- 原文地址:ML Kit Tutorial for iOS: Recognizing Text in Images
- 原文作者:By David East
- 譯文出自:掘金翻譯計劃
- 本文永久連結:github.com/xitu/gold-m…
- 譯者:portandbridge
- 校對者:Lobster-King,iWeslie
在這篇 ML Kit 教程裡面,你會學習如何使用 Google 的 ML Kit 進行文字檢測和識別。
幾年前,機器學習開發者分成兩類:高階開發者是一類,其餘的人則是另一類。機器學習的底層部分有可能很難,因為它涉及很多數學知識,還用到**邏輯迴歸(logistic regression)、稀疏性(sparsity)和神經網路(neural nets) **這樣的艱深字眼。不過,也不是一定要搞得那麼難的。 ) 你也可以成為機器學習開發者的!就其核心而言,機器學習並不難。應用機器學習時,你是通過教軟體模型發現規律來解決問題,而不是將你能想到的每種情況都硬編碼到模型裡面。然而,一開始做的時候有可能會讓人卻步,而這正是你可以運用現有工具的時機。
機器學習與工具配套(Tooling)
和 iOS 開發一樣,機器學習與工具配套息息相關。你不會自己搭建一個 UITableView,或者說,至少你不應該那麼做;你會用一個框架,比如 UIKit。
機器學習也是一樣的道理。機器學習有一個正蓬勃發展的工具配套生態系統。舉個例子,Tensorflow 可以簡化訓練及執行模型的過程。TensorFlow Lite 則可以給 iOS 和 Android 裝置帶來對模型的支援。
這些工具用起來全都需要一定的機器學習方面的經驗。假如你不是機器學習的專家,但又想解決某個具體問題,該怎麼辦呢?這時候你就可以用 ML Kit。
ML Kit
ML Kit 是個移動端的 SDK,可以將 Google 強大的機器學習技術帶到你的 App 中。ML Kit 的 API 有兩大部分,可以用於普通使用場景和自定義模型;而不管使用者的經驗如何,它們用起來都不難。

現有的 API 目前支援:
以上的每種使用場景都附帶一個預先訓練過的模型,而模型則包裝在易用的 API 中。現在是時候動手做點東西啦!
預備工作
在本教程中,你會編寫一個名為 Extractor 的 App。你有沒有試過,只是為了把文字內容寫下來,就去給標誌或者海報拍照呢?如果有個 App 能夠把圖片上的文字摳下來並轉換成真正的文字格式,那就太好了!比方說,你只需要給帶有地址的一個信封拍照,就可以提取上面的地址資訊。接下來你要在這個專案裡面做的,正就是這樣的 App!快做好準備吧!
你首先要做的,是下載本教程要用到的專案材料。點選教程最上方或者底部的“Download Materials”按鈕就可以下載啦。
本專案使用 CocoaPods 對依賴進行管理。
配置 ML Kit 環境
每個 ML Kit API 都有一套不同的 CocoaPods 依賴。這蠻有用的,因為你只需要打包你的 App 所需的依賴。比方說,如果你不打算識別地標建築,你的 App 就不需要有那個模型。在 Extractor 裡,你要用到的是文字識別 API。
假如要在你的 App 裡面加入文字識別 API,你需要在 Podfile 裡面加入以下幾行。不過做這個初始專案的時候就不用了,因為 Podfile 裡面已經寫好啦,你可以自己開啟看看。
pod 'Firebase/Core' => '5.5.0'
pod 'Firebase/MLVision' => '5.5.0'
pod 'Firebase/MLVisionTextModel' => '5.5.0'
複製程式碼需要你做的呢,是開啟終端,進入專案的資料夾,執行下面的命令,從而安裝專案要用到的 CocoaPods:
pod install
複製程式碼安裝好 CocoaPods 之後,在 Xcode 中開啟 Extractor.xcworkspace。
注意:你可能會發現,專案的資料夾裡有一個名為 Extractor.xcodeproj 的專案檔案,和一個名為 Extractor.xcworkspace 的 workspace 檔案。你需要在 Xcode 開啟後者,因為前者沒有包含編譯時所需的 CocoaPods 依賴庫。
如果你不熟悉 CocoaPods,我們的 CocoaPods 教程 可以帶你初步瞭解下。
本專案包含以下的重要檔案:
- ViewController.swift:本專案唯一的控制器。
- +UIImage.swift:用於修正影像方向的
UIImage擴充套件。
開設一個 Firebase 賬號
按照 初步學習 Firebase 的教程 這篇文章裡面有關開設賬號的部分去做,就可以開設一個 Firebase 賬號。雖然涉及的 Firebase 產品不同,新建賬號和設定的過程是完全一樣的。
大概的意思是讓你:
- 註冊賬號。
- 建立專案。
- 在專案中新增一個 iOS app。
- 將 GoogleService-Info.plist 拖動到專案中。
- 在 AppDelegate 中初始化 Firebase。
這個流程做起來不難,不過要是真的有什麼搞不定,上面提到的指南可以幫你解決問題。
