NLP裡最常用、最傳統的深度學習模型就是迴圈神經網路 RNN(Recurrent Neural Network)。這個模型的命名已經說明了資料處理方法,是按順序按步驟讀取的。與人類理解文字的道理差不多,看書都是一個字一個字,一句話一句話去理解的。
本文將介紹RNN及其一些重要的RNN變種模型:
- RNN
- Encoder-Decoder( = Seq-to-Seq )
- Attention Mechanism
RNN 多結構詳解
CNN vs RNN
- CNN 需要固定長度的輸入、輸出,RNN 的輸入和輸出可以是不定長且不等長的
- CNN 只有 one-to-one 一種結構,而 RNN 有多種結構,如下圖:
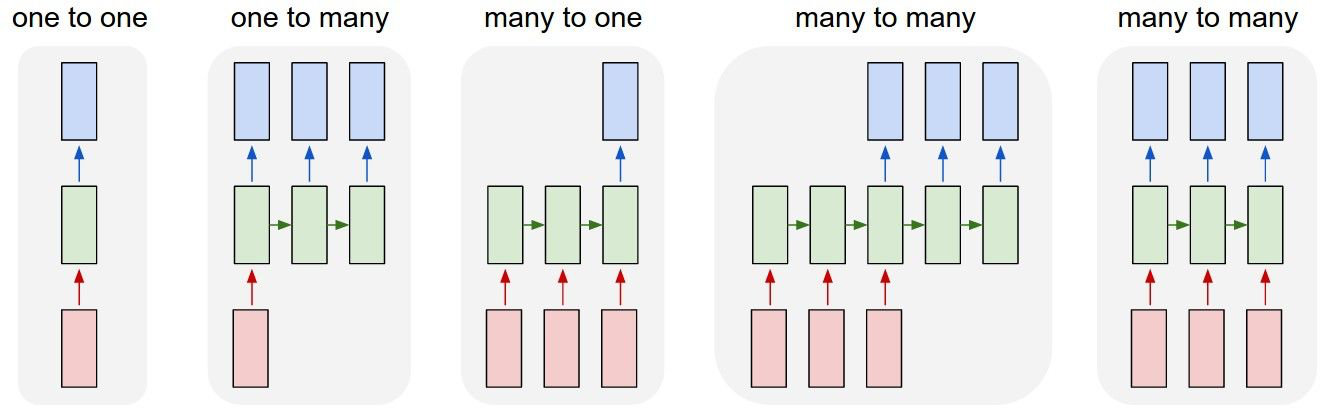
1. one-to-one
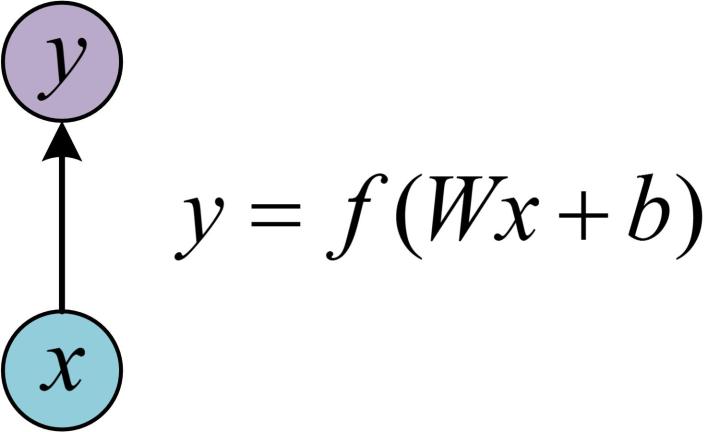
最基本的單層網路,輸入是x,經過變換Wx+b和啟用函式f得到輸出y。
2. one-to-n
輸入不是序列而輸出為序列的情況,只在序列開始進行輸入計算:

圖示中記號的含義是:
- 圓圈或方塊表示的是向量。
- 一個箭頭就表示對該向量做一次變換。如上圖中h0和x分別有一個箭頭連線,就表示對h0和x各做了一次變換。
還有一種結構是把輸入資訊X作為每個階段的輸入:
下圖省略了一些X的圓圈,是一個等價表示:

