原作者
Nathan Jennings 是 Real Python 教程團隊的一員,他在很早之前就使用 C 語言開始了自己的程式設計生涯,但是最終發現了 Python,從 Web 應用和網路資料收集到網路安全,他喜歡任何 Pythonic 的東西 —— realpython
譯者注
譯者 是一名前端工程師,平常會寫很多的 JavaScript。但是當我使用 JavaScript 很長一段時間後,會對一些 語言無關 的程式設計概念感興趣,比如:網路/socket 程式設計、非同步/併發、線/程式通訊等。然而恰好這些內容在 JavasScript 領域很少見
因為一直從事 Web 開發,所以我認為理解了網路通訊及其 socket 程式設計就理解了 Web 開發的某些本質。過程中我發現 Python 社群有很多我喜歡的內容,並且很多都是高質量的公開發布且開源的。
最近我發現了這篇文章,系統地從底層網路通訊講到了應用層協議及其 C/S 架構的應用程式,由淺入深。雖然程式碼、API 使用了 Python,但是底層原理相通。非常值得一讀,推薦給大家
另外,由於本人水平所限,翻譯的內容難免出現偏差,如果你在閱讀的過程中發現問題,請毫不猶豫的提醒我或者開新 PR。或者有什麼不理解的地方也可以開 issue 討論,當然 star 也是歡迎的
開始
網路中的 Socket 和 Socket API 是用來跨網路的訊息傳送的,它提供了 程式間通訊(IPC) 的一種形式。網路可以是邏輯的、本地的電腦網路,或者是可以物理連線到外網的網路,並且可以連線到其它網路。英特網就是一個明顯的例子,就是那個你通過 ISP 連線到的網路
本篇教程有三個不同的迭代階段,來展示如何使用 Python 構建一個 Socket 伺服器和客戶端
- 我們將以一個簡單的 Socket 伺服器和客戶端程式來開始本教程
- 當你看完 API 瞭解例子是怎麼執行起來以後,我們將會看到一個具有同時處理多個連線能力的例子的改進版
- 最後,我們將會開發出一個更加完善且具有完整的自定義頭資訊和內容的 Socket 應用
教程結束後,你將學會如何使用 Python 中的 socket 模組 來寫一個自己的客戶端/伺服器應用。以及向你展示如何在你的應用中使用自定義類在不同的端之間傳送訊息和資料
所有的例子程式都使用 Python 3.6 編寫,你可以在 Github 上找到 原始碼
網路和 Socket 是個很大的話題。網上已經有了關於它們的字面解釋,如果你還不是很瞭解 Socket 和網路。當你你讀到那些解釋的時候會感到不知所措,這是非常正常的。因為我也是這樣過來的
儘管如此也不要氣餒。 我已經為你寫了這個教程。 就像學習 Python 一樣,我們可以一次學習一點。用你的瀏覽器儲存本頁面到書籤,以便你學習下一部分時能找到
讓我們開始吧!
背景
Socket 有一段很長的歷史,最初是在 1971 年被用於 ARPANET,隨後就成了 1983 年釋出的 Berkeley Software Distribution (BSD) 作業系統的 API,並且被命名為 Berkeleysocket
當網際網路在 20 世紀 90 年代隨全球資訊網興起時,網路程式設計也火了起來。Web 服務和瀏覽器並不是唯一使用新的連線網路和 Socket 的應用程式。各種型別不同規模的客戶端/伺服器應用都廣泛地使用著它們
時至今日,儘管 Socket API 使用的底層協議已經進化了很多年,也出現了許多新的協議,但是底層的 API 仍然保持不變
Socket 應用最常見的型別就是 客戶端/伺服器 應用,伺服器用來等待客戶端的連結。我們教程中涉及到的就是這類應用。更明確地說,我們將看到用於 InternetSocket 的 Socket API,有時稱為 Berkeley 或 BSD Socket。當然也有 Unix domain sockets —— 一種用於 同一主機 程式間的通訊
Socket API 概覽
Python 的 socket 模組提供了使用 Berkeley sockets API 的介面。這將會在我們這個教程裡使用和討論到
主要的用到的 Socket API 函式和方法有下面這些:
socket()bind()listen()accept()connect()connect_ex()send()recv()close()
Python 提供了和 C 語言一致且方便的 API。我們將在下面一節中用到它們
作為標準庫的一部分,Python 也有一些類可以讓我們方便的呼叫這些底層 Socket 函式。儘管這個教程中並沒有涉及這部分內容,你也可以通過socketserver 模組 中找到文件。當然還有很多實現了高層網路協議(比如:HTTP, SMTP)的的模組,可以在下面的連結中查到 Internet Protocols and Support
TCP Sockets
就如你馬上要看到的,我們將使用 socket.socket() 建立一個型別為 socket.SOCK_STREAM 的 socket 物件,預設將使用 Transmission Control Protocol(TCP) 協議,這基本上就是你想使用的預設值
為什麼應該使用 TCP 協議?
- 可靠的:網路傳輸中丟失的資料包會被檢測到並重新傳送
- 有序傳送:資料按傳送者寫入的順序被讀取
相反,使用 socket.SOCK_DGRAM 建立的 使用者資料包協議(UDP) Socket 是 不可靠 的,而且資料的讀取寫傳送可以是 無序的
為什麼這個很重要?網路總是會盡最大的努力去傳輸完整資料(往往不盡人意)。沒法保證你的資料一定被送到目的地或者一定能接收到別人傳送給你的資料
網路裝置(比如:路由器、交換機)都有頻寬限制,或者系統本身的極限。它們也有 CPU、記憶體、匯流排和介面包緩衝區,就像我們的客戶端和伺服器。TCP 消除了你對於丟包、亂序以及其它網路通訊中通常出現的問題的顧慮
下面的示意圖中,我們將看到 Socket API 的呼叫順序和 TCP 的資料流:
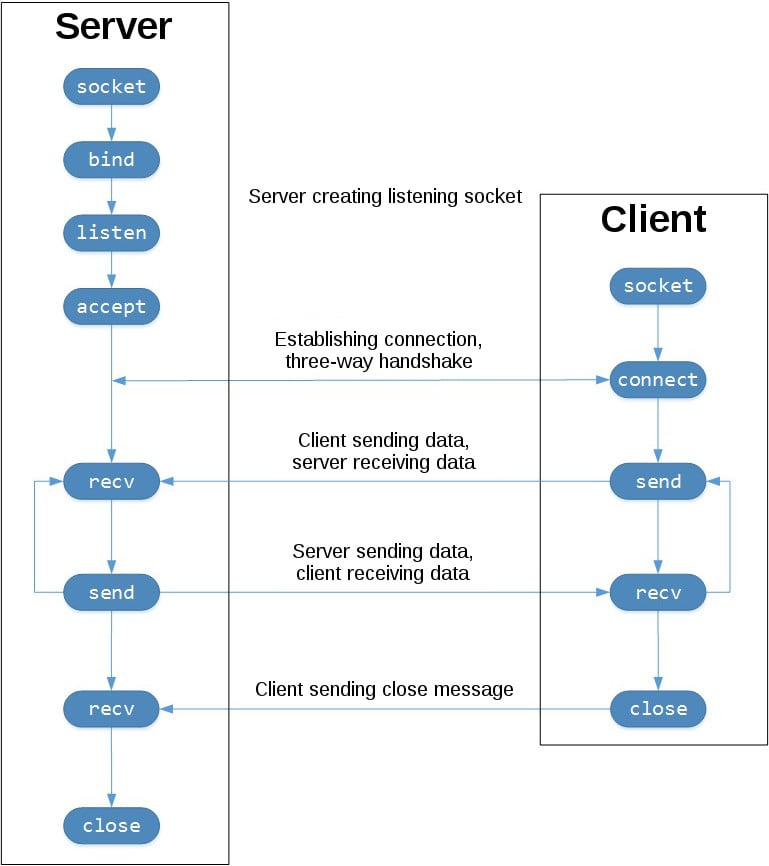
左邊表示伺服器,右邊則是客戶端
左上方開始,注意伺服器建立「監聽」Socket 的 API 呼叫:
socket()bind()listen()accept()
「監聽」Socket 做的事情就像它的名字一樣。它會監聽客戶端的連線,當一個客戶端連線進來的時候,伺服器將呼叫 accept() 來「接受」或者「完成」此連線
客戶端呼叫 connect() 方法來建立與伺服器的連結,並開始三次握手。握手很重要是因為它保證了網路的通訊的雙方可以到達,也就是說客戶端可以正常連線到伺服器,反之亦然
上圖中間部分往返部分表示客戶端和伺服器的資料交換過程,呼叫了 send() 和 recv()方法
下面部分,客戶端和伺服器呼叫 close() 方法來關閉各自的 socket
列印客戶端和服務端
你現在已經瞭解了基本的 socket API 以及客戶端和伺服器是如何通訊的,讓我們來建立一個客戶端和伺服器。我們將會以一個簡單的實現開始。伺服器將列印客戶端傳送回來的內容
列印程式服務端
下面就是伺服器程式碼,echo-server.py:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#!/usr/bin/env python3 import socket HOST = '127.0.0.1' # 標準的迴環地址 (localhost) PORT = 65432 # 監聽的埠 (非系統級的埠: 大於 1023) with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.bind((HOST, PORT)) s.listen() conn, addr = s.accept() with conn: print('Connected by', addr) while True: data = conn.recv(1024) if not data: break conn.sendall(data) |
注意:上面的程式碼你可能還沒法完全理解,但是不用擔心。這幾行程式碼做了很多事情,這 只是一個起點,幫你看見這個簡單的伺服器是如何執行的 教程後面有引用部分,裡面有很多額外的引用資源連結,這個教程中我將把連結放在那兒
讓我們一起來看一下 API 呼叫以及發生了什麼
socket.socket() 建立了一個 socket 物件,並且支援 context manager type,你可以使用 with 語句,這樣你就不用再手動呼叫 s.close() 來關閉 socket 了
|
1 2 |
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: pass # Use the socket object without calling s.close(). |
呼叫 socket() 時傳入的 socket 地址族引數 socket.AF_INET 表示因特網 IPv4 地址族,SOCK_STREAM 表示使用 TCP 的 socket 型別,協議將被用來在網路中傳輸訊息
bind() 用來關聯 socket 到指定的網路介面(IP 地址)和埠號:
|
1 2 3 4 5 6 |
HOST = '127.0.0.1' PORT = 65432 # ... s.bind((HOST, PORT)) |
bind() 方法的入參取決於 socket 的地址族,在這個例子中我們使用了 socket.AF_INET (IPv4),它將返回兩個元素的元組:(host, port)
host 可以是主機名稱、IP 地址、空字串,如果使用 IP 地址,host 就應該是 IPv4 格式的字串,127.0.0.1 是標準的 IPv4 迴環地址,只有主機上的程式可以連線到伺服器,如果你傳了空字串,伺服器將接受本機所有可用的 IPv4 地址
埠號應該是 1-65535 之間的整數(0是保留的),這個整數就是用來接受客戶端連結的 TCP 埠號,如果埠號小於 1024,有的作業系統會要求管理員許可權
使用 bind() 傳參為主機名稱的時候需要注意:
如果你在 host 部分 主機名稱 作為 IPv4/v6 socket 的地址,程式可能會產生非確 定性的行為,因為 Python 會使用 DNS 解析後的 第一個 地址,根據 DNS 解析的結 果或者 host 配置 socket 地址將會以不同方式解析為實際的 IPv4/v6 地址。如果想得 到確定的結果傳入的 host 引數建議使用數字格式的地址 引用
我稍後將在 使用主機名 部分討論這個問題,但是現在也值得一提。目前來說你只需要知道當使用主機名時,你將會因為 DNS 解析的原因得到不同的結果
可能是任何地址。比如第一次執行程式時是 10.1.2.3,第二次是 192.168.0.1,第三次是 172.16.7.8 等等
繼續看上面的伺服器程式碼示例,listen() 方法呼叫使伺服器可以接受連線請求,這使它成為一個「監聽中」的 socket
|
1 2 |
s.listen() conn, addr = s.accept() |
listen() 方法有一個 backlog 引數。它指定在拒絕新的連線之前系統將允許使用的 未接受的連線 數量。從 Python 3.5 開始,這是可選引數。如果不指定,Python 將取一個預設值
如果你的伺服器需要同時接收很多連線請求,增加 backlog 引數的值可以加大等待連結請求佇列的長度,最大長度取決於作業系統。比如在 Linux 下,參考 /proc/sys/net/core/somaxconn
accept() 方法阻塞並等待傳入連線。當一個客戶端連線時,它將返回一個新的 socket 物件,物件中有表示當前連線的 conn 和一個由主機、埠號組成的 IPv4/v6 連線的元組,更多關於元組值的內容可以檢視 socket 地址族 一節中的詳情
這裡必須要明白我們通過呼叫 accept() 方法擁有了一個新的 socket 物件。這非常重要,因為你將用這個 socket 物件和客戶端進行通訊。和監聽一個 socket 不同的是後者只用來授受新的連線請求
|
1 2 3 4 5 6 7 8 |
conn, addr = s.accept() with conn: print('Connected by', addr) while True: data = conn.recv(1024) if not data: break conn.sendall(data) |
從 accept() 獲取客戶端 socket 連線物件 conn 後,使用一個無限 while 迴圈來阻塞呼叫 conn.recv(),無論客戶端傳過來什麼資料都會使用 conn.sendall() 列印出來
如果 conn.recv() 方法返回一個空 byte 物件(b''),然後客戶端關閉連線,迴圈結束,with 語句和 conn 一起使用時,通訊結束的時候會自動關閉 socket 連結
列印程式客戶端
現在我們來看下客戶端的程式,echo-client.py:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#!/usr/bin/env python3 import socket HOST = '127.0.0.1' # 伺服器的主機名或者 IP 地址 PORT = 65432 # 伺服器使用的埠 with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.connect((HOST, PORT)) s.sendall(b'Hello, world') data = s.recv(1024) print('Received', repr(data)) |
