平行計算cuda
本文從軟硬體層面講一下CUDA的結構,應用,邏輯和介面。分為以下章節:
(一)、GPU與CPU
(二)、CUDA硬體層面
(三)、CUDA安裝
(四)、CUDA 結構與介面
4.1 Kernels
4.2 Thread,Block, Grid
4.3 Memory
4.4 Execution
(五)、碼HelloWorld——陣列求和
希望感興趣的同學可以一起討論。
(一)、GPU與CPU
對於浮點數操作能力,CPU與GPU的能力相差在GPU更適用於計算強度高,多並行的計算中。因此,GPU擁有更多電晶體,而不是像CPU一樣的資料Cache和流程控制器。這樣的設計是因為多平行計算的時候每個資料單元執行相同程式,不需要那麼繁瑣的流程控制,而更需要高計算能力,這也不需要大cache。
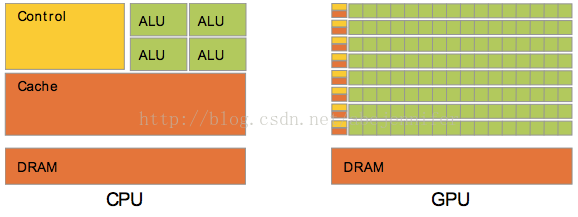
(二)、CUDA硬體層面:
Nvidia於2006年引入CUDA,一個GPU內嵌通用平行計算平臺。CUDA支援C, C++, Fortran, Java, Python等語言。
那麼一個多執行緒CUDA程式如何執行的呢?
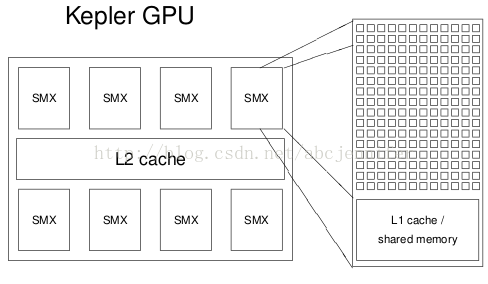
GPU建立在一組多處理器(SMX,Streaming Multiprocessors)附近。
一個SMX的配置:
- 192 cores(都是SIMT cores(Single Instruction Multiple Threads) and 64k registers(如下圖所示)
GPU中的SIMT對應於CPU中的SIMD(Single Instruction Multiple Data)
- 64KB of shared memory / L1 cache
- 8KB cache for constants
- 48KB texture cache for read-only arrays
- up to 2K threads per SMX
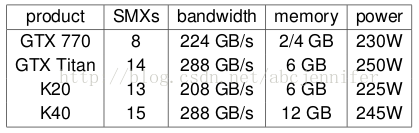
不同顯示卡有不同配置(即SMX數量不同),幾個例子:
每個multi-thread程式的execution kernel instance(kernel定義見下一節,instance指block)在一個SMX上執行,一個多執行緒程式會分配到blocks of threads(每個block中負責一部分執行緒)中獨立執行。所以GPU中的處理器越多執行越快(因為如果SMX不夠給每個kernel instance分配一個,就要幾個kernel搶一個SMX了)。具體來講,如果SMX上有足夠暫存器和記憶體(後面會講到,shared memory),就多個kernel instance在一個SMX上執行,否則放到佇列裡等。
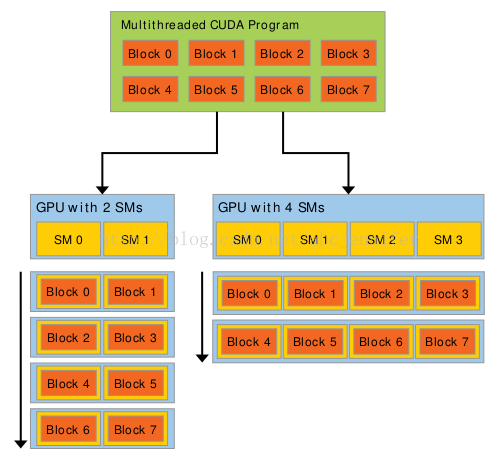
圖:表示不同SM數帶來的執行速度差異。
GPU工作原理:首先通過主介面讀取中央處理器指令,GigaThread引擎從系統記憶體中獲取特定的資料並拷貝到視訊記憶體中,為視訊記憶體控制器提供資料存取所需的高頻寬。GigaThread引擎隨後為各個SMX建立和分派執行緒塊(warp, 詳細介紹見SIMT架構或者CUDA系列學習(二)),SMX則將多個Warp排程到各CUDA核心以及其他執行單元。在圖形流水線出現工作超載的時候,GigaThread引擎還負責進行工作的重新分配。
(三)、CUDA安裝
裝CUDA主要裝以下3個組建:
1. driver
- low-level software that controls the graphics card
2. toolkit
- nvcc CUDA compiler
- profiling and debugging tools
- several libraries
3. SDK
- lots of demonstration examples
