手把手教你從資料預處理開始體驗圖資料庫

本文首發於 Nebula 公眾號:[手把手教你從資料預處理開始體驗圖資料庫](https://mp.weixin.qq.com/s/bn8MZnXt3_nuwKVGYaxlXg),由社群使用者 Jiayi98 供稿,分享了她離線部署 Nebula Graph、預處理 LDBC 資料集的經驗,是個對新手極度友好的手把手教你學 Nebula 分享。
這不是一個標準的壓力測試,而是透過一個小規模的測試幫助我熟悉 Nebula 的部署,資料匯入工具,查詢語言,Java API,資料遷移,以及叢集效能的一個簡單瞭解。
## 準備
所有的準備都需要找個有網的環境
1. docker RPM 包 []()
2. docker-compose tar 包 []()
3. 提前下載映象 [https://hub.docker.com/search?q=vesoft&type=image](https://hub.docker.com/search?q=vesoft&type=image),將 metad、graphd、storaged、console、studio、http-gateway、http-client、nginx、importer(用 `docker save xxx` 命令將拉好的映象匯出成 tar 包)
4. 配置檔案 []()
5. nebula-studio GitHub 上下載 zip 包 []()
## 安裝
1. 安裝 Docker:
```
$ rpm -ivh <rpm包>
$ systemctl start docker --啟動
$ systemctl status docker --檢視狀態
```
2. 安裝 docker-compose
```
$ mv docker-compose /usr/local/bin/ --把docker-compose檔案移動到/usr/local/bin
$ chmod a+x /usr/local/bin/docker-compose --改許可權
$ docker-compose -version
```
3. 匯入映象
```
$ docker load <映象tar包>
$ docker image ls
```
4. 在機器 manager machine 上執行以下命令初始化 Docker Swarm 叢集:
```
$ sudo docker swarm init --advertise-addr <manager machine ip>
```
5. 根據提示在另一臺伺服器上以 `worker` 的身份 `join swarm`
```
$ docker node ls
```
* 新增 `worker node` 如果出現以下報錯:
`Error response from daemon: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 172.16.9.129:2377: connect: no route to host"`
一般是防火牆未關閉導致的(用以下方式關閉防火牆)。
```
$ systemctl status firewalld.service
$ systemctl disable firewalld.service
```
5. 在 manager 節點上改寫 `docker-stack.yml`,並建立 `nebula.env`
```
-- nebula.env
TZ=UTC
USER=root
```
* Yaml file 裡的 hostname 多臺機器不可同名,啟動時的錯誤多半是因為配置檔案寫得有問題,v1 升級 v2 也只需要把配置檔案裡的映象換一下就可以了。
6. 在 manager 節點上動 nebula 叢集
```
$ docker stack deploy <stack name> -c docker-stack.yml
```
這裡附帶一些我 Debug / 檢查方法:
```
$ docker service ls --檢視服務狀態
$ docker service ps <NAME/ID> --檢視某一個具體的狀態
$ docker stack ps --no-trunc <stack name> --檢視 stack 裡所有的程式
```
7. 安裝 Studio
程式碼資料夾裡是 v1,有一個 v2 的資料夾裡是 v2
```
$ cd nebula-web-docker
```
或
```
$ cd nebula-web-docker/v2
$ docker-compose up -d -- 構建並啟動 Studio 服務;
```
其中,`-d` 表示在後臺執行服務容器
啟動成功後,在瀏覽器位址列輸入:` address:7001`
## 測試
我用的 LDBC。
#### 準備
1. 獲取原始碼 [](),scale factor 1-1000 用 stable branch。
2. 下載 hadoop-3.2.1.tar.gz: []()
3. LDBC 資料預處理
#### LDBC 資料預處理
**這裡需要說明一下,要注意你用的 nebula 版本是否支援 `“|”` 作為分隔符**。
ldbc 的所有 vertex 和 edge 的 ID / index 都有問題,需要處理一下使得所有 vertex 的 ID 變為 unique key。
我的做法是每個 vertex 我都給一個字首,比如 person,原始 ID 為 933,變為 p933。(為了試用一下我自己搭的 CDH 我用 Spark 做的資料預處理,處理過的資料放在 HDFS 以便後面用 nebula-exchange 匯入)
#### 硬體資源