與伺服器程式相比,客戶端程式簡單很多。它建立了一個 socket 物件,連線到伺服器並且呼叫 s.sendall() 方法傳送訊息,然後再呼叫 s.recv() 方法讀取伺服器返回的內容並列印出來
執行列印程式的客戶端和服務端
讓我們執行列印程式的客戶端和服務端,觀察他們的表現,看看發生了什麼事情
如果你在執行示例程式碼時遇到了問題,可以閱讀 如何使用 Python 開發命令列命令,如果 你使用的是 windows 作業系統,請檢視 Python Windows FAQ
開啟命令列程式,進入你的程式碼所在的目錄,執行列印程式的服務端:
|
1 |
$ ./echo-server.py |
你的命令列將被掛起,因為程式有一個阻塞呼叫
|
1 |
conn, addr = s.accept() |
它將等待客戶端的連線,現在再開啟一個命令列視窗執行列印程式的客戶端:
|
1 2 |
$ ./echo-client.py Received b'Hello, world' |
在服務端的視窗你將看見:
|
1 2 |
$ ./echo-server.py Connected by ('127.0.0.1', 64623) |
上面的輸出中,服務端列印出了 s.accept() 返回的 addr 元組,這就是客戶端的 IP 地址和 TCP 埠號。示例中的埠號是 64623 這很可能是和你機器上執行的結果不同
檢視 socket 狀態
想查詢你主機上 socket 的當前狀態,可以使用 netstat 命令。這個命令在 macOS, Window, Linux 系統上預設可用
下面這個就是啟動服務後 netstat 命令的輸出結果:
|
1 2 3 4 |
$ netstat -an Active Internet connections (including servers) Proto Recv-Q Send-Q Local Address Foreign Address (state) tcp4 0 0 127.0.0.1.65432 *.* LISTEN |
注意本地地址是 127.0.0.1.65432,如果 echo-server.py 檔案中 HOST 設定成空字串 '' 的話,netstat 命令將顯示如下:
|
1 2 3 4 |
$ netstat -an Active Internet connections (including servers) Proto Recv-Q Send-Q Local Address Foreign Address (state) tcp4 0 0 *.65432 *.* LISTEN |
本地地址是 *.65432,這表示所有主機支援的 IP 地址族都可以接受傳入連線,在我們的例子裡面呼叫 socket() 時傳入的引數 socket.AF_INET 表示使用了 IPv4 的 TCP socket,你可以在輸出結果中的 Proto 列中看到(tcp4)
上面的輸出是我擷取的只顯示了我們們的列印程式服務端程式,你可能會看到更多輸出,具體取決於你執行的系統。需要注意的是 Proto, Local Address 和 state 列。分別表示 TCP socket 型別、本地地址埠、當前狀態
另外一個檢視這些資訊的方法是使用 lsof 命令,這個命令在 macOS 上是預設安裝的,Linux 上需要你手動安裝
|
1 2 3 |
$ lsof -i -n COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME Python 67982 nathan 3u IPv4 0xecf272 0t0 TCP *:65432 (LISTEN) |
isof 命令使用 -i 引數可以檢視開啟的 socket 連線的 COMMAND, PID(process id) 和 USER(user id),上面的輸出就是列印程式服務端
netstat 和 isof 命令有許多可用的引數,這取決於你使用的作業系統。可以使用 man page 來檢視他們的使用文件,這些文件絕對值得花一點時間去了解,你將受益匪淺,macOS 和 Linux 中使用命令 man netstat 或者 man lsof 命令,windows 下使用 netstat /? 來檢視幫助文件
一個通常會犯的錯誤是在沒有監聽 socket 埠的情況下嘗試連線:
|
1 2 3 4 5 |
$ ./echo-client.py Traceback (most recent call last): File "./echo-client.py", line 9, in s.connect((HOST, PORT)) ConnectionRefusedError: [Errno 61] Connection refused |
也可能是埠號出錯、服務端沒啟動或者有防火牆阻止了連線,這些原因可能很難記住,或許你也會碰到 Connection timed out 的錯誤,記得給你的防火牆新增允許我們使用的埠規則
引用部分有一些常見的 錯誤
通訊的流程分解
讓我們再仔細的觀察下客戶端是如何與服務端進行通訊的:
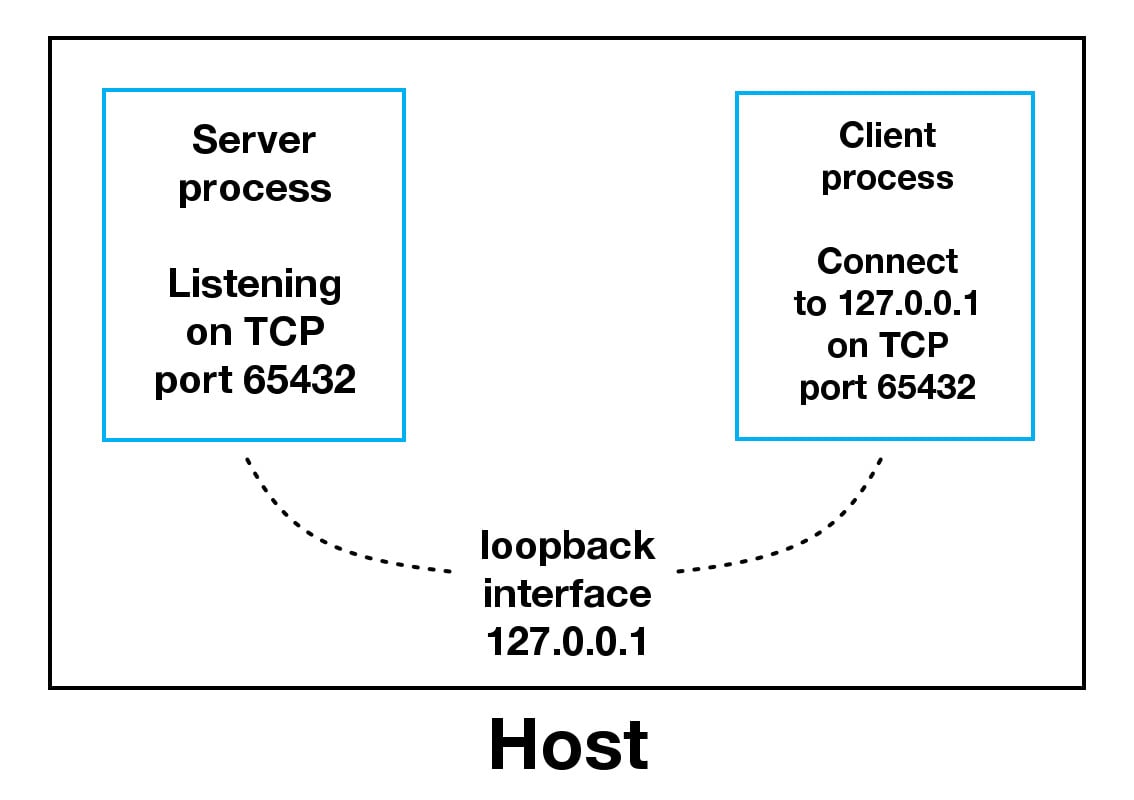
當使用迴環地址時,資料將不會接觸到外部網路,上圖中,迴環地址包含在了 host 裡面。這就是迴環地址的本質,連線資料傳輸是從本地到主機,這就是為什麼你會聽到有迴環地址或者 127.0.0.1、::1 的 IP 地址和表示本地主機
應用程式使用迴環地址來與主機上的其它程式通訊,這使得它與外部網路安全隔離。由於它是內部的,只能從主機內訪問,所以它不會被暴露出去
如果你的應用程式伺服器使用自己的專用資料庫(非公用的),則可以配置伺服器僅監聽迴環地址,這樣的話網路上的其它主機就無法連線到你的資料庫
如果你的應用程式中使用的 IP 地址不是 127.0.0.1 或者 ::1,那就可能會繫結到連線到外部網路的乙太網上。這就是你通往 localhost 王國之外的其他主機的大門
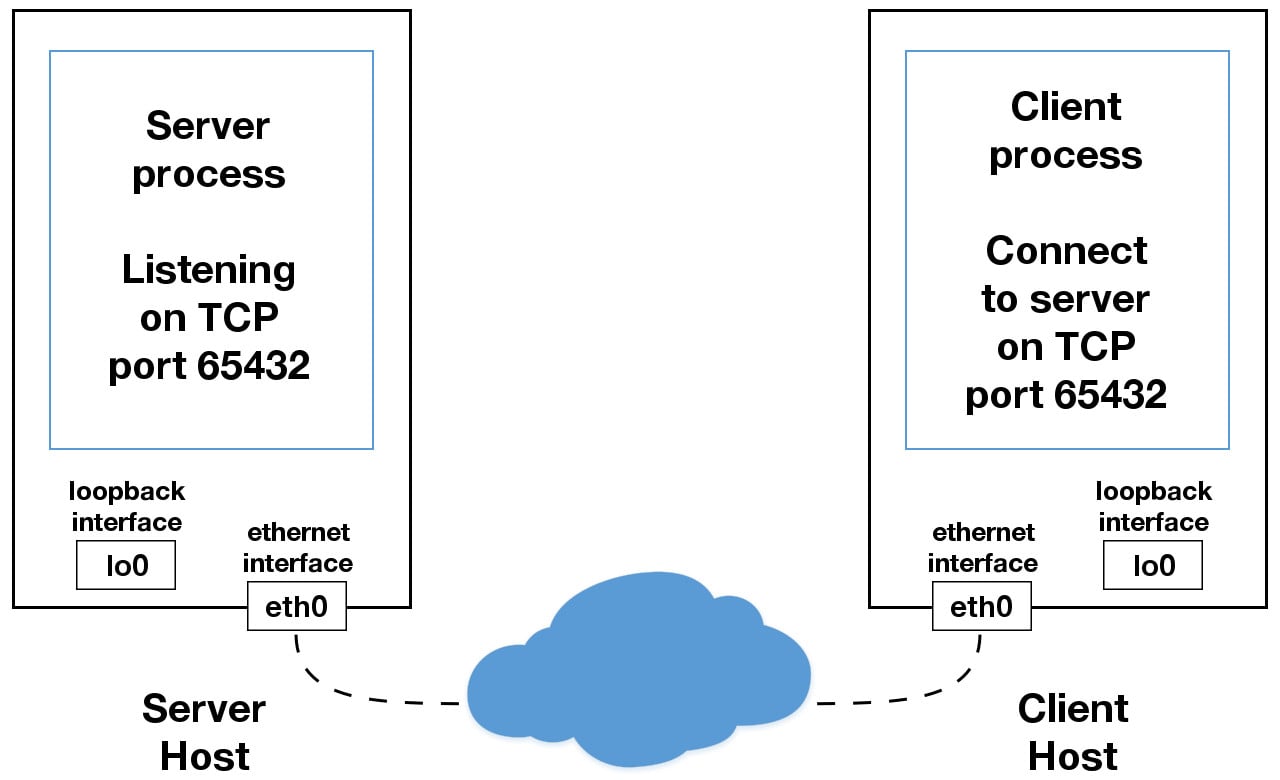
這裡需要小心,並且可能讓你感到難受甚至懷疑全世界。在你探索 localhost 的安全限制之前,確認讀過 使用主機名 一節。 一個安全注意事項是 不要使用主機名,要使用 IP 地址
處理多個連線
列印程式的服務端肯定有它自己的一些侷限。這個程式只能服務於一個客戶端然後結束。列印程式的客戶端也有它自己的侷限,但是還有一個問題,如果客戶端呼叫了下面的方法s.recv() 方法將返回 b'Hello, world' 中的一個位元組 b'H'
|
1 |
data = s.recv(1024) |
1024 是緩衝區資料大小限制最大值引數 bufsize,並不是說 recv() 方法只返回 1024個位元組的內容
send() 方法也是這個原理,它返回傳送內容的位元組數,結果可能小於傳入的傳送內容,你得處理這處情況,按需多次呼叫 send() 方法來傳送完整的資料
應用程式負責檢查是否已傳送所有資料;如果僅傳輸了一些資料,則應用程式需要嘗試傳 遞剩餘資料 引用
我們可以使用 sendall() 方法來回避這個過程
和 send() 方法不一樣的是,
sendall()方法會一直髮送位元組,只到所有的資料傳輸完成 或者中途出現錯誤。成功的話會返回 None 引用
到目前為止,我們有兩個問題:
- 如何同時處理多個連線請求
- 我們需要一直呼叫
send()或者recv()直到所有資料傳輸完成
應該怎麼做呢,有很多方式可以實現併發。最近,有一個非常流程的庫叫做 Asynchronous I/O 可以實現,asyncio 庫在 Python 3.4 後預設新增到了標準庫裡面。傳統的方法是使用執行緒
併發的問題是很難做到正確,有許多細微之處需要考慮和防範。可能其中一個細節的問題都會導致整個程式崩潰
我說這些並不是想嚇跑你或者讓你遠離學習和使用併發程式設計。如果你想讓程式支援大規模使用,使用多處理器、多核是很有必要的。然而在這個教程中我們將使用比執行緒更傳統的方法使得邏輯更容易推理。我們將使用一個非常古老的系統呼叫:select()
select() 允許你檢查多個 socket 的 I/O 完成情況,所以你可以使用它來檢測哪個 socket I/O 是就緒狀態從而執行讀取或寫入操作,但是這是 Python,總會有更多其它的選擇,我們將使用標準庫中的selectors 模組,所以我們使用了最有效的實現,不用在意你使用的作業系統:
這個模組提供了高層且高效的 I/O 多路複用,基於原始的
select模組構建,推薦用 戶使用這個模組,除非他們需要精確到作業系統層面的使用控制 引用
儘管如此,使用 select() 也無法併發執行。這取決於您的工作負載,這種實現仍然會很快。這也取決於你的應用程式對連線所做的具體事情或者它需要支援的客戶端數量
asyncio 使用單執行緒來處理多工,使用事件迴圈來管理任務。通過使用 select(),我們可以建立自己的事件迴圈,更簡單且同步化。當使用多執行緒時,即使要處理併發的情況,我們也不得不面臨使用 CPython 或者 PyPy 中的「全域性解析器鎖 GIL」,這有效地限制了我們可以並行完成的工作量
說這些是為了解析為什麼使用 select() 可能是個更好的選擇,不要覺得你必須使用 asyncio、執行緒或最新的非同步庫。通常,在網路應用程式中,你的應用程式就是 I/O 繫結:它可以在本地網路上,網路另一端的端,磁碟上等待
如果你從客戶端收到啟動 CPU 繫結工作的請求,檢視 concurrent.futures模組,它包含一個 ProcessPoolExecutor 類,用來非同步執行程式池中的呼叫
如果你使用多程式,你的 Python 程式碼將被作業系統並行地在不同處理器或者核心上排程執行,並且沒有全域性解析器鎖。你可以通過 Python 大會上的演講 John Reese – Thinking Outside the GIL with AsyncIO and Multiprocessing – PyCon 2018 來了解更多的想法
在下一節中,我們將介紹解決這些問題的伺服器和客戶端的示例。他們使用 select() 來同時處理多連線請求,按需多次呼叫 send() 和 recv()
多連線的客戶端和服務端
下面兩節中,我們將使用 selectors 模組中的 selector 物件來建立一個可以同時處理多個請求的客戶端和服務端
多連線的服務端
首頁,我們來看眼多連線服務端程式的程式碼,multiconn-server.py。這是開始建立監聽 socket 部分
|
1 2 3 4 5 6 7 8 9 |
import selectors sel = selectors.DefaultSelector() # ... lsock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) lsock.bind((host, port)) lsock.listen() print('listening on', (host, port)) lsock.setblocking(False) sel.register(lsock, selectors.EVENT_READ, data=None) |
這個程式和之前列印程式服務端最大的不同是使用了 lsock.setblocking(False) 配置 socket 為非阻塞模式,這個 socket 的呼叫將不在是阻塞的。當它和 sel.select() 一起使用的時候(下面會提到),我們就可以等待 socket 就緒事件,然後執行讀寫操作
sel.register() 使用 sel.select() 為你感興趣的事件註冊 socket 監控,對於監聽 socket,我們希望使用 selectors.EVENT_READ 讀取到事件
data 用來儲存任何你 socket 中想存的資料,當 select() 返回的時候它也會返回。我們將使用 data 來跟蹤 socket 上傳送或者接收的東西
下面就是事件迴圈:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import selectors sel = selectors.DefaultSelector() # ... while True: events = sel.select(timeout=None) for key, mask in events: if key.data is None: accept_wrapper(key.fileobj) else: service_connection(key, mask) |
sel.select(timeout=None) 呼叫會阻塞直到 socket I/O 就緒。它返回一個(key, events) 元組,每個 socket 一個。key 就是一個包含 fileobj 屬性的具名元組。key.fileobj 是一個 socket 物件,mask 表示一個操作就緒的事件掩碼
如果 key.data 為空,我們就可以知道它來自於監聽 socket,我們需要呼叫 accept() 方法來授受連線請求。我們將使用一個 accept() 包裝函式來獲取新的 socket 物件並註冊到 selector 上,我們馬上就會看到
