ElasticSearch入門簡介
前言
Elasticsearch 是一個建立在全文搜尋引擎 Apache Lucene(TM) 基礎上的搜尋引擎,可以說 Lucene 是當今最先進,最高效的全功能開源搜尋引擎框架。
Elasticsearch是一個實時分散式和開源的全文搜尋和分析引擎。 它可以從RESTful Web服務介面訪問,並使用模式少JSON(JavaScript物件符號)文件來儲存資料。它是基於Java程式語言,這使Elasticsearch能夠在不同的平臺上執行。使使用者能夠以非常快的速度來搜尋非常大的資料量。
Elasticsearch總體架構圖:
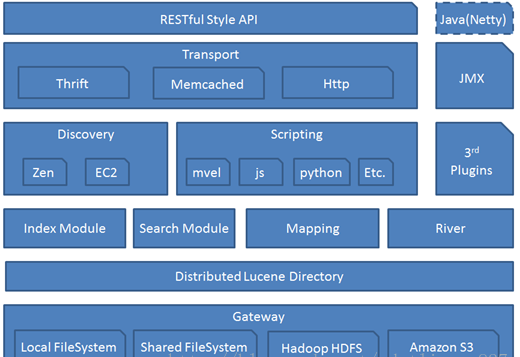
1. ES 基礎概念
1.1 ES定義
ES=elaticsearch簡寫, Elasticsearch是一個開源的高擴充套件的分散式全文檢索引擎,它可以近乎實時的儲存、檢索資料;本身擴充套件性很好,可以擴充套件到上百臺伺服器,處理PB級別的資料。
Elasticsearch也使用Java開發並使用Lucene作為其核心來實現所有索引和搜尋的功能,但是它的目的是通過簡單的RESTful API來隱藏Lucene的複雜性,從而讓全文搜尋變得簡單。
1.2 Lucene與ES關係?
1)Lucene只是一個庫。想要使用它,你必須使用Java來作為開發語言並將其直接整合到你的應用中,更糟糕的是,Lucene非常複雜,你需要深入瞭解檢索的相關知識來理解它是如何工作的。
2)Elasticsearch也使用Java開發並使用Lucene作為其核心來實現所有索引和搜尋的功能,但是它的目的是通過簡單的RESTful API來隱藏Lucene的複雜性,從而讓全文搜尋變得簡單。
1.3 ES主要解決問題:
1)檢索相關資料;
2)返回統計結果;
3)速度要快。
1.4 ES工作原理
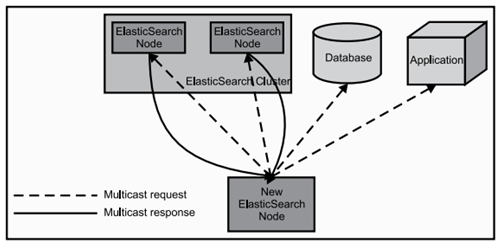
當ElasticSearch的節點啟動後,它會利用多播(multicast)(或者單播,如果使用者更改了配置)尋找叢集中的其它節點,並與之建立連線。這個過程如下圖所示:
1.5 ES核心概念
1)Cluster:叢集
ES可以作為一個獨立的單個搜尋伺服器。不過,為了處理大型資料集,實現容錯和高可用性,ES可以執行在許多互相合作的伺服器上。這些伺服器的集合稱為叢集。
2)Node:節點
形成叢集的每個伺服器稱為節點。
每一個執行例項稱為一個節點,每一個執行例項既可以在同一機器上,也可以在不同的機器上。
