漫談混淆技術----從Citadel混淆殼說起
Author:360天眼實驗室
0x00 前言
由於殺軟對商業殼比較敏感,並且商業殼檢測,脫殼技術比較成熟,病毒作者一般不會去選擇用商業的殼來保護自己的惡意程式碼,所以混淆殼成為了一個不錯的選擇.混淆殼可以有效對抗殺軟,因為這種殼一般不存在通用的檢測方法,並且很難去靜態的脫殼,所以其惡意程式碼就不會被發現,從而使自己長時間的存在.對於惡意程式碼分析者來說,分析這種帶混淆殼的樣本往往會花費很大精力,甚至有時候會使分析變得不可能。本文主要幾種常見的混淆手段,不涉及樣本本身功能分析。
0x01 從一個樣本說起
Citadel(md5: 767a861623802da72fd6c96ce3a33bff)是一個zeus的衍生版本,其較zeus更加的健壯,也更穩定。前一段時間發現了一個citadel 樣本,較之普通的citadel稍微有一點特別,其整體的結構如下圖:
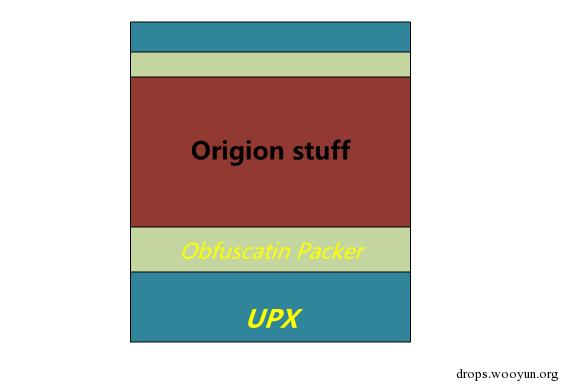
圖1 Citadel樣本結構
即外層加了upx的殼,裡面是一個混淆殼,再往裡面才是citadel原始程式碼。脫掉UPX後的,混淆殼程式碼分支總覽圖:
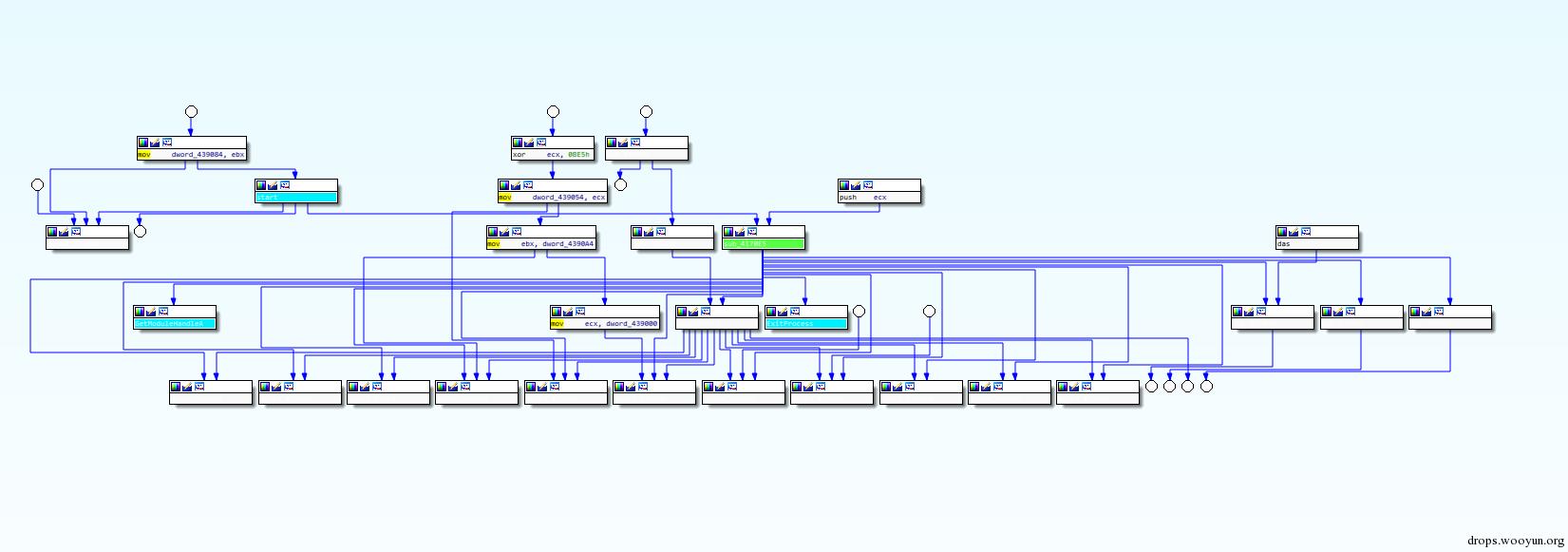
圖2混淆殼程式碼分支總覽圖
對於citadel樣本本身的功能與特點,本文不會提及,剛興趣的可以自己去查資料,這裡主要講講citadel殼的一些特點,與常見的幾種混淆的手段。
下面的圖為該混淆殼的混淆程式碼片段,其中這麼一大段程式碼中只有紅框中的指令是有用的。其他都是無效指令。很顯然比一般的垃圾指令填充不知道高到哪裡去了。
