基於redis實現分散式鎖
背景
在很多網際網路產品應用中,有些場景需要加鎖處理,比如:秒殺,全域性遞增ID,樓層生成等等。大部分的解決方案是基於DB實現的,Redis為單程式單執行緒模式,採用佇列模式將併發訪問變成序列訪問,且多客戶端對Redis的連線並不存在競爭關係。其次Redis提供一些命令SETNX,GETSET,可以方便實現分散式鎖機制。
Redis命令介紹
使用Redis實現分散式鎖,有兩個重要函式需要介紹
SETNX命令(SET if Not eXists)
語法:
SETNX key value
功能:
當且僅當 key 不存在,將 key 的值設為 value ,並返回1;若給定的 key 已經存在,則 SETNX 不做任何動作,並返回0。
GETSET命令
語法:
GETSET key value
功能:
將給定 key 的值設為 value ,並返回 key 的舊值 (old value),當 key 存在但不是字串型別時,返回一個錯誤,當key不存在時,返回nil。
GET命令
語法:
GET key
功能:
返回 key 所關聯的字串值,如果 key 不存在那麼返回特殊值 nil 。
DEL命令
語法:
DEL key [KEY …]
功能:
刪除給定的一個或多個 key ,不存在的 key 會被忽略。
兵貴精,不在多。分散式鎖,我們就依靠這四個命令。但在具體實現,還有很多細節,需要仔細斟酌,因為在分散式併發多程式中,任何一點出現差錯,都會導致死鎖,hold住所有程式。
加鎖實現
SETNX 可以直接加鎖操作,比如說對某個關鍵詞foo加鎖,客戶端可以嘗試
SETNX foo.lock <current unix time>
如果返回1,表示客戶端已經獲取鎖,可以往下操作,操作完成後,透過
DEL foo.lock
命令來釋放鎖。
如果返回0,說明foo已經被其他客戶端上鎖,如果鎖是非堵塞的,可以選擇返回撥用。如果是堵塞呼叫呼叫,就需要進入以下個重試迴圈,直至成功獲得鎖或者重試超時。理想是美好的,現實是殘酷的。僅僅使用SETNX加鎖帶有競爭條件的,在某些特定的情況會造成死鎖錯誤。
處理死鎖
在上面的處理方式中,如果獲取鎖的客戶端端執行時間過長,程式被kill掉,或者因為其他異常崩潰,導致無法釋放鎖,就會造成死鎖。所以,需要對加鎖要做時效性檢測。因此,我們在加鎖時,把當前時間戳作為value存入此鎖中,透過當前時間戳和Redis中的時間戳進行對比,如果超過一定差值,認為鎖已經時效,防止鎖無限期的鎖下去,但是,在大併發情況,如果同時檢測鎖失效,並簡單粗暴的刪除死鎖,再透過SETNX上鎖,可能會導致競爭條件的產生,即多個客戶端同時獲取鎖。
C1獲取鎖,並崩潰。C2和C3呼叫SETNX上鎖返回0後,獲得foo.lock的時間戳,透過比對時間戳,發現鎖超時。
C2 向foo.lock傳送DEL命令。
C2 向foo.lock傳送SETNX獲取鎖。
C3 向foo.lock傳送DEL命令,此時C3傳送DEL時,其實DEL掉的是C2的鎖。
C3 向foo.lock傳送SETNX獲取鎖。
此時C2和C3都獲取了鎖,產生競爭條件,如果在更高併發的情況,可能會有更多客戶端獲取鎖。所以,DEL鎖的操作,不能直接使用在鎖超時的情況下,幸好我們有GETSET方法,假設我們現在有另外一個客戶端C4,看看如何使用GETSET方式,避免這種情況產生。
C1獲取鎖,並崩潰。C2和C3呼叫SETNX上鎖返回0後,呼叫GET命令獲得foo.lock的時間戳T1,透過比對時間戳,發現鎖超時。
C4 向foo.lock傳送GESET命令,
GETSET foo.lock <current unix time>
並得到foo.lock中老的時間戳T2
如果T1=T2,說明C4獲得時間戳。
如果T1!=T2,說明C4之前有另外一個客戶端C5透過呼叫GETSET方式獲取了時間戳,C4未獲得鎖。只能sleep下,進入下次迴圈中。
現在唯一的問題是,C4設定foo.lock的新時間戳,是否會對鎖產生影響。其實我們可以看到C4和C5執行的時間差值極小,並且寫入foo.lock中的都是有效時間錯,所以對鎖並沒有影響。
為了讓這個鎖更加強壯,獲取鎖的客戶端,應該在呼叫關鍵業務時,再次呼叫GET方法獲取T1,和寫入的T0時間戳進行對比,以免鎖因其他情況被執行DEL意外解開而不知。以上步驟和情況,很容易從其他參考資料中看到。客戶端處理和失敗的情況非常複雜,不僅僅是崩潰這麼簡單,還可能是客戶端因為某些操作被阻塞了相當長時間,緊接著 DEL 命令被嘗試執行(但這時鎖卻在另外的客戶端手上)。也可能因為處理不當,導致死鎖。還有可能因為sleep設定不合理,導致Redis在大併發下被壓垮。最為常見的問題還有
GET返回nil時應該走那種邏輯?