如果 key.data 不為空,我們就可以知道它是一個被接受的客戶端 socket,我們需要為它服務,接著 service_connection() 會傳入 key 和 mask 引數並呼叫,這包含了所有我們需要在 socket 上操作的東西
讓我們一起來看看 accept_wrapper() 方法做了什麼:
|
1 2 3 4 5 6 7 |
def accept_wrapper(sock): conn, addr = sock.accept() # Should be ready to read print('accepted connection from', addr) conn.setblocking(False) data = types.SimpleNamespace(addr=addr, inb=b'', outb=b'') events = selectors.EVENT_READ | selectors.EVENT_WRITE sel.register(conn, events, data=data) |
由於監聽 socket 被註冊到了 selectors.EVENT_READ 上,它現在就能被讀取,我們呼叫 sock.accept() 後立即再立即調 conn.setblocking(False) 來讓 socket 進入非阻塞模式
請記住,這是這個版本伺服器程式的主要目標,因為我們不希望它被阻塞。如果被阻塞,那麼整個伺服器在返回前都處於掛起狀態。這意味著其它 socket 處於等待狀態,這是一種 非常嚴重的 誰都不想見到的服務被掛起的狀態
接著我們使用了 types.SimpleNamespace 類建立了一個物件用來儲存我們想要的 socket 和資料,由於我們得知道客戶端連線什麼時候可以寫入或者讀取,下面兩個事件都會被用到:
|
1 |
events = selectors.EVENT_READ | selectors.EVENT_WRITE |
事件掩碼、socket 和資料物件都會被傳入 sel.register()
現在讓我們來看下,當客戶端 socket 就緒的時候連線請求是如何使用 service_connection() 來處理的
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
def service_connection(key, mask): sock = key.fileobj data = key.data if mask & selectors.EVENT_READ: recv_data = sock.recv(1024) # Should be ready to read if recv_data: data.outb += recv_data else: print('closing connection to', data.addr) sel.unregister(sock) sock.close() if mask & selectors.EVENT_WRITE: if data.outb: print('echoing', repr(data.outb), 'to', data.addr) sent = sock.send(data.outb) # Should be ready to write data.outb = data.outb[sent:] |
這就是多連線服務端的核心部分,key 就是從呼叫 select() 方法返回的一個具名元組,它包含了 socket 物件「fileobj」和資料物件。mask 包含了就緒的事件
如果 socket 就緒而且可以被讀取,mask & selectors.EVENT_READ 就為真,sock.recv() 會被呼叫。所有讀取到的資料都會被追加到 data.outb 裡面。隨後被髮送出去
注意 else: 語句,如果沒有收到任何資料:
|
1 2 3 4 5 6 |
if recv_data: data.outb += recv_data else: print('closing connection to', data.addr) sel.unregister(sock) sock.close() |
這表示客戶端關閉了它的 socket 連線,這時服務端也應該關閉自己的連線。不過別忘了先呼叫 sel.unregister() 來撤銷 select() 的監控
當 socket 就緒而且可以被讀取的時候,對於正常的 socket 應該一直是這種狀態,任何接收並被 data.outb 儲存的資料都將使用 sock.send() 方法列印出來。傳送出去的位元組隨後就會被從緩衝中刪除
|
1 |
data.outb = data.outb[sent:] |
多連線的客戶端
現在讓我們一起來看看多連線的客戶端程式,multiconn-client.py,它和服務端很相似,不一樣的是它沒有監聽連線請求,它以呼叫 start_connections() 開始初始化連線:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
messages = [b'Message 1 from client.', b'Message 2 from client.'] def start_connections(host, port, num_conns): server_addr = (host, port) for i in range(0, num_conns): connid = i + 1 print('starting connection', connid, 'to', server_addr) sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.setblocking(False) sock.connect_ex(server_addr) events = selectors.EVENT_READ | selectors.EVENT_WRITE data = types.SimpleNamespace(connid=connid, msg_total=sum(len(m) for m in messages), recv_total=0, messages=list(messages), outb=b'') sel.register(sock, events, data=data) |
num_conns 引數是從命令列讀取的,表示為伺服器建立多少個連結。就像服務端程式一樣,每個 socket 都設定成了非阻塞模式
由於 connect() 方法會立即觸發一個 BlockingIOError 異常,所以我們使用 connect_ex() 方法取代它。connect_ex() 會返回一個錯誤指示 errno.EINPROGRESS,不像 connect() 方法直接在程式中返回異常。一旦連線結束,socket 就可以進行讀寫並且通過 select() 方法返回
socket 建立完成後,我們將使用 types.SimpleNamespace 類建立想會傳送的資料。由於每個連線請求都會呼叫 socket.send(),傳送到服務端的訊息得使用 list(messages) 方法轉換成列表結構。所有你想了解的東西,包括客戶端將要傳送的、已傳送的、已接收的訊息以及訊息的總位元組數都儲存在 data 物件中
讓我們再來看看 service_connection()。基本上和服務端一樣:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
def service_connection(key, mask): sock = key.fileobj data = key.data if mask & selectors.EVENT_READ: recv_data = sock.recv(1024) # Should be ready to read if recv_data: print('received', repr(recv_data), 'from connection', data.connid) data.recv_total += len(recv_data) if not recv_data or data.recv_total == data.msg_total: print('closing connection', data.connid) sel.unregister(sock) sock.close() if mask & selectors.EVENT_WRITE: if not data.outb and data.messages: data.outb = data.messages.pop(0) if data.outb: print('sending', repr(data.outb), 'to connection', data.connid) sent = sock.send(data.outb) # Should be ready to write data.outb = data.outb[sent:] |
有一個不同的地方,客戶端會跟蹤從伺服器接收的位元組數,根據結果來決定是否關閉 socket 連線,服務端檢測到客戶端關閉則會同樣的關閉服務端的連線
執行多連線的客戶端和服務端
現在讓我們把 multiconn-server.py 和 multiconn-client.py 兩個程式跑起來。他們都使用了命令列引數,如果不指定引數可以看到引數呼叫的方法:
服務端程式,傳入主機和埠號
|
1 2 |
$ ./multiconn-server.py usage: ./multiconn-server.py |
客戶端程式,傳入啟動服務端程式時同樣的主機和埠號以及連線數量
|
1 2 |
$ ./multiconn-client.py usage: ./multiconn-client.py |
下面就是服務端程式執行起來在 65432 埠上監聽迴環地址的輸出:
|
1 2 3 4 5 6 7 8 |
$ ./multiconn-server.py 127.0.0.1 65432 listening on ('127.0.0.1', 65432) accepted connection from ('127.0.0.1', 61354) accepted connection from ('127.0.0.1', 61355) echoing b'Message 1 from client.Message 2 from client.' to ('127.0.0.1', 61354) echoing b'Message 1 from client.Message 2 from client.' to ('127.0.0.1', 61355) closing connection to ('127.0.0.1', 61354) closing connection to ('127.0.0.1', 61355) |
下面是客戶端,它建立了兩個連線請求到上面的服務端:
|
1 2 3 4 5 6 7 8 9 10 11 |
$ ./multiconn-client.py 127.0.0.1 65432 2 starting connection 1 to ('127.0.0.1', 65432) starting connection 2 to ('127.0.0.1', 65432) sending b'Message 1 from client.' to connection 1 sending b'Message 2 from client.' to connection 1 sending b'Message 1 from client.' to connection 2 sending b'Message 2 from client.' to connection 2 received b'Message 1 from client.Message 2 from client.' from connection 1 closing connection 1 received b'Message 1 from client.Message 2 from client.' from connection 2 closing connection 2 |
應用程式客戶端和服務端
多連線的客戶端和服務端程式版本與最早的原始版本相比肯定有了很大的改善,但是讓我們再進一步地解決上面「多連線」版本中的不足,然後完成最終版的實現:客戶端/伺服器應用程式
我們希望有個客戶端和服務端在不影響其它連線的情況下做好錯誤處理,顯然,如果沒有發生異常,我們的客戶端和服務端不能崩潰的一團糟。這也是到現在為止我們還沒討論的東西,我故意沒有引入錯誤處理機制因為這樣可以使之前的程式容易理解
現在你對基本的 API,非阻塞 socket、select() 等概念已經有所瞭解了。我們可以繼續新增一些錯誤處理同時討論下「房間裡面的大象」的問題,我把一些東西隱藏在了幕後。你應該還記得,我在介紹中討論到的自定義類
首先,讓我們先解決錯誤:
所有的錯誤都會觸發異常,像無效引數型別和記憶體不足的常見異常可以被丟擲;從 Python 3.3 開始,與 socket 或地址語義相關的錯誤會引發 OSError 或其子類之一的異常 引用
