《世界是數字的》是世界頂尖電腦科學家Brian W.Kernighan寫的一本計算機科普類讀物,簡明扼要但又深入全面地解釋了計算機和通訊系統背後的祕密,適合計算機初學者和非計算機專業的人讀。這真的是一本好書,借Google常務董事長的話:
對計算機、網際網路及其背後的奧祕充滿好奇的人們,這絕對是一本不容錯過的好書。
對於一個計算機已經學了N年的專業人士來說,這本書也許簡單了點,不過我還是認真過了一遍,發現也有一定的收貨,因為一個人很難掌握本領域裡的所有知識,或多或少會有一些欠缺,總會有一些你以前不知道的,或一直沒理解清楚的但又很有必要知曉的知識,我在閱讀此書過程中就有這種感覺,經常會有一種恍然大悟的感覺,比如理解了網際網路上一些不為人知的跟蹤原理(具體可以看我下面總結的第12點“Cookie如何暴露你在網際網路上的行蹤”)。我是個喜歡記筆記和做總結的人,閱讀完一本書,我經常會找個閒暇的時間總結下,主要是根據自己已有的知識儲備體系總結一些對我有幫助的或有必要知道的知識點。
下面就簡單總結下自己的所獲和所感。
注意:下面的知識都是科普知識,適合非計算機專業、計算機初學者及和像我一樣計算機一開始就沒學好的人看,那些牛B的大牛就不用來浪費時間來讀你們已稱之為“常識”的知識啦。
1. P和NP問題
現在的程式設計師都很怕遇到NP問題,不僅演算法複雜而且還保證不了每次都能找到解。那到底什麼是P問題和NP問題呢?作為一個程式設計師,你如果回答說“P問題就是容易的問題,NP問題就是複雜的難以解決的問題”那就太失敗了。P即“Polynomial”(多項式),P問題是指具有“多項式”級複雜性的問題。換句話說,解決這些問題的時間可以用N^2這樣的多項式來表示,其中指數可以大於2,但都是可能在多項式時間內被解決的,這些問題相對比較簡單。
但是,現實中大量的問題或者說很多實際的問題似乎都需要指數級演算法來解決,即我們還不知道對這類問題有沒有多項式演算法。這類問題被稱為“NP(nondeterministic polynomial,非確定性多項式)”問題。NP 問題的特點是,它可以快速驗證某個解決方案是否正確,但要想迅速找到一個解方案卻很難。可以這麼認為,這些問題可以用一個演算法在多項式時間內靠猜測來解決,而且該演算法必須每次都能猜中。在現實生活中,沒有什麼能幸運到始終都做出正確的選擇,所以這只是理論上的一種設想而已。
可以舉個簡單的例子來說明NP問題,那就是著名的“旅行推銷員問題”(Traveling Salesman Problem)。一個推銷員必須從他居住的城市出發,到其他幾個城市去推銷,然後再回家。目標是每個城市只到一次(不能重複),而且走過的總距離最短。這個問題實際應用價值很大,其原理經常被應用於設計電路板上孔洞的位置,或者部署船隻到墨西哥灣的特定地點採集水樣。旅行推銷員問題已經被仔細推敲了50 多年,但還是解決不了NP難問題。
現在業界內也經常討論一個問題:P 是否等於NP?即這些難題到底跟那些簡單的問題是不是一類?