備註:Nebula 不推薦使用 HDD,但我也沒有 SSD, 最後測試結果證明 HDD 真的很弱。
#### 服務分佈
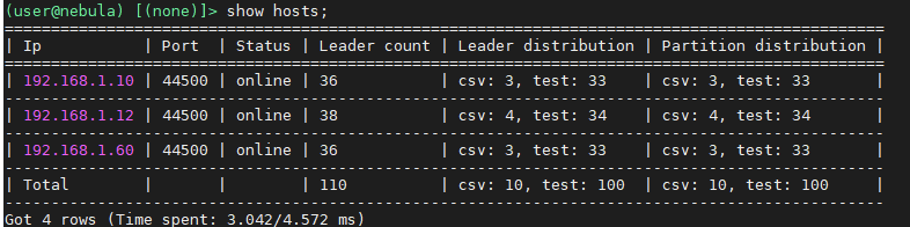
3 節點,服務分佈如下
- 192.168.1.10 meta,storage
- 192.168.1.12 graph,meta,storage
- 192.168.1.60 graph,meta,storage
2 圖空間:
1. csv:10 個 partition
1. 原始資料約 42 M
2. 7 千多個點,40 萬條邊
2. test:100 個 partition
1. 原始資料約 73 G
2. 1.1 億多個點,28.2 億多條邊(Edge: 1,101,535,334;Vertex: 282,612,309)
匯入 Nebula 之後,佔用儲存空間共約 76 G,其中 wal 檔案佔 2.2 G 左右。
沒有做匯入的測試,一部分用了 Nebula-Importer 匯入,一部分用了 Exchange 匯入:
## 開始測試
測試方法:
1. 選取 1000 個 vertex,進行 1000 次查詢的平均值

* 三度超時是將 `timeout` 引數調高至 120 秒後的結果,後來在終端執行了一次三度發現要三百多秒。
最後,希望這份文件對和我一樣的小白們有幫助,也感謝一直以來社群和官方的答疑解惑。
Nebula 真的讓使用者感到真的非常 supportive,在學習使用 Nebula 的過程中我也收穫了很多~
## 進一步交流
交流圖資料庫技術?加入 Nebula 交流群請先[填寫下你的 Nebulae 名片](https://wj.qq.com/s2/8321168/8e2f/),Nebula 小助手會拉你進群~~
要不要看看【美團的圖資料庫系統】、【微眾銀行的資料治理方案】以及其他大廠的風控、知識圖譜實踐?**Follow Nebula 公眾號**:[NebulaGraphCommunity](https://www-cdn.nebula-graph.com.cn/nebula-blog/WeChatOffical.png) 回覆「PPT」即可習得大廠實踐技能 ^^
## 推薦閱讀
- [淺談圖資料庫](https://mp.weixin.qq.com/s/6WkYb0XSN3IP9808p3FyTQ)
- [聊聊圖資料庫和圖資料庫的小知識](https://mp.weixin.qq.com/s/T1i270J6viFDPECvj-ylxA)
- [Nebula Graph 技術總監陳恆:圖資料庫怎麼和深度學習框架進行結合?](https://mp.weixin.qq.com/s/vQoGVyhQjmekLNhv7SAD7g)
- [圖資料庫愛好者的聚會在談論什麼?](https://mp.weixin.qq.com/s/5OyjDVEo6a0oUpdnwT8iIg)
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/69952037/viewspace-2769263/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 資料分析--資料預處理
- 資料預處理-資料清理
- 資料預處理
- 前端資料校驗從建模開始前端
- 資料預處理-資料歸約
- GO web 開發 實戰三,資料庫預處理GoWeb資料庫
- 資料預處理 demo
- 手把手教你AspNetCore WebApi:資料驗證NetCoreWebAPI
- Python資料處理從零開始----第三章(pandas)③資料標準化Python
- 資料預處理-資料整合與資料變換
- 資料清洗與預處理:使用 Python Pandas 庫Python
- nlp 中文資料預處理
- TANet資料預處理流程
- MongoDB資料庫手把手教你來學習MongoDB資料庫
- 資料預處理- 資料清理 資料整合 資料變換 資料規約
- 保證資料庫質量安全:從0開始的資料庫測試資料庫
- Python資料處理從零開始----第四章(視覺化)(5)(韋恩圖)Python視覺化
- 處理圖片流資料
- 資料預處理方法彙總
- 資料預處理和特徵工程特徵工程
- 深度學習--資料預處理深度學習
- 從頭開始,建立Neo4j圖資料庫,詳細版資料庫
- 手把手教你用ManagedSQLiteOpenHelper實現資料庫SQLite資料庫
- 機器學習:探索資料和資料預處理機器學習
- sqlserver01(使用篇從新建資料庫開始)SQLServer資料庫
- Python資料處理(二):處理 Excel 資料PythonExcel
- 開源軟體在地圖資料處理中的應用地圖
- 特徵工程之資料預處理(下)特徵工程
- 資料預處理之 pandas 讀表
- 人工智慧 (01) 資料預處理人工智慧
- 深度學習——資料預處理篇深度學習
- sklearn中常用資料預處理方法
- 資料預處理利器 Amazon Glue DataBrew
- NUS-WIDE資料集預處理IDE
- 使用圖資料庫 Nebula Graph 資料匯入快速體驗知識圖譜 OwnThink資料庫
- 【從零開始學習 MySql 資料庫】(2) 函式MySql資料庫函式
- 資料處理
- 詳解AI開發中的資料預處理(清洗)AI