注意:你需要設定好 Firebase,為最終專案和初始專案建立自己的 GoogleService-Info.plist 檔案。
編譯 App 再執行,你會看到它長這個樣子:

它暫時還做不了什麼,只能讓你用右上方的動作按鈕分享已經寫死的文字。你要用 ML Kit 把它做成一個真正有用的 App。
檢測基本文字
準備好進行第一次文字檢測啦!你一開始可以做的,是向使用者展示這個 App 的用法。
一個不錯的展示方法,就是在 App 第一次啟動的時候,掃描一幅示例圖片。資原始檔夾裡附帶了一幅叫做 scanned-text 的圖片,它現在是檢視控制器的 UIImageView 所顯示的預設圖片,你會用它來做示例圖片。
不過一開始呢,你需要有一個可以檢測圖片內文字的文字檢測器。
建立文字檢測器
新建一個名為 ScaledElementProcessor.swift 的檔案,填入以下程式碼:
import Firebase
class ScaledElementProcessor {
}
複製程式碼好啦,搞定啦!……才怪。你要在這個類裡面新增一個 text-detector 屬性:
let vision = Vision.vision()
var textRecognizer: VisionTextRecognizer!
init() {
textRecognizer = vision.onDeviceTextRecognizer()
}
複製程式碼這個 textRecognizer 就是你用來檢測影像內文字的主要物件。你要用它來識別 UIImageView 所顯示的圖片裡面的文字。向剛才的類新增下面的檢測方法:
func process(in imageView: UIImageView,
callback: @escaping (_ text: String) -> Void) {
// 1
guard let image = imageView.image else { return }
// 2
let visionImage = VisionImage(image: image)
// 3
textRecognizer.process(visionImage) { result, error in
// 4
guard
error == nil,
let result = result,
!result.text.isEmpty
else {
callback("")
return
}
// 5
callback(result.text)
}
}
複製程式碼我們花一點點時間搞懂上面這串程式碼:
- 檢查
imageView當中是否真的包含圖片。沒有的話,直接返回就可以了。不過理想的做法還是,顯示或者自己編寫一段得體的錯誤資訊。 - ML Kit 使用一個特別的
VisionImage型別。它很好用,因為可以包含像是圖片方向之類的具體後設資料,讓 ML Kit 用來處理影像。 textRecognizer帶有一個process方法, 這個方法會輸入VisionImage,然後返回文字結果的陣列,將其作為引數傳遞給閉包。- 結果可以是
nil;那樣的話,你最好為回撥返回一個空字串。 - 最後,觸發回撥,從而傳遞識別出的文字。
使用文字識別器
開啟 ViewController.swift,然後在類本體程式碼頂端的 outlet 後面,將 ScaledElementProcessor 的一個例項作為屬性新增進去:
let processor = ScaledElementProcessor()
複製程式碼然後在 viewDidLoad() 的底部新增以下的程式碼,作用是在 UITextView 中顯示出檢測到的文字:
processor.process(in: imageView) { text in
self.scannedText = text
}
複製程式碼這一小段程式碼會呼叫 process(in:),傳遞主要的 imageView,然後在回撥當中將識別出的文字分配給 scannedText 屬性。
執行 app,你應該會在影像的下方看到下面的文字:
Your
SCanned
text
will
appear
here
複製程式碼你可能要拖動文字檢視才能看到最下面的幾行。
留意一下,scanned 裡面的 S 和 C 字母都是大寫的。有時對某些字型進行識別的時候,文字的大小寫會出錯。這就是要在 UITextView 顯示文字的原因;要是檢測出錯,使用者可以手動編輯文字進行改正。

理解這些類
注意:你不需要複製這一節裡面的程式碼,這些程式碼只是用來幫忙解釋概念的。到了下一節,你才需要往 App 裡面新增程式碼。
VisionText
你有沒有發現,ScaledElementProcessor 中 textRecognizer.process(in:) 的回撥函式返回的,是 result 引數裡面的一個物件,而不是純粹的文字。這是 VisionText 的一個例項;它是一種包含很多有用資訊的類,比如是識別到的文字。不過,你要做的不僅僅是取得文字。如果我們可以幫每個識別出的文字元素都畫出一個外框,那不是更酷炫嗎?
