Logistic迴歸、softmax迴歸以及tensorflow實現MNIST識別
一、Logistic迴歸
Logistic迴歸為概率型非線性迴歸模型,是研究二分類結果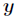
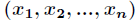
在講解Logistic迴歸理論之前,我們先從LR分類器說起。LR分類器,即Logistic Regression Classifier。在分類情形下,經過學習後的LR分類器是一組權值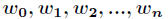
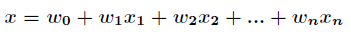
這裡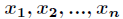
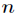
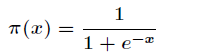
由於Sigmoid函式的定義域為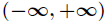
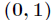
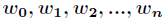
下面正式講Logistic迴歸模型。
考慮具有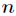
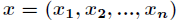
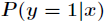
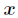
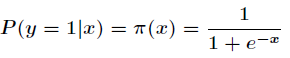
其中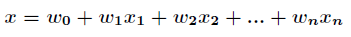
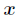

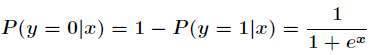
所以事件發生與不發生的概率之比為:

這個比值稱為事件的發生比(the odds of experiencing an event),簡記為odds。
可以看出Logistic迴歸都是圍繞一個Sigmoid函式來展開的。接下來就講如何用極大似然估計求分類器的引數。
假設有



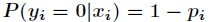

因為各個觀測樣本之間相互獨立,那麼它們的聯合分佈為各邊緣分佈的乘積。得到似然函式為

然後我們的目標是求出是這一似然函式的值最大的引數估計,最大似然估計就是求出引數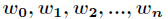
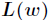
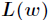
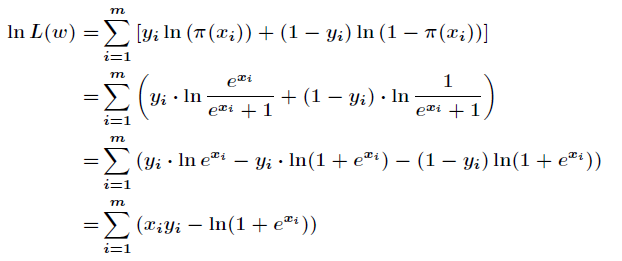
現在求向量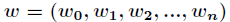
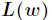
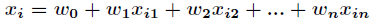
這裡介紹一種方法,叫做梯度下降法(求區域性極小值),當然相對還有梯度上升法(求區域性極大值)。對上述的似然函式求偏導後得到
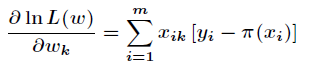
由於是求區域性極大值,所以跟據梯度上升法,有
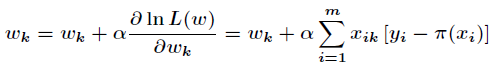
根據上述公式,只需初始化向量
二、softmax迴歸
softmax迴歸可以看成是Logistic迴歸的擴充套件。我們知道Logistic迴歸用於二分類,那麼如果我們面對多分類問題怎麼辦?最常見的例子就是MNIST手寫數字分類,今天要講的softmax迴歸能用於解決這類問題。
在Logistic迴歸中,樣本資料的值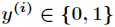


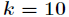
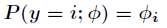
那麼
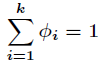
而且有
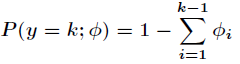
為了將多項式模型表述成指數分佈族,先引入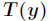
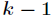
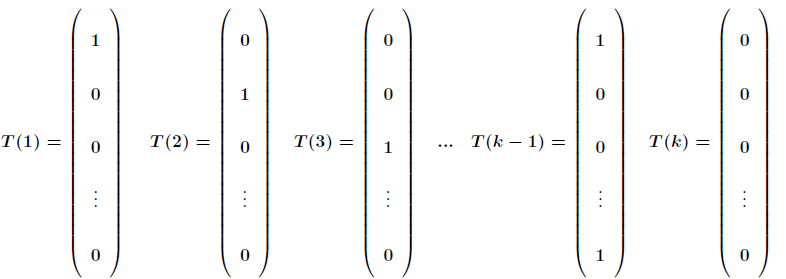
應用於一般線性模型,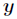