我們需要捕獲 OSError 異常。另外一個我沒提及的的問題是延遲,你將在文件的很多地方看見關於延遲的討論,延遲會發生而且屬於「正常」錯誤。主機或者路由器重啟、交換機埠出錯、電纜出問題或者被拔出,你應該在你的程式碼中處理好各種各樣的錯誤
剛才說的「房間裡面的大象」問題是怎麼回事呢。就像 socket.SOCK_STREAM 這個引數的字面意思一樣,當使用 TCP 連線時,你會從一個連續的位元組流讀取的資料,好比從磁碟上讀取資料,不同的是你是從網路讀取位元組流
然而,和使用 f.seek() 讀檔案不同,換句話說,沒法定位 socket 的資料流的位置,如果可以像檔案一樣定位資料流的位置(使用下標),那你就可以隨意的讀取你想要的資料
當位元組流入你的 socket 時,會需要有不同的網路緩衝區,如果想讀取他們就必須先儲存到其它地方,使用 recv() 方法持續的從 socket 上讀取可用的位元組流
相當於你從 socket 中讀取的是一塊一塊的資料,你必須使用 recv() 方法不斷的從緩衝區中讀取資料,直到你的應用確定讀取到了足夠的資料
什麼時候算「足夠」這取決於你的定義,就 TCP socket 而言,它只通過網路傳送或接收原始位元組。它並不瞭解這些原始位元組的含義
這可以讓我們定義一個應用層協議,什麼是應用層協議?簡單來說,你的應用會傳送或者接收訊息,這些訊息其實就是你的應用程式的協議
換句話說,這些訊息的長度、格式可以定義應用程式的語義和行為,這和我們之前說的從socket 中讀取位元組部分內容相關,當你使用 recv() 來讀取位元組的時候,你需要知道讀的位元組數,並且決定什麼時候算讀取完成
這些都是怎麼完成的呢?一個方法是隻讀取固定長度的訊息,如果它們的長度總是一樣的話,這樣做很容易。當你收到固定長度位元組訊息的時候,就能確定它是個完整的訊息
然而,如果你使用定長模式來傳送比較短的訊息會比較低效,因為你還得處理填充剩餘的部分,此外,你還得處理資料不適合放在一個定長訊息裡面的情況
在這個教程裡面,我們將使用一個通用的方案,很多協議都會用到它,包括 HTTP。我們將在每條訊息前面追加一個頭資訊,頭資訊中包括訊息的長度和其它我們需要的欄位。這樣做的話我們只需要追蹤頭資訊,當我們讀到頭資訊時,就可以查到訊息的長度並且讀出所有位元組然後消費它
我們將通過使用一個自定義類來實現接收文字/二進位制資料。你可以在此基礎上做出改進或者通過繼承這個類來擴充套件你的應用程式。重要的是你將看到一個例子實現它的過程
我將會提到一些關於 socket 和位元組相關的東西,就像之前討論過的。當你通過 socket 來傳送或者接收資料時,其實你傳送或者接收到的是原始位元組
如果你收到資料並且想讓它在一個多位元組解釋的上下文中使用,比如說 4-byte 的整形,你需要考慮它可能是一種不是你機器 CPU 本機的格式。客戶端或者伺服器的另外一頭可能是另外一種使用了不同的位元組序列的 CPU,這樣的話,你就得把它們轉換成你主機的本地位元組序列來使用
上面所說的位元組順序就是 CPU 的 位元組序,在引用部分的位元組序 一節可以檢視更多。我們將會利用 Unicode 字符集的優點來規避這個問題,並使用UTF-8 的方式編碼,由於 UTF-8 使用了 8位元組 編碼方式,所以就不會有位元組序列的問題
你可以檢視 Python 關於編碼與 Unicode 的 文件,注意我們只會編碼訊息的頭部。我們將使用嚴格的型別,傳送的訊息編碼格式會在頭資訊中定義。這將讓我們可以傳輸我們覺得有用的任意型別/格式資料
你可以通過呼叫 sys.byteorder 來決定你的機器的位元組序列,比如在我的英特爾筆記本上,執行下面的程式碼就可以:
|
1 2 |
$ python3 -c 'import sys; print(repr(sys.byteorder))' 'little' |
如果我把這段程式碼跑在可以模擬大位元組序 CPU「PowerPC」的虛擬機器上的話,應該是下面的結果:
|
1 2 |
$ python3 -c 'import sys; print(repr(sys.byteorder))' 'big' |
在我們的例子程式中,應用層的協議定義了使用 UTF-8 方式編碼的 Unicode 字元。對於真正傳輸訊息來說,如果需要的話你還是得手動交換位元組序列
這取決於你的應用,是否需要它來處理不同終端間的多位元組二進位制資料,你可以通過新增額外的頭資訊來讓你的客戶端或者服務端支援二進位制,像 HTTP 一樣,把頭資訊做為引數傳進去
不用擔心自己還沒搞懂上面的東西,下面一節我們看到是如果實現的
應用的協議頭
讓我們來定義一個完整的協議頭:
- 可變長度的文字
- 基於 UTF-8 編碼的 Unicode 字符集
- 使用 JSON 序列化的一個 Python 字典
其中必須具有的頭應該有以下幾個:
| 名稱 | 描述 |
|---|---|
| byteorder | 機器的位元組序列(uses sys.byteorder),應用程式可能用不上 |
| content-length | 內容的位元組長度 |
| content-type | 內容的型別,比如 text/json 或者 binary/my-binary-type |
| content-encoding | 內容的編碼型別,比如 utf-8 編碼的 Unicode 文字,二進位制資料 |
這些頭資訊告訴接收者訊息資料,這樣的話你就可以通過提供給接收者足夠的資訊讓他接收到資料的時候正確的解碼的方式向它傳送任何資料,由於頭資訊是字典格式,你可以隨意向頭資訊中新增鍵值對
傳送應用程式訊息
不過還有一個問題,由於我們使用了變長的頭資訊,雖然方便擴充套件但是當你使用 recv() 方法讀取訊息的時候怎麼知道頭資訊的長度呢
我們前面講到過使用 recv() 接收資料和如何確定是否接收完成,我說過定長的頭可能會很低效,的確如此。但是我們將使用一個比較小的 2 位元組定長的頭資訊字首來表示頭資訊的長度
你可以認為這是一種混合的傳送訊息的實現方法,我們通過傳送頭資訊長度來引導接收者,方便他們解析訊息體
為了給你更好地解釋訊息格式,讓我們來看看訊息的全貌:
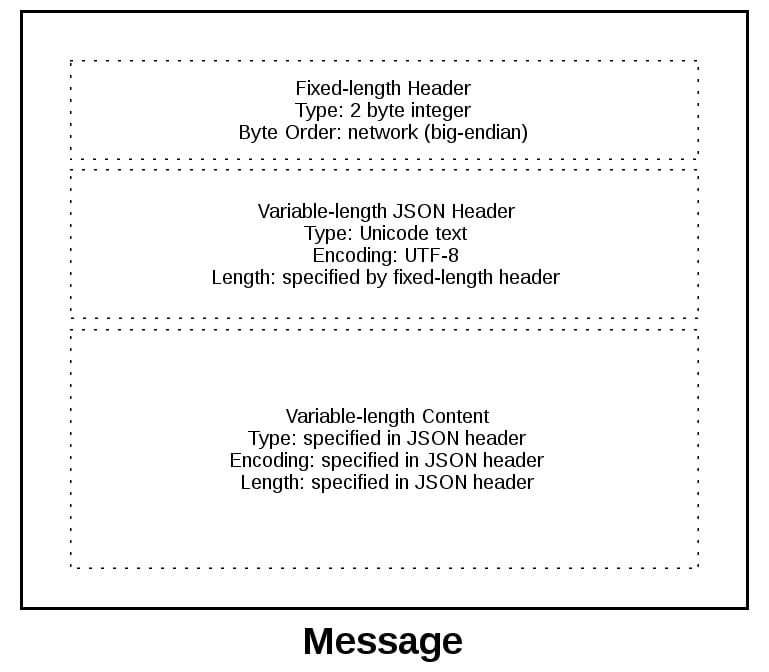
訊息以 2位元組的固定長度的頭開始,這兩個位元組是整型的網路位元組序列,表示下面的變長 JSON 頭資訊的長度,當我們從 recv() 方法讀取到 2 個位元組時就知道它表示的是頭資訊長度的整形數字,然後在解碼 JSON 頭之前讀取這麼多的位元組
JSON 頭包含了頭資訊的字典。其中一個就是 content-length,這表示訊息內容的數量(不是JSON頭),當我們使用 recv() 方法讀取到了 content-length 個位元組的資料時,就表示接收完成並且讀取到了完整的訊息
應用程式類
最後讓我們來看下成果,我們使用了一個訊息類。來看看它是如何在 socket 發生讀寫事件時與 select() 配合使用的
對於這個示例應用程式而言,我必須想出客戶端和伺服器將使用什麼型別的訊息,從這一點來講這遠遠超過了最早時候我們寫的那個玩具一樣的列印程式
為了保證程式簡單而且仍然能夠演示出它是如何在一個真正的程式中工作的,我建立了一個應用程式協議用來實現基本的搜尋功能。客戶端傳送一個搜尋請求,伺服器做一次匹配的查詢,如果客戶端的請求沒法被識別成搜尋請求,伺服器就會假定這個是二進位制請求,對應的返回二進位制響應
跟著下面一節,執行示例、用程式碼做實驗後你將會知道他是如何工作的,然後你就可以以這個訊息類為起點把他修改成適合自己使用的
就像我們之前討論的,你將在下面看到,處理 socket 時需要儲存狀態。通過使用類,我們可以將所有的狀態、資料和程式碼打包到一個地方。當連線開始或者接受的時候訊息類就會為每個 socket 建立一個例項
類中的很多包裝方法、工具方法在客戶端和服務端上都是差不多的。它們以下劃線開頭,就像 Message._json_encode() 一樣,這些方法通過類使用起來很簡單。這使得它們在其它方法中呼叫時更短,而且符合 DRY 原則
訊息類的服務端程式本質上和客戶端一樣。不同的是客戶端初始化連線併傳送請求訊息,隨後要處理服務端返回的內容。而服務端則是等待連線請求,處理客戶端的請求訊息,隨後傳送響應訊息
看起來就像這樣:
步驟 | 端 | 動作/訊息內容 :- | :- | :- 1 | 客戶端 | 傳送帶有請求內容的訊息 2 | 服務端 | 接收並處理請求訊息 3 | 服務端 | 傳送有響應內容的訊息 4 | 客戶端 | 接收並處理響應訊息
下面是程式碼的結構:
| 應用程式 | 檔案 | 程式碼 |
|---|---|---|
| 服務端 | app-server.py | 服務端主程式 |
| 服務端 | libserver.py | 服務端訊息類 |
| 客戶端 | app-client.py | 客戶端主程式 |
| 客戶端 | libclient.py | 客戶端訊息類 |
訊息入口點
我想通過首先提到它的設計方面來討論 Message 類的工作方式,不過這對我來說並不是立馬就能解釋清楚的,只有在重構它至少五次之後我才能達到它目前的狀態。為什麼呢?因為要管理狀態
當訊息物件建立的時候,它就被一個使用 selector.register() 事件監控起來的 socket 關聯起來了
|
1 2 |
message = libserver.Message(sel, conn, addr) sel.register(conn, selectors.EVENT_READ, data=message) |
注意,這一節中的一些程式碼來自服務端主程式與訊息類,但是這部分內容的討論在客戶端 也是一樣的,我將在他們之間存在不同點的時候來解釋客戶端的版本
當 socket 上的事件就緒的時候,它就會被 selector.select() 方法返回。對過 key 物件的 data 屬性獲取到 message 的引用,然後在訊息用呼叫一個方法:
|
1 2 3 4 5 6 |
while True: events = sel.select(timeout=None) for key, mask in events: # ... message = key.data message.process_events(mask) |
觀察上面的事件迴圈,可以看見 sel.select() 位於「司機位置」,它是阻塞的,在迴圈的上面等待。當 socket 上的讀寫事件就緒時,它就會為其服務。這表示間接的它也要負責呼叫 process_events() 方法。這就是我說 process_events() 方法是入口的原因
讓我們來看下 process_events() 方法做了什麼
|
1 2 3 4 5 |
def process_events(self, mask): if mask & selectors.EVENT_READ: self.read() if mask & selectors.EVENT_WRITE: self.write() |
這樣做很好,因為 process_events() 方法很簡潔,它只可以做兩件事情:呼叫 read() 和 write() 方法
這又把我們帶回了狀態管理的問題。在幾次重構後,我決定如果別的方法依賴於狀態變數裡面的某個確定值,那麼它們就只應該從 read() 和 write() 方法中呼叫,這將使處理socket 事件的邏輯儘量的簡單
可能說起來很簡單,但是經歷了前面幾次類的迭代:混合了一些方法,檢查當前狀態、依賴於其它值、在 read() 或者 write() 方法外面呼叫處理資料的方法,最後這證明了這樣管理起來很複雜
當然,你肯定需要把類按你自己的需求修改使它能夠符合你的預期,但是我建議你儘可能把狀態檢查、依賴狀態的呼叫的邏輯放在 read() 和 write() 方法裡面
讓我們來看看 read() 方法,這是服務端版本,但是客戶端也是一樣的。不同之處在於方法名稱,一個(客戶端)是 process_response() 另一個(服務端)是 process_request()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def read(self): self._read() if self._jsonheader_len is None: self.process_protoheader() if self._jsonheader_len is not None: if self.jsonheader is None: self.process_jsonheader() if self.jsonheader: if self.request is None: self.process_request() |
_read() 方法首頁被呼叫,然後呼叫 socket.recv() 從 socket 讀取資料並存入到接收緩衝區
記住,當呼叫 socket.recv() 方法時,組成訊息的所有資料並沒有一次性全部到達。socket.recv() 方法可能需要呼叫很多次,這就是為什麼在呼叫相關方法處理資料前每次都要檢查狀態
當一個方法開始處理訊息時,首頁要檢查的就是接受緩衝區儲存了足夠的多讀取的資料,如果確定,它們將繼續處理各自的資料,然後把資料存到其它流程可能會用到的變數上,並且清空自己的緩衝區。由於一個訊息有三個元件,所以會有三個狀態檢查和處理方法的呼叫:
Message Component | Method | Output – | – | – Fixed-length header | process_protoheader() | self._jsonheader_len JSON header | process_jsonheader() | self.jsonheader Content | process_request() | self.request