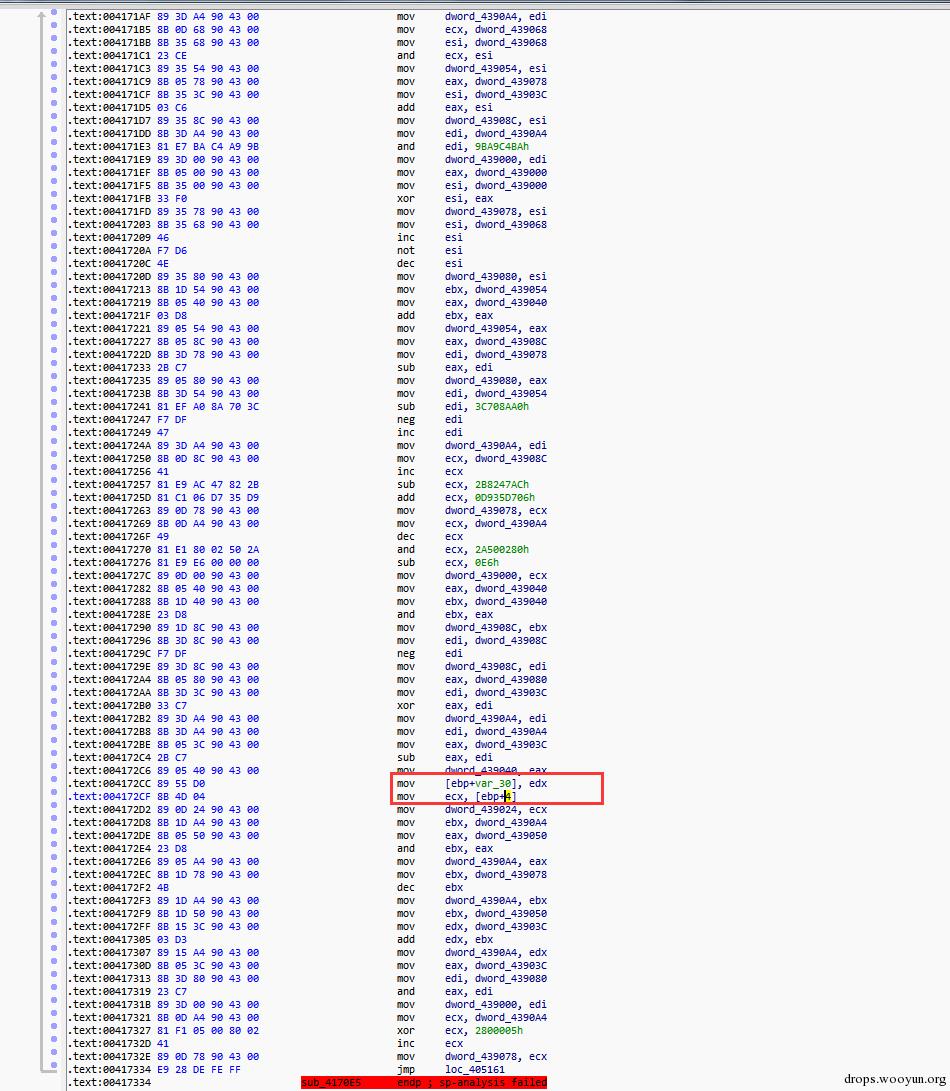
圖 3,混淆片段例項
1.1 Citadel混淆殼的一個trick
當手動脫掉upx後,執行樣本後就崩潰了,然而不脫upx殼,樣本是可以正常執行的。執行前後api trace 對比圖:

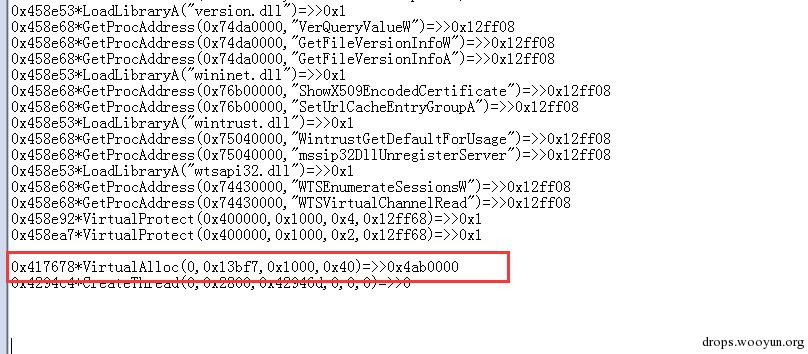
圖4,api trace
其中上圖是脫掉upx殼的api log,下圖為沒脫upx殼的api log,從圖中我們可以看到在地址0x4176768地址中的呼叫的API名不同。很顯然從這裡出錯了。從這個地址往上回溯,這個呼叫api的過程被劃分為十幾個程式碼塊,然後利用JMP連線起來,其中每個程式碼塊就只有一兩條程式碼是有效指令:
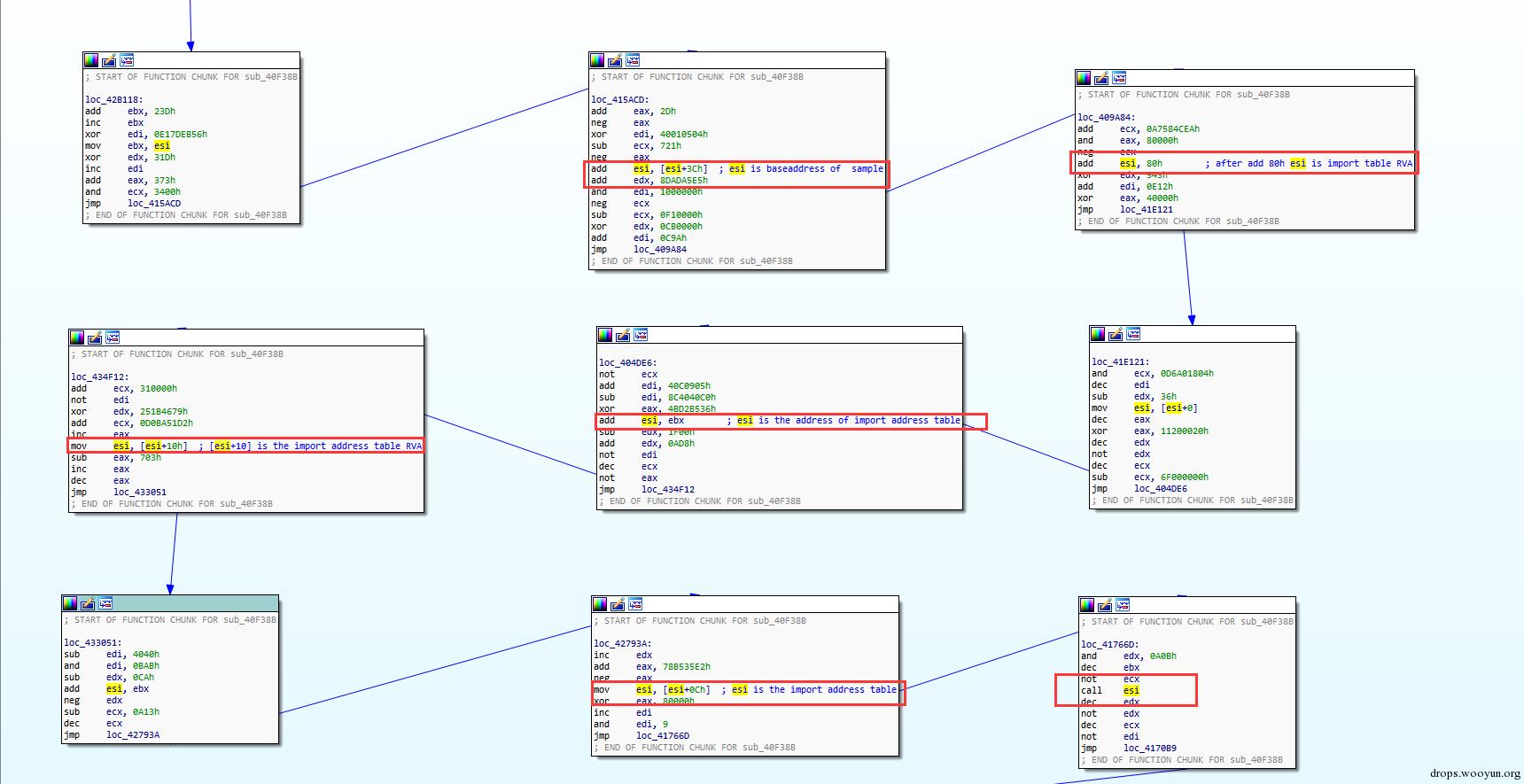
圖5,獲取匯入表匯入函式地址表第四項過程
透過上圖我們發現call esi指令中esi的值由mov esi,[esi+0xch]獲得,esi+0xch的值是匯入函式地址表中第四項的api的地址。所以問題很可能出現在這裡,即脫殼後與脫殼前匯入地址表第四項api不同。

圖6,沒脫upx殼的匯入函式地址表:

圖 7,脫掉upx殼的第四項:
所以我們可以看出問題就出現在這裡。即脫殼後與脫殼前匯入函式地址表的不同導致了脫殼後citadel執行奔潰.從這一點可以看出這個樣本在加殼的時候就是upx殼與內層混淆殼是天然一體的。
1.2 混淆殼整個的執行流程

圖 8,,程式碼執行流程
