AI安全對抗中,只用一招輕鬆騙過五種神經網路
影像識別作為人工智慧最成熟的應用領域,已經大規模落地並服務於人們的日常生活。但在大規模商業化的同時,也面臨更多方面的威脅。對抗樣本透過對影像做微小的改動,在使用者無感知的情況下,會導致AI系統被入侵、錯誤命令被執行。欺騙AI系統做出錯誤的決斷,將會給社會造成重大的損失。透過研究如何欺騙AI系統,對現有的薄弱點進行修補,使得AI系統更健壯。
本文提供了一個強勁的攻擊方案,該方案可以對ResNeXt50白盒模型、人工加固的灰盒模型、AutoDL模型均有顯著的效果,並在飛槳AI安全對抗賽中取得較好成績。在該比賽中,選手需要儘量小的擾動下騙過更多的模型,才能拿到更好的得分,一起來看看他是如何實現的吧。
01.方案部分結果展示



02.解題思路
相比初賽,決賽的難點在於多了一個人工加固的模型(灰盒),黑盒模型增加為三個,包括由AutoDL技術訓練的模型,因此需要針對人工加固模型訓練自己加固的模型。針對黑盒模型,我主要整合多樣化的模型來逼近;針對AutoDL技術訓練的模型,我主要整合AutoDL搜尋出的網路結構來遷移攻擊。
此外相比初賽,我在方案中新增了多樣的越過區域性最優的策略和限定變動畫素點的限制,同時對生成的圖片進行了小擾動截斷,保證在提升遷移效能的同時降低MSE。
03.攻擊方法
攻擊所用演算法主體為MomentumIteratorAttack,程式碼實現參照了advbox。在此基礎之上,嘗試了不同的目標函式,整合了不同的模型,新增了多樣的越過區域性最優的策略。
3.1目標函式
損失函式1:

其中,m為模型個數,
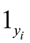 為標籤y的獨熱編碼,
為第i個模型的引數。此損失函式引用於[1]
為標籤y的獨熱編碼,
為第i個模型的引數。此損失函式引用於[1]
程式碼如下:
loss_logp = -1*fluid.layers.log(1-fluid.layers.matmul(out1,one_hot_label[0],transpose_y=True))\ -1*fluid.layers.log(1-fluid.layers.matmul(out2,one_hot_label[0],transpose_y=True))\ -1*fluid.layers.log(1-fluid.layers.matmul(out3,one_hot_label2[0],transpose_y=True))\ -1*fluid.layers.log(1-fluid.layers.matmul(out4,one_hot_label2[0],transpose_y=True))\ -1*fluid.layers.log(1-fluid.layers.matmul(out5,one_hot_label2[0],transpose_y=True))\ -1*fluid.layers.log(1-fluid.layers.matmul(out6,one_hot_label2[0],transpose_y=True))\ -1*fluid.layers.log(1-fluid.layers.matmul(out8,one_hot_label2[0],transpose_y=True))\ -1*fluid.layers.log(1-fluid.layers.matmul(out9,one_hot_label2[0],transpose_y=True))
損失函式2:

其中,N為類別數量,M為模型數量,為當輸入為X時,模型j判定類別i的機率。
程式碼如下:
out_total1 = fluid.layers.softmax(out_logits1[0]+out_logits2[0]) out_total2 = fluid.layers.softmax(out_logits3[0]+out_logits4[0]+out_logits5[0]+out_logits6[0]+out_logits7[0]+out_logits8[0]+out_logits9[0]) loss2 = fluid.layers.matmul(ze, fluid.layers.cross_entropy(input=out_total1, labellabel=label[0]))\ + fluid.layers.matmul(ze, fluid.layers.cross_entropy(input=out_total2, label=label2[0]))
損失函式3:

符號含義同損失函式2,不再贅述。
程式碼如下:
ze = fluid.layers.fill_constant(shape=[1], value=-1, dtype='float32') loss = 1.2*fluid.layers.matmul(ze, fluid.layers.cross_entropy(input=out1, labellabel=label[0]))\ + 0.2*fluid.layers.matmul(ze, fluid.layers.cross_entropy(input=out2, labellabel=label[0]))\ + fluid.layers.matmul(ze, fluid.layers.cross_entropy(input=out3, label=label2[0]))\ + fluid.layers.matmul(ze, fluid.layers.cross_entropy(input=out4, label=label2[0]))\ + fluid.layers.matmul(ze, fluid.layers.cross_entropy(input=out5, label=label2[0]))\ + fluid.layers.matmul(ze, fluid.layers.cross_entropy(input=out6, label=label2[0]))\ + fluid.layers.matmul(ze, fluid.layers.cross_entropy(input=out7, label=label2[0]))\ + fluid.layers.matmul(ze, fluid.layers.cross_entropy(input=out8, label=label2[0]))\ + fluid.layers.matmul(ze, fluid.layers.cross_entropy(input=out9, label=label2[0]))
經過實測,發現三者效果接近,損失函式3效果最好。損失函式1的特點是程式執行快,猜測可能是求梯度簡單。使用損失函式2時,攻擊成功後的分類會接近一致。
3.2模型整合
整合模型選取思路為多元,儘可能多的不同模型,才可能逼近賽題背後的黑盒模型,所用模型總體描述如圖3-1所示。