接下來,讓我們一起看看 write() 方法,這是服務端的版本:
|
1 2 3 4 5 6 |
def write(self): if self.request: if not self.response_created: self.create_response() self._write() |
write() 方法會首先檢測是否有請求,如果有而且響應還沒被建立的話 create_response() 方法就會被呼叫,它會設定狀態變數 response_created,然後為傳送緩衝區寫入響應
如果傳送緩衝區有資料,write() 方法會呼叫 socket.send() 方法
記住,當 socket.send() 被呼叫時,所有傳送緩衝區的資料可能還沒進入到傳送佇列,socket 的網路緩衝區可能滿了,socket.send() 可能需要重新呼叫,這就是為什麼需要檢查狀態的原因,create_response() 應該只被呼叫一次,但是 _write() 方法需要呼叫多次
客戶端的 write() 版大體與服務端一致:
|
1 2 3 4 5 6 7 8 9 10 |
def write(self): if not self._request_queued: self.queue_request() self._write() if self._request_queued: if not self._send_buffer: # Set selector to listen for read events, we're done writing. self._set_selector_events_mask('r') |
因為客戶端首頁初始化了一個連線請求到服務端,狀態變數_request_queued被檢查。如果請求還沒加入到佇列,就呼叫 queue_request() 方法建立一個請求寫入到傳送緩衝區中,同時也會使用變數 _request_queued 記錄狀態值防止多次呼叫
就像服務端一樣,如果傳送緩衝區有資料 _write() 方法會呼叫 socket.send() 方法
需要注意客戶端版本的 write() 方法與服務端不同之處在於最後的請求是否加入到佇列中的檢查,這個我們將在客戶端主程式中詳細解釋,原因是要告訴 selector.select()停止監控 socket 的寫入事件而且我們只對讀取事件感興趣,沒有辦法通知套接字是可寫的
我將在這一節中留下一個懸念,這一節的主要目的是解釋 selector.select() 方法是如何通過 process_events() 方法呼叫訊息類以及它是如何工作的
這一點很重要,因為 process_events() 方法在連線的生命週期中將被呼叫很多次,因此,要確保那些只能被呼叫一次的方法正常工作,這些方法中要麼需要檢查自己的狀態變數,要麼需要檢查呼叫者的方法中的狀態變數
服務端主程式
在服務端主程式 app-server.py 中,主機、埠引數是通過命令列傳遞給程式的:
|
1 2 |
$ ./app-server.py usage: ./app-server.py |
例如需求監聽本地迴環地址上面的 65432 埠,需要執行:
|
1 2 |
$ ./app-server.py 127.0.0.1 65432 listening on ('127.0.0.1', 65432) |
引數為空的話就可以監聽主機上的所有 IP 地址
建立完 socket 後,一個傳入引數 socket.SO_REUSEADDR 的方法 to socket.setsockopt() 將被呼叫
|
1 2 |
# Avoid bind() exception: OSError: [Errno 48] Address already in use lsock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) |
設定這個引數是為了避免 埠被佔用 的錯誤發生,如果當前程式使用的埠和之前的程式使用的一樣,你就會發現連線處於 TIME_WAIT 狀態
比如說,如果伺服器主動關閉連線,伺服器會保持為大概兩分鐘的 TIME_WAIT 狀態,具體時長取決於你的作業系統。如果你想在兩分鐘內再開啟一個服務,你將得到一個OSError 表示 埠被戰勝,這樣做是為了確保一些在途的資料包正確的被處理
事件迴圈會捕捉所有錯誤,以保證伺服器正常執行:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
while True: events = sel.select(timeout=None) for key, mask in events: if key.data is None: accept_wrapper(key.fileobj) else: message = key.data try: message.process_events(mask) except Exception: print('main: error: exception for', f'{message.addr}:\n{traceback.format_exc()}') message.close() |
當伺服器接受到一個客戶端連線時,訊息物件就會被建立:
|
1 2 3 4 5 6 |
def accept_wrapper(sock): conn, addr = sock.accept() # Should be ready to read print('accepted connection from', addr) conn.setblocking(False) message = libserver.Message(sel, conn, addr) sel.register(conn, selectors.EVENT_READ, data=message) |
訊息物件會通過 sel.register() 方法關聯到 socket 上,而且它初始化就被設定成了只監控讀事件。當請求被讀取時,我們將通過監聽到的寫事件修改它
在伺服器端採用這種方法的一個優點是,大多數情況下,當 socket 正常並且沒有網路問題時,它始終是可寫的
如果我們告訴 sel.register() 方法監控 EVENT_WRITE 寫入事件,事件迴圈將會立即喚醒並通知我們這種情況,然而此時 socket 並不用喚醒呼叫 send() 方法。由於請求還沒被處理,所以不需要發回響應。這將消耗並浪費寶貴的 CPU 週期
服務端訊息類
在訊息切入點一節中,當通過 process_events() 知道 socket 事件就緒時我們可以看到訊息物件是如何發出動作的。現在讓我們來看看當資料在 socket 上被讀取是會發生些什麼,以及為伺服器就緒的訊息的元件片段發生了什麼
libserver.py 檔案中的服務端訊息類,可以在 Github 上找到 原始碼
這些方法按照訊息處理順序出現在類中
當伺服器讀取到至少兩個位元組時,定長頭的邏輯就可以開始了
|
1 2 3 4 5 6 |
def process_protoheader(self): hdrlen = 2 if len(self._recv_buffer) >= hdrlen: self._jsonheader_len = struct.unpack('>H', self._recv_buffer[:hdrlen])[0] self._recv_buffer = self._recv_buffer[hdrlen:] |
網路位元組序列中的定長整型兩位元組包含了 JSON 頭的長度,struct.unpack() 方法用來讀取並解碼,然後儲存在 self._jsonheader_len 中,當這部分訊息被處理完成後,就要呼叫 process_protoheader() 方法來刪除接收緩衝區中處理過的訊息
就像上面的定長頭的邏輯一樣,當接收緩衝區有足夠的 JSON 頭資料時,它也需要被處理:
|
1 2 3 4 5 6 7 8 9 10 |
def process_jsonheader(self): hdrlen = self._jsonheader_len if len(self._recv_buffer) >= hdrlen: self.jsonheader = self._json_decode(self._recv_buffer[:hdrlen], 'utf-8') self._recv_buffer = self._recv_buffer[hdrlen:] for reqhdr in ('byteorder', 'content-length', 'content-type', 'content-encoding'): if reqhdr not in self.jsonheader: raise ValueError(f'Missing required header "{reqhdr}".') |
self._json_decode() 方法用來解碼並反序列化 JSON 頭成一個字典。由於我們定義的 JSON 頭是 utf-8 格式的,所以解碼方法呼叫時我們寫死了這個引數,結果將被存放在 self.jsonheader 中,process_jsonheader 方法做完他應該做的事情後,同樣需要刪除接收緩衝區中處理過的訊息
接下來就是真正的訊息內容,當接收緩衝區有 JSON 頭中定義的 content-length 值的數量個位元組時,請求就應該被處理了:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
def process_request(self): content_len = self.jsonheader['content-length'] if not len(self._recv_buffer) >= content_len: return data = self._recv_buffer[:content_len] self._recv_buffer = self._recv_buffer[content_len:] if self.jsonheader['content-type'] == 'text/json': encoding = self.jsonheader['content-encoding'] self.request = self._json_decode(data, encoding) print('received request', repr(self.request), 'from', self.addr) else: # Binary or unknown content-type self.request = data print(f'received {self.jsonheader["content-type"]} request from', self.addr) # Set selector to listen for write events, we're done reading. self._set_selector_events_mask('w') |
把訊息儲存到 data 變數中後,process_request() 又會刪除接收緩衝區中處理過的資料。接著,如果 content type 是 JSON 的話,它將解碼並反序列化資料。否則(在我們的例子中)資料將被視 做二進位制資料並列印出來
最後 process_request() 方法會修改 selector 為只監控寫入事件。在服務端的程式 app-server.py 中,socket 初始化被設定成僅監控讀事件。現在請求已經被全部處理完了,我們對讀取事件就不感興趣了
現在就可以建立一個響應寫入到 socket 中。當 socket 可寫時 create_response() 將被從 write() 方法中呼叫:
|
1 2 3 4 5 6 7 8 9 |
def create_response(self): if self.jsonheader['content-type'] == 'text/json': response = self._create_response_json_content() else: # Binary or unknown content-type response = self._create_response_binary_content() message = self._create_message(**response) self.response_created = True self._send_buffer += message |
響應會根據不同的 content type 的不同而呼叫不同的方法建立。在這個例子中,當 action == 'search' 的時候會執行一個簡單的字典查詢。你可以在這個地方新增你自己的處理方法並呼叫