- upx殼程式碼執行。
- 混淆程式碼Routine 1。
- 解密Routine2程式碼(堆記憶體)。
- Routine2 執行(堆程式碼),解密原始citadel程式碼,修復api呼叫函式地址。
- 執行原始citadel程式碼流程。
1.3 混淆程式碼的細節
在這個樣本中,各種混淆函式中,大部分的程式碼是操作都是在操作0x439000-0x4390a4區塊的資料,其中混淆函式里面插入一兩條真正有用的程式碼,如圖1紅框中的指令,然後這些混淆函式串聯起來,完成對0x4390a8開始大小為0x3b70的資料的解密。如果對這種型別混淆殼不熟悉的的話很容易被這些無用的混淆指令所干擾,分析人員可能會花費大量的時間在理解這些無用的計算上面了。
1.4混淆程式碼snippet 型別
如前面所說citadel大部分的混淆程式碼主要是運算元據讀寫,主要的混淆程式碼是由一下幾種模式組合起來,形成這種長的混淆程式碼片段的,作者使用這幾種模式:
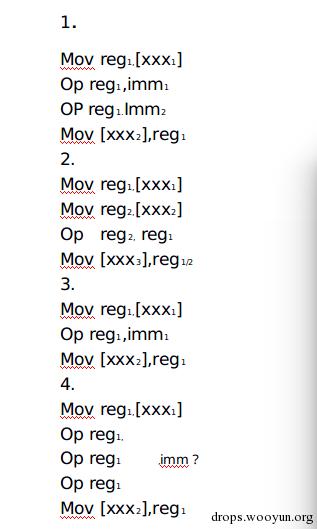
如下圖所示

圖9,混淆模式
基本上在Routine1的混淆程式碼中就是這種程式碼的隨機組合形成的,然後用控制流程指令,如jmp/jz/jnz/jne/je連線起來。
0x02 混淆殼常見的幾種技術手段
- 控制流程混淆
- 資料混淆
- 程式碼混淆
需要說明的是這幾種混淆方式是完全可以同時存在的。
2.1 控制流程混淆
2.1.1 碼塊亂序
對於編譯器來說在生成程式碼的時候,一般情況下邏輯相關的程式碼塊都處在相距離比較近的位置。但是對於混淆來說是故意打破這種規則的,毫無疑問這將會使分析人員花費更長的時間來分析此類樣本。
