IO模型
常見的五種IO模型
常見的IO模型大概有5種:
1.IO阻塞模型(blocking IO)
2.非IO阻塞模型(blocking IO)
3.IO多路複用(IO multiplexing)
4.訊號驅動IO(signal driven IO 不常用)
5.非同步IO(asynchronous IO)
IO執行一共有兩個階段:一個階段是指等待資料階段,第二個階段是指將速度從作業系統打包複製給應用程式
#1)等待資料準備 (Waiting for the data to be ready)
#2)將資料從核心拷貝到程式中(Copying the data from the kernel to the process)
在網路程式設計中常見的會造成阻塞的程式碼:accept,recv,recvfrom
IO阻塞模型:
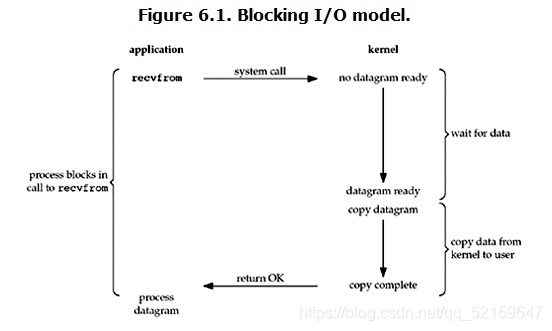
阻塞模型的特點是:在wait for data階段和copy data階段均阻塞
mport socket
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
while True:
conn, addr = server.accept()
while True:
try:
data = conn.recv(1024)
if len(data) == 0:break
print(data)
conn.send(data.upper())
except ConnectionResetError as e:
break
conn.close()
# 即使我們開設了多執行緒和多程式,但是其實本質上沒有解決IO阻塞問題
# 程式仍然會等,知識不相互干擾的等待
非阻塞模型
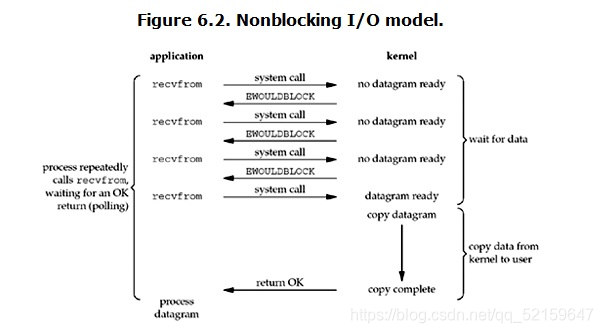
非阻塞模型的特點:在 wait for data階段立即回撥一個函式,如果資料沒有準備好,程式可以幹其他事情,也可以再次向作業系統發資料請求指令
"""
要自己實現一個非阻塞IO模型
"""
import socket
import time
server = socket.socket()
server.bind(('127.0.0.1', 8081))
server.listen(5)
server.setblocking(False)
# 將所有的網路阻塞變為非阻塞
r_list = []
del_list = []
while True:
try:
conn, addr = server.accept()
r_list.append(conn)
except BlockingIOError:
# time.sleep(0.1)
# print('列表的長度:',len(r_list))
# print('做其他事')
for conn in r_list: # 當列表中沒有值時候不會報錯,是因為for迴圈捕捉了迭代器無值的異常
try:
data = conn.recv(1024) # 沒有訊息 報錯
if len(data) == 0: # 客戶端斷開連結
conn.close() # 關閉conn
# 將無用的conn從r_list刪除
del_list.append(conn)
continue
conn.send(data.upper())
except BlockingIOError:
continue
except ConnectionResetError:
conn.close()
del_list.append(conn)
# 揮手無用的連結
for conn in del_list:
r_list.remove(conn)
del_list.clear()
# 客戶端
import socket
client = socket.socket()
client.connect(('127.0.0.1',8081))
while True:
client.send(b'hello world')
data = client.recv(1024)
print(data)
優點:
1.能夠同時完成多個任務,提升程式效率。
問題:
- 迴圈呼叫recv()將大幅度推高CPU佔用率;這也是我們在程式碼中留一句time.sleep(2)的原因,否則在低配主機下極容易出現卡機情況
- 任務完成的響應延遲增大了,因為每過一段時間才去輪詢一次read操作,而任務可能在兩次輪詢之間的任意時間完成。這會導致整體資料吞吐量的降低。
多路複用IO模型
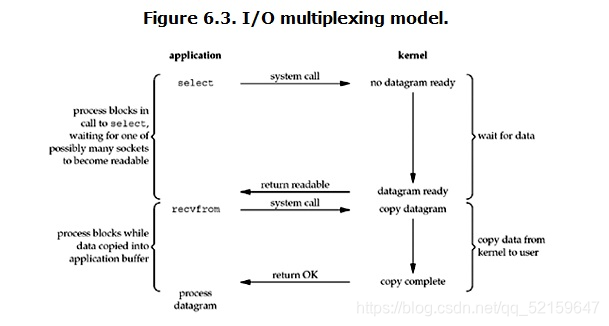
特點:
1.如果監測數量較少,多路複用IO模型的監測速度低於IO阻塞模型
2.相比於程式級別的監測,多路複用IO是作業系統級別的監測
3.多路影印仍然處於阻塞,但是阻塞的原因不是因為IO操作造成的,而是因為select造成的(相比於非阻塞會交出CPU的許可權給其他程式)
4.由於底層相當於一個for迴圈,因此可能出現一個迴圈結束後資料才送達的情況。
# coding:utf-8
import socket
import select
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
server.setblocking(False)
print(type(server))
read_list = [server]
while True:
r_list, w_list, x_list = select.select(read_list, [], []) # ==>返回三個列表