這種 one-to-n 的結構可以處理的問題有:
- 從影像生成文字(image caption),此時輸入的X就是影像的特徵,而輸出的y序列就是一段句子,就像看圖說話等
- 從類別生成語音或音樂等
3. n-to-n
最經典的RNN結構,輸入、輸出都是等長的序列資料。

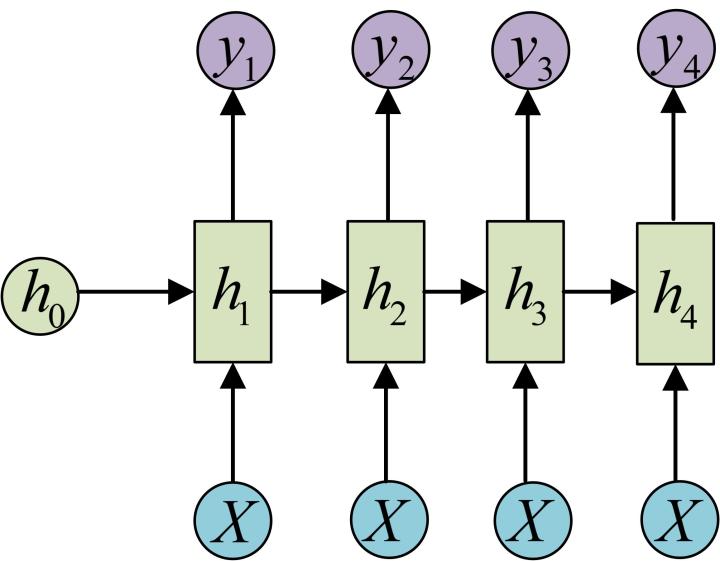
假設輸入為X=(x1, x2, x3, x4),每個x是一個單詞的詞向量。
為了建模序列問題,RNN引入了隱狀態h(hidden state)的概念,h可以對序列形的資料提取特徵,接著再轉換為輸出。先從h1的計算開始看:
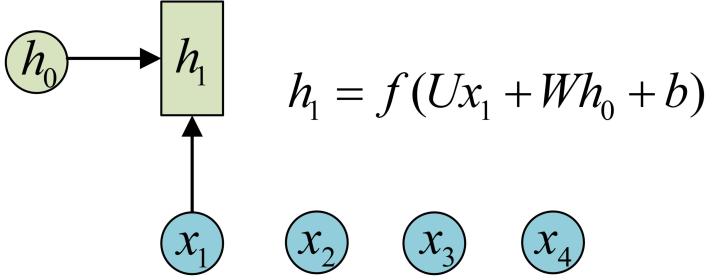
h2的計算和h1類似。要注意的是,在計算時,每一步使用的引數U、W、b都是一樣的,也就是說每個步驟的引數都是共享的,這是RNN的重要特點,一定要牢記。

