百億資料個性化推薦:彈幕工程架構演進
背景
為什麼要做個性化推薦
回顧彈幕工程建設的發展歷程,大致可以分幾個階段:
1. 基礎能力:在高併發、熱點場景下,保證彈幕服務的穩定和高可用
2. 負向治理:以管控為目標,透過刪除、自見、打薄等手段過濾低質彈幕內容
3. 正向推薦:以最佳化影片消費體驗為目標,篩選優質彈幕內容上屏展示
這三個階段的目標始終在並行推進,在1和2的基本問題完成之後,作為B站的特色功能和社群文化重要載體,彈幕業務在承接基礎功能之外也需要持續探索最佳化消費體驗的能力。這也就必須在稿件維度優選的基礎上透過使用者特徵互動獲得更大的策略空間,建設千人千面的彈幕推薦能力。
這個過程離不開工程、演算法、產品等多個團隊的傾力合作,本文會以工程團隊的視角重點介紹工程架構對推薦系統的能力支援。
第一階段:基於原架構構建推薦能力
這一階段,我們基於原有架構搭了一個最簡版的推薦能力:

傳送彈幕時,工程系統透過資料庫binlog同步給推薦系統。在展示側,由推薦系統負責計算對應影片要展示的彈幕id列表,工程系統獲取彈幕內容最終返回。這樣就實現了一個具備基礎能力的彈幕推薦系統。
1.1 遺留問題
這一階段的線上表現還有很大的提升空間。主要原因是當時的彈幕系統依賴一個彈幕池的設計,基於影片的長度確定一個影片內可展示彈幕數的上限。當彈幕池滿了,會按照時間倒序淘汰,留下最新的N條。
舉個例子,一個15分鐘長度的影片,彈幕池上限是6000條。這個設計會帶來以下的問題:
1. 可展示彈幕少
由於彈幕池上限比較小並且分佈不均勻,經常出現彈幕填不滿螢幕的情況。
2. 彈幕質量差,優質歷史彈幕無法召回
因為彈幕池整體較小,候選集有限,選出優質內容的空間較小。同時因為時間序淘汰,很多優質的彈幕內容無法沉澱下來。
3. 彈幕分佈不均勻,長影片出現空屏
舉個例子,很多長影片比如ogv,大量彈幕集中出現在開屏打卡。這部分重複內容會把整個影片的彈幕池擠掉,導致後面大段內容出現彈幕空屏。
這些問題,我們會在下一個階段著重最佳化解決。
第二階段:10倍擴大召回池
在前一個階段,我們發現了基於原有彈幕池工程基建去搭建個性化推薦的問題。我們決定重新搭建一套專門服務於個性化推薦的工程系統。整體架構如下,後面會逐步展開介紹。
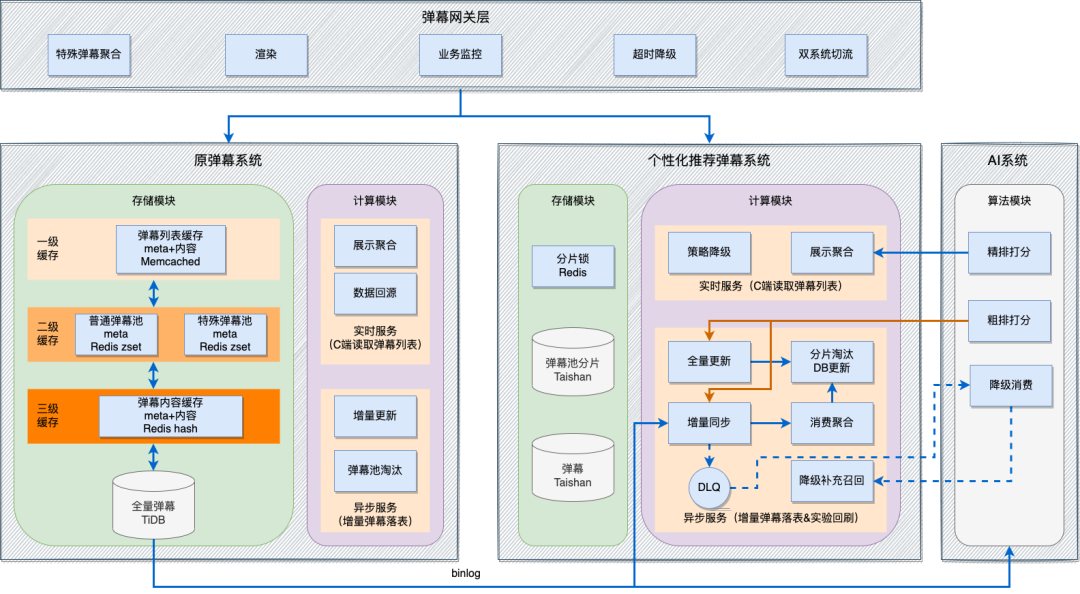
2.1 原彈幕系統
先簡單介紹一下原彈幕系統的工程實現。彈幕的兩個核心場景是,發彈幕時以彈幕維度的唯一id(彈幕id)作為主鍵落庫,同時關聯影片id;在讀彈幕時,一次性讀取一個影片6分鐘分片的全部彈幕,以影片+分片維度讀取。作為B站的核心功能,彈幕的讀寫場景都要隨時應對高併發流量以及突發的熱點場景。原有架構的儲存系統主要用了一套三級快取的結構:

第一級介面級快取直接承接C端讀流量。在第一級快取miss之後,先透過第二級快取獲取當前影片分片的彈幕id列表,然後從第三級快取獲取獲取具體的彈幕內容。在第二級快取到第三級快取之間存在彈幕數量的讀放大,若當前影片的6分鐘分片有1000條彈幕,就會產生1000倍的讀放大。若第三級快取發生miss,則會回源到底層儲存TiDB。
這套架構儲存相對複雜,因為彈幕池的儲存強依賴於Memcached和Redis zset,在容量擴充套件上,很難支援個性化推薦的業務訴求。同時影片維度時間序淘汰這一固定邏輯也很難變更。這一階段我們也思考過透過AI側的彈幕質量粗排模型打分來代替時間序淘汰,但在現有架構下,整體資料重新整理的複雜度、模型實驗能力的支援、模型版本更新的資料回刷都成為瓶頸點。
2.2 個性化推薦彈幕系統

基於上述問題,我們決定重新搭建一套彈幕的個性化推薦系統。新系統在展示側的核心鏈路不變,仍然是透過AI的精排介面獲取彈幕ID,在內部儲存系統中讀取彈幕內容,渲染並返回。新系統的核心目標是最大限度擴大推薦系統的召回池容量,同時選用基於模型的召回策略並支援回刷。在實現上,核心思路是簡化儲存並提升計算能力,後面也會主要以儲存和計算兩方面進行介紹。
儲存設計

新系統的職責邊界是隻滿足讀彈幕的個性化推薦這一個最核心場景,因而在儲存上不需要存全量彈幕,也不需要支援複雜的業務邏輯和查詢能力。基於這樣的場景特點,我們放棄了關係查詢支援,選擇了B站自研的KV資料庫泰山,將一個影片一分鐘內經過召回的彈幕存在一個key裡面。同時,單條彈幕也以彈幕id作為key進行儲存,用於處理彈幕狀態或其他後設資料的更新。因為KV資料庫不支援事務,我們自己透過redis分散式鎖保證了併發場景下的資料一致性。受益於KV資料庫強大的讀寫併發能力,在場景有讀放大的情況下,我們仍然選擇了不加快取直連資料庫的最簡單儲存結構。最終線上表現,DB完全可以承受百萬QPS的併發訪問量。
計算最佳化
原系統中,如果彈幕池存滿是基於時間序倒序淘汰。在新系統中,我們選擇影片每10秒鐘的彈幕作為最小的策略單元,可支援10秒1000條彈幕的召回空間,按照AI策略提供的粗排模型打分進行淘汰。這樣做的一個問題是,一旦粗排模型有邏輯更新,需要重新重新整理召回池。為此,我們設計了全量回刷模組。AI透過離線Hive獲取全量彈幕,打分並推送至工程側,重新計算淘汰策略並進行儲存。經過線上驗證,更新百億以上的彈幕資料大概需要2天左右。增量資料更新模組中,我們透過訊息佇列聚合的方式減輕資料庫的寫入壓力,透過redis分散式鎖保證召回池全量回刷期間增量資料也同時更新的資料一致性。
分片顆粒度選擇
在個性化推薦的系統中,多處使用到了分片的概念,用來聚合單位影片長度下的彈幕內容。我們對分片的大小做了不同的選型:
在介面層,如果一次下發的分片過長會造成頻寬浪費,比如下發10分鐘的彈幕,使用者看1分鐘就退出了。但如果分片過小,又會因為請求輪詢導致服務端QPS變大。這裡我們一開始用了6分鐘的分片大小,後來最佳化為服務端根據場景動態下發分片大小,從而節約頻寬。
同樣,在儲存上我們主要的平衡點是讀資料時的請求放大和資料更新時的顆粒度。在一個儲存單元內部,我們以每10秒作為一個策略單元進行彈幕淘汰,主要為了滿足策略目標,讓彈幕足量且均勻。

雙系統關係
線上維持兩套系統的常見問題是職責邊界和關係不清晰,導致在迭代中逐漸走向混亂。我們在設計階段就對兩套系統做了明確的職責劃分和關係定義:原彈幕系統負責整體的彈幕業務邏輯,新系統(圖中個性化推薦彈幕系統)只為個性化推薦這一個場景服務。在儲存上,原系統以TiDB儲存全量彈幕內容作為source of truth,新系統的KV資料庫作為個性化推薦的召回池,是TiDB資料庫的子集。同時,在彈幕消費這一主要場景下,原系統以線上熱備的形式維護。在個性化推薦系統出現故障時,可以自動降級使使用者側無感。
2.3 核心收益
這套架構透過召回池儲存容量的整體擴充,以及影片維度彈幕淘汰到影片每10秒維度淘汰的策略顆粒度提升,最直觀的收益是彈幕召回池的上線擴充,是原來的10倍左右。假設影片是15分鐘,彈幕上限就從整個影片6000條升級到每10秒1000條,曝光上漲30%,大大提升了消費體驗。很好理解,1w選1000和10w選1000的最終質量是完全不一樣的。
在穩定性上,我們透過策略降級、工程指標降級以及雙系統保障等手段,從上線至今沒有出現過全站事故。
當然,業務上最核心的收益是工作思路轉變:個性化推薦提供了一個工作通路,可以透過彈幕持續最佳化影片的消費體驗、社群互動氛圍和UP主滿意度。
第三階段:工程架構和推薦系統深度結合
在上一個階段,主要透過最佳化工程系統提升了個性化推薦的能力支援。經過一段時間的應用,我們發現系統中還存在一些問題,主要有:
1. 工程和AI的資料不對齊。線上經常出現,精排返回的彈幕id在工程系統的召回池中獲取不到。經過排查我們發現,核心問題是工程和AI兩邊對召回和淘汰各自實現。工程側的召回池透過上述彈幕池分片進行儲存,AI側在系統內部透過離線hdfs儲存。雖然工程側是依據AI的粗排模型進行召回並淘汰,但隨著AI的召回策略迭代,兩邊的策略一致性和資料一致性都很難有效保證。
2. AI側系統降級頻繁。核心原因主要有兩個方面,一是模型打分的儲存架構不夠合理,二是在精排階段缺少實時退場能力。AI側的模型索引透過hdfs檔案系統儲存,每次索引服務啟動時熱載入到記憶體中。顯而易見的問題是啟動效率低且不穩定,且難以支援水平擴充套件。同時在精排階段沒有做退場淘汰,遇到熱點影片時經常出現響應超時甚至OOM。