"""
幫你監管
一旦有人來了 立刻給你返回對應的監管物件
"""
# print(res) # ([<socket.socket fd=3, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 8080)>], [], [])
# print(server)
# print(r_list)
print(type(server)) ==>都是server.server類
print(type(r_list[0])) ==>都是server.server類
for i in r_list: #
"""針對不同的物件做不同的處理"""
if i is server:
conn, addr = i.accept()
# 也應該新增到監管的佇列中
read_list.append(conn)
else:
res = i.recv(1024)
if len(res) == 0:
i.close()
# 將無效的監管物件 移除
read_list.remove(i)
continue
print(res)
i.send(b'heiheiheiheihei')
監管:
監管機制其實有很多:
1.select機制
底層監管相當於for 迴圈
支援Windows和Linux雙系統
問題:當監管的物件特別多的時候可能會出現 極其大的延時響應
2.poll機制
支援Linux系統
問題:當監管的物件特別多的時候可能會出現 極其大的延時響應
3.epoll機制(能夠)
支援Linux系統
因此,針對不同的作業系統要選擇不同的監管機制:
而selectors模組能夠根據作業系統自動選擇不同的機制
非同步IO
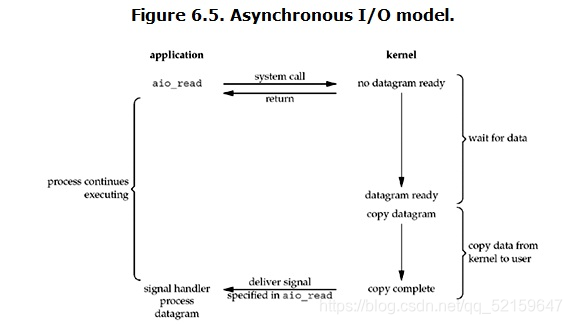
非同步IO是所有IO模型中效率最高的
相關的模組和框架
模組:asyncio模組
非同步框架:sanic,tronado,twisted
本質上就是協程思想與多道技術:切換+儲存狀態 ==>回撥機制
"""
非同步IO模型是所有模型中效率最高的 也是使用最廣泛的
相關的模組和框架
模組:asyncio模組
非同步框架:sanic tronado twisted
速度快!!!
本質上就是協程思想和多道技術的思想
"""
import threading
import asyncio
@asyncio.coroutine
def hello():
print('hello world %s'%threading.current_thread())
yield from asyncio.sleep(1) # 換成真正的IO操作
print('hello world %s' % threading.current_thread())
loop = asyncio.get_event_loop()
tasks = [hello(),hello()]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
四個IO模型的比較

1.blocking全程堵塞
2.nonblocking大部分時間不用阻塞,但是會一直髮check,造成CPU的資源濫用
3.asynchronous IO雖然會不造成IO阻塞,但是將監測交給了CPU核心,仍然會造成阻塞
4.signal_driven IO 多道技術==>切換加儲存狀態,效率極高
相關文章
- IO模型學習(一)IO模型分類模型
- io模型 WSAAsyncSelect模型
- 【IO】Linux下的五種IO模型Linux模型
- linux的IO模型Linux模型
- IO通訊模型(三)多路複用IO模型
- 【NIO系列】——之IO模型模型
- (四)五種IO模型模型
- WinSock 重疊IO模型模型
- NIO(二)淺析IO模型模型
- 五種網路io模型模型
- 圖解四種 IO 模型圖解模型
- 五種傳統IO模型模型
- 今天我們來聊Java IO模型,BIO、NIO、AIO三種常見IO模型Java模型AI
- IO通訊模型(二)同步非阻塞模式NIO(NonBlocking IO)模型模式BloC
- 高效能IO模型淺析模型
- Linux中的IO模型介紹Linux模型
- 【OS】5種網路IO模型模型
- 【網路IO系列】IO的五種模型,BIO、NIO、AIO、IO多路複用、 訊號驅動IO模型AI
- 網路IO模型-非同步選擇模型(Delphi版)模型非同步
- 通過IO模型帶來的思考模型
- 網路程式設計之IO模型程式設計模型
- 從io模型到ppc,tpc,reactor,preactor模型React
- (三)Redis 執行緒與IO模型Redis執行緒模型
- 大壓力 小資料IO模型模型
- 高階IO模型之kqueue和epoll模型
- JAVA進階之IO模型深入解析Java模型
- IO模型與吃飯的那些事模型
- 網路 IO 模型簡單介紹模型
- 從時間碎片角度理解阻塞IO模型及非阻塞模型模型
- Linux網路程式設計之IO模型Linux程式設計模型
- 五種IO模型介紹和對比模型
- 併發程式設計——IO模型詳解程式設計模型
- IO流中「執行緒」模型總結執行緒模型
- activemq修改IO模型和最大連線數MQ模型
- 談談對不同I/O模型的理解 (阻塞/非阻塞IO,同步/非同步IO)模型非同步
- 伺服器端程式設計之 IO 模型伺服器程式設計模型
- Java3種IO模型,一次搞懂!Java模型
- Redis基礎篇(二)高效能IO模型Redis模型