2.1.2 程式碼塊分割
即將一個函式過程分割成更多的流程。擾亂分析者對樣本分析,很顯然這樣的過程會使分析者感到沮喪,嚴重拖慢了分析效率。這個在citadel中是有體現的。即在執行Routine2堆記憶體程式碼的時候:
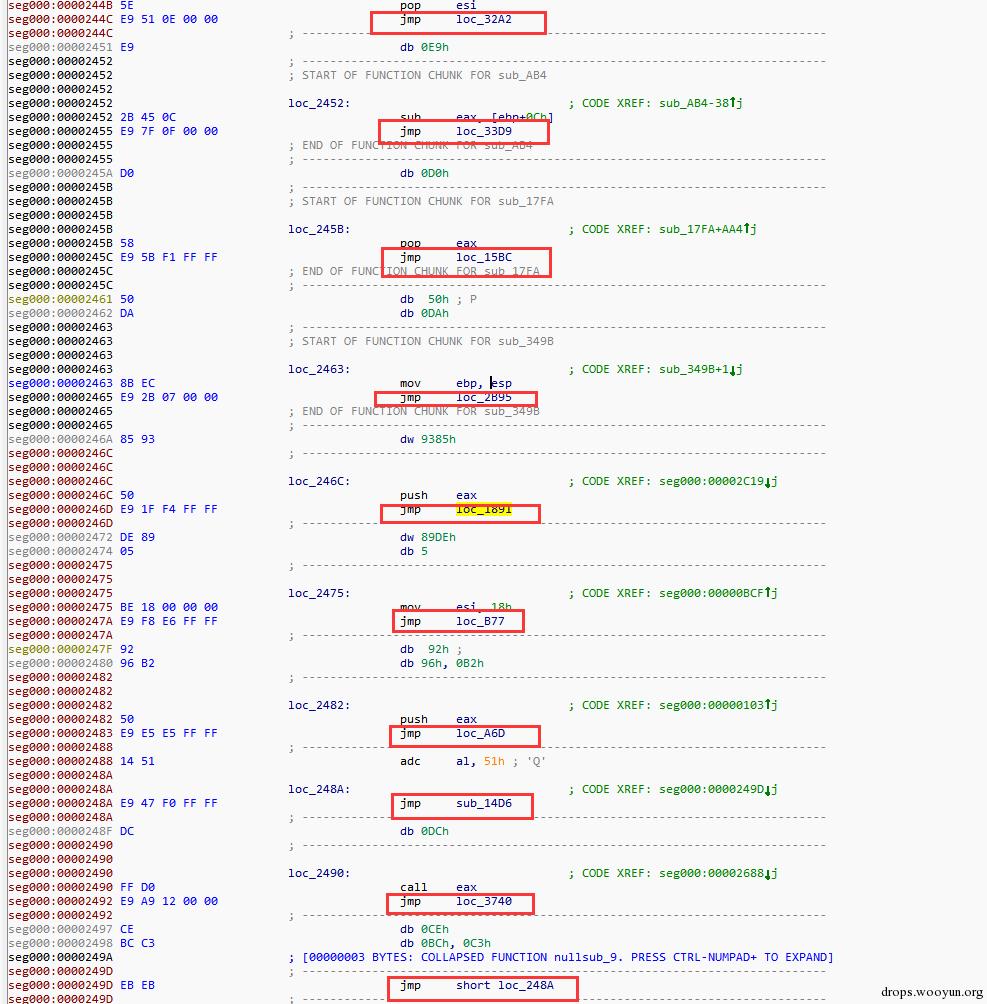
圖10 程式碼塊分割
每執行一跳指令就會jmp到另一個程式碼塊。當然這只是一個很小的例子,其中這裡面可以更加的複雜,比如新增更多的dead code blocks。
2.2 資料混淆
2.2.1 常量拆分(constant unfolding)
常量拆分是一個比較常用的混淆手段,主要目的是隱藏真實的程式碼邏輯,讓分析者內心崩潰
比如:value=9*8,實際上value就是72,惡意程式碼編寫者故意讓這些常數72,在執行時由乘法指令產生。常量拆分就是一種逆向的操作,把本來可以直接獲取的值,透過計算來產生的一種混淆方式。如下圖:

圖11,常量拆分
本來直接可以mov esi,0x400000,但是卻拆分成兩部分而且其中新增不少無效指令
其中經過紅框中的計算可以得到esi的值為0x400000.這一步的目的是獲取pe檔案基址。很顯然惡意程式碼作者沒有考慮地址隨機化問題。
2.2.2 資料編碼
資料編碼的原理就是將常量資料動態編碼,然後在動態的解解碼,資料編碼集中體現在加密解密上。同樣在citadel這個樣本里我們發現有這樣的過程,如下圖:
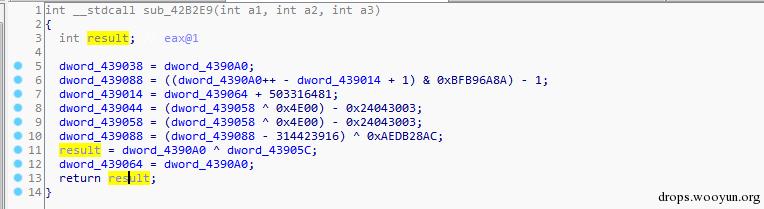