儘管很多人都相信未來的某一天可以達到P=NP,但我還是希望這一天不要太早到來,因為現在一些重要的應用,如加密軟體,都是完全建立在某個特定的問題確實極難解決的基礎之上的。設想一下,如果某天這些難問題都被攻破了,那我們的各個賬號密碼、網銀豈不是要……當然,如果真有那麼一天,也表明計算機領域又有了一個重大的突破,這是值得可賀的。
2. 沒有刪除只有覆蓋
我們知道,磁碟沒有真正的刪除,我們所謂的“delete”操作只是把檔案佔用的塊回寫到空閒塊列表。但是,這些檔案的內容並沒有被刪除。換句話說,原始檔案佔用的每個塊中的所有位元組都會原封不動地呆在原地。除非相應的塊從空閒塊列表中被“除名”並奉送給某個應用程式,否則這些位元組不會被新內容覆蓋。這意味著什麼呢?意味著你認為已經刪除的資訊實際上還儲存在硬碟上。如果有人知道怎麼讀取它們,仍然可以把它們讀出來。任何可以不通過檔案系統而能夠逐塊讀取硬碟的程式,都可以看到那些被“刪除”的內容。
那麼如何真正的徹底刪除呢?Mac中的“安全擦除”選項在釋放磁碟塊之前,會先用隨機生成的位元重寫其中的內容。但是即使用新資訊重寫了原有內容,一名訓練有素的敵人仍舊可以憑藉他掌握的大量資源發現蛛絲馬跡。軍事級的檔案擦除會用隨機的1 和0 對要釋放的塊進行多遍重寫。更為保險的做法是把整塊硬碟放到強磁場裡進行消磁。而最保險的做法則是物理上銷燬硬碟,這也是保證其中內容徹底銷聲 匿跡的唯一可靠方法。
也有一些徹底刪除檔案的軟體,比如我用過的BCWipe(是看韓國黑客犯罪片“幽靈”時知道的,劇裡經常用這個軟體刪除機密檔案),它提供 Delete with wiping、Wipe free disk space 兩種方式來清除你的磁碟檔案,還有其它選項,不過這款軟體是收費軟體,我只試用過一段時間,我本人沒啥見不得人的檔案,也不需要此類軟體,只是當時看完電視好奇試玩了一把。
3. 無線網路上網原理
從技術角度講,無線網路利用電磁波傳送訊號。電磁波是特定頻率的電波,其振動頻率以Hz 來衡量(讀者可能更熟悉廣播電臺常用的MHz 或GHz,比如北京交通廣播電臺的頻率是103.9 MHz)。在傳送訊號之前,首先要通過調製把資料訊號附加到載波上。比如,調幅(AM)就是通過改變載波的振幅或強度來傳達資訊,而調頻(FM)的原理則是圍繞一箇中心值來改變載波的頻率。接收器接收到訊號的強度與發射器的功率成正比,與到發射器距離的平方成反比。由於存在這種二次方遞減的關係,距離發射器的距離增加一倍,接收器接收到的訊號強度就只有原來的四分之一。無線電波穿越各種物質時強度都會衰減,物質不同衰減程度也不同,比如說金屬就會遮蔽任何電波(突然想起《超驗駭客》電影裡卡斯特家花園裡建的用來遮蔽訊號的金屬網)。高頻比低頻更容易被吸收,二者在其他方面都一樣。
無線聯網對可以使用的頻率範圍—頻段,以及使用多大的功率傳送電波都有嚴格規定。頻段分配始終都是一個有爭議的話題,因為各種需求總會發生衝突。
無線乙太網裝置發射的電波頻率為2.4~2.5 GHz,某些802.11 裝置的頻率會達到5 GHz。所有無線裝置的頻率都侷限於這一較窄的範圍內,衝突的可能性大大增加。更糟的是,有些無線電話、醫療裝置,甚至微波爐也跟著湊熱鬧,同樣使用這一頻段。有一次作者在使用廚房裡那臺舊筆記本時無線連線突然斷了,後來才發現是用微波爐加熱咖啡的緣故。30 秒鐘的加熱就足以讓筆記本斷開無線連線。
下面介紹三種使用最廣泛的無線聯網技術。
