雲端計算分散式平行計算:系統架構
系列文章:
Dryad系統的總體的構建用來支援有向無環圖(Directed Acycline Graph,DAG)型別資料流的並行程式。Dryad的整體框架根據程式的要求完成排程工作,自動完成任務在各個節點上的執行。在Dryad平臺上,每個Dryad工作或平行計算過程被表示為一個有向無環圖。圖中的每個節點表示一個要執行的程式,節點之間的邊表示資料通道中資料的傳輸方式,其可能是檔案、TCP Pipe、共享記憶體等,為了支援資料型別需要針對每個型別有序列化程式碼。
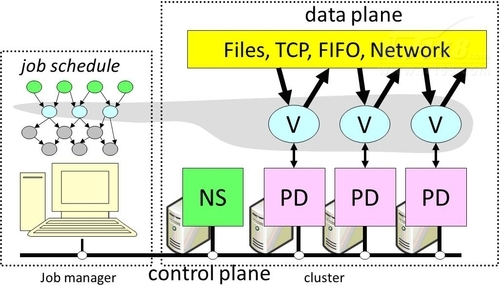
▲圖1 Dryad系統結構
如圖1所示,當使用者使用Dryad平臺時,首先是需要在任務管理(JM)節點上建立自己的任務。每一個任務由一些處理過程以及在這些處理過程資料傳遞組成。工作管理員(JM)獲取無環圖之後,便會在程式的輸入通道準備,當有可用機器的時候便對它進行排程。JM從命名伺服器(NS)那裡獲得一個可用的計算機列表,並通過一個維護程式(PD)來排程這個程式。
系統元件:
工作管理員(Job Manager,JM):每個Job的執行被一個Job Manager控制,該元件負責例項化這個Job的工作圖;在計算機群上排程節點的執行;監控各個節點的執行情況並收集一些資訊;通過重新執行來提供容錯;根據使用者配置的策略動態地調整工作圖;
計算機群(Cluster):用於執行工作圖中的節點;
命名伺服器(Name Server,NS):負責維護Cluster中各個機器的資訊;
維護程式(PDaemon,PD):程式監管與排程工作。
從總體來看,傳統的Linux/Unix管道是一維管道,每個節點在管道中是單個的程式。而Dryad的執行過程就可以看做是一個二維的管道流的處理過程。其中,每個節點可以具有多個程式的執行,通過這種演算法可以同時處理大規模資料。
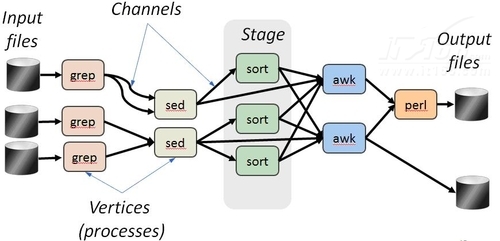
▲圖2 Dryad任務結構
如圖2所示,我們可以看到,在每個節點程式(Vertices Processes)上都有一個處理程式在執行,並且通過資料管道(Channels)的方式在它們之間傳送資料。二維的Dryad管道模型定義了一系列的操作,可以用來動態的建立並且改變這個有向無環圖。這些操作包括建立新的節點,在節點之間加入邊,合併兩個圖以及對任務的輸入和輸出進行處理等。
與微軟Dryad相似,MapReduce程式設計模型可用於大規模資料集(大於1TB)的並行運算。概念“Map(對映)”和“Reduce(化簡)”,它們的主要思想都是從函數語言程式設計語言裡借來的,還有從向量程式語言裡借來的特性。MapReduce對映處理結構,如圖3所示。
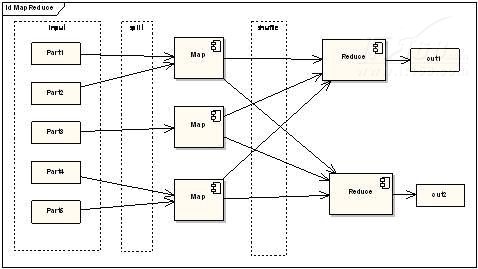
▲圖3 MapReduce對映處理結構
從上圖可以看出,MapReduce極大地方便了程式設計人員在不會分散式並行程式設計的情況下,將自己的程式執行在分散式系統上。當前的軟體實現是指定一個Map(對映)函式,用來把一組鍵值對對映成一組新的鍵值對,指定併發的Reduce(化簡)函式,用來保證所有對映的鍵值對中的每一個共享相同的鍵組。微軟Dryad與谷歌的MapReduc對映原理相似,但不同的是通過DryadLINQ來實現分散式程式程式設計設計。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/25436212/viewspace-690374/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 分散式雲端計算分散式
- 雲端計算架構架構
- 系統架構設計筆記(105)—— 雲端計算架構筆記
- 雲端計算的架構架構
- 雲端計算,網格計算,分散式計算,叢集計算的區別?分散式
- [分散式]分散式計算系統淺析分散式
- 億級流量系統架構之如何設計高容錯分散式計算系統架構分散式
- (OO + 分散式計算) = 軟體架構的方向分散式架構
- 億級流量系統架構之如何設計高容錯分散式計算系統【石杉的架構筆記】架構分散式筆記
- PostgreSQL11preview-ParallelAppend(多表平行計算)sharding架構平行計算核心功能之一SQLViewParallelAPP架構
- 線上遊戲為何青睞雲端計算?揭祕手遊雲端計算架構遊戲架構
- 雲端計算-從基礎到應用架構系列-雲端計算的演進應用架構
- 【雲端計算】數字化時代,邊緣計算參考架構架構
- 雲端計算生態系統
- 平行計算π值
- Oracle平行計算Oracle
- 平行計算cuda
- 雲端計算是什麼意思?3張圖看懂雲端計算架構架構
- 雲端計算教程學習入門影片課件:雲端計算架構參考模型架構模型
- 雲端計算開發學習教程,雲端計算基礎架構實現講解架構
- 挑戰傳統集中式雲端計算架構,分散式雲的核心要義是什麼?架構分散式
- 分散式系統中的自主自治計算 - pathelland分散式
- Spark:一個高效的分散式計算系統Spark分散式
- GPU:平行計算利器GPU
- 雲端計算時代下的大型ERP系統架構, 演講完畢...架構
- 初識雲端計算:歷史、服務、架構架構
- “雲端計算”時代 儲存架構如何變化架構
- 開源雲端計算Iaas平臺CloudStack架構Cloud架構
- 移動的雲端計算技術架構1:架構
- IaaS雲端計算基礎設施與架構架構
- 程式設計體系結構(09):分散式系統架構程式設計分散式架構
- 從雲端計算到函式計算函式
- 什麼是分散式計算系統?—Vecloud微雲分散式Cloud
- 計算機架構計算機架構
- HPC高效能運算知識: 異構平行計算
- 論文榮登計算機體系結構頂會ISCA,晶片架構成為邊緣AI最佳平行計算選擇計算機晶片架構AI
- 《雲端計算》)——超越桌面:雲端計算導論
- Uber實時資料基礎設施:分散式計算架構分散式架構