第一種走超時邏輯
C1客戶端獲取鎖,並且處理完後,DEL掉鎖,在DEL鎖之前。C2透過SETNX向foo.lock設定時間戳T0 發現有客戶端獲取鎖,進入GET操作。
C2 向foo.lock傳送GET命令,獲取返回值T1(nil)。
C2 透過T0>T1+expire對比,進入GETSET流程。
C2 呼叫GETSET向foo.lock傳送T0時間戳,返回foo.lock的原值T2
C2 如果T2=T1相等,獲得鎖,如果T2!=T1,未獲得鎖。
第二種情況走迴圈走setnx邏輯
C1客戶端獲取鎖,並且處理完後,DEL掉鎖,在DEL鎖之前。C2透過SETNX向foo.lock設定時間戳T0 發現有客戶端獲取鎖,進入GET操作。
C2 向foo.lock傳送GET命令,獲取返回值T1(nil)。
C2 迴圈,進入下一次SETNX邏輯
兩種邏輯貌似都是OK,但是從邏輯處理上來說,第一種情況存在問題。當GET返回nil表示,鎖是被刪除的,而不是超時,應該走SETNX邏輯加鎖。走第一種情況的問題是,正常的加鎖邏輯應該走SETNX,而現在當鎖被解除後,走的是GETST,如果判斷條件不當,就會引起死鎖,很悲催,我在做的時候就碰到了,具體怎麼碰到的看下面的問題
GETSET返回nil時應該怎麼處理?
C1和C2客戶端呼叫GET介面,C1返回T1,此時C3網路情況更好,快速進入獲取鎖,並執行DEL刪除鎖,C2返回T2(nil),C1和C2都進入超時處理邏輯。
C1 向foo.lock傳送GETSET命令,獲取返回值T11(nil)。
C1 比對C1和C11發現兩者不同,處理邏輯認為未獲取鎖。
C2 向foo.lock傳送GETSET命令,獲取返回值T22(C1寫入的時間戳)。
C2 比對C2和C22發現兩者不同,處理邏輯認為未獲取鎖。
此時C1和C2都認為未獲取鎖,其實C1是已經獲取鎖了,但是他的處理邏輯沒有考慮GETSET返回nil的情況,只是單純的用GET和GETSET值就行對比,至於為什麼會出現這種情況?一種是多客戶端時,每個客戶端連線Redis的後,發出的命令並不是連續的,導致從單客戶端看到的好像連續的命令,到Redis server後,這兩條命令之間可能已經插入大量的其他客戶端發出的命令,比如DEL,SETNX等。第二種情況,多客戶端之間時間不同步,或者不是嚴格意義的同步。
時間戳的問題
我們看到foo.lock的value值為時間戳,所以要在多客戶端情況下,保證鎖有效,一定要同步各伺服器的時間,如果各伺服器間,時間有差異。時間不一致的客戶端,在判斷鎖超時,就會出現偏差,從而產生競爭條件。
鎖的超時與否,嚴格依賴時間戳,時間戳本身也是有精度限制,假如我們的時間精度為秒,從加鎖到執行操作再到解鎖,一般操作肯定都能在一秒內完成。這樣的話,我們上面的CASE,就很容易出現。所以,最好把時間精度提升到毫秒級。這樣的話,可以保證毫秒級別的鎖是安全的。
分散式鎖的問題
1:必要的超時機制:獲取鎖的客戶端一旦崩潰,一定要有過期機制,否則其他客戶端都降無法獲取鎖,造成死鎖問題。
2:分散式鎖,多客戶端的時間戳不能保證嚴格意義的一致性,所以在某些特定因素下,有可能存在鎖串的情況。要適度的機制,可以承受小機率的事件產生。
3:只對關鍵處理節點加鎖,良好的習慣是,把相關的資源準備好,比如連線資料庫後,呼叫加鎖機制獲取鎖,直接進行操作,然後釋放,儘量減少持有鎖的時間。
4:在持有鎖期間要不要CHECK鎖,如果需要嚴格依賴鎖的狀態,最好在關鍵步驟中做鎖的CHECK檢查機制,但是根據我們的測試發現,在大併發時,每一次CHECK鎖操作,都要消耗掉幾個毫秒,而我們的整個持鎖處理邏輯才不到10毫秒,玩客沒有選擇做鎖的檢查。
5:sleep學問,為了減少對Redis的壓力,獲取鎖嘗試時,迴圈之間一定要做sleep操作。但是sleep時間是多少是門學問。需要根據自己的Redis的QPS,加上持鎖處理時間等進行合理計算。
6:至於為什麼不使用Redis的muti,expire,watch等機制,可以查一參考資料,找下原因。
鎖測試資料
未使用sleep
第一種,鎖重試時未做sleep。單次請求,加鎖,執行,解鎖時間

可以看到加鎖和解鎖時間都很快,當我們使用
ab -n1000 -c100 '
AB 併發100累計1000次請求,對這個方法進行壓測時。
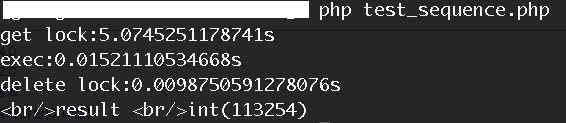
我們會發現,獲取鎖的時間變成,同時持有鎖後,執行時間也變成,而delete鎖的時間,將近10ms時間,為什麼會這樣?