圖3-1 模型整合細節
- 橙色框中mnasnet1_0,nas_mobile_net為特意選取逼近黑盒AutoDL技術訓練的黑盒模型,人工加固ResNeXt50_32x4d模型訓練細節接下來會詳細闡述。
- 橙色和藍色框中模型均採用pytorch進行遷移訓練,訓練集測試集為原始Stanford Dogs資料集劃分,迭代次數均為25,學習率均為0.001。
- 虛線框中為效果最好的9個模型的組合。
3.3灰盒模型攻擊思路
決賽中的灰盒模型為人工加固的模型,結構為ResNeXt50。為了攻擊黑盒模型,我在本地訓練了一個加固模型,作為灰盒模型的逼近。訓練加固模型涉及到訓練集的選取和訓練方法的選取,訓練集的構成主要包含如下兩部分:
- 第一部分採用不同的方法攻擊初賽的白盒模型(此白盒模型與灰盒模型具有相同的網路結構),將生成的n個樣本集作為訓練集的一部分,設計思路如圖3-2所示(T代表對抗樣本能被真實灰盒模型正確分類(猜測);F代表對抗樣本不能被真實灰盒模型正確分類(猜測))。由於不同的攻擊方法生成的對抗樣本在真實的灰盒模型表現上會有差異,有些圖片依然能被灰盒模型正確識別。將n個樣本集集合,就可以構建出完全將灰盒攻擊成功的圖片集。
圖3-2 對抗訓練部分樣本集構建思路
- 第二部分是從Stanford Dogs資料集中隨機選取的8000張圖片和原始的121張圖片,這些圖片的選取是為了保持模型的泛化能力。
對抗模型的訓練方法與一般模型訓練無異。為了探索更優的對抗模型,我們進行了幾組不同訓練集的對比(其他引數固定),如下表所示。

其中,86.45等分數是決賽評測分數,經過實驗對比第一組實驗設定效果最好。
3.4 越過山丘
下面主要介紹為了解決陷入區域性最優採取的一系列策略。
3.4.1 圖片粒度梯度反向
此方法受啟發於[2],論文中採取雙路尋優,一路採用常規方法梯度上升,如圖3-3中綠線所示。另一路先採取梯度下降到達這一分類區域性最優再進行梯度上升,以期找到更快的上升路徑,如圖3-3中藍線所示。我在實現過程中對其進行簡化,僅在迭代的第一步進行梯度下降。

圖3-3 梯度策略示意圖(圖片來自論文[2])
核心程式碼如下:
if i==0:#第一次迭代梯度反向 advadv=adv+epsilon*norm_m_m else: advadv=adv-epsilon*norm_m_m
3.4.2 畫素粒度梯度反向
此方法承接於3.4.1,可將3.4.1視為整個圖片粒度的梯度反向。同樣是為了越過區域性最優,採用3.4.2方法,隨機選取梯度中5%進行取反,可視為畫素粒度的梯度反向,反轉比例為一超引數。同樣為了在迭代後期趨於穩定,反向的梯度的比例會隨著迭代次數增加而減少。比例為一需要調節的超引數。
核心程式碼如下:
if i<50: #前50步,2%的梯度反響,隨著i遞減 試試5% dir_mask = np.random.rand(3,224,224) dir_maskdir_mask = dir_mask>(0.15-i/900) dir_mask[dir_mask==0] = -1 norm_m_m = np.multiply(norm_m_m,dir_mask)
3.4.3 每步迭代前,對原始圖片新增高斯噪聲
此方法受啟發於[6],論文作者認為攻擊模型的梯度具有噪聲,損害了遷移能力。論文作者用一組原始圖片加噪聲後的梯度的平均代替原來的梯度,效果得到提升,形式化表述如下:
而我與論文作者理解不同,新增噪聲意在增加梯度的噪聲,以越過區域性最優,再者多次計算梯度非常耗時,因此我選用了只加一次噪聲,均值為0,方差為超引數,形式化表述如下:

同時,為在迭代後期趨於穩定,在新增噪聲時,噪聲的方差會隨著迭代次數的增加而減小。
核心程式碼如下:
if i<50: adv_noise = (adv+np.random.normal(loc=0.0, scale=0.8+epsilon/90,size = (3,224,224))).astype('float32') else: adv_noise = (adv+np.random.normal(loc=0.0, scale=0.2,size = (3,224,224))).astype('float32')
3.4.4 將圖片變動的畫素點限定在梯度最大的5%
該方法受啟發於[3], 隨機在影像中選擇max_pixels個點。而我採用的方法是計算所有畫素的梯度,選取梯度最大的5%進行變動,此舉可以有效降低MSE。
3.4.5 三通道梯度平均
該方法受啟發於[3],文中,作者隨機在影像中選擇max_pixels個點 在多個通道中同時進行修改。因此我嘗試了兩種方法,一是隻計算R或G或B通道的梯度,三個通道減去相同的梯度。二是將三通道的梯度進行平均。從結果來看,後者更有效,提分明顯。
3.4.6 攻擊後進行目標攻擊
此方法受啟發於[2],作者在成功越過分界線後進行消除無用噪聲操作,作者認為此舉可以加強對抗樣本的遷移能力。
我的做法與此不同,我認為不僅要越過邊界,還要走向這個錯誤分類的低谷。此舉依據的假設是:儘管不同模型的分界線存在差異,模型學到的特徵應是相似的。思路如圖3-4中紅色箭頭所示,帶有圓圈的數字表示迭代步數。
因此在成功攻擊之後,我又新增了兩步定向攻擊,目標為攻擊成功時被錯分的類別。在整合攻擊時,目標為被錯分類別的眾數。

圖3-4 目標攻擊示意圖(修改自論文[2])
核心程式碼如下:
for i in range(2):#迭代兩次進行目標攻擊 adv_noise = (adv+np.random.normal(loc=0.0, scale=0.1,size = (3,224,224))).astype('float32') target_label=np.array([t_label]).astype('int64') target_label=np.expand_dims(target_label, axis=0) target_label2=np.array([origdict[t_label]]).astype('int64') target_label2=np.expand_dims(target_label2, axis=0) g,resul1,resul2,resul3,resul4,resul5,resul6,resul7,resul8,resul9 = exe.run(adv_program, fetch_list=[gradients,out1,out2,out3,out4,out5,out6,out7,out8,out9], feed={'label2':target_label2,'adv_image':adv_noise,'label': target_label } ) g = (g[0][0]+g[0][1]+g[0][2])/3 #三通道梯度平均 velocity = g / (np.linalg.norm(g.flatten(),ord=1) + 1e-10) momentum = decay_factor * momentum + velocity norm_m = momentum / (np.linalg.norm(momentum.flatten(),ord=2) + 1e-10) _max = np.max(abs(norm_m)) tmp = np.percentile(abs(norm_m), [25, 99.45, 99.5])#將圖片變動的畫素點限定在0.5% thres = tmp[2] mask = abs(norm_m)>thres norm_m_m = np.multiply(norm_m,mask) advadv=adv+epsilon*norm_m_m #實施linf約束 adv=linf_img_tenosr(img,adv,epsilon)
3.5 臨門一腳
然而這不夠,作為一個競賽,人人都虎視眈眈盯著獎金的時候還需要不斷的提升,因此還需要臨門一腳,一種後處理方法。
小擾動截斷:
使用上述方法後,我的結果在95-96分之間波動,為進一步提升成績,我選用最高分96.53分圖片進行後處理。後處理方法為:將攻擊後的圖片與原圖片進行對比,對一定閾值以下的擾動進行截斷。經過不斷上探閾值,發現閾值為17(圖片的畫素範圍為0-255)的時候效果最好。此方法提分0.3左右。
核心程式碼如下:
org_img = tensor2img(img) adv_img = tensor2img(adv) #17/256 以下的擾動全部截斷 diff = abs(org_img-adv_img)<drop_thres #<17的為1 diff_max = abs(org_img-adv_img)>=drop_thres #>=17的為1 #<17的保留org_img tmp1 = np.multiply(org_img,diff) #>17的保留adv_img tmp2 = np.multiply(adv_img,diff_max) final_img = tmp1+tmp2
04.嘗試過的方法
本小節介紹在比賽過程中嘗試過但沒效果過或者效果不明顯的方法。
4.1 中間層攻擊
依據論文[4]中所述,我用飛槳復現了文中方法,採用模型為ResNeXt50_32x4d,引數為初賽提供白盒模型引數,處理的中間層為res5a,學習率0.01,迭代次數為5次,損失函式為ILA。

圖4-1 沒有經過後處理生成的對抗樣本與原樣本對比圖
圖4-2 經過後處理的生成的對抗樣本與原樣本對比圖
圖4-2中Pos_Adversarial Image為圖4-1中Adversarial Image圖片使用中間層攻擊生成的圖片,使用該後處理方法後確如論文中所說圖片更平滑了,但是遷移效能卻下降了,因此棄用。
4.2 標籤平滑
效果下降。
4.3 推後原始類別排名
以6分類問題為例說明推後原始類別排名想法,如圖4-3所示。