3. 實驗能力不足。當前的工程系統可以透過全量資料回刷的方式來對策略迭代做最基礎的支援。但是B站全量彈幕在百億以上,回刷一次需要2-3天完成,這顯然無法支援快速策略迭代的業務訴求。
這三個表象問題都指向了工程側和AI側結合之後的系統問題,因此我們這一階段的主要思路是以工程和AI結合的整體視角來對系統進行設計最佳化。
3.1 彈幕推薦的場景分析
首先我們重新調研一下彈幕推薦的場景特點,以及和B站的核心內容推薦場景,影片推薦的比較。在第一、二階段,工程和演算法系統的互動模式以參考影片推薦的主流方式為主:工程側在生產(傳送)內容時透過binlog訂閱同步給演算法側,在展示場景下呼叫演算法側介面獲取id列表,兩邊類似黑盒模式,各自進行迭代和最佳化。
我們比較一下兩個場景的特點和工程要求:

影片推薦是動態推理,即將隨著影片播放不斷產生的互動資料用於模型更新。彈幕推薦是靜態推理,即在彈幕傳送時就計算好全部的模型分數,不隨著線上資料進行變更。這一點上,影片推薦的推理策略複雜度更高,而彈幕推薦的場景下更適合透過批次任務的方式最佳化離線模型分數的計算和儲存。同時,內容查詢複雜度、數量級、QPS和響應時間幾個方面彈幕系統都需要滿足更高的要求。在整體流程上,都由召回、粗排、精排這3個主要步驟構成,在召回和粗排階段完成模型計算,在精排階段進行使用者特徵的實時互動,從而實現個性化。
3.2 設計目標&核心思路
根據這上述的場景特點,我們決定打破之前工程和演算法互相黑盒的常規設計模式,在整體視角下調整架構設計,在模組級別透過職能進行分工。由工程團隊負責高併發的資料讀取,以及各類實時、離線任務的更新;演算法團隊專注負責計算策略,包括模型推理和精排。這樣兩個團隊都可以發揮自己的優勢,將整個系統做好。
首先介紹一些核心概念:
彈幕物料:指彈幕的基礎資料,包括內容、狀態、點贊、舉報、屬性標記等。
彈幕索引:指彈幕的全部模型打分,包含基線模型(即粗排模型)、點贊模型、舉報模型、內容相關模型等,主要用於精排計算。目前每條彈幕大概有15-20組模型打分。
物料池:指一個影片分片(一分鐘)內所有彈幕物料的集合。
索引池:和物料池類似,一個影片分片(一分鐘)內所有彈幕索引的集合。
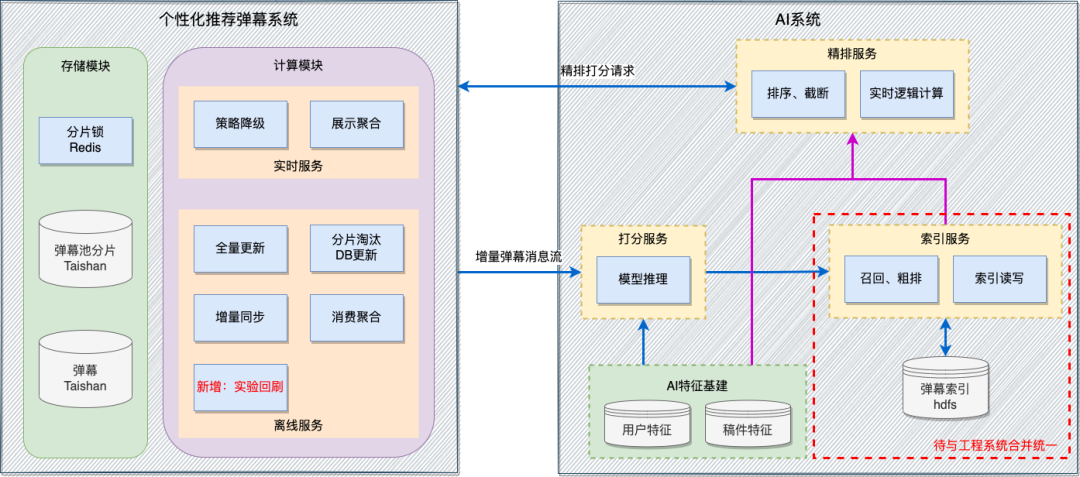
上圖將第二階段架構圖中的AI系統進行了詳細展開。AI系統主要由打分服務、索引服務、精排服務三塊構成,其中打分服務和精排服務主要負責模型和策略,索引服務負責資料召回、粗排淘汰和資料讀寫。在資料上,使用者和稿件特徵可以複用公司成熟的平臺能力,彈幕索引目前以自建hdfs+記憶體的方式儲存。再結合上述遺留問題和場景分析,核心思路是將目前的系統瓶頸點,負責資料讀寫的索引服務以及對應的資料儲存合併到工程系統中。主要設計目標如下:
1. 合併物料池、索引池:解決物料池、索引池各自進行淘汰導致的資料不對齊問題。