一個不好處理的問題是響應寫入完成時如何關閉連線,我會在 _write() 方法中呼叫 close()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def _write(self): if self._send_buffer: print('sending', repr(self._send_buffer), 'to', self.addr) try: # Should be ready to write sent = self.sock.send(self._send_buffer) except BlockingIOError: # Resource temporarily unavailable (errno EWOULDBLOCK) pass else: self._send_buffer = self._send_buffer[sent:] # Close when the buffer is drained. The response has been sent. if sent and not self._send_buffer: self.close() |
雖然close() 方法的呼叫有點隱蔽,但是我認為這是一種權衡。因為訊息類一個連線只處理一條訊息。寫入響應後,伺服器無需執行任何操作。它的任務就完成了
客戶端主程式
客戶端主程式 app-client.py 中,引數從命令列中讀取,用來建立請求並連線到服務端
|
1 2 |
$ ./app-client.py usage: ./app-client.py |
來個示例演示一下:
|
1 |
$ ./app-client.py 127.0.0.1 65432 search needle |
當從命令列引數建立完一個字典來表示請求後,主機、埠、請求字典一起被傳給 start_connection()
|
1 2 3 4 5 6 7 8 9 |
def start_connection(host, port, request): addr = (host, port) print('starting connection to', addr) sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.setblocking(False) sock.connect_ex(addr) events = selectors.EVENT_READ | selectors.EVENT_WRITE message = libclient.Message(sel, sock, addr, request) sel.register(sock, events, data=message) |
對伺服器的 socket 連線被建立,訊息物件被傳入請求字典並建立
和服務端一樣,訊息物件在 sel.register() 方法中被關聯到 socket 上。然而,客戶端不同的是,socket 初始化的時候會監控讀寫事件,一旦請求被寫入,我們將會修改為只監控讀取事件
這種實現和服務端一樣有好處:不浪費 CPU 生命週期。請求傳送完成後,我們就不關注寫入事件了,所以不用保持狀態等待處理
客戶端訊息類
在 訊息入口點 一節中,我們看到過,當 socket 使用準備就緒時,訊息物件是如何呼叫具體動作的。現在讓我們來看看 socket 上的資料是如何被讀寫的,以及訊息準備好被加工的時候發生了什麼
客戶端訊息類在 libclient.py 檔案中,可以在 Github 上找到 原始碼
這些方法按照訊息處理順序出現在類中
客戶端的第一個任務就是讓請求入佇列:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
def queue_request(self): content = self.request['content'] content_type = self.request['type'] content_encoding = self.request['encoding'] if content_type == 'text/json': req = { 'content_bytes': self._json_encode(content, content_encoding), 'content_type': content_type, 'content_encoding': content_encoding } else: req = { 'content_bytes': content, 'content_type': content_type, 'content_encoding': content_encoding } message = self._create_message(**req) self._send_buffer += message self._request_queued = True |
用來建立請求的字典,取決於客戶端程式 app-client.py 中傳入的命令列引數,當訊息物件建立的時候,請求字典被當做引數傳入
請求訊息被建立並追加到傳送緩衝區中,訊息將被 _write() 方法傳送,狀態引數 self._request_queued 被設定,這使 queue_request() 方法不會被重複呼叫
請求傳送完成後,客戶端就等待伺服器的響應
客戶端讀取和處理訊息的方法和服務端一致,由於響應資料是從 socket 上讀取的,所以處理 header 的方法會被呼叫:process_protoheader() 和 process_jsonheader()
最終處理方法名字的不同在於處理一個響應,而不是建立:process_response(),_process_response_json_content() 和 _process_response_binary_content()
最後,但肯定不是最不重要的 —— 最終的 process_response() 呼叫:
|
1 2 3 4 |
def process_response(self): # ... # Close when response has been processed self.close() |
訊息類的包裝
我將通過提及一些方法的重要注意點來結束訊息類的討論
主程式中任意的類觸發異常都由 except 字句來處理:
|
1 2 3 4 5 6 |
try: message.process_events(mask) except Exception: print('main: error: exception for', f'{message.addr}:\n{traceback.format_exc()}') message.close() |
注意最後一行的方法 message.close()
這一行很重要的原因有很多,不僅僅是保證 socket 被關閉,而且通過呼叫 message.close() 方法刪除使用 select() 監控的 socket,這是類中的一段非常簡潔的程式碼,它能減小複雜度。如果一個異常發生或者我們自己主動丟擲,我們很清楚 close() 方法將處理善後
Message._read() 和 Message._write() 方法都包含一些有趣的東西:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def _read(self): try: # Should be ready to read data = self.sock.recv(4096) except BlockingIOError: # Resource temporarily unavailable (errno EWOULDBLOCK) pass else: if data: self._recv_buffer += data else: raise RuntimeError('Peer closed.') |
注意 except 行:except BlockingIOError:
_write() 方法也有,這幾行很重要是因為它們捕獲臨時錯誤並通過使用 pass 跳過。臨時錯誤是 socket 阻塞的時候發生的,比如等待網路響應或者連線的其它端
通過使用 pass 跳過異常,select() 方法將再次呼叫,我們將有機會重新讀寫資料
執行應用程式的客戶端和服務端
經過所有這些艱苦的工作後,讓我們把程式執行起來並找到一些樂趣!
在這個救命中,我們將傳一個空的字串做為 host 引數的值,用來監聽伺服器端的所有IP 地址。這樣的話我就可以從其它網路上的虛擬機器執行客戶端程式,我將模擬一個 PowerPC 的機器
首頁,把服務端程式執行進來:
|
1 2 |
$ ./app-server.py '' 65432 listening on ('', 65432) |
現在讓我們執行客戶端,傳入搜尋內容,看看是否能看他(墨菲斯-黑客帝國中的角色):
|
1 2 3 4 5 6 |
$ ./app-client.py 10.0.1.1 65432 search morpheus starting connection to ('10.0.1.1', 65432) sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 41}{"action": "search", "value": "morpheus"}' to ('10.0.1.1', 65432) received response {'result': 'Follow the white rabbit. ?'} from ('10.0.1.1', 65432) got result: Follow the white rabbit. ? closing connection to ('10.0.1.1', 65432) |
我的命令列 shell 使用了 utf-8 編碼,所以上面的輸出可以是 emojis
再試試看能不能搜尋到小狗:
|
1 2 3 4 5 6 |
$ ./app-client.py 10.0.1.1 65432 search ? starting connection to ('10.0.1.1', 65432) sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"action": "search", "value": "\xf0\x9f\x90\xb6"}' to ('10.0.1.1', 65432) received response {'result': '? Playing ball! ?'} from ('10.0.1.1', 65432) got result: ? Playing ball! ? closing connection to ('10.0.1.1', 65432) |
注意請求傳送行的 byte string,很容易看出來你傳送的小狗 emoji 表情被列印成了十六進位制的字串 \xf0\x9f\x90\xb6,我可以使用 emoji 表情來搜尋是因為我的命令列支援utf-8 格式的編碼
這個示例中我們傳送給網路原始的 bytes,這些 bytes 需要被接受者正確的解釋。這就是為什麼之前需要給訊息附加頭資訊並且包含編碼型別欄位的原因
下面這個是伺服器對應上面兩個客戶端連線的輸出:
|
1 2 3 4 5 6 7 8 9 |
accepted connection from ('10.0.2.2', 55340) received request {'action': 'search', 'value': 'morpheus'} from ('10.0.2.2', 55340) sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 43}{"result": "Follow the white rabbit. \xf0\x9f\x90\xb0"}' to ('10.0.2.2', 55340) closing connection to ('10.0.2.2', 55340) accepted connection from ('10.0.2.2', 55338) received request {'action': 'search', 'value': '?'} from ('10.0.2.2', 55338) sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"result": "\xf0\x9f\x90\xbe Playing ball! \xf0\x9f\x8f\x90"}' to ('10.0.2.2', 55338) closing connection to ('10.0.2.2', 55338) |
注意傳送行中寫到客戶端的 bytes,這就是服務端的響應訊息
如果 action 引數不是搜尋,你也可以試試給伺服器傳送二進位制請求
|
1 2 3 4 5 6 |
$ ./app-client.py 10.0.1.1 65432 binary ? starting connection to ('10.0.1.1', 65432) sending b'\x00|{"byteorder": "big", "content-type": "binary/custom-client-binary-type", "content-encoding": "binary", "content-length": 10}binary\xf0\x9f\x98\x83' to ('10.0.1.1', 65432) received binary/custom-server-binary-type response from ('10.0.1.1', 65432) got response: b'First 10 bytes of request: binary\xf0\x9f\x98\x83' closing connection to ('10.0.1.1', 65432) |