(1)首先就是藍芽,藍芽技術是為近距離臨時性連線而發明的,使用與802.11 相同的2.4 GHz 頻段。藍芽連線的距離是1 到100 米,具體取決於功率大小,資料傳輸速度為1~3 Mbit/s。使用藍芽技術的裝置主要包括無線麥克風、耳機、鍵盤、滑鼠、遊戲手柄,功率相對較低。
(2)第二種技術是RFID(radio-frequency identification),即無線射頻識別,主要用於電子門禁、各種商品的電子標籤、自動收費系統、寵物植入晶片,以及護照等身份證明。 **RFID 標籤其實就是一個小型無線訊號收發裝置,對外廣播身份資訊。被動式標籤不帶電源,通過天線接收到的RFID 讀取器廣播的訊號來驅動。RFID 系統使用多種不同的頻率,比較常見的是13.56 MHz。**RFID 晶片讓祕密監視物體和人的行蹤成為可能。 植入寵物體內的晶片就是一種常見的應用,已經有人建議也給人植入這種晶片了。至於動機嘛,就不好說了。
(3)最後一種是GPS(Global Positioning System,全球定位系統),它是一種重要的單向無線系統,常見於汽車和手機導航系統中。GPS衛星會廣播精確的時間資訊,而GPS接收器會根據它從三四顆衛星接收到訊號的時間來計算自己在地面的位置。然而,GPS只接收訊號不傳送訊號。以前曾有一個關於GPS 的誤解,認為它能悄悄地跟蹤使用者。給大家摘錄一段《紐約時報》幾年前鬧的一個笑話吧:“有些(手機)依靠全球定位系統,也就是GPS,通過向衛星傳送訊號來精確地定位使用者。”這完全是誤解。要 想利用GPS跟蹤使用者,必須得有地面系統(比如手機)轉發位置資訊。手機與基站之間保持密切通訊,因而可以(而且確實會)不斷地報告你的位置。只不過有了GPS 接收器之後,它所報告的資訊可以更加精確。
4. 手機為何又稱作“蜂窩電話”?
何謂“蜂窩”?因為頻段和無線電的覆蓋範圍都是有限的,因此就要把整個地區劃分為蜂窩狀的許多小區。可以將每個這樣的小區想象為六邊形,然後中央有一個基站,相鄰的小區之間通過基站相連。打電話的時候,手機會與最近的基站通訊。當使用者移動到另一個小區時,進行中的通話就由原來的小區移交給新小區,但這個切換使用者一般覺察不到。
由於接收功率會隨著距離的二次方衰減,所以位於既定頻段中的頻帶在不相鄰的小區內可以重用,而不會相互干擾。這就是可以高效利用有限頻段的祕密所在。
大家看下面這幅示意圖: 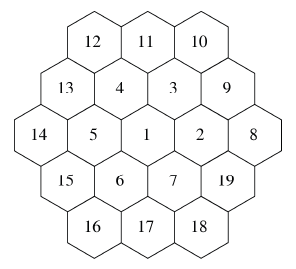
1 號小區中的基站與2 到7 號小區中的基站不會使用相同的頻率,但可以跟8到19號小區中的基站使用相同的頻率,因為與它們之間的距離足以避免干擾了。“蜂窩”中小區的實際形狀要取決很多因素,比如天線的輻射圖形。這張圖只是一種理想化的結果。
蜂窩手機是常規的電話網路的一部分,只不過連線這個網路不是靠電話線,而是靠基站發射無線電波。
手機使用的頻段很窄,傳輸資訊的能力有限。因為要使用電池,所以打電話時發射的都是低功率無線電波。而且根據法律規定,為了避免與其他無線裝置發生干擾,它們的傳輸功率也受到限制。
手機在世界的不同地區會使用不同的頻帶,但一般都在900 MHz 左右。每個頻帶被分成多個通道,每次通話時,收發訊號各佔用一個通道。傳送呼叫訊號的通道由小區中所有手機共享,在某些系統中這個通道也可以同時用於傳送簡訊和資料。