ML Kit 所提供的結果,具有像樹一樣的結構。你需要到達葉元素,才能取得包含已識別文字的 frame 的位置和尺寸。如果聽完樹形結構這個類比你還不是很懂的話,不用擔心。下面的幾節會講清楚到底發生了什麼。
不過,如果你有興趣多瞭解樹形資料結構的話,可以隨時去看看這篇教程 — Swift 樹形資料結構。
VisionTextBlock
處理識別出的文字時,你首先要用到 VisionText 物件 — 這個物件(我所說的樹)包含多個文字區塊(就像樹上的枝條)。每個分支都是 blocks 陣列裡面的 VisionTextBlock 物件;而你需要迭代每個分支,做法如下:
for block in result.blocks {
}
複製程式碼VisionTextElement
VisionTextBlock 純粹是個包含一系列分行文字(文字就像是樹枝上的葉子)的物件,它們每一個都由 VisionTextElement 例項進行代表。你可以在這幅由各物件組成的巢狀圖裡,看清已識別文字的層級結構。
![[譯] 用於 iOS 的 ML Kit 教程:識別影像中的文字](https://koenig-media.raywenderlich.com/uploads/2018/07/vision-hierarchy-2x-1.png)
迴圈遍歷每個物件的時候,大概是這樣:
for block in result.blocks {
for line in block.lines {
for element in line.elements {
}
}
}
複製程式碼這個層級結構裡面的每個物件都包涵文字所在的 frame。然而,每個物件都具有不同層次的粒度。一個塊(block)裡面或許包括幾個行。每行可能包括多個元素。而每個元素則可能包括多個符號。
就這篇教程而言,你要用到的是元素這一粒度層次。元素通常對應的是一個單詞。這樣一來,你就可以在每個單詞上方進行繪製,向使用者展示出影像中每個單詞的位置。
最後一個迴圈會對文字塊中每一行的元素進行迭代。這些元素包含 frame,它是個簡單的 CGRect。運用這個 frame,你就可以在影像的文字周圍繪製外框。
突出顯示文字的 frame
frame 檢測
要在影像上繪製,你需要建立一個具有文字元素的 frame 的 CAShapeLayer。開啟 ScaledElementProcessor.swift,將下面的 struct 插入到檔案的最上方:
struct ScaledElement {
let frame: CGRect
let shapeLayer: CALayer
}
複製程式碼這個 struct 很方便好用。有了 struct,就可以更容易地把 frame 和 CAShapeLayer 與控制器組合到一起。現在,你需要一個輔助方法,利用它從元素的 frame 建立 CAShapeLayer。
在 ScaledElementProcessor 的底部加入以下程式碼:
private func createShapeLayer(frame: CGRect) -> CAShapeLayer {
// 1
let bpath = UIBezierPath(rect: frame)
let shapeLayer = CAShapeLayer()
shapeLayer.path = bpath.cgPath
// 2
shapeLayer.strokeColor = Constants.lineColor
shapeLayer.fillColor = Constants.fillColor
shapeLayer.lineWidth = Constants.lineWidth
return shapeLayer
}
// MARK: - private
// 3
private enum Constants {
static let lineWidth: CGFloat = 3.0
static let lineColor = UIColor.yellow.cgColor
static let fillColor = UIColor.clear.cgColor
}
複製程式碼這段程式碼的作用是:
CAShapeLayer並沒有可以輸入CGRect的初始化器。所以,你要建立一個包含CGRect的UIBezierPath,然後將形狀圖層的path設定為這個UIBezierPath。- 通過
Constants列舉型別,設定顏色和寬度方面的影像屬性。 - 這一列舉型別可以讓顏色和寬度保持不變。
現在,用下面的程式碼替換掉 process(in:callback:):
// 1
func process(
in imageView: UIImageView,
callback: @escaping (_ text: String, _ scaledElements: [ScaledElement]) -> Void
) {
guard let image = imageView.image else { return }
let visionImage = VisionImage(image: image)
textRecognizer.process(visionImage) { result, error in
guard
error == nil,
let result = result,
!result.text.isEmpty
else {
callback("", [])
return
}
// 2
var scaledElements: [ScaledElement] = []
// 3
for block in result.blocks {
for line in block.lines {
for element in line.elements {
// 4
let shapeLayer = self.createShapeLayer(frame: element.frame)
let scaledElement =
ScaledElement(frame: element.frame, shapeLayer: shapeLayer)
// 5
scaledElements.append(scaledElement)
}
}
}
callback(result.text, scaledElements)
}
}
複製程式碼程式碼有以下的改動:
- 這裡的回撥函式現在不但可以接受已識別的文字,也可以接受
ScaledElement例項組成的陣列。 scaledElements的作用是收集存放 frame 和形狀圖層。- 和上文的簡介完全一致,這段程式碼使用
for迴圈取得每個元素的 frame。 - 最內層的
for迴圈用元素的 frame 建立形狀圖層,然後又用圖層來建立一個新的ScaledElement例項。 - 將剛剛建立的例項新增到
scaledElements之中。
繪製
上面這些程式碼的作用,是幫你預備好紙和筆。現在是時候開始畫畫啦。開啟 ViewController.swift,然後把 viewDidLoad() 有關 process(in:) 的呼叫替換為下面的程式碼:
processor.process(in: imageView) { text, elements in
self.scannedText = text
elements.forEach() { feature in
self.frameSublayer.addSublayer(feature.shapeLayer)
}
}
複製程式碼ViewController 具有一個附著於 imageView 的 frameSublayer 屬性。你要在這裡將每個元素的形狀圖層新增到子圖層中,這樣一來,iOS 就會自動在影像上繪製形狀。
編譯 App,然後執行。欣賞下自己的大作吧。

喲……這是啥?同學你這說不上是莫奈風格,倒有點畢加索的味道呀。(譯者注:畢加索的繪畫風格是將物體不同角度的樣貌縮放拼合,使其顯得支離破碎)這是哪裡出錯了呢?呃,或許是時候講講縮放比例這個問題了。
理解影像的縮放
預設的 scanned-text.png,其大小為 654×999 (寬乘高);但是呢,UIImageView 的“Content Mode”是“Aspect Fit”,這一設定會將檢視中的影像縮放成 375×369。ML Kit 所獲得的是影像的實際大小,它也是按照實際大小返回元素的 frame。然後,由實際尺寸得出的 frame 會繪製在縮放後的尺寸上。這樣得出的結果就讓人搞不懂狀況。