所謂執行例項,就是一個伺服器程式,在測試環境中可以在一臺伺服器上執行多個伺服器程式,在生產環境中建議每臺伺服器執行一個伺服器程式。
3)Index:索引
形成叢集的每個伺服器稱為節點。
Elasticsearch裡的索引概念是名詞而不是動詞,類似於關聯式資料庫裡面每一個伺服器可以支援多個資料庫是一個道理,但是本質
上和關聯式資料庫還是有很大的區別,我們這裡暫時可以這麼理解。
4)Shard:分片
當有大量的文件時,由於記憶體的限制、磁碟處理能力不足、無法足夠快的響應客戶端的請求等,一個節點可能不夠。這種情況下,資料可以分為較小的分片。每個分片放到不同的伺服器上。
當你查詢的索引分佈在多個分片上時,ES會把查詢傳送給每個相關的分片,並將結果組合在一起,而應用程式並不知道分片的存在。即:這個過程對使用者來說是透明的。
5)Replia:副本
為提高查詢吞吐量或實現高可用性,可以使用分片副本。
副本是一個分片的精確複製,每個分片可以有零個或多個副本。ES中可以有許多相同的分片,其中之一被選擇更改索引操作,這種特殊的分片稱為主分片。
當主分片丟失時,如:該分片所在的資料不可用時,叢集將副本提升為新的主分片。
6)全文檢索。
全文檢索就是對一篇文章進行索引,可以根據關鍵字搜尋,類似於mysql裡的like語句。
全文索引就是把內容根據詞的意義進行分詞,然後分別建立索引,例如”你們的激情是因為什麼事情來的” 可能會被分詞成:“你們“,”激情“,“什麼事情“,”來“ 等token,這樣當你搜尋“你們” 或者 “激情” 都會把這句搜出來。
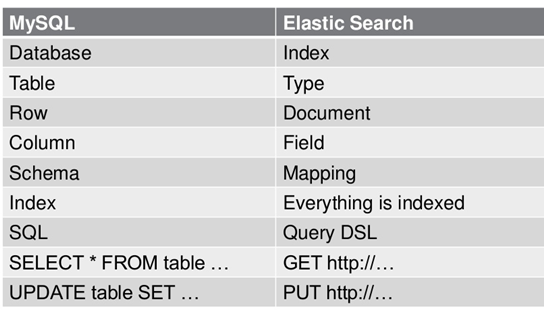
1.6 ES資料架構的主要概念(與關聯式資料庫Mysql對比)
(1)關係型資料庫中的資料庫(DataBase),等價於ES中的索引(Index)
(2)一個資料庫下面有N張表(Table),等價於1個索引Index下面有N多型別(Type),
(3)一個資料庫表(Table)下的資料由多行(ROW)多列(column,屬性)組成,等價於1個Type由多個文件(Document)和多Field組成。
(4)在一個關係型資料庫裡面,schema定義了表、每個表的欄位,還有表和欄位之間的關係。 與之對應的,在ES中:Mapping定義索引下的Type的欄位處理規則,即索引如何建立、索引型別、是否儲存原始索引JSON文件、是否壓縮原始JSON文件、是否需要分詞處理、如何進行分詞處理等。
(5)在資料庫中的增insert、刪delete、改update、查search操作等價於ES中的增PUT/POST、刪Delete、改_update、查GET.
