自然語言處理入門 - olay
自然語言可以採用文字或語音的形式,機器學習可用於以文字和語音的形式解決涉及人類自然語言的問題。這被稱為自然語言處理,它已經有許多迷人的現實世界應用程式。
非結構化文字,例如文章、新聞、評論或評論,是自然語言資料的常見來源。必須從非結構化資料中檢索有用的資訊。為了檢索這些有用的資料,我們必須完成一系列步驟。
在本文中,我們將使用自然語言工具包 (NLTK)、一個 Python 包以及 Jupyter 筆記本來演示我們需要採取的常規程式來提取這些有用的資料。Anaconda 軟體包預裝了這些軟體包,因此您可以安裝它。
這些步驟包括:
1. 分詞
這是將多個短語或段落分解為更小的元件(例如單個句子或單詞)的過程。要執行這一步,我們需要匯入 NLTK 庫並下載punkt
import nltk
nltk.download('punkt')
|
然後匯入傳送的標記器和單詞標記器以分別生成句子和單詞標記。我們將使用它來標記一個句子,結果如下所示:
from nltk.tokenize import sent_tokenize, word_tokenize |
使用的示例文字是:
'Mary had a little lamb. Her fleece is white as snow'
text = 'Mary had a little lamb. Her fleece is white as snow' sents = sent_tokenize(text) print(sents) |
句子標記器的結果如下所示:
['Mary had a little lamb.', ' Her fleece is white as snow' ] |
在同一個句子上使用單詞分詞器:
words = word_tokenize(text) print(words) |
word tokenizer的結果如下圖:
['Mary', 'had', 'a', 'little', 'lamb', '.', 'Her', 'fleece', 'is', 'white', 'as', 'snow' ] |
2. 停用詞去除
句子被標記化後,停用詞將被刪除。停用詞是用於結構和語法目的但不為文字提供意義的詞。此類詞的示例是“is”、“for”等。除此之外,要刪除停用詞,我們需要下載 nltk 中的停用詞。一個例子如下所示
# Downloading the stop words
nltk.download('stopwords')
# Importing the downloaded stopwords
from nltk.corpus import stopwords
# Importing punctuations in other to also remove them from the sentence
from string import punctuation
# Creating a custom stopwords by adding the list of punctuation to the stopwords
custom_stop_words = set(stopwords.words('english')+list(punctuation))
print(custom_stop_words)
你需要建立一個
|
# sentence to remove stop words from text = 'Mary had a little lamb. Her fleece is white as snow' # Creating list of words without stopwords # Code below means to return each word in the tokenized word, if the words cant be found in the custom stop words words_without_stopwords = [word for word in word_tokenize(text) if word not in custom_stop_words] print(words_without_stopwords) |
上面程式碼的結果如下圖所示:
['Mary','little', 'lamb', 'Her', 'fleece','white','snow' ] |
從結果中,我們可以看到諸如had, a, is, 和等詞as沒有被包含在結果中,因為它們沒有為句子增加意義而是為結構增加了含義。
3. N-GRAMS
這需要確定一組一起找到的術語。例如,在一篇關於“勞斯萊斯”的文章中,“Rolls Royce”和 "Rolls" 與"Royce" 這兩個詞幾乎肯定會一起出現。如果將“Rolls Royce”保留為一個單一的實體,則可能會從該語言中衍生出更多的含義。單詞集合中單詞的數量以 n-gram 為單位,可以是 bi-gram、tri-gram 等。下面顯示了一個 n-gram 的例子。
from nltk.collocations import * bigram_measures = nltk.collocations.BigramAssocMeasures() finder = BigramCollocationFinder.from_words(words_without_stopwords) |
# Bi-grams sorted(finder.ngram_fd.items()) |
結果:

使用tri-grams:
find = TrigramCollocationFinder.from_words(words_without_stopwords) sorted(find.ngram_fd.items()) |
結果:

4. 詞幹
具有相同基本含義的單詞可能會因使用時的時態和上下文結構而不同。關閉、關閉和關閉是此類術語的示例。詞幹提取是將所有這些詞返回到它們的根詞並讓計算機對它們一視同仁的過程。為了說明詞幹提取,我們將使用不同的句子和 lancaster 詞幹提取器,如下所示
# New text to be used text_2 = 'Mary closed on closing night when she was in the mood to close.' from nltk.stem.lancaster import LancasterStemmer st = LancasterStemmer() stemmed_words = [st.stem(word) for word in word_tokenize(text_2)] print(stemmed_words) |
詞幹提取的結果如下所示,我們可以看到單詞“closed”、“close”和“close”返回到詞根“clos”,因此計算機將以相同的方式對待它們。
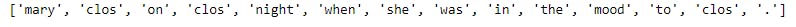
5. 部分語音標籤
計算機如何確定短語中的單詞是名詞、動詞、代詞還是詞性的其他部分。為了說明這一點,我們將使用 NLTK 下載“averaged_perceptron_tagger”,如下所示
nltk.download('averaged_perceptron_tagger')
nltk.pos_tag(word_tokenize(text_2))
|
結果如下所示,眾所周知,Mary 是專有名詞,閉合動詞等,因為它們已被標記