1:持有鎖後,我們的執行邏輯中包含了再次呼叫Redis操作,在大併發情況下,Redis執行明顯變慢。
2:鎖的刪除時間變長,從之前的0.2ms,變成9.8ms,效能下降近50倍。
在這種情況下,我們壓測的QPS為49,最終發現QPS和壓測總量有關,當我們併發100總共100次請求時,QPS得到110多。當我們使用sleep時
使用Sleep時
單次執行請求時
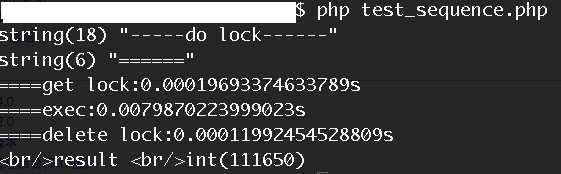
我們看到,和不使用sleep機制時,效能相當。當時用相同的壓測條件進行壓縮時
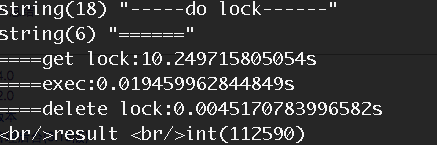
獲取鎖的時間明顯變長,而鎖的釋放時間明顯變短,僅是不採用sleep機制的一半。當然執行時間變成就是因為,我們在執行過程中,重新建立資料庫連線,導致時間變長的。同時我們可以對比下Redis的命令執行壓力情況

上圖中細高部分是為未採用sleep機制的時的壓測圖,矮胖部分為採用sleep機制的壓測圖,通上圖看到壓力減少50%左右,當然,sleep這種方式還有個缺點QPS下降明顯,在我們的壓測條件下,僅為35,並且有部分請求出現超時情況。不過綜合各種情況後,我們還是決定採用sleep機制,主要是為了防止在大併發情況下把Redis壓垮,很不行,我們之前碰到過,所以肯定會採用sleep機制。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/31557424/viewspace-2220662/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 基於redis分散式鎖實現“秒殺”Redis分散式
- 基於Redis實現一個分散式鎖Redis分散式
- 分散式鎖與實現(一)基於Redis實現!分散式Redis
- 基於 Redis 分散式鎖Redis分散式
- 基於redis和zookeeper的分散式鎖實現方式Redis分散式
- 基於redis的分散式鎖Redis分散式
- 基於redis做分散式鎖Redis分散式
- 基於 Redis 的分散式鎖Redis分散式
- Golang 基於單節點 Redis 實現的分散式鎖GolangRedis分散式
- java 實現開箱即用基於 redis 的分散式鎖JavaRedis分散式
- 基於ZK實現分散式鎖分散式
- 分散式鎖----Redis實現分散式Redis
- Redis實現分散式鎖Redis分散式
- 【Redis】利用 Redis 實現分散式鎖Redis分散式
- 基於AOP和Redis實現的簡易版分散式鎖Redis分散式
- 教你一招:基於Redis實現一個分散式鎖Redis分散式
- 基於資料庫、redis和zookeeper實現的分散式鎖資料庫Redis分散式
- 基於 Zookeeper 的分散式鎖實現分散式
- 分散式鎖之Redis實現分散式Redis
- 利用Redis實現分散式鎖Redis分散式
- redis分散式鎖-SETNX實現Redis分散式
- 分散式鎖實現(一):Redis分散式Redis
- Redis之分散式鎖實現Redis分散式
- Redis如何實現分散式鎖Redis分散式
- redis分散式鎖的實現Redis分散式
- redis分散式鎖-java實現Redis分散式Java
- NodeJS 基於redis的分散式鎖的實現(Redlock演算法)NodeJSRedis分散式演算法
- 手把手教你實現一個基於Redis的分散式鎖Redis分散式
- 【進階篇】基於 Redis 實現分散式鎖的全過程Redis分散式
- 基於SpringBoot AOP面向切面程式設計實現Redis分散式鎖Spring Boot程式設計Redis分散式
- Java程式猿筆記——基於redis分散式鎖實現“秒殺”Java筆記Redis分散式
- 分散式鎖中-基於 Redis 的實現需避坑 - Jedis 篇分散式Redis
- [翻譯]基於redis的分散式鎖Redis分散式
- Redis優雅實現分散式鎖Redis分散式
- 實現一個 Redis 分散式鎖Redis分散式
- 如何使用Redis實現分散式鎖Redis分散式
- 用 Go + Redis 實現分散式鎖GoRedis分散式
- redis分散式鎖實現(golang版)Redis分散式Golang