- some error-checking utilities
- not officially supported by NVIDIA
- almost no documentation
詳情請見CUDA
安裝與配置
(四)、CUDA 結構與介面
4.1 Kernels
CUDA C 中可通過定義kernel,每次被呼叫就在N個CUDA thread中並行執行。
kernel的定義:
- 宣告 __global__
- 配置kernel_routine<<<gridDim, Blockdim>>>(args)
其中gridDim和Blockdim變數可以是int或dim3(<=3維)型別的變數。gridDim表示每個grid中block結構(the number of instances(blocks) of the kernel),Blockdim表示每個block中thread結構。那麼。。thread,block,grid又是啥?往下看。。。見4.2節
- 每個執行該kernel的thread都會通過被分配到一個unique thread ID,就是built-in變數:threadIdx
4.2 Thread,Block,Grid
很多threads組成1維,2維or3維的thread block. 為了標記thread在block中的位置(index),我們可以用上面講的threadIdx。threadIdx是一個維度<=3的vector。還可以用thread index(一個標量)表示這個位置。
thread的index與threadIdx的關係:
|
|
Thread index |
| 1 | T |
| 2 | T.x + T.y * Dx |
| 3 | T.x+T.y*Dx+z*Dx*Dy |
其中T表示變數threadIdx。(Dx, Dy, Dz)為block的size(每一維有多少threads)。
因為一個block內的所有threads會在同一處理器核心上共享記憶體資源,所以block內有多少threads是有限制的。目前GPU限制每個 block最多有1024個threads。但是一個kernel可以在多個相同shape的block上執行,效果等效於在一個有N*#thread per block個thread的block上執行。
Block又被組織成grid。同樣,grid中block也可以被組織成1維,2維or3維。一個grid中的block數量由系統中處理器個數或待處理的資料量決定。
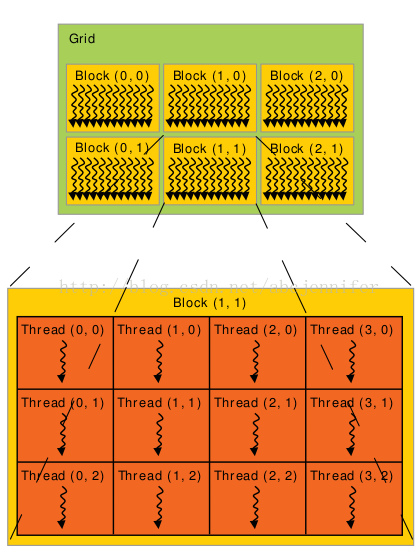
和threadIdx類似,對於block有built-in變數blockDim(block dimension)和blockIdx(block index)。
回過頭來看4.1中的configureation,舉個栗子,假設A,B,C都是大小[N][N]的二維矩陣,kernel MatAdd目的將A,B對應位置元素加和給C的對應位置。
宣告:
- // Kernel definition
- __global__ void MatAdd(float A[N][N], float B[N][N],
- float C[N][N])
- {
- int i = blockIdx.x * blockDim.x + threadIdx.x;
- int j = blockIdx.y * blockDim.y + threadIdx.y;
- if (i < N && j < N)
- C[i][j] = A[i][j] + B[i][j];
- }
- int main()
- {
- ...
- // Kernel invocation
- dim3 threadsPerBlock(16, 16);
- dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
- MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
- ...
