【本文正在參與 “擁抱開源 | 濤思資料 TDengine有獎徵稿】https://marketing.csdn.net/p/0ada836ca30caa924b9baae0fd33857c
裝置上傳的資料具有很明顯的物聯網特點,通常是時序性的,按時間先後順序上報,而且寫入後,幾乎不會修改,主要是查詢和統計。針對這些特點,時序資料庫TDengine 將資料庫、訊息佇列、快取、流式計算等功能融合一起,在大幅提高效能的同時,降低平臺開發維護的複雜度和成本。
-
實現方案
-
服務端安裝
官網提供了三種格式的安裝包其中deb支援ubuntu系統,rpm支援centos系統,tar.gz包兩種系統都支援。我們常用centOS,下載tar.gz包。
1、解壓
tar -xzvf /home/tdengine/TDengine-server-1.6.5.5-Linux-x64.tar.gz

2、安裝
解壓檔案後,進入子目錄,執行其中的install.sh安裝指令碼:
sudo ./install.sh

3、啟動服務
設定為自啟動 :
systemctl start taosd
設定成功後,輸入taos,測試服務是否正常啟動

- 客戶端安裝
研發使用環境通常是windows,在官網上下載對應版本,雙擊安裝即可。

安裝完成後,預設會生成C:\Tdengine目錄,在此目錄下執行taos命令,連線服務端。

建立資料庫,並使用
create database td_test

建立表格,

- python****庫安裝
在C:\TDengine\connector\python\windows目錄下安裝第三方連線庫
pip install python3/

- **python **連線TDengine
引入taos包,與pg的連線方式類似,在connect中傳入服務端的ip,使用者名稱,密碼,資料庫名。
ip="10.19.133.18"
pwd="taosdata"
db="tc"
user="root"
# 連線taos資料庫
conn = taos.connect(host=ip, user=user, password=pwd, database='td_test')
cursor = conn.cursor()```
+
+ **TDengine****插入效能**
採用隨機生成經緯度,uuid和時間戳累加的方式構造10000條假資料,插入TDengine,測試其插入效能程式碼如下:
```python
def forInsert():
startTime = time.time()
start_time = datetime.datetime(2019, 7, 1)
for i in range(1,10001):
time_interval = datetime.timedelta(seconds=60)
latitude = random.randrange(11879804, 11879904)
longitude = random.randrange(43278291, 43278491)
id = str(uuid.uuid4())
sql = '''INSERT INTO t_gps_info_h
(sampling_time,device_index_code, longitude, latitude)VALUES('%s', '%s', '%d', '%d')'''
try:
cursor.execute(sql % (start_time, id, longitude, latitude))
start_time += time_interval
except Exception as err:
cursor.close
raise(err)
print(i,start_time, id, longitude, latitude)
endTime = time.time()
print('總用時:' + str(endTime - startTime))
cursor.close```
執行後得到結果如下:
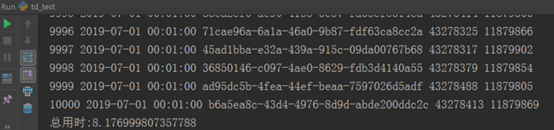
插入10000條資料,用時8秒左右,大概是postgre的4倍左右,未達到其官方的10倍以上,可能還需要後期具體最佳化。
+
+ **TDengine****查詢效能**
透過sql語句查詢其中的四個欄位,測試其查詢效能,程式碼如下:
```python
def select():
startTime = time.time()
# sql語句
sql = "SELECT sampling_time,device_index_code, longitude, latitude FROM t_gps_info_h"
# read_sql 方法返回的資料型別是DataFrame
dataframe = pd.read_sql(sql, con=conn)
endTime = time.time()
print(dataframe)
print('查詢條數:' + str(dataframe.size))
print('總用時:' + str(endTime - startTime))```
執行後,得到測試結果,如下圖所示:

查詢條數近4萬條,用時0.15s,效能是其插入的200倍。
+ 結束語
1、 centos上第一次安裝服務端後,如果出現dberror的錯誤,客戶端也無法連線,則伺服器需要重啟。
2、語言與sql類似,只是資料型別比較有限,第一列必須是時間戳,並且會自動設為主鍵。
3、TDengine最大的優勢就是效能,但是限制條件比較多,後期還需要在相同條件下與postgre進行對比。
4、本文僅對TDengine效能進行測試,其內建訊息佇列和預統計的功能還未涉及。
【本文正在參與 “擁抱開源 | 濤思資料 TDengine有獎徵稿】[https://marketing.csdn.net/p/0ada836ca30caa924b9baae0fd33857c](https://marketing.csdn.net/p/0ada836ca30caa924b9baae0fd33857c)