撥打電話的原理:每個手機都有唯一的識別碼(可不是說手機號啊),相當於乙太網的地址。啟動手機後,它就會廣播自己的識別碼。距離最近的基站接收到手機訊號後,會通過後臺系統驗證該識別碼。隨著手機移動,基站實時更新其位置資訊,並不斷向後臺系統報告。如果有人呼叫該手機,後臺系統就能通過一直與它保持聯絡的基站找到它。
手機與基站通訊時的訊號強度很高。但手機會動態調整功率,在距離基站較近時降低功率。這樣不僅可以省電,也可以減少干擾。待機時的耗電量遠遠比不上一次通話,而這也是為什麼待機時間以天為單位,而通話時間以小時為單位的原因。如果手機所在小區訊號較弱或根本沒有訊號,那麼它就會因為拼命查詢基站而大量耗電。
美國使用了兩種完全不同的手機通訊技術:
(1)AT&T和T-Mobile使用GSM(Global System for Mobile Communications,全球行動通訊系統),這是一種在歐洲使用非常普遍的系統,它把頻帶分成很窄的通道,在每個通道內依次附加多路通話。GSM 是世界上應用範圍最廣的系統。
(2)Verizon 和Sprint 使用CDMA (Code Division Multiple Access,分碼多重進接),這是一種“擴充套件頻段”技術,它把訊號擴充套件到頻帶之外,但對不同的通話採用不同的編碼模式進行調製。這就意味著,雖然所有手機都使用相同的頻帶,但大多數情況下通話之間不會發生干擾。
GSM 和CDMA 都會利用資料壓縮來儘可能減少封裝訊號的位元量。對於通過嘈雜的無線電通道傳送資料時無法避免的錯誤,再新增錯誤校驗來解決問題。
手機帶來了一系列難解的非技術問題:
(1)頻段的分配。在美國,政府限 制每個頻帶最多隻能有兩家公司使用指定頻率。因此頻段是非常稀缺的資源,也是無線聯網系統的關鍵資源。
(2)手機訊號發射塔的位置。訊號發射塔作為戶外建築算不上漂亮,很多地區為 此拒絕在自己的地界上搭設這種東西。
5. TCP/IP協議作用
網際網路有很多協議,其中最基礎的有兩個,一是網際網路協議(Internet Procotol,IP),定義了單個包的格式和傳輸方式,二是傳輸控制協議(Transmission Control Protocol,TCP),定義了IP包如何組合成資料流以及如何連線到服務。兩者合起來起就叫TCP/IP。當然TCP/IP協議族不只是包含這兩個協議,還包含其它許多的協議。
6. 資料壓縮技術
資料壓縮技術分為無失真壓縮和有失真壓縮。
- 無失真壓縮,即壓縮過程中不丟失資訊,解壓後得到的資料和原始資料一模一樣,比如霍夫曼編碼(Huffman coding),和廣泛使用的zip程式或bzip2程式,都屬於無失真壓縮。只不過前者按單個字母來壓縮,而後者按大塊文字,比如zip就是根據原始文件的屬性選擇按單詞或片語壓縮。
- 有失真壓縮最常用於處理要給人看或聽的內容。比如壓縮數碼相機拍出來 的照片。人眼分辨不出來非常相近的顏色,所以不必保留實際輸入的那麼多種顏色,顏色少一點沒有任何問題,這樣就可以減少編碼所用的位數。與此類似,某些難以覺察的細節也可以丟棄,這樣處理後的影象儘管沒有原始畫面那麼精密,但眼睛看不出來。細微的亮度變化也是如此。比如JPEG演算法和用於壓縮電影和電視節目的MPEG 系列演算法都是有失真壓縮。
所有壓縮演算法的思路都是減少或去掉那些不能物盡其用的位串,採用的主要方法包括把出現頻率較高的元素編碼成短位串、構造頻率字典、用數字代替重複內容等。無失真壓縮能夠完美重現原始資料,有失真壓縮通過丟棄接收者不需要的資訊,來達成資料質量和壓縮率的折中。
7. 如何根據銀行卡號判斷卡的真偽?