5. 詞義歧義
這就是計算機如何根據使用的上下文來解釋單詞的含義。有些詞根據情況有不同的含義。根據上下文,“洋流”一詞既可以指海洋的流動,也可以指現代的任何事物。為了說明這一點,我們將使用 nltk 下載 wordnet,我們將使用 wordnet 來檢查單詞“bass”的含義
nltk.download('wordnet')
from nltk.corpus import wordnet as wn
for ss in wn.synsets('bass'):
print(ss, ss.definition())
|
從下面顯示的結果來看,bass 一詞有多種含義,從“音樂範圍的最低部分”到“Serranidae 科鹹水魚的瘦肉”

我們將舉例說明wordnet能否根據上下文判斷單詞的意思
from nltk.wsd import lesk
sense_1 = lesk(word_tokenize('sing in a lower tone, along with the bass.'), 'bass')
print(sense_1, sense_1.definition())
|
輸出如下所示,wordnet 能夠根據上下文確定單詞的含義

顯示另一個例子
sense_2 = lesk(word_tokenize('This sea bass was really hard to catch.'), 'bass')
print(sense_2, sense_2.definition())
|
這些結果如下所示

這些是在訓練自然語言處理模型之前執行的 5 項常見活動。
本文的程式碼可以在我的 Github 儲存庫中找到
如果您有任何疑問,請隨時傳送郵件至[email]olayemibolaji1@gmail.com[/email]
相關文章
- NLP漢語自然語言處理入門基礎知識自然語言處理
- 自然語言處理入門基礎之hanlp詳解自然語言處理HanLP
- NLP漢語自然語言處理入門基礎知識介紹自然語言處理
- 關於《自然語言處理入門》的反饋意見,作者何晗說明如下自然語言處理
- 自然語言處理NLP快速入門自然語言處理
- 自然語言處理怎麼最快入門?自然語言處理
- 自然語言處理(NLP)系列(一)——自然語言理解(NLU)自然語言處理
- 入門自然語言處理必看:圖解詞向量自然語言處理圖解
- 自然語言處理NLP(四)自然語言處理
- 自然語言處理(NLP)概述自然語言處理
- Python自然語言處理工具Python自然語言處理
- HanLP 自然語言處理 for nodejsHanLP自然語言處理NodeJS
- 2023nlp影片教程大全 NLP自然語言處理教程 自然語言處理NLP從入門到專案實戰自然語言處理
- [譯] 自然語言處理真是有趣!自然語言處理
- 自然語言處理:分詞方法自然語言處理分詞
- 精通Python自然語言處理 2 :統計語言建模Python自然語言處理
- FFmpeg 影片處理入門教程
- 配置Hanlp自然語言處理進階HanLP自然語言處理
- 自然語言處理的最佳實踐自然語言處理
- 自然語言處理之jieba分詞自然語言處理Jieba分詞
- 人工智慧 (06) 自然語言處理人工智慧自然語言處理
- 自然語言處理與情緒智慧自然語言處理
- Pytorch系列:(六)自然語言處理NLPPyTorch自然語言處理
- 中國語文(自然語言處理)作業自然語言處理
- 自然語言處理中的語言模型預訓練方法自然語言處理模型
- FFmpeg 視訊處理入門教程
- 音訊訊號處理入門音訊
- 探索自然語言處理:語言模型的發展與應用自然語言處理模型
- 自然語言處理NLP(6)——詞法分析自然語言處理詞法分析
- 精通Python自然語言處理 1 :字串操作Python自然語言處理字串
- 深度解析自然語言處理之篇章分析自然語言處理
- 自然語言處理(NLP)路線圖 - kdnuggets自然語言處理
- 人工智慧--自然語言處理簡介人工智慧自然語言處理
- 牛津大學xDeepMind自然語言處理 第13講 語言模型(3)自然語言處理模型
- python呼叫自然語言處理工具hanlp記錄Python自然語言處理HanLP
- 有趣的自然語言處理資源集錦自然語言處理
- 自然語言處理(NLP)簡介 | NLP課程自然語言處理
- 自然語言處理技術詳細概覽自然語言處理