圖12,資料編碼
Result由 4390a0與43905c異或獲取,而這兩個值也是動態計算出來的。所以這樣的編碼如想靜態的獲取result會比較困難。
2.3 程式碼混淆
2.3.1 指令替換
對於指令的替換,這個大家見得比較多。就是指令的拆分,或者合併,目的是使分析人員更加難以理解,或者拖慢分析速度。
MOV Mem,Imm
CMP/TEST Reg,Mem --> CMP/TEST Reg,Imm
Jcc @xxx Jcc @xxx
MOV Reg,Imm -> LEA Reg,[Imm]
ADD Reg,Imm -> LEA Reg,[Reg+Imm]
MOV Reg,Reg2 -> LEA Reg,[Reg2]
ADD Reg,Reg2 -> LEA Reg,[Reg+Reg2]
OP Reg,Imm -> MOV Mem,Imm TEST Reg,Imm -> MOV Mem,Reg
OP Mem,Reg Jcc @xxx AND/TEST Mem,Imm
MOV Reg,Mem Jcc @xxx
這些指令的含義很簡單,這裡就不介紹了。類似的這種指令替換方式變化無窮。
2.3.2 MOV指令混淆
在去年的recon大會中《The M/o/Vfuscator-Turning 'mov' into a soul-crushing RE nightmare》議題,讓我們見識到了,程式碼混淆的另一種方式,作者演示了所有的機器指令,除過控制流指令外,都用mov指令來實現,很顯然,如果人為去理解這樣的程式碼,是很困難的,這個可以看出作者對x86指令深入的理解,讓我們大開眼界,下面我就從我的角度來說明下這個背後的原理和一些細節。先來直觀的感受下,這些程式碼指令吧:
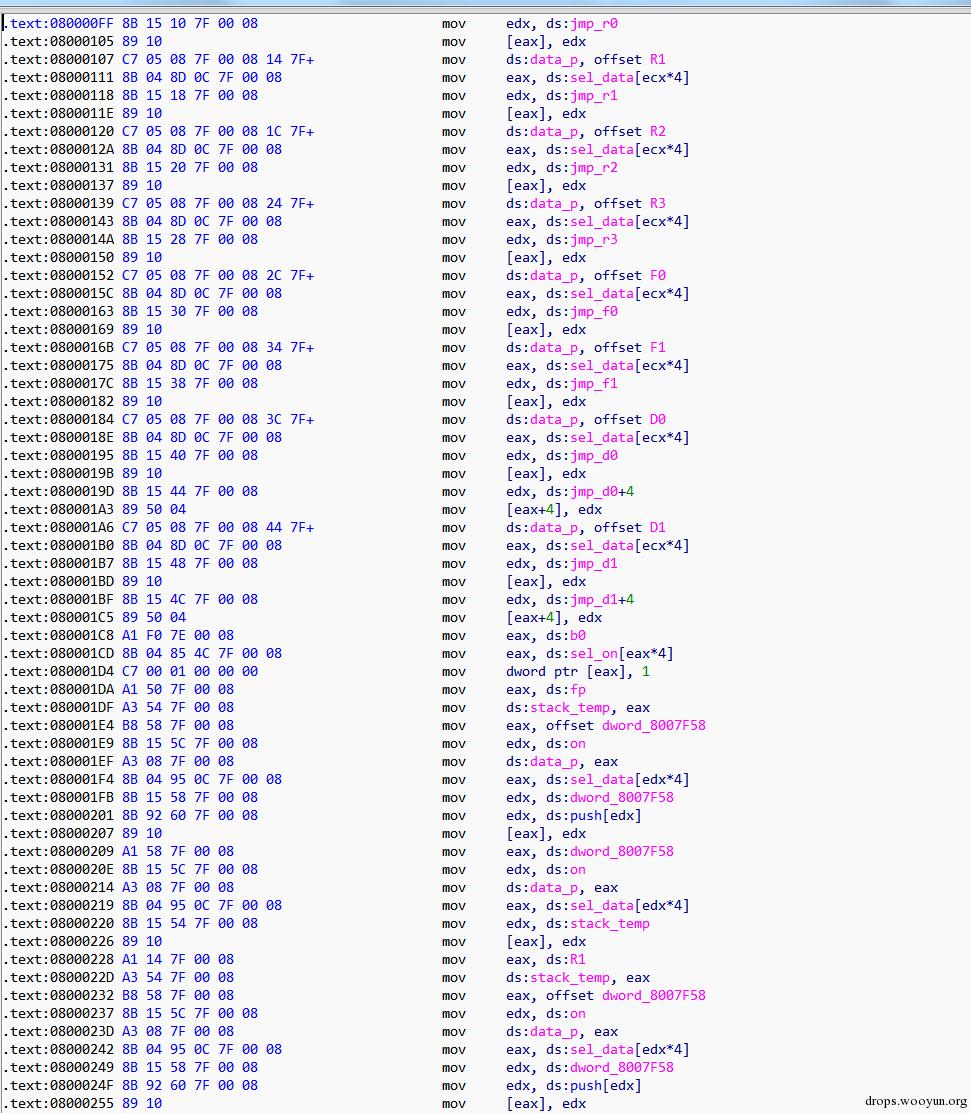
圖13,mov 混淆程式碼
原始碼是這樣子的:

圖14,原始碼
可以看出本來一個很簡單的c程式程式碼,現在混淆的面目全非。
技術原理:
Christopher Domas 的這個議題源自Stephen Dolan的一篇paper《mov is Turing-complete》
所謂圖靈完備指的就是如果一個系統的資料操作規則(比如計算機指令集,程式語言)能夠模擬任意的單磁帶圖靈機就成稱之為圖靈完備。我們主要看看Christopher Domas是如何來完成mov obfuscation的。
首先解釋一下為什麼Chirstopher Domas為什麼會選擇 mov指令。
Mov指令可以用於記憶體讀寫,同時可以將立即數載入到暫存器,並且有不少定址模式,它沒有條件分支和比較的功能,因此貌似不是很顯性圖靈完備。在有限的時間裡執行有限的數量的mov指令序列,為了圖靈完備性,除過mov指令外還得再加入跳轉指令,這樣一來就完全符合圖靈完備了。
對於mov指令來說,不能實現跳轉,程式碼的執行流就只有一種,所以需要跳轉指令來幫助實現跳轉來完成真正意義上的圖靈完備。
所以整體上說程式碼流如下:
**Start: mov … mov … mov … mov … mov … mov … jmp Start **
mov模擬其他指令虛擬碼:
case 1: // mov檢查值是否相等:
x==y?