2. 精排最佳化:前置精排退場邏輯,解決熱點場景下OOM導致精排不可用的問題。
3. 提升實驗效率:提供小時級模型更新實驗能力,支撐策略快速迭代。
3.3 詳細設計
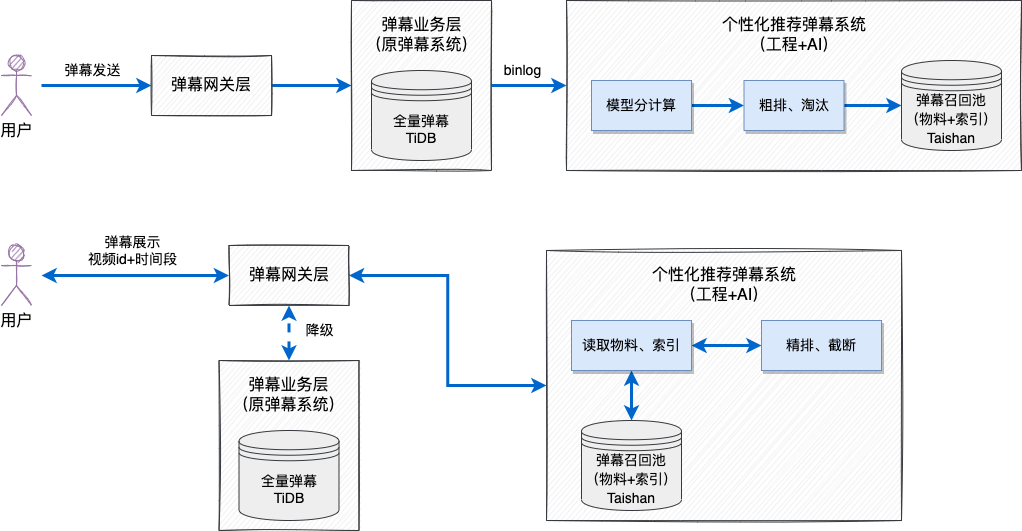
3.3.1 傳送、展示鏈路簡要流程
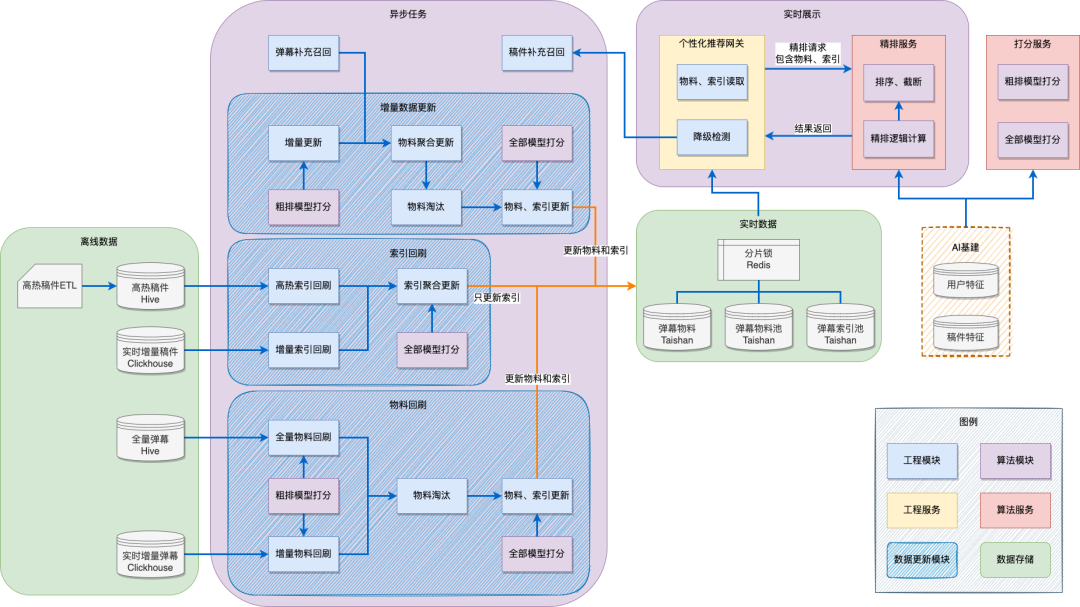
3.3.2 個性化推薦彈幕系統模組展開
3.3.3 實時資料儲存最佳化
在索引池的合併上,因為讀寫場景一致,我們選擇了和物料池同樣的kv資料庫(taishan)實現,也是在一個影片id+分鐘作為key的單位下,對應物料池的粗排分排序淘汰進行儲存。這裡物料池和索引池用不同的key來存,沒有使用在物料池的基礎上擴充套件欄位來實現,核心原因是:
1. 物料和主要業務資料庫tidb、各業務場景下的彈幕模型保持一致,避免排序索引和業務功能的耦合。
2. 可實現索引、物料獨立更新,降低索引回刷成本。
3. 分梯度降級保證可用性,一旦出現事故索引失效,可以隨機打分降級保證C端無感。
同時,物料池、索引池兩者的一致性透過redis分片鎖保證,它的顆粒度是影片+分鐘,和物料池、索引池key的顆粒度相同,從而在業務存在高併發,且線上增量資料和物料、索引回刷同時進行的情況下實現影片每分鐘的彈幕原子性寫入。在優先順序上以物料池為主,寫入索引前先驗證物料存在,反之則不做強校驗。
3.3.4 實驗能力支援
我們設計了三個不同的資料回刷鏈路:增量資料更新、索引回刷、物料回刷。其中增量資料更新應用於實時傳送的彈幕打分落表,索引回刷應用於在召回、粗排策略不變的情況下重新整理一組(或多組)模型打分,物料回刷應用於粗排模型更新時透過全量彈幕重新計算召回和粗排淘汰。業務上出現的主要場景是,如何快速支援粗排模型外的一組模型分數更新。在之前一期的設計中,我們需要對全部的存量資料進行回刷,因此耗時非常久。針對這一特點,我們拆分了索引回刷和物料回刷,區別是是否需要更新粗排模型,重新進行召回和淘汰。這樣透過索引回刷即可滿足大部分策略迭代需求,減輕了整體的流程。結合前面物料池、索引池分離的儲存設計,可以減少了一半的資料寫入量。
索引回刷設計
消費端的一個特點是流量集中在頭部稿件,因此我們的思考方向是如何透過儘量小的資料回刷來覆蓋儘量多的vv百分比。在新的系統中,透過ETL任務計算得到小時更新的高熱稿件(即影片)表,再透過Clickhouse儲存當天的實時增量資料,這樣兩者結合即可得到完整的高熱+實時影片列表,在需要更新索引時只需要更新這部分影片對應的彈幕即可。透過上述冷熱資料分離的方式,我們最終透過15%計算量可以覆蓋90%的vv,大幅提升了實驗效率。