依次計算剩下來的(使用相同的引數U、W、b):
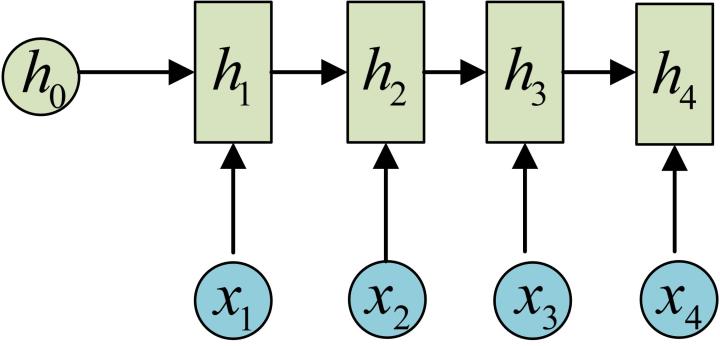
這裡為了方便起見,只畫出序列長度為4的情況,實際上,這個計算過程可以無限地持續下去。得到輸出值的方法就是直接通過h進行計算:
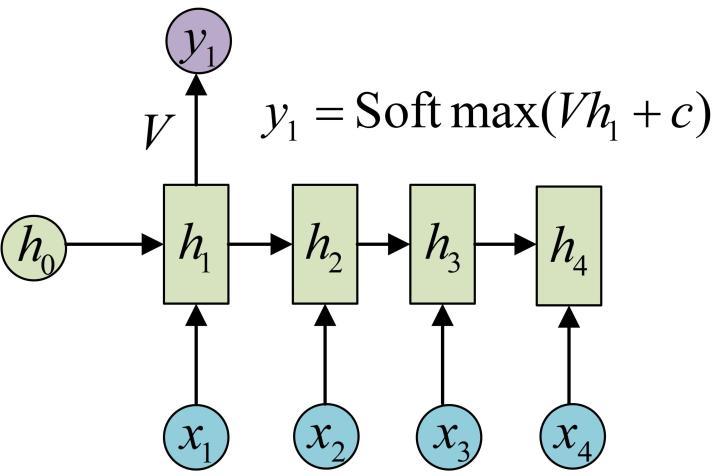
正如之前所說,一個箭頭就表示對對應的向量做一次類似於f(Wx+b)的變換,這裡的這個箭頭就表示對h1進行一次變換,得到輸出y1。
剩下的輸出類似進行(使用和y1同樣的引數V和c):
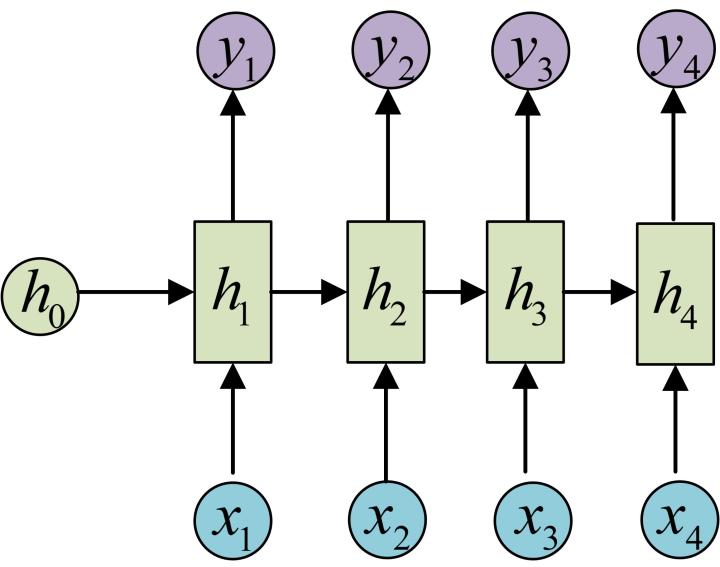
這就是最經典的RNN結構,它的輸入是x1, x2, …..xn,輸出為y1, y2, …yn,也就是說,輸入和輸出序列必須要是等長的。由於這個限制的存在,經典RNN的適用範圍比較小,但也有一些問題適合用經典的RNN結構建模,如:
- 計算視訊中每一幀的分類標籤。因為要對每一幀進行計算,因此輸入和輸出序列等長。
- 輸入為字元,輸出為下一個字元的概率。這就是著名的Char RNN(詳細介紹請參考:The Unreasonable Effectiveness of Recurrent Neural Networks,Char RNN可以用來生成文章,詩歌,甚至是程式碼,非常有意思)。
4. n-to-one
要處理的問題輸入是一個序列,輸出是一個單獨的值而不是序列,應該怎樣建模呢?實際上,我們只在最後一個h上進行輸出變換就可以了:
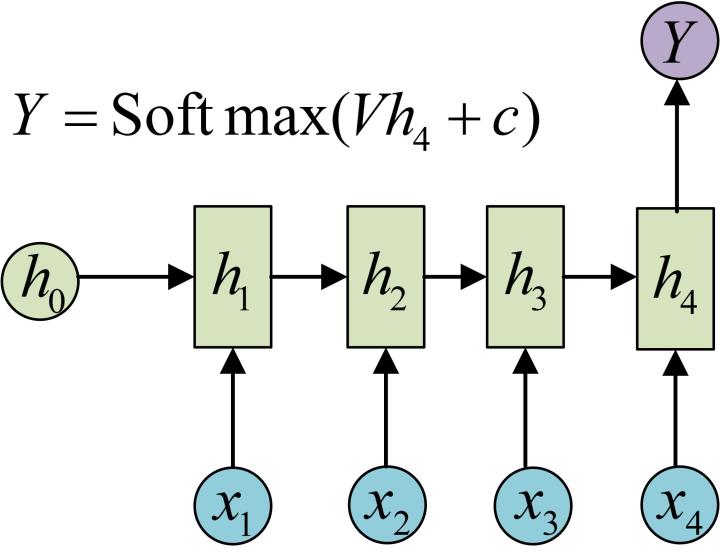
這種結構通常用來處理序列分類問題。如輸入一段文字判別它所屬的類別,輸入一個句子判斷其情感傾向,輸入一段視訊並判斷它的類別等等。
Encoder-Decoder
n-to-m
還有一種是 n-to-m,輸入、輸出為不等長的序列。
這種結構是Encoder-Decoder,也叫Seq2Seq,是RNN的一個重要變種。原始的n-to-n的RNN要求序列等長,然而我們遇到的大部分問題序列都是不等長的,如機器翻譯中,源語言和目標語言的句子往往並沒有相同的長度。為此,Encoder-Decoder結構先將輸入資料編碼成一個上下文語義向量c:

語義向量c可以有多種表達方式,最簡單的方法就是把Encoder的最後一個隱狀態賦值給c,還可以對最後的隱狀態做一個變換得到c,也可以對所有的隱狀態做變換。
拿到c之後,就用另一個RNN網路對其進行解碼,這部分RNN網路被稱為Decoder。Decoder的RNN可以與Encoder的一樣,也可以不一樣。具體做法就是將c當做之前的初始狀態h0輸入到Decoder中:
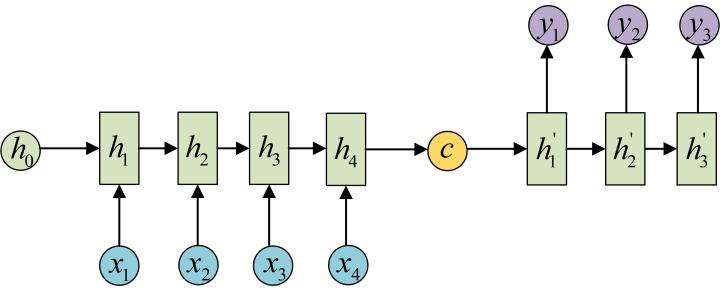
還有一種做法是將c當做每一步的輸入:
Encoder-Decoder 應用
由於這種Encoder-Decoder結構不限制輸入和輸出的序列長度,因此應用的範圍非常廣泛,比如:
- 機器翻譯:Encoder-Decoder的最經典應用,事實上這結構就是在機器翻譯領域最先提出的。
- 文字摘要:輸入是一段文字序列,輸出是這段文字序列的摘要序列。
- 閱讀理解:將輸入的文章和問題分別編碼,再對其進行解碼得到問題的答案。
- 語音識別:輸入是語音訊號序列,輸出是文字序列。
Encoder-Decoder 框架
Encoder-Decoder 不是一個具體的模型,是一種框架。
- Encoder:將 input序列 →轉成→ 固定長度的向量
- Decoder:將 固定長度的向量 →轉成→ output序列
- Encoder 與 Decoder 可以彼此獨立使用,實際上經常一起使用
因為最早出現的機器翻譯領域,最早廣泛使用的轉碼模型是RNN。其實模型可以是 CNN /RNN /BiRNN /LSTM /GRU /…
Encoder-Decoder 缺點
- 最大的侷限性:編碼和解碼之間的唯一聯絡是固定長度的語義向量c
- 編碼要把整個序列的資訊壓縮排一個固定長度的語義向量c
- 語義向量c無法完全表達整個序列的資訊
- 先輸入的內容攜帶的資訊,會被後輸入的資訊稀釋掉,或者被覆蓋掉
- 輸入序列越長,這樣的現象越嚴重,這樣使得在Decoder解碼時一開始就沒有獲得足夠的輸入序列資訊,解碼效果會打折扣
因此,為了彌補基礎的 Encoder-Decoder 的侷限性,提出了attention機制。
Attention Mechanism
注意力機制(attention mechanism)是對基礎Encoder-Decoder的改良。Attention機制通過在每個時間輸入不同的c來解決問題,下圖是帶有Attention機制的Decoder:

每一個c會自動去選取與當前所要輸出的y最合適的上下文資訊。具體來說,我們用aij衡量Encoder中第j階段的hj和解碼時第i階段的相關性,最終Decoder中第i階段的輸入的上下文資訊 ci就來自於所有 hj 對 aij 的加權和。
以機器翻譯為例(將中文翻譯成英文):
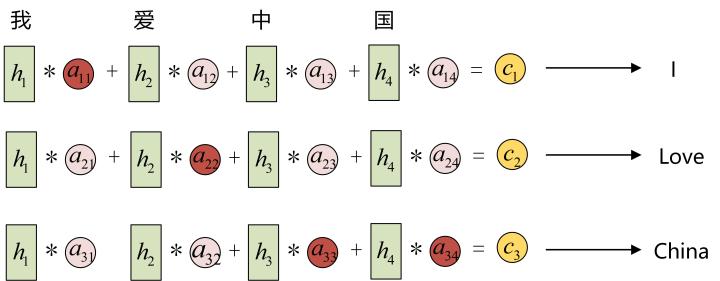
輸入的序列是“我愛中國”,因此,Encoder中的h1、h2、h3、h4就可以分別看做是“我”、“愛”、“中”、“國”所代表的資訊。在翻譯成英語時,第一個上下文c1應該和 “我” 這個字最相關,因此對應的 a11 就比較大,而相應的 a12、a13、a14 就比較小。c2應該和“愛”最相關,因此對應的 a22 就比較大。最後的c3和h3、h4最相關,因此 a33、a34 的值就比較大。
至此,關於Attention模型,只剩最後一個問題了,那就是:這些權重 aij 是怎麼來的?
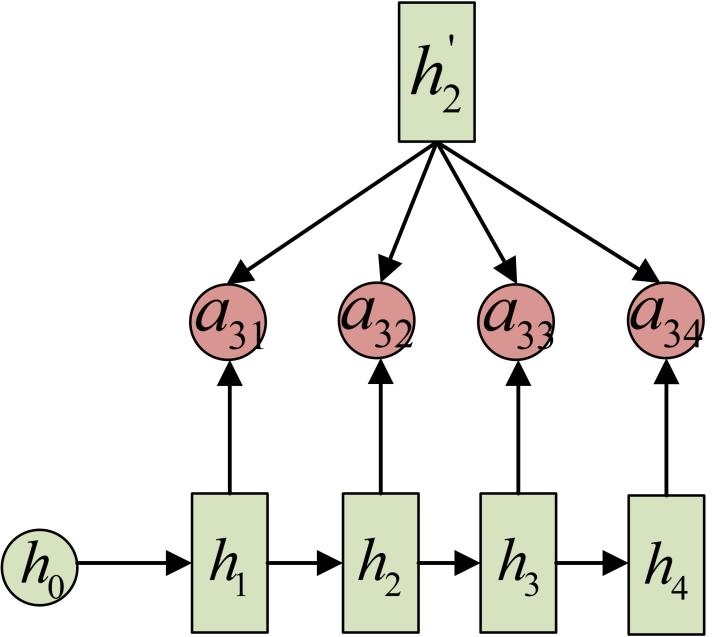
事實上,aij 同樣是從模型中學出的,它實際和Decoder的第i-1階段的隱狀態、Encoder第j個階段的隱狀態有關。
同樣還是拿上面的機器翻譯舉例, a1j 的計算(此時箭頭就表示對h’和 hj 同時做變換):

a2j 的計算:

a3j 的計算:
以上就是帶有Attention的Encoder-Decoder模型計算的全過程。
Attention 的優點:
- 在機器翻譯時,讓生詞不只是關注全域性的語義向量c,增加了“注意力範圍”。表示接下來輸出的詞要重點關注輸入序列種的哪些部分。根據關注的區域來產生下一個輸出。
- 不要求編碼器將所有資訊全輸入在一個固定長度的向量中。
- 將輸入編碼成一個向量的序列,解碼時,每一步選擇性的從序列中挑一個子集進行處理。
- 在每一個輸出時,能夠充分利用輸入攜帶的資訊,每個語義向量Ci不一樣,注意力焦點不一樣。
Attention 的缺點
- 需要為每個輸入輸出組合分別計算attention。50個單詞的輸出輸出序列需要計算2500個attention。
- attention在決定專注於某個方面之前需要遍歷一遍記憶再決定下一個輸出是以什麼。
Attention的另一種替代方法是強化學習,來預測關注點的大概位置。但強化學習不能用反向傳播演算法端到端的訓練。
Attention視覺化
Attention的視覺化是一件非常cool的事!?下面推薦一些優秀的attention相關論文。
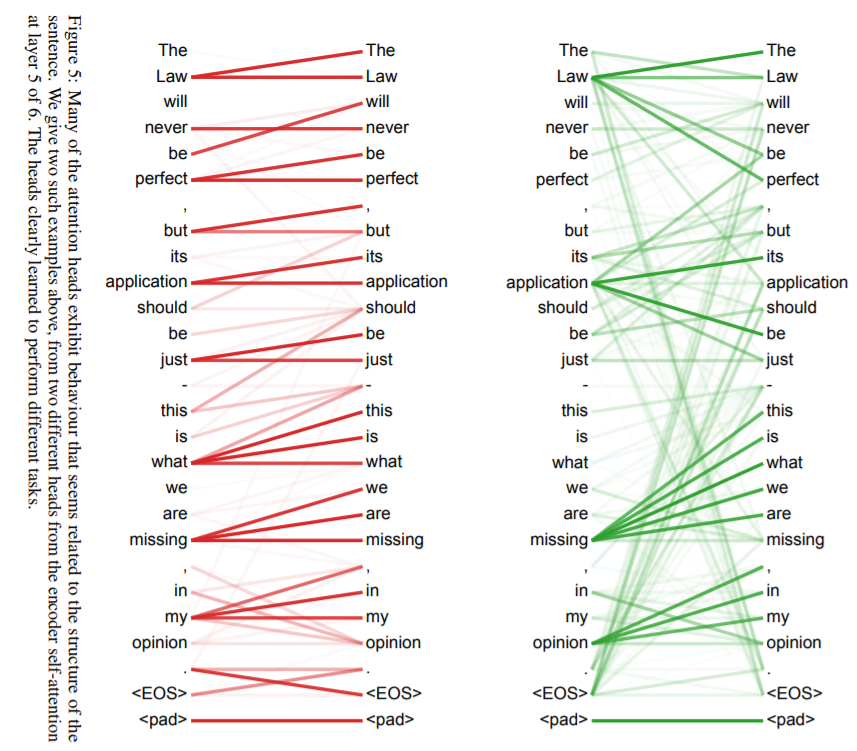
paper: Attention Is All You Need
下圖是句子的單詞之間的attention聯絡,顏色深淺表示大小。

paper: Show, Attend and Tell
注意每個句子的不同單詞在圖片中的attention標註:


paper: Convolutional Sequence to Sequence Learning
機器翻譯中attention數值的視覺化,一般是隨著順序強相關的。

其它paper:
[Grammar as a Foreign Language]
[Teaching Machines to Read and Comprehend]
下面這張Attention熱力圖表達出了,當人在閱讀的時候,注意力大多數放在了文字標題或者段落第一句話,還是蠻符合現實情況的。

Attention Mechanism是很早的概念了,但隨著2017年穀歌的一篇《Attention Is All You Need》被完全引爆。隨後會寫這篇論文的詳細走讀和過程推導?,敬請期待~
參考