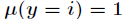
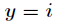
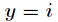
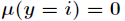
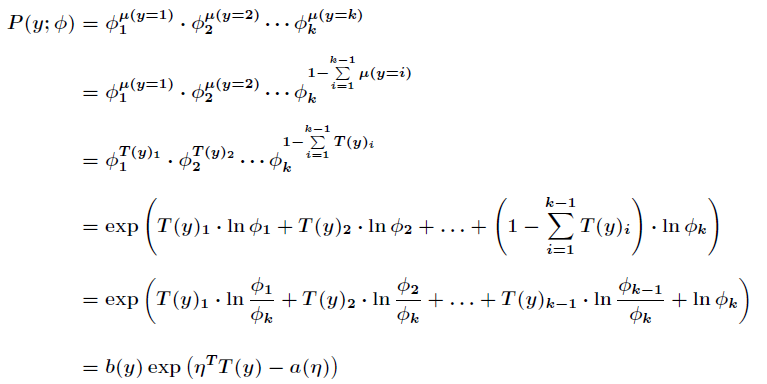
對比一下,可以得到
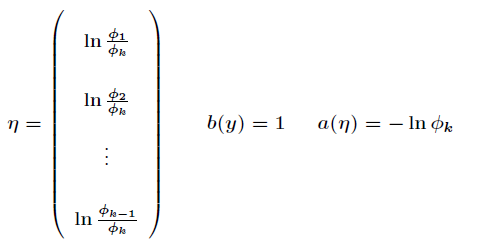
由於
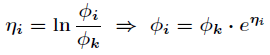
那麼最終得到

可以得到期望值為
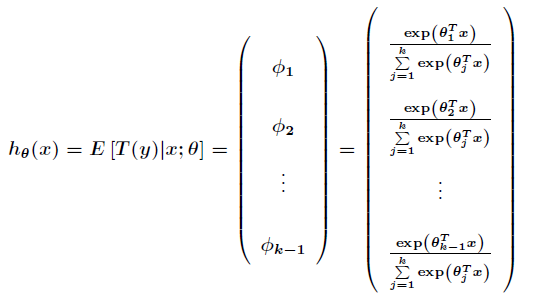
接下來得到對數似然函式為
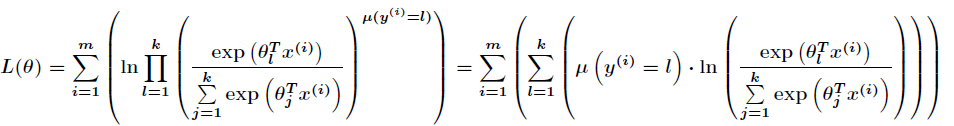
其中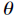
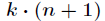

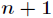

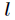
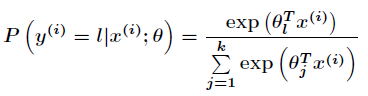
跟Logistic迴歸一樣,softmax也可以用梯度下降法或者牛頓迭代法求解,對對數似然函式求偏導數,得到
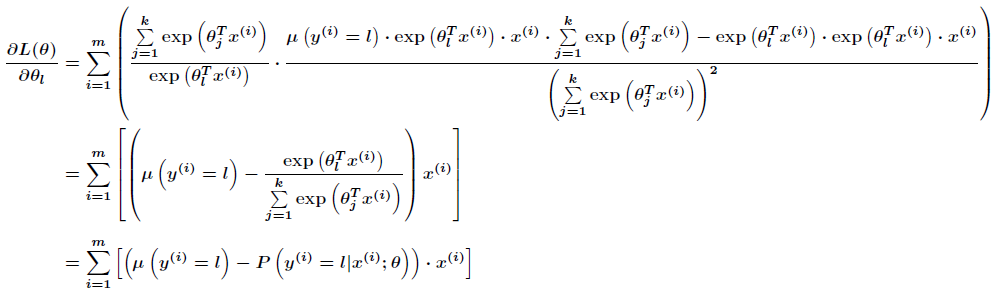
然後我們可以通過梯度上升法來更新引數