在“錯誤檢測和校正”小節看到了一個有意思的演算法,是IBM公司的彼得·盧恩(Peter Luhn)於1954年設計的一個校驗和(checksum)演算法,來檢測在實際操作中最常見的兩種錯誤:單個數字錯誤、由於兩個數字寫錯位置而引起的大多數換位錯誤。後來這個演算法有了很多應用場景,比如可以檢測16位長的信用卡和儲蓄卡的卡號是否是有效的卡號(這是美國的情況,中國的儲蓄卡一般是19位,不過演算法同樣適用);10 位或13 位的ISBN 書號也採用了類似演算法的校驗和,用來對付同類錯誤。
這個演算法很簡單:從最右一位數開始向左,把每個數字交替乘1或2,如果結果大於 9就減9。如果把各位數的計算結果加起來,最後得到的總和能被10 整除,那這個卡號就是有效卡號。
你可以用這個方法測試一下信用卡,以“4417 1234 5678 9112”為例(此卡號取自某銀行廣告),這個卡號計算的結果是69,所以不是真卡號;如果把它的最後一個數字換成3,那就是有效卡號了。我用該演算法測試了自己的銀行卡和信用卡,的確可以用來檢測卡的真偽,這也算是個小知識吧。
8. 你能用一句話解釋CGI是幹嘛的嗎?
通用閘道器介面(Common Gateway Interface,CGI),是HTTP 協議裡一個從客戶端(你的瀏覽器)向伺服器傳遞資訊的機制,它能用來傳遞使用者名稱和密碼、查詢條件、單選按鈕和下拉選單選項。
CGI機制在HTML裡用 ... 標籤來控制。你可以在標籤裡放入文字輸入區、按鈕等常見介面元素。如果再加上一個“提交”按鈕,按下去就會把表單裡的資料傳送到伺服器,伺服器用這些資料作為輸入,來執行指定的程式。
9. 偉大的Netscape公司
Cookie技術和Javascript指令碼語言都是Netscape公司發明的,網景公司對網際網路的貢獻真是太大了(還記得網景瀏覽器嗎?),不得不佩服。
10. 病毒和蠕蟲的差別
病毒和蠕蟲在技術上有個細微差別是:病毒的傳播需要人工介入,也就是隻有你的操作才能催生它的傳播;而蠕蟲的傳播卻不需要你的援手,完全自發進行。
11. 搜尋引擎核心競爭力及主要收入來源
搜尋引擎的核心競爭力在於怎麼才能迅速從抓取的頁面中篩選出匹配度最高的URL,比如最為匹配的十個頁面。誰能把最佳匹配結果排在前頭,誰的響應速度快,誰就能贏得使用者。
第一批搜尋引擎只會顯示一組包含搜尋關鍵詞的頁面,而隨著網頁數量激增,搜尋結果中就會混入大量無關頁面。谷歌的PageRank演算法會給每個頁面賦予一個權重,權重大小取決於是否有其他頁面引用該頁面,以及引用該頁面的其他頁面自身的權重。從理論上講,權重越大的頁面與查詢的相關度就越高。正如布林和佩奇所說:“憑直覺,那些經常被其他網頁提及和引用的頁面的價值一定更高一些。”當然,要產生高質量的搜尋結果絕對不會只靠這一點。搜尋引擎公司會不斷採取措施來改進自己的結果質量,以期超越對手。
搜尋引擎的收入通常來自廣告。簡單來說,搜尋引擎的廣告模式有兩種:
(1)廣告客戶付錢在網頁上顯示廣告,價格由多少人看過以及什麼樣的人看到該網頁來決定。這種定價模式叫按頁面瀏覽量收費,即按“展示”, 也就是按廣告在頁面上被展示的次數收費。
(2)另一種模式是按點選收費,即按瀏覽者點選 廣告的次數收費。因此搜尋引擎的廣告模式。
說到底就是拍賣搜尋關鍵詞,且搜尋引擎公司都有完備的手段避免虛假點選。
12. Cookie如何暴露你在網際網路上的行蹤?— Cookie跟蹤的原理
