以使用推薦演算法解決。
3.2 資料
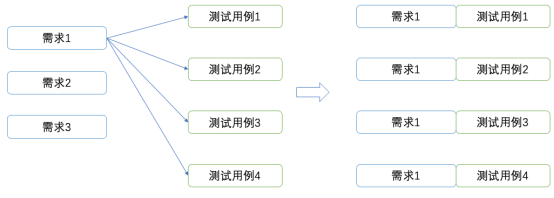
目前我們擁有了需求資料和測試用例資料,如何將它們關聯起來從而可以進行模型訓練呢?比較容易想到的方法就是將需求資料與測試用例資料做笛卡爾積,也就是對於每一份需求資料,都將其與所有的測試用例進行關聯,也即認為一個需求對所有的測試用例都可能產生影響。這種關聯方法優點在於減少了遺漏,不會漏掉需求或者測試用例,但也有明顯的缺點,需求並不會對所有的測試用例都產生影響。
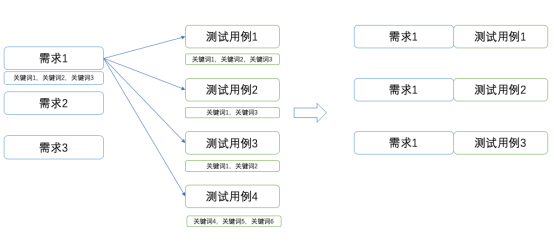
為此,我們設計了關鍵詞關聯法,在不增加工作量的基礎上,加強需求與測試用例的關聯關係。該方法透過將需求和測試用例拆分為關鍵詞片語,若需求關鍵詞片語與用例關鍵詞片語存在交集,則認為兩者存在關聯。這也是一種非常直觀的方法,即需求對應的業務與測試用例對應的業務如果相同,那麼兩者之間有較大機率存在關聯,反之亦然。
3.3 模型
我們使用的需求資料與測試用例資料的特徵非常稀疏,且樣本數量與業界動則上億的樣本數量相比顯得非常少,因此需要精心挑選推薦模型,以求模型能夠達到較好擬合效果。我們比較了Logistic Regression(LR)、Factorization Machine(FM)、Deep Structured Semantic Model(DSSM)、XGBoost、RandomForest等模型演算法,並進行了相關實驗,最終我們選擇了FM模型作為主要的推薦模型。
04 實驗結果
為了探究將推薦演算法應用到TCP問題上的效果,我們設計了以下3個問題來驗證我們方法的有效性。
問題1. 我們的方法對比用例隨機排序有提升嗎?
問題2. 使用需求資料與不使用需求資料,有多大的區別?
問題3. 關鍵詞關聯法到底有沒有效果?
我們使用了嗶哩嗶哩粉版6.53.0~6.84.0共計31個版本的應用來進行實驗。
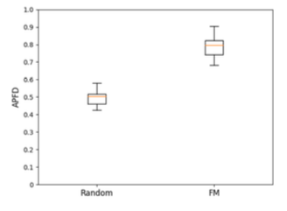
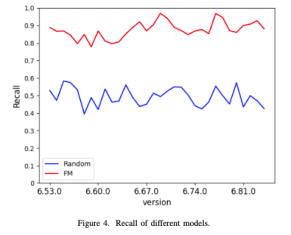
問題1的實驗結果如上圖。APFD的箱型圖顯示,採用FM演算法後,發現BUG的時機相比隨機結果提前了非常多,這表明我們的整體方法是有效的。同時,我們使用Recall_{0.5} 來觀察BUG的遺漏情況,可以看到在使用一半的測試用例的情況下,平均召回率可以達到90%,即只有10%左右的BUG會遺漏。
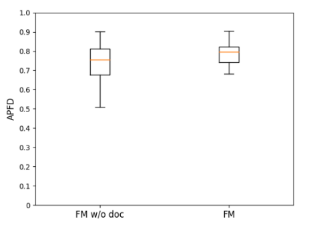
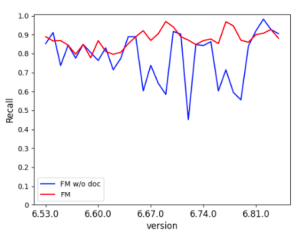
問題2的實驗結果如上圖。從APFD箱型圖我們可以看到,儘管使用需求資料與不使用需求資料的APFD在均值上相差僅4~5個百分點,但不使用需求資料的APFD分佈更加分散,即僅使用測試用例的情況下,預測BUG的效果並不穩定,並不能穩定將BUG的發現時機提前。再看召回率圖則更加明顯,僅使用測試用例的模型,其召回率非常不穩定,極端情況甚至出現低於50%的召回率,即使用一半的測試用例,甚至無法召回一半的BUG。這個實驗表明,在增加了需求資料後,採用FM演算法對測試用例進行排序,其效果更加穩定。
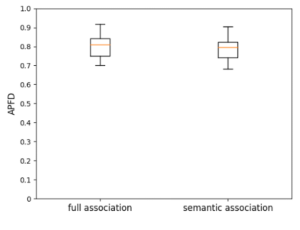
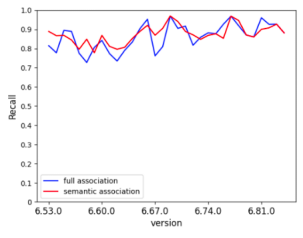