圖4-3 推後類別排名思路示意圖
假設攻擊前某張圖片機率分佈如圖4-3第一行所示,屬於第一類的機率最高。一旦攻擊成功就停止的情況下,如圖4-3第二行所示,屬於第一類的機率下降為0.2,模型將原圖誤分類為第二類。
但是第一類的類別排序仍然靠前,在其他不同分界線模型下,很可能仍然能夠正確分類(猜測)。因此將終止條件改進,不但要能夠攻擊成功,還要原始類別的排序靠後,如圖4-3第三行,原始第一類的類別機率降至0.1,排序降至第四,也許會提升遷移效能。
在實驗中,這種做法效果不是很明顯。與此想法類似,我還嘗試了定向攻擊為原始分類機率最低的類別,同樣效果不明顯。
05.寫在賽後
1. 以上就是本人在AI安全對抗賽取得第二名的全部方案,完成執行程式碼可以訪問AI Studio專案:
2. 決賽賽程中我霸榜半個月有餘,絞盡腦汁嘗試各種攻擊方法,不斷閱讀論文,不斷嘗試效果,並且照貓畫虎快速入門了飛槳,收穫很多。
3. 致讀者,這是一個非常好的入門對抗樣本的機會,細嚼baseline和我的方案將讓你入門多種這個領域的演算法。
4. 感謝AI Studio讓我用到了v100,基本不用擔心視訊記憶體不夠用,我自己的桌上型電腦裝的gtx 1050連n年前的vgg都跑不動。
5. 一點腦洞:受啟發於[5],為人臉新增一個眼睛可以達到錯分目的,類似的給狗新增一幅眼鏡。


圖5.1 人臉新增眼鏡示意圖(擷取自[5])

圖5.2 為狗新增眼鏡示意圖(左圖為原始圖片,右圖為新增眼鏡後的圖片)
【編輯推薦】
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/69946223/viewspace-2696728/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 知物由學 | 未來安全隱患:AI的軟肋——故意欺騙神經網路AI神經網路
- IJCAI 2019 提前看 | 神經網路後門攻擊、對抗攻擊AI神經網路
- KDD 2018最佳論文解讀 | 圖神經網路對抗攻擊神經網路
- 第五週:迴圈神經網路神經網路
- AI之(神經網路+深度學習)AI神經網路深度學習
- 【深度學習篇】--神經網路中的卷積神經網路深度學習神經網路卷積
- python對BP神經網路實現Python神經網路
- 神經網路:numpy實現神經網路框架神經網路框架
- AI和ML如何幫助對抗網路攻擊?AI
- 神經網路神經網路
- Ian Goodfellow等人提出對抗重程式設計,讓神經網路執行其他任務Go程式設計神經網路
- 輕量級神經網路:ShuffleNetV2解讀神經網路
- 輕量級卷積神經網路的設計卷積神經網路
- 一個故事看懂AI神經網路工作原理AI神經網路
- 4種除錯深度神經網路的方法除錯神經網路
- MnasNet:經典輕量級神經網路搜尋方法 | CVPR 2019神經網路
- 網路對抗技術——網路嗅探與欺騙(第一二部分)非平臺
- SysML 2019提前看:神經網路安全性神經網路
- 輕量級卷積神經網路的設計技巧卷積神經網路
- 從MobileNet看輕量級神經網路的發展神經網路
- (四)卷積神經網路 -- 8 網路中的網路(NiN)卷積神經網路
- 神經網路中間層輸出神經網路
- LSTM神經網路神經網路
- 8、神經網路神經網路
- 使用NumPy演示實現神經網路過程神經網路
- 使用PyTorch演示實現神經網路過程PyTorch神經網路
- 聊聊從腦神經到神經網路神經網路
- 圖神經網路GNN 庫,液體神經網路LNN/LFM神經網路GNN
- AI神經網路可復原古希臘文字AI神經網路
- 介紹一種有趣的競爭神經網路!神經網路
- 卷積神經網路四種卷積型別卷積神經網路型別
- 幾種型別神經網路學習筆記型別神經網路筆記
- 網路安全測試---ARP欺騙
- 【機器學習】之第五章——神經網路機器學習神經網路
- MFA並非100%有效 網路犯罪分子可透過這幾種方式輕鬆破壞
- 【神經網路篇】--RNN遞迴神經網路初始與詳解神經網路RNN遞迴
- 神經網路篇——從程式碼出發理解BP神經網路神經網路
- 跟Bilibili UP主們學網路安全:輕鬆掌握攻防技術