前言
本文從使用 GPU 程式設計技術的角度來了解計算中並行實現的方法思路。
平行計算中需要考慮的三個重要問題
1. 同步問題
在作業系統原理的相關課程中我們學習過程式間的死鎖問題,以及由於資源共享帶來的臨界資源問題等,這裡不做累述。
2. 併發度
有一些問題屬於 “易並行” 問題:如矩陣乘法。在這型別問題中,各個運算單元輸出的結果是相互獨立的,這類問題能夠得到很輕鬆的解決 (通常甚至呼叫幾個類庫就能搞定問題)。
然而,若各個運算單元之間有依賴關係,那問題就複雜了。在 CUDA 中,塊內的通訊通過共享記憶體來實現,而塊間的通訊,則只能通過全域性記憶體。
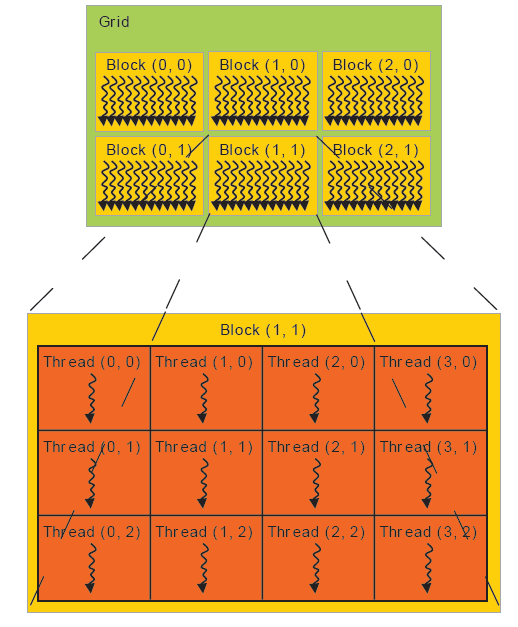
CUDA 並行程式設計架構可以用網格 (GRID) 來形容:一個網格好比一隻軍隊。網格被分成好多個塊,這些塊好比軍隊的每個部門 (後勤部,指揮部,通訊部等)。每個塊又分成好多個執行緒束,這些執行緒束好比部門內部的小分隊,下圖可幫助理解:
3. 區域性性
在作業系統原理中,對區域性性做過重點介紹,簡單來說就是將之前訪問過的資料 (時間區域性性) 和之前訪問過的資料的附近資料 (空間區域性性) 儲存在快取中。
在 GPU 程式設計中,區域性性也是非常重要的,這體現在要計算的資料應當在計算之前儘可能的一次性的送進視訊記憶體,在迭代的過程中一定要儘可能減少資料在記憶體和視訊記憶體之間的傳輸,實際專案中發現這點十分重要的。
對於 GPU 程式設計來說,需要程式猿自己去管理記憶體,或者換句話來說,自己實現區域性性。
平行計算的兩種型別
1. 基於任務的並行處理
這種並行模式將計算任務拆分成若干個小的但不同的任務,如有的運算單元負責取數,有的運算單元負責計算,有的負責...... 這樣一個大的任務可以組成一道流水線。
需要注意的是流水線的效率瓶頸在於其中效率最低的那個計算單元。
2. 基於資料的並行處理
這種並行模式將資料分解為多個部分,讓多個運算單元分別去計算這些小塊的資料,最後再將其彙總起來。
一般來說,CPU 的多執行緒程式設計偏向於第一種並行模式,GPU 並行程式設計模式則偏向於第二種。
常見的並行優化物件
1. 迴圈
這也是最常見的一種模式,讓每個執行緒處理迴圈中的一個或一組資料。
這種型別的優化一定要小心各個運算單元,以及每個運算單元何其自身上一次迭代結果的依賴性。
2. 派生/彙集模式
該模式下大多數是序列程式碼,但程式碼中的某一段可以並行處理。
典型的情況就是某個輸入佇列當序列處理到某個時刻,需要對其中不同部分進行不同處理,這樣就可以劃分成多個計算單元對改佇列進行處理 (也即派生),最後再將其彙總 (也即彙集)。
這種模式常用於併發事件事先不定的情況,具有 “動態並行性”。
3. 分條/分塊模式
對於特別龐大的資料 (如氣候模型),可以將資料分為過個塊來進行平行計算。
4. 分而治之
絕大多數的遞迴演算法,比如快速排序,都可以轉換為迭代模型,而迭代模型又能對映到 GPU 程式設計模型上。
特別說明:雖然費米架構和開普勒架構的 GPU 都支援緩衝棧,能夠直接實現遞迴模型到 GPU 並行模型的轉換。但為了程式的效率,在開發時間允許的情況下,我們最好還是先將其轉換為迭代模型。