mov [x], 0
mov [y], 1
mov R, [x]
很顯然當x==y的時候R的值就是1,否則為0。
Case2://條件分支指令
IF X == Y THEN
X=100
對於這種分支程式碼,設定一個Selector(相當於一個指標),一個data記憶體區域存放的資料是100,一個scratch 記憶體區,是存放的原始x的原始值,如果x的值與y的值相等的話就將selector的指向data區,如果不等就將selector指向scratch區域。

從上圖我們可以總結出具體的實現原理是這樣的:
#!c
int* select_x[]={&DUMMY_X , &X}
*select_x[x==y]=100
即selector就是一個包含有假的X地址(DUMMY_X)與X的真實地址的陣列,如果X等於Y則select_x[x==y]指向第二個元素,並給*X賦值等於100,否則selector_x[x==y]是DUMMY_X。
模擬程式碼:
mov eax,[X]
mov [eax],0
mov eax,[Y]
mov [eax],4
mov eax,[X]
mov eax,[Select_x+eax]
mov [eax],100 ;X=100
在這裡可以看出作者很巧妙的利用x86指令記憶體排布特性分別在X ,Y,所代表的記憶體地址放置值0,4,這剛好是DUMMY_X與X地址的偏移,這樣[Select_x+eax]就指向了DUMMY_X或者X,最後賦值X或者DUMM_X,實現了上面的整個的過程。這裡可以看出程式碼比正常的彙編指令膨脹了不少。正常彙編指令最多4條就夠了,這裡用到了7條,很顯然現在程式碼不是那麼容易理解了。
一些模擬指令序列:
兩個值相等
%macro eq 3
mov eax, 0
mov al, [%2]
mov byte [e+eax], 0
mov byte [e+%3], 4
mov al, [e+eax]
mov [%1], al
%end macro
其中%2 %3 為要比較的兩個值,%1為比較的結果。
兩個值不等
%macro neq 3
mov eax, 0
mov al, [%2]
mov byte [e+eax], 4
mov byte [e+%3], 0
mov al, [e+eax]
mov [%1], al
%endmacro
neq與eq的差別就在第三條與第四條指令中,賦值的區別,
建立一個選擇器
; create selector
%macro c_s 1
%1: dd 0
d_%1: dd 0
s_%1: dd d_%1, %1
%endmacro
即一個4位元組的記憶體塊,包含兩個元素 %1 ,d_%1
關於迴圈與分支
Extend the if/else idea
On each branch
If the branch is taken
Store the target address
Turn execution “off”
If the branch is not taken
Leave execution “on”
解釋下上面的意思,分支程式碼被觸發的時候,儲存目標地址程式碼,置位該執行為關閉狀態,
如果分支程式碼沒有被執行,置位離開執行塊狀態。
On each operation
If execution is on
Run the operation on real data
If execution is off
Is current address the stored branch target?
Yes?
Turn execution “on”
Run operation on real data
No?
Leave execution “off”
Run on dummy data
如果執行塊開啟,執行真實程式碼,如果執行塊關閉,先判斷當前地址是否儲存了目標指令程式碼,如果是,將執行體置位為on,執行程式碼。如果不是,置離開執行體為off,執行dummy data中的程式碼。關於mov 混淆的更多的細節,可以檢視去年recon的議題與相關的影片。
2.3.3 編譯器混淆
利用編譯器進行混淆的樣本不是很常見,但是這類的樣本將會成為一個新的發展方向。 編譯器程式碼混淆就是在編譯器生成二進位制程式碼的時候插入混淆程式碼。下面簡單的介紹下一個例項。
2.3.3.1 tcc編譯器的混淆
原理就是在tcc生成機器碼的時候加入混淆函式。作者patch了tcc編譯器加入了一些混淆的指令:
插入混淆程式碼序列的過程
#!c
for (i=0; i<t; i++)
{ int q;
q=rand_reg (0, 4);
switch (q)
{
case 0: // add
rrr=genrand(); curval=curval+rrr;
o(0x81); oad(0xc0 | (0 << 3) | r, rrr); // add
break;
case 1: // sub
rrr=genrand(); curval=curval-rrr;
o(0x81); oad(0xc0 | (5 << 3) | r, rrr); // add
break;
case 2: // shl
rrr=genrand()&0x7; curval=curval<<rrr;
o(0xc1); /* shl/shr/sar $xxx, r */
o(0xe0 | r);
g(rrr);
break;
case 3: // shr
rrr=genrand()&0x7; curval=curval>>rrr;