由於請求的 content-type 不是 text/json,伺服器會把內容當成二進位制型別並且不會解碼 JSON,它只會列印 content-type 和返回的前 10 個 bytes 給客戶端
|
1 2 3 4 5 6 |
$ ./app-server.py '' 65432 listening on ('', 65432) accepted connection from ('10.0.2.2', 55320) received binary/custom-client-binary-type request from ('10.0.2.2', 55320) sending b'\x00\x7f{"byteorder": "little", "content-type": "binary/custom-server-binary-type", "content-encoding": "binary", "content-length": 37}First 10 bytes of request: binary\xf0\x9f\x98\x83' to ('10.0.2.2', 55320) closing connection to ('10.0.2.2', 55320) |
故障排除
某些東西執行不了是很常見的,你可能不知道應該怎麼做,不用擔心,所有人都會遇到這種問題,希望你藉助本教程、偵錯程式和萬能的搜尋引擎解決問題並且繼續下去
如果還是解決不了,你的第一站應該是 python 的 socket 模組文件,確保你讀過文件中每個我們使用到的方法、函式。同樣的可以從引用一節中找到一些辦法,尤其是錯誤一節中的內容
有的時候問題並不是由你的原始碼引起的,原始碼可能是正確的。有可能是不同的主機、客戶端和伺服器。也可能是網路原因,比如路由器、防火牆或者是其它網路裝置扮演了中間人的角色
對於這些型別的問題,額外的一些工具是必要的。下面這些工具或者集可能會幫到你或者至少提供一些線索
pin
ping 命令通過傳送一個 ICMP 報文來檢測主機是否連線到了網路,它直接與作業系統上的 TCP/IP 協議棧通訊,所以它在主機上是獨立於任何應用程式執行的
下面是一段在 macOS 上執行 ping 命令的結果
|
1 2 3 4 5 6 7 8 9 |
$ ping -c 3 127.0.0.1 PING 127.0.0.1 (127.0.0.1): 56 data bytes 64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=0.058 ms 64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.165 ms 64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.164 ms --- 127.0.0.1 ping statistics --- 3 packets transmitted, 3 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 0.058/0.129/0.165/0.050 ms |
注意後面的統計輸出,這對你排查間歇性的連線問題很有幫助。比如說,是否有資料包丟失?網路延遲怎麼樣(檢視訊息的往返時間)
如果你與主機之間有防火牆的話,ping 傳送的請求可能會被阻止。防火牆管理員定義了一些規則強制阻止一些請求,主要的原因就是他們不想自己的主機是可以被發現的。如果你的機器也出現這種情況的話,請確保在規則中新增了允許 ICMP 包的傳送
ICMP 是 ping 命令使用的協議,但它也是 TCP 和其他底層用於傳遞錯誤訊息的協議,如果你遇到奇怪的行為或緩慢的連線,可能就是這個原因
ICMP 訊息通過型別和代號來定義。下面有一些重要的資訊可以參考:
ICMP 型別 | ICMP 程式碼 | 說明 – | – | – 8 | 0 | 列印請求 0 | 0 | 列印回覆 3 | 0 | 目標網路不可達 3 | 1 | 目標主機不可達 3 | 2 | 目標協議不可達 3 | 3 | 目標埠不可達 3 | 4 | 需要分片,但是 DF(Don’t fragmentation) 標識已被設定 11 | 0 | 網路存在環路
檢視 Path MTU Discovery 更多關於分片和 ICMP 訊息的內容,裡面遇到的問題就是我前面提及的一些奇怪行為
netstat
在 檢視 socket 狀態 一節中我們已經知道如何使用 netstat 來檢視 socket 及其狀態的資訊。這個命令在 macOS, Linux, Windows 上都可以使用
在之前的示例中我並沒有提及 Recv-Q 和 Send-Q 列。這些列表示傳送或者接收佇列中網路緩衝區資料的位元組數,但是由於某些原因這些位元組還沒被遠端或者本地應用讀寫
換句話說,這些網路中的位元組還在作業系統的佇列中。一個原因可能是應用程式受 CPU 限制或者無法呼叫 socket.recv()、socket.send() 方法處理,或者因為其它一些網路原因導致的,比如說網路的擁堵、失敗、硬體及電纜的問題
為了復現這個問題,看看到底在錯誤發生前我應該傳送多少資料。我寫了一個測試客戶端可以連線到測試伺服器,並且重複的呼叫 socket.send() 方法。測試服務端永遠不呼叫 socket.recv() 或者 socket.send() 方法來處理客戶端傳送的資料,它只接受連線請求。這會導致伺服器上的網路緩衝區被填滿,最終會在客戶端上報錯
首先執行服務端:
|
1 |
$ ./app-server-test.py 127.0.0.1 65432 listening on ('127.0.0.1', 65432) |
然後執行客戶端,看看發生了什麼:
|
1 2 3 |
$ ./app-client-test.py 127.0.0.1 65432 binary test error: socket.send() blocking io exception for ('127.0.0.1', 65432): BlockingIOError(35, 'Resource temporarily unavailable') |
下面是用 netstat 命令在錯誤發生時執行的結果:
|
1 2 3 4 5 |
$ netstat -an | grep 65432 Proto Recv-Q Send-Q Local Address Foreign Address (state) tcp4 408300 0 127.0.0.1.65432 127.0.0.1.53225 ESTABLISHED tcp4 0 269868 127.0.0.1.53225 127.0.0.1.65432 ESTABLISHED tcp4 0 0 127.0.0.1.65432 *.* LISTEN |
第一行就表示服務端(本地埠是 65432)
|
1 2 |
Proto Recv-Q Send-Q Local Address Foreign Address (state) tcp4 408300 0 127.0.0.1.65432 127.0.0.1.53225 ESTABLISHED |
注意 Recv-Q: 408300
第二行表示客戶端(遠端埠是 65432)
|
1 2 |
Proto Recv-Q Send-Q Local Address Foreign Address (state) tcp4 0 269868 127.0.0.1.53225 127.0.0.1.65432 ESTABLISHED |
注意 Send-Q: 269868
顯然,客戶端試著寫入位元組,但是服務端並沒有讀取他們。這導致服務端網路緩衝佇列中應該儲存的資料被積壓在接收端,客戶端的網路緩衝佇列積壓到傳送端
windows
如果你使用的是 windows 電腦,有一個工具套件絕對值得安裝 Windows Sysinternals
裡面有個工具叫 TCPView.exe,它是 windows 下的一個視覺化的 netstat 工具。除了地址、埠號和 socket 狀態之外,它還會顯示傳送和接收的資料包以及位元組數。就像 Unix 工具集 lsof 命令一樣,你也可以看見程式名和 ID,可以在選單中檢視更多選項
Wireshark
有時候你可能想檢視網路底層發生了什麼,忽略應用程式的輸出或者外部庫呼叫,想看看網路層面到底收發了什麼內容,就像偵錯程式一樣,當你需要看清這些的時候,沒有別的辦法
Wireshark 是一款可以執行在 macOS, Linux, Windows 以及其它系統上的網路協議分析、流量捕獲工具,GUI 版本的程式叫做 wireshark,命令 行的程式叫做 tshark
流量捕獲是一個非常好用的方法,它可以讓你看到網路上應用程式的行為,收集到關於收發訊息多少、頻率等資訊,你也可以看到客戶端或者服務端如何關閉/取消連線,或者停止響應,當你需要排除故障的時候這些資訊非常的有用
網上還有很多關於 wireshark 和 TShark 的基礎使用教程
這有一個使用 wireshark 捕獲本地網路資料的例子:
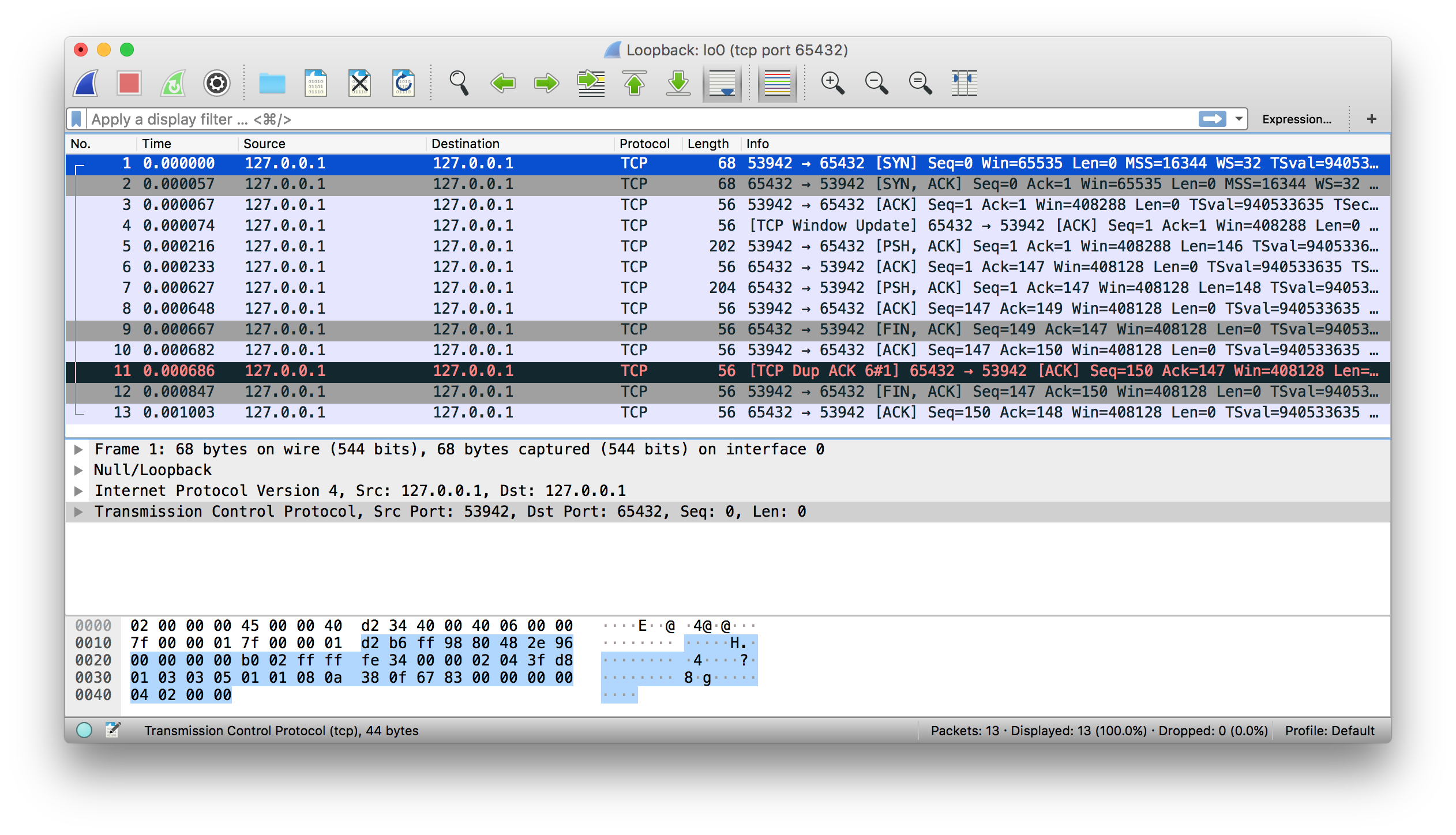
還有一個和上面一樣的使用 tshark 命令輸出的結果:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
$ tshark -i lo0 'tcp port 65432' Capturing on 'Loopback' 1 0.000000 127.0.0.1 → 127.0.0.1 TCP 68 53942 → 65432 [SYN] Seq=0 Win=65535 Len=0 MSS=16344 WS=32 TSval=940533635 TSecr=0 SACK_PERM=1 2 0.000057 127.0.0.1 → 127.0.0.1 TCP 68 65432 → 53942 [SYN, ACK] Seq=0 Ack=1 Win=65535 Len=0 MSS=16344 WS=32 TSval=940533635 TSecr=940533635 SACK_PERM=1 3 0.000068 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=940533635 TSecr=940533635 4 0.000075 127.0.0.1 → 127.0.0.1 TCP 56 [TCP Window Update] 65432 → 53942 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=940533635 TSecr=940533635 5 0.000216 127.0.0.1 → 127.0.0.1 TCP 202 53942 → 65432 [PSH, ACK] Seq=1 Ack=1 Win=408288 Len=146 TSval=940533635 TSecr=940533635 6 0.000234 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [ACK] Seq=1 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635 7 0.000627 127.0.0.1 → 127.0.0.1 TCP 204 65432 → 53942 [PSH, ACK] Seq=1 Ack=147 Win=408128 Len=148 TSval=940533635 TSecr=940533635 8 0.000649 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=147 Ack=149 Win=408128 Len=0 TSval=940533635 TSecr=940533635 9 0.000668 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [FIN, ACK] Seq=149 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635 10 0.000682 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=147 Ack=150 Win=408128 Len=0 TSval=940533635 TSecr=940533635 11 0.000687 127.0.0.1 → 127.0.0.1 TCP 56 [TCP Dup ACK 6#1] 65432 → 53942 [ACK] Seq=150 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635 12 0.000848 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [FIN, ACK] Seq=147 Ack=150 Win=408128 Len=0 TSval=940533635 TSecr=940533635 13 0.001004 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [ACK] Seq=150 Ack=148 Win=408128 Len=0 TSval=940533635 TSecr=940533635 ^C13 packets captured |