此外,部分策略迭代並不需要重新整理全部影片下的彈幕。在這種情況下,透過數倉更新定製化的ETL並投遞到資料消費端即可,在1小時內即可完成策略更新。
計算量最佳化
在推薦系統中,模型推理的計算成本也是一項重要考量,如果能節省掉冗餘的推理次數,可以提升整個系統的效率,同時降低運維成本。在前一個階段,計算一條彈幕所有模型打分的方式是併發進行所有模型的推理。但如果這條彈幕最終因粗排分過低而淘汰,則會造成計算冗餘。新系統中的最佳化方式是,在增量資料更新和物料回刷的過程中,先進行粗排模型分的推理,完成排序淘汰之後再進行全部的模型推理,從而最佳化計算量。
3.3.5 精排最佳化
精排場景的難點是如何處理熱點影片下大批次資料的計算和排序問題。一些爆火的影片會出現總長度20分鐘左右,單影片彈幕量超過100w的情況,且集中在影片開頭。同時各組模型分數的覆蓋、重新整理情況也不盡相同,如何在單組模型推理邏輯出錯、部分資料已經寫入索引的情況下保證業務可快速恢復降級也是精排階段的目標之一。
退場邏輯前置
之前的架構中,精排伺服器在記憶體中快取彈幕索引且沒有退場淘汰邏輯,成為了熱點下的效能瓶頸。在新的系統中,我們將退場邏輯收斂到粗排階段,精排時不再需要進行資料快取,只需讀取經過粗排淘汰後的物料和快取即可。這樣,在精排階段需要排序的資料量大大減少,從而最佳化了響應時間。
模型版本控制
彈幕索引的模型是離線更新,如果新的模型出現邏輯錯誤只能在精排階段透過業務指標分組異常發現。而這時極有可能資料重新整理已經完成或者進行了一半。為了解決這種場景下的模型策略迭代可灰度、可觀測、可回滾,我們透過彈幕索引的欄位冗餘和版本控制來實現:

假設目前線上有點贊模型、負向模型2個模型,本次需要更新負向模型版本,則:更新版本(version+1),新版負向模型更新在空白欄位score16,同時保留舊版負向模型score2。模型內容和分數字段的對映關係在精排服務內維護。若發現新版模型不符合預期,則更新對映關係,使用舊版模型欄位score2即可完成回滾。若經線上驗證新版模型符合預期,則打分服務服務停止對舊模型)生成打分,同時在精排服務中標記舊模型欄位為空白即可完成釋出。
展示側召回補充
在前面索引回刷的設計中提到,為了支援快速實驗策略迭代模型回刷會覆蓋大多數影片而非全量影片。如果一些冷的影片又火了起來,需要有方法能發現這些影片,並且覆蓋最新的模型策略。這裡的實現是,在精排服務中校驗索引的版本(即version欄位)。若version過低,將影片id推送到補召回佇列中,更新全部最新的模型打分。這樣就實現了冷熱資料的轉換。
收益與展望
經過工程和演算法系統的整合,資料一致性、穩定性都獲得了大幅提升。精排降級率從3%下降到了0.1%,在策略不變的情況下彈幕曝光也有大幅增長,再透過減少曝光、提升上屏彈幕質量的方式最佳化了彈幕點贊率。同時全站策略實驗可以在10小時內完成資料回刷,小規模策略迭代可以在一小時內完成。同時在新的系統中,彈幕點贊、舉報、狀態、屬性位這些特徵可以做到實時而非離線,從而提升策略空間和流量冷啟動的效率。