- }
這裡threadsPerBlock(16,16)一般是標配。例子中,我們假定grid中block足夠多,保證N/threadsPerBlock不會超限。
4.3 Memory
前面提到了Block中的threads共享記憶體,那麼怎樣同步呢?在kernel中呼叫內部__synthreads()函式,其作用是block內的所有threads必須全部執行完,程式才能繼續往下走。那麼thread到底怎樣使用memory呢?
- 每個thread有private local memory
- 每個block有shared memory
- 所有thread都能訪問到相同的一塊global memory
- 所有thread都能訪問兩塊read-only memory:constant & texture array(通常放查詢表)
其中,global,constant,texture memory伴隨kernel生死。
CUDA程式執行的時候,GPU就像一個獨立的裝置一樣,kernel部分由GPU執行,其餘部分CPU執行。於是memory就被分為host memory(for CPU)& device memory(for GPU)。因此,一個程式需要在CUDA執行時管理device memory的分配,釋放和device & host memory之間的data transfer。
4.4 Execution
從執行角度看,程式經過了以下步驟:
1. initialises card
2. allocates memory in host and on device
3. copies data from host to device memory
4. launches multiple instances of execution “kernel” on device
5. copies data from device memory to host
6. repeats 3-5 as needed
7. de-allocates all memory and terminates
總結:每個kernel放在一個grid上執行,1個kernel有多個instance,每個instance在一個block上執行,每個block只能在一個SM上執行,如果block數>SM數,多個block搶SM用。kernel的一個instance在SMX上通過一組程式來執行。如下圖所示:
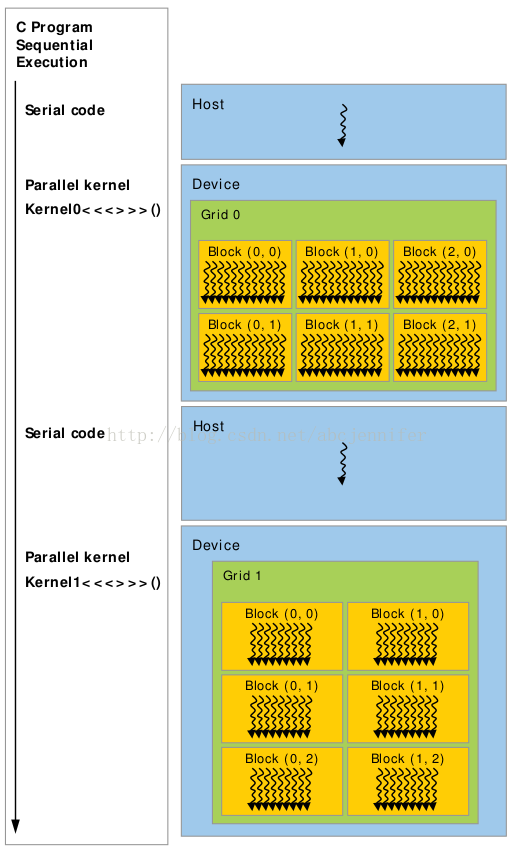
總結:
CUDA的3個key abstraction:thread groups, shared memories, 和barrier synchronization
CUDA中的built-in變數:gridDim, blockDim, blockIdx(block在grid中的index), threadIdx, warpSize(threads的warp size)
(五)、碼HelloWorld
- kernel code很像MPI,從單執行緒的角度coding
- 需要think about每個變數放在哪塊記憶體
這裡我們以陣列對應元素相加為例,看下Code :
- #include<cutil_inline.h>
- #include<iostream>
- using namespace std;
- #define N 32
- // Kernel definition
- __global__ void MatAdd(float A[N], float B[N], float* C)
- {
- int i = blockIdx.x * blockDim.x + threadIdx.x; //get thread index by built-in variables
- if (i < N)
- C[i] = A[i] + B[i];
- }
- int main()
- {
- float A[N],B[N]; // host variable
- float *dA, *dB; // device variable, to have same value with A,B
- float *device_res, *host_res; // device and host result, to be device and host variable respectively
- // initialize host variable
- memset(A,0,sizeof(A));
- memset(B,0,sizeof(B));
- A[0] = 1;
- B[0] = 2;
- // allocate for device variable and set value to them
- cudaMalloc((void**) &dA,N*sizeof(float));
