大資料入門到精通,想入行大資料需要學習這些知識
歡迎大家評論留言發表自己的觀點,大資料還需要掌握哪些知識或者技術。
基礎概念
大資料的本質
一、資料的儲存:分散式檔案系統(分散式儲存)
二、資料的計算:分部署計算
基礎知識
學習大資料需要具備Java知識基礎及Linux知識基礎
學習路線
(1)Java基礎和Linux基礎
(2)Hadoop的學習:體系結構、原理、程式設計
第一階段:HDFS、MapReduce、HBase(NoSQL資料庫)
第二階段:資料分析引擎 -> Hive、Pig
資料採集引擎 -> Sqoop、Flume
第三階段:HUE:Web管理工具
ZooKeeper:實現Hadoop的HA
Oozie:工作流引擎
(3)Spark的學習
第一階段:Scala程式語言
第二階段:Spark Core -> 基於記憶體、資料的計算
第三階段:Spark SQL -> 類似於mysql 的sql語句
第四階段:Spark Streaming ->進行流式計算:比如:自來水廠
(4)Apache Storm 類似:Spark Streaming ->進行流式計算
NoSQL:Redis基於記憶體的資料庫
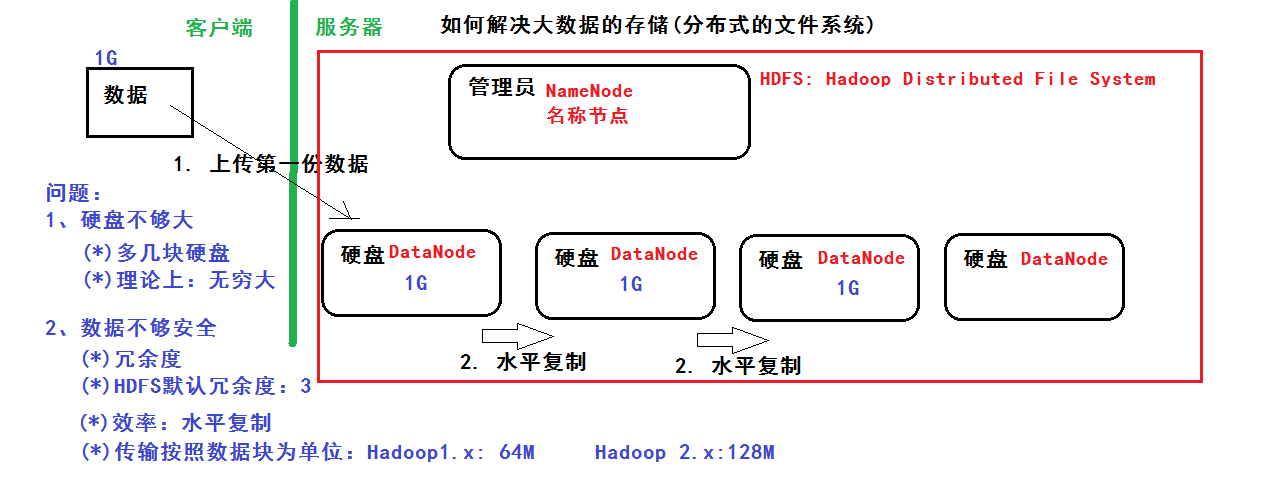
HDFS
分散式檔案系統 解決以下問題:
• 硬碟不夠大:多幾塊硬碟,理論上可以無限大
• 資料不夠安全:冗餘度,hdfs預設冗餘為3 ,用水平復制提高效率,傳輸按照資料庫為單位:Hadoop1.x 64M,Hadoop2.x 128M
• 管理員:NameNode 硬碟:DataNode
MapReduce
基礎程式設計模型:把一個大任務拆分成小任務,再進行彙總
• MR任務:Job = Map + Reduce
Map的輸出是Reduce的輸入、MR的輸入和輸出都是在HDFS
MapReduce資料流程分析:
• Map的輸出是Reduce的輸入,Reduce的輸入是Map的集合


HBase
什麼是BigTable?: 把所有的資料儲存到一張表中,採用冗餘 ---> 好處:提高效率
• 因為有了bigtable的思想:NoSQL:HBase資料庫
• HBase基於Hadoop的HDFS的
• 描述HBase的表結構
核心思想是:利用空間換效率

大資料工程涉及大量資料的設計,部署,獲取以及維護(儲存)。大資料工程師需要去設計和部署這樣一個系統,使相關資料能面向不同的消費者及內部應用。
1. 而大資料分析的工作則是利用大資料工程師設計的系統所提供的大量資料。大資料分析包括趨勢、圖樣分析以及開發不同的分類、預測預報系統。
2.因此,簡而言之,大資料分析是對資料的高階計算。而大資料工程則是進行系統設計、部署以及計算執行平臺的頂層構建。
3.如何成為一名大資料工程師
我們知道大資料領域充斥著多種技術。因此,你學習與你的大資料工作角色相關的技術非常重要。這與任何常規領域有點不同,如資料科學和機器學習中,你可以從某些地方開始並努力完成這一領域內的所有工作。
4.資源,想要大資料學習資料可以加入我們大資料開發學習群
學習一個新的東西肯定是需要需要學習資料,沒有資料從何學習呢。零基礎.進階.專案實戰歡迎加入319819749
相關文章
- 大資料入門到精通課程學習,大資料學習,你還得知道這些大資料
- 2018大資料學習路線從入門到精通大資料
- 2018最新大資料學習路線從入門到精通大資料
- 學習大資料需要掌握的知識,需要學習的資料技術大資料
- 大資料入門學習,你要掌握這些技能大資料
- 學大資料需要掌握的知識,需要學習的資料技術大資料
- 大資料架構師從入門到精通 學習必看寶典大資料架構
- 大資料架構師從入門到精通大資料架構
- 想學習大資料?這才是完整的大資料學習體系大資料
- 大資料應用開發如何入門需要知道這些大資料
- 大資料分析入門基礎知識學什麼?大資料
- 大資料學習:怎樣進行大資料的入門級學習?大資料
- 大資料學習,涉及的知識點大資料
- 大資料學習入門看什麼書?大資料新手怎麼入門?大資料
- 大資料怎樣入門學習?大資料
- 學習大資料,一定要了解大資料的這些用途大資料
- 大資料學習|小白學習大資料需要滿足這六個條件你就能學好大資料大資料
- 入行IT界,0基礎如何學習大資料?大資料
- 資料庫MySQL需要學習基本知識資料庫MySql
- hadoop大資料平臺安全基礎知識入門Hadoop大資料
- 大資料學習:零基礎大資料入門該看哪些書?大資料
- 大資料學習四:網路相關知識大資料
- 大資料工程師需要掌握的知識點大資料工程師
- 大資料學習方法,學大資料需要的基礎和路線大資料
- 大資料入門大資料
- 大資料學習入門規劃?和學習路線大資料
- 想從事資料科學領域,需要多少數學知識?資料科學
- 學習大資料需要什麼基礎?大資料要學哪些內容?大資料
- 大資料學習入門難,給初學者支招大資料
- 大資料學習資料大資料
- 搞大資料,Java 工程師需要掌握哪些知識?大資料Java工程師
- 部門有界資料無界大資料需要大胸懷大資料
- 入門大資料---大資料調優彙總大資料
- 想自學大資料開發 鄭州大資料學習路線是什麼大資料
- 大資料入門001大資料
- 大話 資料入門
- 知識學習綜合三---分散式系統大資料分散式大資料
- 如何更高效的系統學習大資料方面知識?大資料