在未來,我們也會在策略迭代效率、特徵實時性和工程穩定性三個方面對系統進行持續最佳化探索,從而帶來更優質的彈幕消費體驗。
來自 “ 嗶哩嗶哩技術 ”, 原文作者:孫嘉岐;原文連結:http://server.it168.com/a2022/1128/6777/000006777449.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 有贊個性化推薦能力的演進與實踐
- 推薦系統工程架構架構
- 第四正規化程曉澄: 推薦系統的架構演進架構
- 資料治理:資料整合架構的演進架構
- MySQL資料庫架構——高可用演進MySql資料庫架構
- 架構的演進, 阿里資深Java工程師表述架構的腐化之謎架構阿里Java工程師
- 架構的演進,阿里資深Java工程師表述架構的腐化之謎架構阿里Java工程師
- FunData — 電競大資料系統架構演進大資料架構
- 資料基礎架構如何演進,西部資料有話說架構
- 架構演進之「微服務架構」架構微服務
- 京東物流資料同步平臺“資料蜂巢”架構演進之路架構
- 聊聊演進式架構架構
- Airbnb的架構演進AI架構
- Serverless 架構的演進Server架構
- 推薦收藏|資料庫架構一次搞定(適合2-6年工程師)資料庫架構工程師
- OPPO大資料離線計算平臺架構演進大資料架構
- 新一代雲資料平臺架構演進之路架構
- 今日頭條架構演進之路——高壓下的架構演進專題架構
- 如何實現彈性架構架構
- IDEA外掛和個性化配置推薦Idea
- 專車資料層「架構進化」往事架構
- Python後端架構演進Python後端架構
- Serverless 架構模式及演進Server架構模式
- 高可用、彈性動態的金融級移動架構在螞蟻金服的演進之路架構
- OPPO大資料計算叢集資源排程架構演進大資料架構
- 面向資料架構的雲演變架構
- 外賣客戶端容器化架構的演進客戶端架構
- 架構視覺化支撐系統演進探索架構視覺化
- 智慧推薦系統:個性化推薦引領消費新潮流
- 京東推薦系統架構揭祕:大資料時代下的智慧化改造架構大資料
- 愛奇藝個性化推薦排序實踐排序
- 個性化推薦系統實踐應用
- 萬表商城Android架構演進Android架構
- vivo推送平臺架構演進架構
- 技術架構演進的思考架構
- Serverless 架構演進與實踐Server架構
- Flutter Fish Redux架構演進2.0FlutterRedux架構
- 故事篇:資料庫架構演變之路資料庫架構