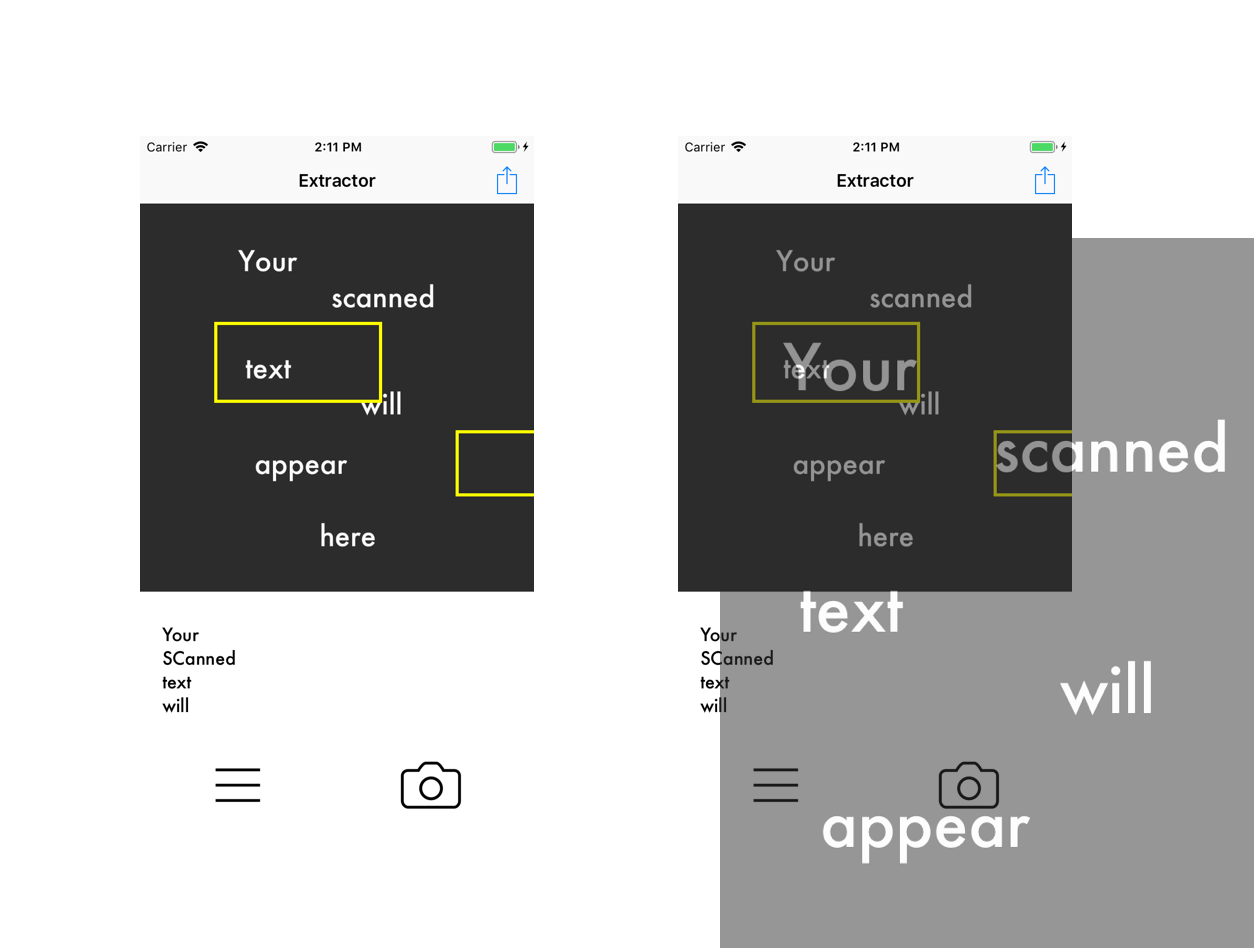
注意上圖裡面縮放尺寸與實際尺寸之間的差異。你可以看到,圖中的 frame 是與實際尺寸一致的。要把 frame 的位置放對,你就要計算出影像相對於檢視的縮放比例。
公式挺簡單的(?…大概吧):
- 計算出檢視和影像的解析度。
- 比較兩個解析度,定出縮放比例。
- 通過與縮放比例相乘,計算出高度、寬度、原點 x 和原點 y。
- 運用有關資料點,建立一個新的 CGRect。
要是聽糊塗了也不要緊!你看到程式碼就會懂的。
計算縮放比例
開啟 ScaledElementProcessor.swift,新增以下方法:
// 1
private func createScaledFrame(
featureFrame: CGRect,
imageSize: CGSize, viewFrame: CGRect)
-> CGRect {
let viewSize = viewFrame.size
// 2
let resolutionView = viewSize.width / viewSize.height
let resolutionImage = imageSize.width / imageSize.height
// 3
var scale: CGFloat
if resolutionView > resolutionImage {
scale = viewSize.height / imageSize.height
} else {
scale = viewSize.width / imageSize.width
}
// 4
let featureWidthScaled = featureFrame.size.width * scale
let featureHeightScaled = featureFrame.size.height * scale
// 5
let imageWidthScaled = imageSize.width * scale
let imageHeightScaled = imageSize.height * scale
let imagePointXScaled = (viewSize.width - imageWidthScaled) / 2
let imagePointYScaled = (viewSize.height - imageHeightScaled) / 2
// 6
let featurePointXScaled = imagePointXScaled + featureFrame.origin.x * scale
let featurePointYScaled = imagePointYScaled + featureFrame.origin.y * scale
// 7
return CGRect(x: featurePointXScaled,
y: featurePointYScaled,
width: featureWidthScaled,
height: featureHeightScaled)
}
複製程式碼程式碼所做的東西包括:
- 這個方法會輸入
CGRect,從而獲取影像的原本尺寸、顯示尺寸,以及UIImageView的 frame。 - 計算檢視和影像的解析度時,分別用它們各自的寬度除以自身的高度。
- 根據兩個解析度之中較大的一個來決定縮放比例。如果檢視比較大,就根據高度進行縮放;反之,則根據寬度進行縮放。
- 這個方法會計算寬度和高度。frame 的寬和高會乘以縮放比例,從而算出縮放後的寬和高。
- frame 的原點也必須進行縮放。不然的話,就算外框的尺寸搞對了,它也會位於偏離(文字)中心的錯誤位置。
- 新原點的計算方法是,用縮放比例乘以未縮放的原點,再加上 X 和 Y 點的縮放值。
- 返回經過縮放、依照計算出的原點和尺寸配置好的
CGRect。