問題3的實驗結果如上圖。出乎意料的是,全量關聯法在APFD上要比關鍵詞關聯法表現稍好,即其排列的測試用例,發現BUG的時機要提前一些,但是在召回率上的表現要比關鍵詞關聯法稍低一些,且穩定性也不如關鍵詞關聯法。因此,是否採用關鍵詞關聯法,取決於我們更關注BUG的發現時機,還是BUG的漏測率,但兩者本質上並無太大差距。
05 實際落地
如何將TCP技術應用於實際的生產中呢?我們選擇採用例推薦的方式來應用TCP技術。具體的過程如下:
輸入當前版本的需求資料及測試用例資料後,我們會透過已經訓練好的FM模型給測試用例打分,進而排序。同時,系統會給排序在前 p % 的用例打上“推薦”標籤。QA們在迴歸測試時,選擇優先去測試打上“推薦”標籤的用例。在時間充足的情況,QA可以選擇迴歸全量測試用例,由於BUG的發現時間提前了,研發們會有更多時間去修復BUG。而一旦測試時間比較緊急,則可以選擇延後測試那些沒有被推薦的測試用例,這樣可以在儘量保證應用質量的同時,不影響應用迭代釋出的時間。
以嗶哩嗶哩粉版應用為例,首先選擇應用及要對用例進行排序的版本,然後根據實際需求選擇推薦的用例比例。

點選【用例推薦】後,Jenkins會自動執行資料下載、模型訓練、模型預測等過程。

模型在執行完打分程式後,會同步更新至TAPD平臺,在每條用例上更新【出BUG機率分】和【是否優先推薦】屬性。

在執行完迴歸測試後,我們也會收集發現的BUG,並計算召回覆蓋率,從而觀察模型的效能,並進行調整最佳化。
06 展望
目前我們已經將需求及測試用例的特徵挖掘地差不多了,實際更改模型後也並未取得更好的效果。因此我們還需要將目光投向程式碼特徵,如何在儘可能不增加複雜度及工作量的情況下,獲取更多更豐富的程式碼特徵,並加入模型訓練,成為我們下一步的目標。
來自 “ 嗶哩嗶哩技術 ”, 原文作者:王京京;原文連結:http://server.it168.com/a2022/1221/6781/000006781734.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 紅豆Live推薦演算法中召回和排序的應用和策略演算法排序
- 阿里可解釋性推薦演算法應用阿里演算法
- Netflix 推薦系統 (Part One)-排序演算法排序演算法
- 線上腦圖測試用例管理平臺求推薦~
- 推薦幾個我在用的Android studio外掛Android
- 容器應用測試的妙招推薦!
- 【推薦演算法】推薦系統的評估演算法
- 第6講回顧:聯邦推薦演算法及其應用演算法
- AutoML 在推薦系統中的應用TOML
- 取消演算法推薦,是技術上的倒退嗎?演算法
- 9款AI女友應用推薦AI
- Pinterest:將GCN應用於影像推薦RESTGC
- Pinterest:將GCN應用於影象推薦RESTGC
- Talroo使用Analytics Zoo和AWS利用深度學習在工作推薦上的應用深度學習
- 推薦演算法的“前世今生”演算法
- 推薦一款好用的Macos應用Radial MenuMac
- Embedding在騰訊應用寶的推薦實踐
- 知識蒸餾在推薦系統的應用
- Java中可以用的大資料推薦演算法Java大資料演算法
- 騰訊QQ大資料:神盾推薦——MAB演算法應用總結大資料演算法
- 用Spark學習矩陣分解推薦演算法Spark矩陣演算法
- YouTube視訊的推薦演算法演算法
- 推薦系統應該如何保障推薦的多樣性?
- 使用Spring Reactor最佳化推薦流程SpringReact
- 精準測試之用例推薦
- 協同過濾在推薦系統中的應用
- Debias 技術在金融推薦場景下的應用
- 雲音樂推薦系統(二):推薦系統的核心演算法演算法
- 精簡推薦演算法演算法
- 基於遺傳最佳化的協同過濾推薦演算法matlab模擬演算法Matlab
- 應用推薦:開源磁碟分割槽工具 GParted
- 個性化推薦系統實踐應用
- 常用的排序演算法(五)--選擇排序以及最佳化(PHP實現)排序演算法PHP
- 互動式推薦在外賣場景的探索與應用
- Apple推薦的2020年最佳應用程式已經出爐APP
- oracle最佳化相關書籍推薦Oracle
- 推薦演算法(二)--演算法總結演算法
- 5大移動應用開發平臺推薦