o(0xc1); /* shl/shr/sar $xxx, r */
o(0xe8 | r);
g(rrr);
break;
case 4: // xor
rrr=genrand(); curval=curval^rrr;
o(0x81); oad(0xc0 | (6 << 3) | r, rrr); // xor
break;
};
首先隨機選取了暫存器,Genrand()是產生隨機數的函式,o()是產生opcode的函式,oad()是產生指令其餘部分的函式。每次隨機選取一個暫存器,然後對選取的暫存器產生對應的混淆指令。

對於call指令會產生這樣的程式碼:
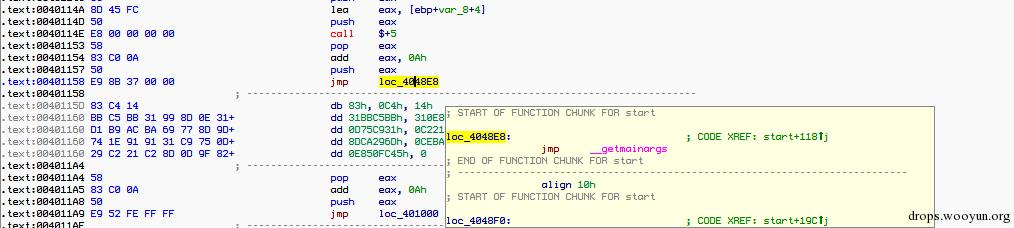
對應的程式碼如下:
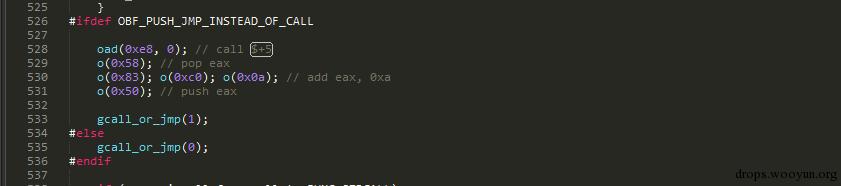
就是在原始的call 之前加入程式碼,最後jmp到原來的流程,然後返回繼續執行下面的流程。還有很多的細節這裡就不一一介紹了,如果感興趣可以自己研究下原始碼。
0x03 如何反混淆
從上面可以看出混淆技術的種類繁多,但是也是有層次的,對於海量樣本的處理,反混淆流程是必須的,也是一個很重要的流程,怎麼做,如何做,這將直接影響到對惡意樣本的分類,資料提煉效果上,所以這是一個很有意義的話題,關於如何反混淆,將會在後續的文章談到。
參考文獻:
- https://en.wikipedia.org/wiki/Turing_completeness
- https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/turing-machine/one.html
- https://en.wikipedia.org/wiki/Turing_machine
- https://recon.cx/2015/slides/recon2015-14-christopher-domas-The-movfuscator.pdf
- http://conus.info/stuff/tcc-obfuscate/
相關文章
- ios加固,ios程式碼混淆,ios程式碼混淆工具, iOS原始碼混淆使用說明詳解2020-06-11iOS原始碼
- AI繪畫漫談——從AI網頁生成說起2024-10-31AI網頁
- Android程式碼混淆&元件化混淆方案2020-11-20Android元件化
- Flutter 程式碼混淆 混淆Dart程式碼2021-08-19FlutterDart
- Android混淆2018-06-13Android
- 漫談 SLAM 技術(上)2019-03-04SLAM
- 【程式碼混淆】react-native 程式碼混淆2023-12-26React
- 逆向進階,利用 AST 技術還原 JavaScript 混淆程式碼2022-04-27ASTJavaScript
- Python 程式碼混淆和加密技術2018-11-15Python加密
- JS解混淆2024-04-12JS
- android 混淆規則作用,Android程式碼混淆詳解2024-02-27Android
- Python程式碼混淆工具,Python原始碼保密、加密、混淆2024-02-05Python原始碼加密
- SpringBoot程式碼混淆與反混淆加密工具詳解2023-12-20Spring Boot加密
- Java 混淆那些事(六):Android 混淆的那些瑣事2019-03-24JavaAndroid
- 程式碼混淆與反混淆學習-第二彈2023-04-09
- 保護C#程式碼的藝術:深入淺出程式碼混淆技術2024-04-12C#
- JavaScript混淆安全加固2019-06-09JavaScript
- js程式碼混淆2024-11-19JS
- 深度解析Android APP加固中的必備手段——程式碼混淆技術2024-01-24AndroidAPP
- HTML程式碼混淆技術:原理、應用和實現方法詳解2023-12-05HTML
- Android修煉之混淆2018-11-28Android
- Android混淆(Proguard)詳解2018-05-01Android
- Vue混淆與還原2023-12-06Vue
- 陣列方法不混淆2019-07-18陣列
- 【JS 逆向百例】反混淆入門,某鵬教育 JS 混淆還原2021-12-02JS
- 【教程】深入探究 JS程式碼混淆與加密技術2024-03-22JS加密
- 從Google Spanner漫談分散式儲存與資料庫技術XA2022-03-21Go分散式資料庫
- Android 混淆簡單入門2019-02-27Android
- Android 程式碼混淆規則2018-07-17Android
- iOS 初探程式碼混淆(OC)2018-05-24iOS
- 原始碼部分加密混淆方案2018-06-14原始碼加密
- 你對@synthesize混淆了嗎?2018-09-05
- Python 程式碼混淆工具概述2024-04-01Python
- 字串混淆常見問題2024-03-24字串
- powershell程式碼混淆繞過2020-06-21
- estools 輔助反混淆 Javascript2020-08-19JavaScript
- JS常見加密混淆方式2020-10-12JS加密
- 使用proguard混淆springboot程式碼2019-03-04Spring Boot