注意這裡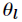
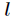
在softmax迴歸中直接用上述對數似然函式是不能更新引數的,因為它存在冗餘的引數,通常用牛頓方法中的Hessian矩陣也不可逆,是一個非凸函式,那麼可以通過新增一個權重衰減項來修改代價函式,使得代價函式是凸函式,並且得到的Hessian矩陣可逆。
三、TensorFlow實現MNIST手寫數字識別(利用到softmax迴歸)
#!/usr/bin/env python
import tensorflow as tf
import numpy as np
import tensorflow.examples.tutorials.mnist.input_data as input_data
# read MNIST data set
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
#trX, trY, teX, teY = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels
# create symbolic variables
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
# create variables: weights and biases
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# define model
y = tf.nn.softmax(tf.matmul(X, W) + b)
# cross entropy
cross_entropy = -tf.reduce_sum(Y * tf.log(y))
# train step
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
# init step
init = tf.initialize_all_variables()
with tf.Session() as sess:
# run the init op
sess.run(init)
# then train
for i in range(1000):
batch_trX, batch_trY = mnist.train.next_batch(128)
sess.run(train_step, feed_dict={X: batch_trX, Y: batch_trY})
# test and evaluate our model
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print sess.run(accuracy, feed_dict={X: mnist.test.images, Y: mnist.test.labels})參考:
相關文章
- Keras上實現Softmax迴歸模型Keras模型
- Softmax迴歸簡介
- 1.4 - logistic迴歸
- [機器學習實戰-Logistic迴歸]使用Logistic迴歸預測各種例項機器學習
- 機器學習實戰之Logistic迴歸機器學習
- TensorFlow實現線性迴歸
- 機器學習之Logistic迴歸機器學習
- 利用TensorFlow實現多元線性迴歸
- 利用TensorFlow實現多元邏輯迴歸邏輯迴歸
- 利用TensorFlow實現線性迴歸模型模型
- 利用Tensorflow實現邏輯迴歸模型邏輯迴歸模型
- tf.keras實現邏輯迴歸和softmax多分類Keras邏輯迴歸
- Logistic 迴歸-原理及應用
- 機器學習筆記(2): Logistic 迴歸機器學習筆記
- 機器學習之Logistic迴歸演算法機器學習演算法
- 前言以及迴歸分析
- python實現線性迴歸之簡單迴歸Python
- P2 鄒博機器學習logistic迴歸機器學習
- 【機器學習】Logistic迴歸ex2data2機器學習
- 迴歸分析類別
- 【TensorFlow篇】--Tensorflow框架初始,實現機器學習中多元線性迴歸框架機器學習
- 邏輯迴歸(Logistic Regression)原理及推導邏輯迴歸
- 吳恩達機器學習筆記 —— 7 Logistic迴歸吳恩達機器學習筆記
- 吳恩達機器學習課程05——Logistic迴歸吳恩達機器學習
- 機器學習筆記之Logistic迴歸演算法機器學習筆記演算法
- 對數機率迴歸(邏輯迴歸)原理與Python實現邏輯迴歸Python
- 迴歸
- [Rscript]邏輯迴歸識別學生群體的R實現邏輯迴歸
- 使用TensorFlow實現手寫識別(Softmax)
- ML-邏輯迴歸-Softmax-交叉熵(小航)邏輯迴歸熵
- 機器學習演算法:Logistic迴歸學習筆記機器學習演算法筆記
- 三、邏輯迴歸logistic regression——分類問題邏輯迴歸
- 【機器學習】線性迴歸sklearn實現機器學習
- pytorch實現線性迴歸PyTorch
- Tensorflow教程(前三)——邏輯迴歸邏輯迴歸
- 機器學習 | 線性迴歸與邏輯迴歸機器學習邏輯迴歸
- 迴歸問題知識樹
- 【動手學深度學習】第三章筆記:線性迴歸、SoftMax 迴歸、交叉熵損失深度學習筆記熵