有了縮放好的 CGRect,就可以大大提升你的繪製技能,達到 sgraffito 的水平啦。對的,我就是要教你個新單詞,下次玩 Scrabble 填字遊戲的時候可要謝謝我呀。
前往 ScaledElementProcessor.swift 中的 process(in:callback:),修改最內層的 for 迴圈,讓它使用下面的程式碼:
for element in line.elements {
let frame = self.createScaledFrame(
featureFrame: element.frame,
imageSize: image.size,
viewFrame: imageView.frame)
let shapeLayer = self.createShapeLayer(frame: frame)
let scaledElement = ScaledElement(frame: frame, shapeLayer: shapeLayer)
scaledElements.append(scaledElement)
}
複製程式碼剛剛加入的線條會建立一個縮放好的 frame,而程式碼會使用外框建立位置正確的形狀圖層。
編譯 App,然後執行。frame 應該出現在正確的地方啦。你真是個繪框大師呢。

預設圖片我們已經玩夠了,是時候出門找點實物練手啦!
用照相機拍照
專案已經包含設定好的相機及相簿選圖程式碼,它們位於 ViewController.swift 底部的一個擴充套件裡。如果你現在就用用看,你會發現 frame 全都會錯位。這是因為 App 還在使用預載影像中的 frame。你要移除這些舊 frame,然後在拍攝或者選取照片的時候繪製新的 frame。
把下面的方法新增到 ViewController:
private func removeFrames() {
guard let sublayers = frameSublayer.sublayers else { return }
for sublayer in sublayers {
sublayer.removeFromSuperlayer()
}
}
複製程式碼這個方法使用 for 迴圈移除 frame 子圖層中的所有子圖層。這樣你在處理接下來的照片時,才會有一張乾淨的畫布。
為了完善檢測程式碼,我們在 ViewController 中加入下面的新方法:
// 1
private func drawFeatures(
in imageView: UIImageView,
completion: (() -> Void)? = nil
) {
// 2
removeFrames()
processor.process(in: imageView) { text, elements in
elements.forEach() { element in
self.frameSublayer.addSublayer(element.shapeLayer)
}
self.scannedText = text
// 3
completion?()
}
}
複製程式碼程式碼有以下改動:
- 這個方法會接收
UIImageView和回撥,這樣你就能知道什麼時候完成了。 - frame 會在處理新影像之前自動被移除。
- 所有工作都完成後,觸發完成回撥。
現在,用下面的程式碼,替換掉 viewDidLoad() 中對 processor.process(in:callback:) 的呼叫:
drawFeatures(in: imageView)
複製程式碼向下滾動到類擴充套件的位置,找出 imagePickerController(_:didFinishPickingMediaWithInfo:)。在 if 段落的底部,imageView.image = pickedImage 的後面加入這一行程式碼:
drawFeatures(in: imageView)
複製程式碼拍攝或者選取新照片的時候,這段程式碼可以確保將之前繪製的 frame 移除,再用新照片的 frame 進行替換。
編譯 App,然後執行。如果你是用真實裝置執行(而不是模擬器的話),拍一副帶文字的照片吧。這時或許會出現奇怪的結果:

這是怎麼啦?