只要上網,我們的資訊就會被收集,而如果沒有我們留下的蛛絲馬跡,幾乎什麼事兒也幹不了。使用其他系統時的情況也一樣,特別是使用手機的時候,手機網路隨時都知道我們在哪裡。如果是在戶外,支援GPS的手機(現在的智慧手機幾乎都支援)定位使用者的誤差不超過10米,而且隨時都會報告你的位置。有些數碼相機也帶GPS,可以在照片中編入地理位置資訊,這種做法被稱為打地理標籤。
把多個來源的跟蹤資訊彙總起來,就可以繪製一幅關於個人的活動、喜好、財務狀況,以及其他很多方面的資訊圖。這些資訊最起碼可以讓廣告客戶更精準地定位我們,讓我們看到樂意點選的廣告。不過,跟蹤資料的應用可遠不止於此。這些資料還可能被用在很多我們意想不到的地方。比如根據收入把人分成三六九等,在貸款時區別對待,或者更糟糕地,被人冒名頂替,被政府監控,被人圖財,甚至害命。
怎麼收集我們的瀏覽資訊呢?有些資訊會隨著瀏覽器的每一次請求傳送,包括你的IP地址、正在瀏覽的頁面、瀏覽器的型別和版本、作業系統,還有語言偏好。
此外,如果伺服器的域中有cookie,那麼這些“小甜餅”也會隨瀏覽器請求一塊傳送。根據cookie的規範,只能把這些儲存使用者資訊的小檔案發給最初生成它們的域。那還怎麼利用cookie跟蹤我對其他網站的訪問呢?
要知道答案,就得明白連結的工作原理:
每個網頁都包含指向其他頁面的連結(這正是“超連結”的本義)。我們都知道連結必須由我們主動點選,然後瀏覽器才會開啟或轉向新頁面。但圖片不需要任何人點選,它會隨著頁面載入而自動下載。網頁中引用的圖片可以來自任何域。於是,在瀏覽器取得圖片時,提供該圖片的域就知道我訪問過哪個頁面了。而且這個域也可以在我的計算機上存放cookie,並且收到之前訪問過的域所產生的cookie。
以上就是實現跟蹤的祕密所在,下面我們再通過例子來解釋一下。假設我想買一輛新車,因此訪問了toyota.com。我的瀏覽器因此會下載60 KB的HTML檔案,還有一些JavaScript,以及40張圖片。其中一張圖片的原始碼如下:
<img src="http://ad.doubleclick.net/ad/
N2724.deduped_spotlight/B1009212;
sz=1x1;tag=total_traffic;ord=1?"
width=1 height=1 border=0>
這個<img>標籤會讓瀏覽器從ad.doubleclick.net下載一張圖片。這張圖片只有1畫素寬、1畫素高,沒有邊框,而且很可能是透明的,總之頁面上看不見它(稱之為網頁信標)。當然,這張圖片根本就沒想讓人看到。當我的瀏覽器請求它時,DoubleClick會知道我正在瀏覽豐田汽車公司網站的某個頁面,而且(如果我允許)還會在我的計算機中儲存一個cookie檔案。要是我隨後又訪問了一個內建DoubleClick圖片的網站,DoubleClick就可以繪製一張我的“足跡圖”。如果我的“足跡”大都留在汽車網站上,DoubleClick會把這個資訊透露給自己的廣告客戶。於是乎,我就能看到汽車經銷商、購車貸款、修車服務、汽車配件等等各種廣告。如果我的“足跡”更多與交通事故或止疼有關,那麼就會看到律師和醫生投放的廣告。