1.7 ELK是什麼?
ELK=elasticsearch+Logstash+kibana
elasticsearch:後臺分散式儲存以及全文檢索
logstash: 日誌加工、“搬運工”
kibana:資料視覺化展示。
ELK架構為資料分散式儲存、視覺化查詢和日誌解析建立了一個功能強大的管理鏈。 三者相互配合,取長補短,共同完成分散式大資料處理工作。
2. ES特點和優勢
1)分散式實時檔案儲存,可將每一個欄位存入索引,使其可以被檢索到。
2)實時分析的分散式搜尋引擎。
分散式:索引分拆成多個分片,每個分片可有零個或多個副本。叢集中的每個資料節點都可承載一個或多個分片,並且協調和處理各種操作;
負載再平衡和路由在大多數情況下自動完成。
3)可以擴充套件到上百臺伺服器,處理PB級別的結構化或非結構化資料。也可以執行在單臺PC上(已測試)
4)支援外掛機制,分詞外掛、同步外掛、Hadoop外掛、視覺化外掛等。
2.1 ES核心機制
1)Recovery
Elasticsearch 的recovery代表的是資料恢復或者叫做資料重新分佈,當有節點加入或退出時時它會根據機器的負載對索引分片進行重新分配,當掛掉的節點再次重新啟動的時候也會進行資料恢復。
2)River
Elasticsearch 的river 代表的是一個資料來源,這也是其它儲存方式(比如:資料庫)同步資料到 elasticsearch 的一個方法。 它是以外掛方式存在的一個 elasticsearch 服務,通過讀取 river 中的資料並把它索引到 elasticsearch 當中去,官方的 river 有 couchDB、RabbitMQ、Twitter、Wikipedia。3)Gateway
Elasticsearch 的gateway 代表 elasticsearch 索引的持久化儲存方式,elasticsearch 預設是先把索引存放到記憶體中去,當記憶體滿了的時候再持久化到硬碟裡。當這個 elasticsearch 叢集關閉或者再次重新啟動時就會從 gateway 中讀取索引資料。elasticsearch 支援多種型別的 gateway,有本地檔案系統(預設),分散式檔案系統,Hadoop 的 HDFS 和 amazon 的 s3 雲端儲存服務。
4)Discovery.zen
Elasticsearch 的discovery.zen代表 elasticsearch 的自動節點發現機制,而且 elasticsearch還是一個基於 P2P 的系統。首先它它會通過以廣播的方式去尋找存在的節點,然後再通過多播協議來進行節點之間的通訊,於此同時也支援點對點的互動操作。
5)Transport
Elasticsearch 的transport代表 elasticsearch 內部的節點或者叢集與客戶端之間的互動方式。預設的內部是使用 tcp 協議來進行互動的,同時它支援 http 協議(json格式)、thrift、servlet、memcached、zeroMQ等多種的傳輸協議(通過外掛方式整合)。
相關文章
- ElasticSearch 入門簡介Elasticsearch
- Elasticsearch 極簡入門Elasticsearch
- ElasticSearch極簡入門總結Elasticsearch
- Fiddler 入門簡介
- Kubernetes入門簡介
- Docker入門簡介Docker
- GraphQL 入門簡介
- CSS 入門簡介CSS
- Redis 入門 - 簡介Redis
- ElasticSearch簡介Elasticsearch
- 小白入門 - PHP簡介PHP
- ElasticSearch基本簡介Elasticsearch
- [譯]Elasticsearch 簡介Elasticsearch
- ElasticSearch 入門Elasticsearch
- phyon快速入門(python簡介)Python
- Android入門教程 | SharedPreferences 簡介Android
- GraphQL 快速入門【1】簡介
- Azure Terraform(一)入門簡介ORM
- ElasticSearch基本簡介(一)Elasticsearch
- Elasticsearch入門教程Elasticsearch
- ARouter簡單入門和介紹
- Vue.js入門 (一) - 簡介Vue.js
- gitbook 入門教程之 gitbook 簡介Git
- Azure Storage 系列(一)入門簡介
- Azure Data Factory(一)入門簡介
- Azure Key Vault(二)- 入門簡介
- Flutter入門教程(一)Flutter簡介Flutter
- 《Flink入門與實戰》簡介
- Python 入門系列 —— 1. 簡介Python
- Elasticsearch核心技術(二):Elasticsearch入門Elasticsearch
- 搜尋引擎ElasticSearch18_ElasticSearch簡介1Elasticsearch
- 【入門】分散式Session一致性入門簡介分散式Session
- EVE-NG簡單入門介紹
- MySQL入門系列:查詢簡介(二)MySql
- TypeScript基礎入門-函式-簡介TypeScript函式
- 爬蟲工程師的入門簡介爬蟲工程師
- html+css快速入門-css簡介HTMLCSS
- 我的Elasticsearch入門Elasticsearch