上面是影像朝向出問題了,所以我們馬上就來講講影像朝向。
處理影像的朝向
這個 App 是鎖定於豎向模式的。在裝置旋轉方向的時候重繪 frame 很麻煩。目前的話,還是給使用者設定一些限制,這樣做起來比較簡單。
有這條限制,使用者就必須拍攝縱向照片。UICameraPicker 會在幕後將縱向照片旋轉 90 度。你不會看見旋轉過程,因為 UIImageView 會幫你旋轉成原來的樣子。但是,文字檢測器所獲取的,則是旋轉後的 UIImage。

這樣就會出現讓人困惑的結果。ML Kit 可以讓你在 VisionMetadata 物件中設定照片的朝向。設定正確的朝向,App 就會返回正確的文字,但是 frame 還是依照旋轉後的圖片繪製的。

所以呢,你需要處理照片朝向的問題,讓它總是“朝上”。本專案包含一個名為 +UIImage.swift 的擴充套件。這個擴充套件會在 UIImage 加入一個方法,它可以將任何照片的朝向更改為縱向。影像的朝向擺正之後,整個 App 就可以順暢執行啦。
開啟 ViewController.swift,在 imagePickerController(_:didFinishPickingMediaWithInfo:) 之中,用下面的程式碼替換掉 imageView.image = pickedImage:
// 1
let fixedImage = pickedImage.fixOrientation()
// 2
imageView.image = fixedImage
複製程式碼改動有兩點:
- 把剛剛選中的影像
pickedImage旋轉到朝上的位置。 - 然後,將旋轉好的影像分配到
imageView。
編譯 App,然後執行。再拍一次照。這次所有東西的位置應該都沒問題了。

分享文字
最後一步你什麼都不用做。是不是棒棒噠?這個 App 已經整合了 UIActivityViewController。去看看 shareDidTouch():
@IBAction func shareDidTouch(_ sender: UIBarButtonItem) {
let vc = UIActivityViewController(
activityItems: [textView.text, imageView.image!],
applicationActivities: [])
present(vc, animated: true, completion: nil)
}
複製程式碼這裡所做的只有兩步,很簡單。建立一個包含掃描所得文字及影像的 UIActivityViewController。然後呼叫 present(),剩下的讓使用者搞定就可以了。
之後可以乾點啥?
恭喜!你已經是一名機器學習開發者啦!點選本文頁首或者文末的 Download Materials 按鈕,可以取得完整版本的 Extractor。不過要注意的是,下載最終版本的專案檔案之後,還需要新增你自己的 GoogleService-Info.plist;這點我在上文也說過啦。你也需要依據你在 Firebase 控制檯中的設定,將 bundle ID 更改為合適的值。
在這個教程裡,你做到了:
- 開發具有文字檢測功能的照相 app,從中學習 ML Kit 的基礎知識。
- 搞懂 ML Kit 的文字識別 API、影像縮放和影像方向。
而且你不需要拿到機器學習的博士學位就做到啦 :]
如果你想再多多瞭解 Firebase 和 ML Kit,請查閱 官方文件。
如果你對這份 Firebase 教程、Firebase、ML Kit 或者示例 App 有任何意見或疑問,歡迎你加入到下面的討論中!
如果發現譯文存在錯誤或其他需要改進的地方,歡迎到 掘金翻譯計劃 對譯文進行修改並 PR,也可獲得相應獎勵積分。文章開頭的 本文永久連結 即為本文在 GitHub 上的 MarkDown 連結。
掘金翻譯計劃 是一個翻譯優質網際網路技術文章的社群,文章來源為 掘金 上的英文分享文章。內容覆蓋 Android、iOS、前端、後端、區塊鏈、產品、設計、人工智慧等領域,想要檢視更多優質譯文請持續關注 掘金翻譯計劃、官方微博、知乎專欄。