DoubleClick(現為谷歌所有)在拿到使用者訪問過的站點資訊後,會根據這些資訊向豐田等廣告客戶推銷廣告位。豐田公司繼而利用這些資訊定向投放廣告,而且(可能)會參考包括我的IP地址在內的其他資訊。(DoubleClick不會把這些資訊賣給任何人。)隨著我訪問的頁面越來越多,DoubleClick就可以繪製一幅關於我的更詳細的圖畫,藉以推斷我的個性、愛好,甚至知道我已經60多歲了,是個男的,收入中上,住在新澤西中部,在普林斯頓大學上班。知道我的資訊越多,DoubleClick的廣告客戶投放的廣告就越精準。到了某個時刻,DoubleClick甚至可以確定那個人就是我,儘管大多數公司都聲稱不會針對具體的某個人。可是假如我的確在某些網頁中填過自己的名字和電子郵件地址,那誰也不敢保證這些資訊不會被傳播。
這套網際網路廣告系統設計得極其精密。開啟一個網頁,這個網頁的釋出者會立即通知雅虎的Right Media或谷歌的Ad Exchange,說這個網頁上有一個空地兒正虛位以待,可以顯示廣告。同時發過去的還有瀏覽者的資訊(例如,25到40歲之間、單身、住在舊金山,是個技術宅,喜歡泡館子)。於是,廣告客戶會為這個廣告位而競價,勝出者的廣告將被插入到這個網頁中。整個過程不過零點幾秒而已。
如何防範?
只要上網,防範基本上是不可能的,不過可以選擇性的關閉一些cookie跟蹤。比如作者使用過Firefox 的一個擴充套件TACO(Target Advertising Cookie Opt-out,定向廣告Cookie 自願迴避),這個擴充套件維護著一個cookie 跟蹤站點的列表(目前有大約150個名字),在瀏覽器中儲存著它們的自願迴避cookie。而我呢,同時對大多數網站都選擇關閉cookie。
許多網站都含有多家公司的跟蹤程式。給大家推薦一個瀏覽器擴充套件Ghostery,通過它可以禁用JavaScript 跟蹤程式碼,還能檢視被阻止的跟蹤器。裝上它,你會驚訝於網際網路上潛伏著多少“間諜”。僅適用於Firefox的Noscript外掛也有類似的功能。
總結:
一個畫素大的圖片或者叫網頁信標(web beacon,一個很小而且通常是看不到的圖片,用於記錄某個網頁是否已經被下載過了。)都可以用來跟蹤你。 用於取得畫素圖片的URL 可以包含一個標識碼,表示你正在瀏覽什麼網頁,還可以包含一個識別符號,表示特定的使用者。這兩個標誌就足以跟蹤你的瀏覽活動了。
13. 隱私失控問題
隨著社交網站的流行,為了娛樂和與其他人聯絡,我們自願放棄了很多個人隱私。社交網站存在隱私問題是毫無疑義的,因為它們會收集註冊使用者的大量資訊,而且是通過把這些資訊賣給廣告客戶來賺錢。
作為最大也最成功的社交網站,Facebook 的問題也最明顯。Facebook 給第三方提供了 API,以方便編寫Facebook 使用者可以使用的應用。但這些API 有時候會違背公司隱私政策透露一些隱私資訊。當然,並非只有Facebook 一家如此。做地理定位服務的Foursquare 會在手機上顯示使用者的位置,能夠為找朋友和基於位置的遊戲提供方便。在知道潛在使用者位置的情況下,定向廣告的效果特別好。如果你走到一家餐館的門口,而手機上恰好是關於這家餐館的報導,那你很可能就會推門進去體驗一下。雖然讓朋 友知道你在哪兒沒什麼問題,但把自己的位置昭告天下則非明智之舉。比如,有人做了一個示範性的網站叫“來搶劫我吧”(Please Rob Me),該網站根據Foursquare 使用者在Twitter 上發表的微博可以推斷出他們什麼時候不在家,這就為入室行竊提供了機會。
社交網站很容易根據自己的使用者構建一個交往群體的“社交圖譜”,其中包括被這些使用者牽連進來但並未同意甚至毫不知情的人。