基於python的大資料分析-pandas資料讀取(程式碼實戰)
我們常見的資料儲存格式無非就是csv、excel、txt以及資料庫等形式。
資料讀取
在pandas中可以使用一些函式完成資料的讀取。比如read_csv、read_excel、read_table、read_sql等,這些分別是啥意思呢。。。。自己看字尾就能明白啦~
下面我們就通過擼程式碼來了解它們
txt檔案
格式:read_table(檔案路徑與檔名, names=[列名1,列名2,.....], sep="",......)
其中names為列名,預設為檔案中的第一行作為列名
sep為分隔符,預設為空
from pandas import read_table #txt df=read_table(r'D:python_workspaceanacondarz.txt') #檢視前五行資料 df.head(5) #檢視後兩行資料 #df.tail(2)
rz.txt的內容如下
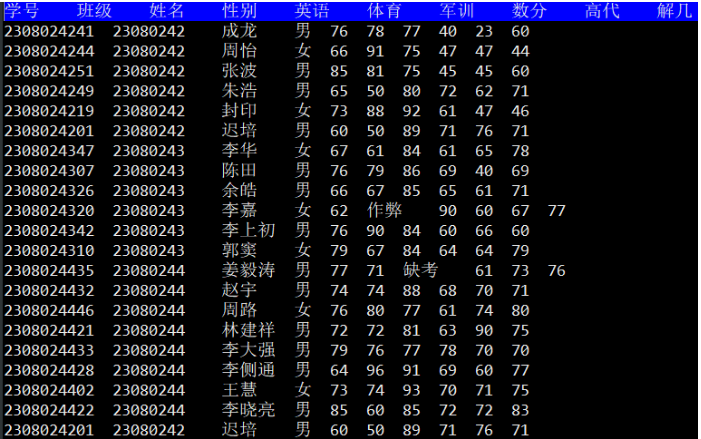
csv檔案
格式:read_csv(檔案路徑與檔名, names=[列名1,列名2,.....], sep="",......)
解釋同上,不在廢話
#csv from pandas import read_csv df=read_csv(r'D:python_workspaceanacondarz.csv') df
rz.csv的內容如下
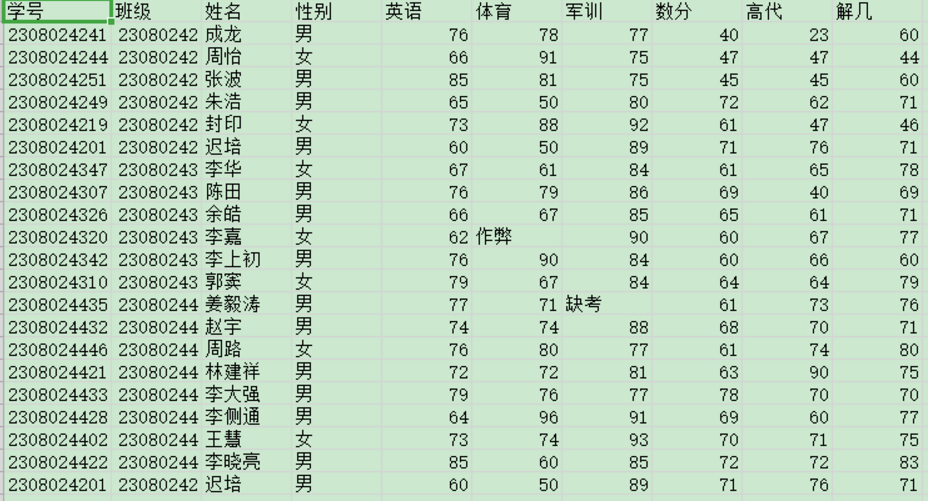
excel檔案
格式:read_excel(檔案路徑與檔名, sheetname=sheet的名稱, header=0)
sheetname可以指定讀取幾個sheet,sheet數目從0開始。如果sheetname=[0,2]則代表讀取第一個和第三個sheet
header為0表示以檔案第一行作為表頭顯示;為1則把檔案第一行丟棄不作為表頭顯示。
#exel from pandas import read_excel df=read_excel(r'D:python_workspaceanacondarz.xls', sheetname='Sheet3') df
mysql
首先安裝pymysql,通過pip命令即可安裝
格式:read_sql(要查詢的sql語句, 資料庫的連結物件)
import pandas as pd import pymysql #具體的資料庫連結資訊自行替換 conn=pymysql.connect(host='xxxx',database='xxx',user='root', password='',port=3306,charset='utf8') sql='select * from a' r=pd.read_sql(sql,conn) #關閉資料庫連結 conn.close() print(r.head(5))
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/69942496/viewspace-2655342/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 基於python的大資料分析-pandas資料儲存(程式碼實戰)Python大資料
- 基於python的大資料分析-資料處理(程式碼實戰)Python大資料
- 基於python的大資料分析實戰學習筆記-pandas(資料分析包)Python大資料筆記
- 基於python的大資料分析實戰學習筆記-pandas之DataFramePython大資料筆記
- 基於python的大資料分析實戰學習筆記-AnacondaPython大資料筆記
- 【Pandas基礎教程】第02講 Pandas讀取資料
- Python - pandas 資料分析Python
- Python資料分析之pandasPython
- Python | 資料分析實戰ⅠPython
- Python | 資料分析實戰 ⅡPython
- Python資料分析之Pandas篇Python
- Python大資料分析學習.Pandas 資料匯入問題 (1)Python大資料
- Python資料分析 Pandas模組 基礎資料結構與簡介Python資料結構
- ajax讀取資料庫資料程式碼例項資料庫
- CSDN周賽第37期:贏《Pandas入門與實戰應用 :基於Python的資料分析與處理》Python
- 基於Pandas+ECharts的金融大資料視覺化實現方案Echarts大資料視覺化
- 遊戲資料分析的三大實戰案例深度解讀遊戲
- 七牛大資料平臺的實時資料分析實戰大資料
- 處理pandas讀取資料為nan時NaN
- 資料分析常用的 23 個 Pandas 程式碼,收好不謝
- 基於雲原生的大資料實時分析方案實踐大資料
- 基於 Spark 的資料分析實踐Spark
- python-資料分析-Pandas-3、DataFrame-資料重塑Python
- python讀取MySQL資料PythonMySql
- 基於Hive的大資料分析系統Hive大資料
- 《Python資料分析與挖掘實戰》原始碼下載Python原始碼
- Python利用pandas處理資料與分析Python
- 用 Python 進行資料分析 pandas (一)Python
- Python入門教程—資料分析工具PandasPython
- python-資料分析-Pandas-4、DataFrame-資料透視Python
- 《Python資料分析與挖掘實戰》-- 讀書筆記(2)-- 2019Python筆記
- 大資料實戰:電商該如何利用大資料獲取流量?大資料
- Pandas讀寫資料庫資料庫
- Python讀取YAML配置資料PythonYAML
- python讀取串列埠 資料Python串列埠
- 2.2 基於python開發的資料比對工具--SYDCTOOL程式碼設計解讀Python
- python-資料分析-Pandas-1、Series物件Python物件
- python pandas庫讀取excel/csv中指定行或列資料詳解PythonExcel