引用
這一節主要用來引用一些額外的資訊和外部資源連結
Python 文件
- Python’s socket module
- Python’s Socket Programming HOWTO
錯誤資訊
下面這段話來自 python 的 socket 模組文件:
所有的錯誤都會觸發異常,像無效引數型別和記憶體不足的常見異常可以被丟擲;從 Python 3.3 開始,與 socket 或地址語義相關的錯誤會引發 OSError 或其子類之一的異 常 引用
異常 | errno 常量 | 說明 BlockingIOError | EWOULDBLOCK | 資源暫不可用,比如在非阻塞模式下呼叫 send() 方法,對方太繁忙面沒有讀取,傳送佇列滿了,或者網路有問題 OSError | EADDRINUSE | 埠被戰用,確保沒有其它的程式與當前的程式執行在同一地址/埠上,你的伺服器設定了 SO_REUSEADDR 引數 ConnectionResetError | ECONNRESET | 連線被重置,遠端的程式崩潰,或者 socket 意外關閉,或是有防火牆或鏈路上的設配有問題 TimeoutError | ETIMEDOUT | 操作超時,對方沒有響應 ConnectionRefusedError | ECONNREFUSED | 連線被拒絕,沒有程式監聽指定的埠
socket 地址族
socket.AF_INET 和 socket.AF_INET6 是 socket.socket() 方法呼叫的第一個引數 ,表示地址協議族,API 使用了一個期望傳入指定格式引數的地址,這取決於是 AF_INET 還是 AF_INET6
地址族 | 協議 | 地址元組 | 說明 – | – | – | – socket.AF_INET | IPv4 | (host, port) | host 引數是個如 www.example.com 的主機名稱,或者如 10.1.2.3 的 IPv4 地址 socket.AF_INET6 | IPv6 | (host, port, flowinfo, scopeid) | 主機名同上,IPv6 地址 如:fe80::6203:7ab:fe88:9c23,flowinfo 和 scopeid 分別表示 C 語言結構體 sockaddr_in6 中的 sin6_flowinfo 和 sin6_scope_id 成員
注意下面這段 python socket 模組中關於 host 值和地址元組文件
對於 IPv4 地址,使用主機地址的方式有兩種:
''空字串表示INADDR_ANY,字元''表示INADDR_BROADCAST,這個行為和 IPv6 不相容,因此如果你的 程式中使用的是 IPv6 就應該避免這種做法。源文件
我在本教程中使用了 IPv4 地址,但是如果你的機器支援,也可以試試 IPv6 地址。socket.getaddrinfo() 方法會返回五個元組的序列,這包括所有建立 socket 連線的必要引數,socket.getaddrinfo() 方法理解並處理傳入的 IPv6 地址和主機名
下面的例子中程式將返回一個通過 TCP 連線到 example.org 80 埠上的地址資訊:
|
1 2 3 4 5 |
>>> socket.getaddrinfo("example.org", 80, proto=socket.IPPROTO_TCP) [(, , 6, '', ('2606:2800:220:1:248:1893:25c8:1946', 80, 0, 0)), (, , 6, '', ('93.184.216.34', 80))] |
如果 IPv6 可用的話結果可能有所不同,上面返回的值可以被用於 socket.socket() 和 socket.connect() 方法呼叫的引數,在 python socket 模組文件中的 示例 一節中有客戶端和服務端 程式
使用主機名
這一節主要適用於使用 bind() 和 connect() 或 connect_ex() 方法時如何使用主機名,然而當你使用迴環地址做為主機名時,它總是會解析到你期望的地址。這剛好與客戶端使用主機名的場景相反,它需要 DNS 解析的過程,比如 www.example.com
下面一段來自 python socket 模組文件
如果你主機名稱做為 IPv4/v6 socket 地址的 host 部分,程式可能會出現非預期的結果 ,由於 python 使用了 DNS 查詢過程中的第一個結果,socket 地址會被解析成與真正的 IPv4/v6 地址不同的其它地址,這取決於 DNS 解析和你的 host 檔案配置。如果想得到 確定的結果,請使用數字格式的地址做為 host 引數的值 源文件
通常回環地址 localhost 會被解析到 127.0.0.1 或 ::1 上,你的系統可能就是這麼設定的,也可能不是。這取決於你係統配置,與所有 IT 相關的事情一樣,總會有例外的情況,沒辦法完全保證 localhost 被解析到了迴環地址上
比如在 Linux 上,檢視 man nsswitch.conf 的結果,域名切換配置檔案,還有另外一個 macOS 和 Linux 通用的配置檔案地址是:/etc/hosts,在 windows 上則是C:\Windows\System32\drivers\etc\hosts,hosts 檔案包含了一個文字格式的靜態域名地址對映表,總之 DNS 也是一個難題
有趣的是,在撰寫這篇文章的時候(2018 年 6 月),有一個關於 讓 localhost 成為真正的 localhost的 RFC 草案,討論就是圍繞著 localhost 使用的情況開展的
最重要的一點是你要理解當你在應用程式中使用主機名時,返回的地址可能是任何東西,如果你有一個安全性敏感的應用程式,不要使用主機名。取決於你的應用程式和環境,這可能會困擾到你
注意: 安全方面的考慮和最佳實踐總是好的,即使你的程式不是安全敏感型的應用。如果你的應用程式訪問了網路,那它就應該是安全的穩定的。這表示至少要做到以下幾點:
- 經常會有系統軟體升級和安全補丁,包括 python,你是否使用了第三方的庫?如果是的話,確保他們能正常工作並且更新到了新版本
- 儘量使用專用防火牆或基於主機的防火牆來限制與受信任系統的連線
- DNS 服務是如何配置的?你是否信任配置內容及其配置者
- 在呼叫處理其他程式碼之前,請確保儘可能地對請求資料進行了清理和驗證,還要為此新增測試用例,並且經常執行
無論是否使用主機名稱,你的應用程式都需要支援安全連線(加密授權),你可能會用到 TLS,這是一個超越了本教程的範圍的話題。可以從 python 的 SSL 模組文件瞭解如何開始使用它,這個協議和你的瀏覽器使用的安全協議是一樣的
考慮到介面、IP 地址、域名解析這些「變數」,你應該怎麼應對?如果你還沒有網路應用程式審查流程,可以使用以下建議:
應用程式 | 使用 | 建議 – | – | – 服務端 | 迴環地址 | 使用 IP 地址 127.0.0.1 或 ::1 服務端 | 乙太網地址 | 使用 IP 地址,比如:10.1.2.3,使用空字串表示本機所有 IP 地址 客戶端 | 迴環地址 | 使用 IP 地址 127.0.0.1 或 ::1 客戶端 | 乙太網地址 | 使用統一的不依賴域名解析的 IP 地址,特殊情況下才會使用主機地址,檢視上面的安全提示
對於客戶端或者服務端來說,如果你需要授權連線到主機,請檢視如何使用 TLS
阻塞呼叫
如果一個 socket 函式或者方法使你的程式掛起,那麼這個就是個阻塞呼叫,比如 accept(), connect(), send(), 和 recv() 都是 阻塞 的,它們不會立即返回,阻塞呼叫在返回前必須等待系統呼叫 (I/O) 完成。所以呼叫者 —— 你,會被阻止直到系統呼叫結束或者超過延遲時間或者有錯誤發生
阻塞的 socket 呼叫可以設定成非阻塞的模式,這樣他們就可以立即返回。如果你想做到這一點,就得重構並重新設計你的應用程式
由於呼叫直接返回了,但是資料確沒就緒,被呼叫者處於等待網路響應的狀態,沒法完成它的工作,這種情況下,當前 socket 的狀態碼 errno 應該是 socket.EWOULDBLOCK。setblocking() 方法是支援非阻塞模式的
預設情況下,socket 會以阻塞模式建立,檢視 socket 延遲的注意事項 中三種模式的解釋
關閉連線
有趣的是 TCP 連線一端開啟,另一端關閉的狀態是完全合法的,這被稱做 TCP「半連線」,是否需要這種保持狀態是由應用程式決定的,通常來說不需要。這種狀態下,關閉方將不能傳送任何資料,它只能接收資料
我不是在提倡你採用這種方法,但是作為一個例子,HTTP 使用了一個名為「Connection」的頭來標準化規定應用程式是否關閉或者保持連線狀態,更多內容請檢視 RFC 7230 中 6.3 節, HTTP 協議 (HTTP/1.1): 訊息語法與路由
當你在設計應用程式及其應用層協議的時候,最好先了解一下如何關閉連線,有時這很簡單而且很明顯,或者採取一些可以實現的原型,這取決於你的應用程式以及訊息迴圈如何被處理成期望的資料,只要確保 socket 在完成工作後總是能正確關閉
位元組序
檢視維基百科 位元組序 中關於不同的 CPU 是如何在記憶體中儲存位元組序列的,處理單個位元組時沒有任何問題,但是當把多個位元組處理成單個值(四位元組整型)時,如果和你通訊的另一端使用了不同的位元組序時位元組順序需要被反轉
位元組順序對於字元文字來說也很重要,字元文字通過表示為多位元組的序列,就像 Unicode 一樣。除非你只使用 true 和 ASCII 字元來控制客戶端和服務端的實現,否則使用 utf-8 格式或者支援位元組序標識(BOM) 的 Unicode 字符集會比較合適
在應用層協議中明確的規定使用編碼格式是很重要的,你可以規定所有的文字都使用 utf-8 或者用「content-encoding」頭指定編碼格式,這將使你的程式不需要檢測編碼方式,當然也應該儘量避免這麼做
當資料被呼叫儲存到了檔案或者資料庫中而且又沒有資料的元資訊的時候,問題就很麻煩了,當資料被傳到其它端,它將試著檢測資料的編碼方式。有關討論,請參閱 Wikipedia 的 Unicode 文章,它引用了 RFC 3629:UTF-8, a transformation format of ISO 10646
然而 UTF-8 的標準 RFC 3629 中推薦禁止在 UTF-8 協議中使用標記位元組序 (BOM),但是 討 論了無法實現的情況,最大的問題在於如何使用一種模式在不依賴 BOM 的情況下區分 UTF-8 和其它編碼方式
避開這些問題的方法就是總是儲存資料使用的編碼方式,換句話說,如果不只用 utf-8 格式的編碼或者其它的帶有 BOM 的編碼就要嘗試以某種方式將編碼方式儲存為後設資料,然後你就可以在資料上附加編碼的頭資訊,告訴接收者編碼方式
TCP/IP 使用的位元組順序是 big-endian,被稱做網路序。網路序被用來表示底層協議棧中的整型數字,好比 IP 地址和埠號,python 的 socket 模組有幾個函式可以把這種整型數字從網路位元組序轉換成主機位元組序
函式 | 說明 – | – socket.ntohl(x) | 把 32 位的正整型數字從網路位元組序轉換成主機位元組序,在網路位元組序和主機位元組序相同的機器上這是個空操作,否則將是一個 4 位元組的交換操作 socket.ntohs(x) | 把 16 位的正整型數字從網路位元組序轉換成主機位元組序,在網路位元組序和主機位元組序相同的機器上這是個空操作,否則將是一個 2 位元組的交換操作 socket.htonl(x) | 把 32 位的正整型數字從主機位元組序轉換成網路位元組序,在網路位元組序和主機位元組序相同的機器上這是個空操作,否則將是一個 4 位元組的交換操作 socket.htons(x) | 把 16 位的正整型數字從主機位元組序轉換成網路位元組序,在網路位元組序和主機位元組序相同的機器上這是個空操作,否則將是一個 2 位元組的交換操作
你也可以使用 struct 模組打包或者解包二進位制資料(使用格式化字串):
|
1 2 3 |
import struct network_byteorder_int = struct.pack('>H', 256) python_int = struct.unpack('>H', network_byteorder_int)[0] |
結論
我們在本教程中介紹了很多內容,網路和 socket 是很大的一個主題,如果你對它們都比較陌生,不要被這些規則和大寫字母術語嚇到
為了理解所有的東西如何工作的,有很多部分需要了解。但是,就像 python 一樣,當你花時間去了解每個獨立的部分時它才開始變得有意義
我們看過了 python socket 模組中底層的一些 API,並瞭解瞭如何使用它們建立客戶端伺服器應用程式。我們也建立了一個自定義類來做為應用層的協議,並用它在不同的端點之間交換資料,你可以使用這個類並在些基礎上快速且簡單地構建出一個你自己的 socket 應用程式
你可以在 Github 上找到 原始碼
恭喜你堅持到最後!你現在就可以在程式中很好地使用 socket 了
我希望這個教程能為你開始 socket 程式設計旅途中提供一些資訊、示例、或者靈感