- cudaMalloc((void**) &dB,N*sizeof(float));
- cudaMemcpy(dA, A, N*sizeof(float),cudaMemcpyHostToDevice);
- cudaMemcpy(dB, B, N*sizeof(float),cudaMemcpyHostToDevice);
- //malloc for host and device variable
- host_res = (float*) malloc(N*sizeof(float));
- cudaMalloc((void**)&device_res, N*sizeof(float));
- // Kernel invocation
- int threadsPerBlock = 16;
- int numBlocks = N/threadsPerBlock;
- MatAdd<<<numBlocks, threadsPerBlock>>>(dA, dB, device_res);
- cudaMemcpy(host_res, device_res, N*sizeof(float),cudaMemcpyDeviceToHost); //copy from device to host
- // validate
- int i;
- float sum = 0;
- for(i=0;i<N;i++)
- sum += host_res[i];
- cout<<sum<<endl;
- //free variables
- cudaFree(dA);
- cudaFree(dB);
- cudaFree(device_res);
- free(host_res);
- }
編譯:
nvcc -I ~/NVIDIA_GPU_Computing_SDK/C/common/inc/ Matadd.cu
執行結果:
3
OK,大功告成。
這裡注意kernel部分的code,所有變數都必須是device variable,即需要通過cudaMalloc分配過memory的。之前我忘記將A,B陣列cudaMemcpy到dA,dB,而直接傳入MatAdd
kernel就出現了執行一次過後卡住的問題。
參考:
3. CUDA
安裝與配置
5. GPU工作方式
6. Fermi 架構白皮書(GPU繼承了Fermi的很多架構特點)
7. GTX460架構
相關文章
- cuda程式設計與gpu平行計算(四):cuda程式設計模型程式設計GPU模型
- CUDA 高效能平行計算入門
- 平行計算π值
- Oracle平行計算Oracle
- GPU:平行計算利器GPU
- 淺談.NET下的多執行緒和平行計算(十四)平行計算前言執行緒
- java8平行計算Java
- 平行計算與Neon簡介
- cuda程式設計與gpu平行計算(六):圖稀疏矩陣轉為CSR結構並傳入gpu程式設計GPU矩陣
- 雲端計算分散式平行計算:系統架構分散式架構
- 大文字平行計算實現方式
- OpenCV使用ParallelLoopBody進行平行計算OpenCVParallelOOP
- springboot~CompletableFuture平行計算Spring Boot
- NVDIA CUDA ---------GPU計算的革命GPU
- PostgreSQL11preview-ParallelAppend(多表平行計算)sharding架構平行計算核心功能之一SQLViewParallelAPP架構
- 瞭解Flow -- elixir的平行計算庫
- 引文——平行計算的學習之殤
- 多核平行計算時代的來臨
- 請問,平行計算和資料庫資料庫
- 後端請求中的非同步計算與平行計算後端非同步
- 黃仁勳:序列計算過時平行計算是未來
- [930]python平行計算框架pathos模組Python框架
- 【1】Embarrassingly Parallel(易平行計算問題)Parallel
- 大資料平行計算利器之MPI/OpenMP大資料
- 推薦文章:多執行緒平行計算執行緒
- JDK7的平行計算功能升級JDK
- HPC高效能運算知識: 異構平行計算
- 完數的OpenMP並行程式設計-平行計算並行行程程式設計
- 完數的MPI並行程式設計-平行計算並行行程程式設計
- PostgreSQL11preview-平行計算增強彙總SQLView
- Java通過Fork/Join來優化平行計算Java優化
- 在“平行計算”中增加了幾篇文章
- [索引]Oracle RAC資料庫平行計算的使用索引Oracle資料庫
- 使用 QuTrunk+Amazon ParallelCluster3 進行平行計算Parallel
- 第二篇:從 GPU 的角度理解平行計算GPU
- Linux叢集的安裝與平行計算(轉)Linux
- .NET4.0平行計算技術基礎(2)
- .NET4.0平行計算技術基礎(1)