大模型推理最佳化實踐:KV cache複用與投機取樣
在本文中,我們將詳細介紹兩種在業務中實踐的最佳化策略:多輪對話間的 KV cache 複用技術和投機取樣方法。我們會細緻探討這些策略的應用場景、框架實現,並分享一些實現時的關鍵技巧。
背景
RTP-LLM 是阿里巴巴大模型預測團隊開發的大模型推理加速引擎,作為一個高效能的大模型推理解決方案,它已被廣泛應用於阿里內部。該引擎與當前廣泛使用的多種主流模型相容,並透過採用高效能的 CUDA 運算元來實現瞭如 PagedAttention 和 Continuous Batching 等多項最佳化措施。RTP-LLM 還支援包括多模態、LoRA、P-Tuning、以及 WeightOnly 動態量化等先進功能。
隨著大模型的廣泛應用,如何降低推理延遲並最佳化成本已成為業界關注的焦點。我們不斷地在這一領域內探索和挖掘新方法。在本文中,我們將詳細介紹兩種在業務中實踐的最佳化策略:多輪對話間的 KV cache 複用技術和投機取樣方法。我們會細緻探討這些策略的應用場景、框架實現,並分享一些實現時的關鍵技巧。
多輪對話複用KV cache
在淘寶問問中,有兩類多輪對話的場景:一是問答類的場景,它每次請求模型時會拼接之前的問答;二是LangChain應用,它在模型生成結束後會呼叫外部外掛,拼接外掛返回的結果再次請求模型。這兩類場景共同的問題是:隨著對話輪數的增加,請求長度變長,導致模型的First Token Time(下稱FTT)不斷變長。
模型的FTT變長,本質上是因為第一次進入模型時,越來越多的token需要生成KV cache。考慮到這兩種多輪對話場景存在一個共同點:前一輪對話的輸出構成後一輪對話輸入的一部分,或者存在較長的公共字首。且大部分自迴歸模型(除了chatglm-6b)的Attention Mask都是下三角矩陣:即某一位置token的注意力與後續token無關,因此兩輪對話公共字首部分的KV cache是一致的。進而能夠想到的解決辦法是:儲存上一輪對話產生的KV cache,供下一輪對話時複用,就能減少下一輪需要生成KV cache的token數,從而減少FTT。根據這個思路改進前後的模型如下:

2.1 框架設計
使用者請求對應的KV cache存放在機器視訊記憶體中,因此不同輪次的對話需要請求同一臺機器,才能複用KV cache。但是在生產環境中,模型部署在由多臺機器組成的機器叢集,使用者層的請求由統一域名服務轉發到機器叢集中某一臺機器上,這樣的架構設計導致不同輪對話命中同一臺機器的機率微乎其微。
最直觀的解決辦法是讓使用者去記錄首次請求的機器資訊,並將後續請求同一臺機器。這個方法可行但是不合理,使用者不僅需要感知機器叢集的具體資訊,還需要對自己鏈路做大量改造;進而能想到的辦法是增加一層轉發層,使用者將多輪請求攜帶同樣的標識id併傳送給轉發層,轉發層感知叢集資訊並匹配標識id和下游機器。這樣不同輪對話就能打到同一臺存有KV cache的下游機器。至於如何在轉發機器間同步匹配資訊,可以使用分散式資料庫記錄,我們取樣的方法是使用統一的雜湊演算法,將相同id雜湊到固定的機器。只要選擇合適的雜湊演算法,就能在機器叢集負載均衡的同時讓多輪對話命中同一臺機器。

在底層實現上,複用KV cache的邏輯和P-Tuning v2在實現上非常相似,透過複用引數,我們使用PTuning的運算元支援了KV cache複用。
2.2 總結與反思
我們在Qwen13B/int8量化/A10機器的條件下,對不同輸入和字首長度的請求進行了測試:

可以看到在複用KV cache功能極大程度的減少了FTT,並且歷史長度的變化對FTT的影響較小,FTT更多的取決於本次請求的輸入長度。並且除了多輪對話場景外,KV cache複用功能也擴充套件到複用Ptuning字首和長System Prompt的場景,降低FTT和視訊記憶體佔用。
雖然複用KV cache的功能能夠顯著減少多輪對話場景下的FTT,但是在服務壓力過大時,存放歷史KV cache的視訊記憶體可能被新請求佔用,導致後續請求出現cache miss請求時間變長,加劇服務壓力最後導致雪崩。目前我們已實現的解決方案是使用LRU演算法優先移除較舊請求的KV cache。未來進一步的策略是參照vllm的思路,將過期的KV cache轉移到記憶體,必要時重新載入至視訊記憶體。這種策略比重新計算快,有助於減輕極端情況下的請求延遲,防止服務雪崩。
投機取樣
3.1 介紹
投機取樣最早在2022年的Fast Inference from Transformers via Speculative Decoding提出,因為不久前的gpt4洩密而被更多人知道。投機取樣的設計基於兩點認知:在模型推理中,token生成的難度有差別,有部分token生成難度低,用小引數草稿模型(下簡稱小模型)也能夠比較好的生成;在小批次情況下,原始模型(下簡稱大模型)在前向推理的主要時間在載入模型權重而非計算,因此批次數量對推理時間的影響非常小。
基於以上兩點認知,投機推理的每一輪的推理變成如下步驟: 1. 使用小模型自迴歸的生成N個token 2. 使用大模型並行驗證N個token出現的機率,接受一部分或者全部token。由於小模型推理時間遠小於大模型,因此投機取樣在理想的情況下能夠實現數倍的推理速度提升。同時,投機取樣使用了特殊的取樣方法,來保證投機取樣獲得的token分佈符合原模型的分佈,即使用投機取樣對效果是無損的。

上圖是投機取樣的執行過程,每一行的綠色token代表小模型生成並被大模型接受的部分,紅色token是小模型生成但被大模型拒絕的部分,藍色token是大模型根據最後接受token的logits重新取樣出來的部分。由上可以看到使用投機取樣,在合適的場景下能夠大幅提高每輪生成的token數,降低平均單個token生成時間。
3.2 設計思路
我們在RTP-LLM中基於論文的思路,使用大小模型進行了投機取樣的實踐。在程式碼設計上我們一方面考慮系統的可維護性,希望這部分能夠和原始流程解耦;其次投機取樣最佳化需要與其他最佳化正交,使投機取樣時兩個模型都能夠用上FT的其他最佳化。最後我們的設計是為投機取樣封裝了一層編排層,對外提供統一的API,在內部組織引數順序呼叫正常流程。

3.3 效能評估
在實現過程中,我們著重關注投機取樣引入的額外負擔。我們希望做到在系統每輪接受token數較少的情況下,也能有與原始模型相近的表現。在實踐中,我們測得額外時間消耗主要有兩塊:小模型順序生成token引入時間和取樣。
首先最直觀的額外消耗,就是小模型推理所佔用的時間。在小模型順序生成N個token時,會有N*T_{small\_model}的時間,在N較大且接受token數少的情況下,這部分開銷會非常大。值得一提的時最初我們假設模型消耗時間和引數規模成正比,而實際上這個猜測是錯誤的。我們測試得到在引數規模減少的情況下, lm_head在模型呼叫的佔比會顯著增加。以下是Qwen1.8B和Qwen13B在A10/half條件下,單個token在Transformer網路(transformer_layer)和輸出層(lm_head)的時間對比:

造成上述比例不一致原因在於:模型引數規模從13B變成1.8B時, Transformer網路在層數(40 -> 24)和權重大小(5120 -> 2048)兩個維度減少,而輸出層的引數僅從[5120, 152064]變成[2048, 152064] 。同時因為模型詞表通常很大,因此輸出層的時間通常也比較長。除了輸出層的影響以外,在一些情況下小模型矩陣乘對硬體的利用率並沒有大模型這麼高,因此在選擇小模型時需要對這部分開銷進行更謹慎的估計。
其次重複多次的取樣也引入了巨大的開銷。從上面流程圖可以看到,在一輪投機取樣流程中,需要進行N次小batch取樣和1次大batch取樣。我們以a10/half/vocab_size=152064/top_k=0.5/top_p=0.95的情況下用huggingface取樣邏輯進行了測試:

假設在原始請求batch為2, 投機取樣每次出5個token的條件下,需要1.15*5+1.47=7.221.15∗5+1.47=7.22毫秒的時間,這接近上述1.8B小模型一次推理的總時長。
好在FT的取樣流程針對存在top_k引數的情況,透過融合運算元對原版(Huggingface流程)進行了最佳化,改進後的流程分成兩步:對維度是[batch, vocab]的輸入進行TopK取樣後,使用輸出維度是[batch, k]的tensor進行後續流程;省略TopP步驟,直接在取樣過程中對TopP進行判斷。改進前後的流程對比如下:

改進後的流程不影響結果分佈,且大幅度減少了計算量和kernel數量,極大程度減少了取樣需要的時間。我們測試最佳化後的取樣流程需要的時間是原來的1/10。
3.4 總結
我們在店鋪起名和文案生成兩類任務,對原模型和投機取樣模型進行了效能對比。其中原模型是int8量化的Qwen13B模型,投機取樣使用量化後的Qwen13B和Qwen1.8B模型,在A10機器測試結果如下:
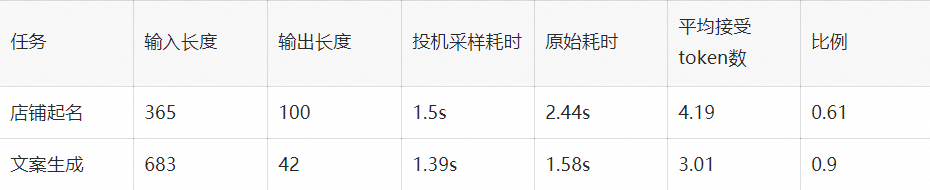
在兩類任務下投機取樣對模型均有加速,效果隨接受token數和輸入token長度變化。我們測得在使用上述條件每輪生成5個token的情況下,短序列跑一輪需要60ms,長序列跑一輪需要70ms。而原模型跑一輪需要30ms,因此長/短序列只有在拒絕全部token的情況下會劣於原模型,其他情況則是與原模型平均token時間相近或者優於原模型。由於測試條件限制,相比原論文的大小模型比例(70B:6B),我們大模型和小模型的規模(7B:1.8B)更接近,並且Qwen中文模型的詞表大小是152064,相比其他模型(如Llama詞表大小是32000)大了數倍,這也額外開銷時間變大,因此在其他測試場景下應該還能有更好的表現。
存在的問題
上文我們著重介紹了兩個最佳化對推理速度的影響,但除了推理速度外,並行度也是影響大模型吞吐的重要因素。影響並行度的主要因素是視訊記憶體,大模型的視訊記憶體佔用分三塊:模型權重佔用視訊記憶體、執行時視訊記憶體和KV cache視訊記憶體,KV cache視訊記憶體越多,模型能夠同時承載的請求數越多,並行度越大。
序列長度較長時,對執行時視訊記憶體執行最大的是Softmax Buffer,它的大小和序列的平方成正比,知名最佳化FlashAttention除了能降低模型第一次執行時間外,更重要的作用是消除了Softmax Buffer對視訊記憶體的佔用。但比較遺憾的是,FlashAttention最佳化的開源實現要求Attention計算的QKV維度一致,而KV csache複用和投機取樣都未滿足這個條件,導致對視訊記憶體有額外的佔用。除此之外,投機取樣因為要額外載入小模型的權重,且執行時需要多儲存一份小模型的KV cache,還需要額外的視訊記憶體。
總結與致謝
以上是我們在大模型推理上做的一些最佳化嘗試,有根據業務場景和實際問題的,也有參考論文實現的,並且都取得了一定的加速效果。但是從極致效能的角度,我們做的還遠遠不算完美,這些功能在運算元層和框架層都還有最佳化空間,這些是我們後續需要改進的。
除了上述介紹的功能外,RTP-LLM還支援了非常多的功能,和上文相關的對System Prompt進行快取的Multi Task Prompt複用Medusa投機取樣,以及動態LoRA和不規則剪枝模型支援。未來我們也會持續的新增新功能,最佳化底層運算元效能,打造更好的大模型推理框架。
我們的專案主要基於FasterTransformer,並在此基礎上整合了TensorRT-LLM的部分kernel實現。FasterTransformer和TensorRT-LLM為我們提供了可靠的效能保障。Flash-Attention2和cutlass也在我們持續的效能最佳化過程中提供了大量幫助。我們的continuous batching和increment decoding參考了vllm的實現;取樣參考了hf transformers,投機取樣部分整合了Medusa的實現,多模態部分整合了llava和qwen-vl的實現。感謝這些專案對我們的啟發和幫助。
來自 “ 阿里雲開發者 ”, 原文作者:米基;原文連結:https://server.it168.com/a2024/0220/6839/000006839999.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 【雜學】大模型推理加速 —— KV-cache 技術大模型
- 投機取樣會損失大語言模型的推理精度嗎?模型
- LLM大模型:推理最佳化-模型int8量化大模型
- 一種KV儲存的GC最佳化實踐GC
- 大模型推理指南:使用 vLLM 實現高效推理大模型
- 探索大模型:袋鼠雲在 Text To SQL 上的實踐與最佳化大模型SQL
- 萬字綜述大模型高效推理:無問芯穹與清華、上交最新聯合研究全面解析大模型推理最佳化大模型
- 大模型原理與思維鏈推理大模型
- 最佳化故事: BLOOM 模型推理OOM模型
- Guava Cache本地快取在 Spring Boot應用中的實踐Guava快取Spring Boot
- 餓了麼分散式KV架構與實踐分散式架構
- Laravel 效能優化實踐:在 Auth 中用 Cache 排程快取的 User 模型Laravel優化快取模型
- Guava Cache 原理分析與最佳實踐Guava
- Spring Cache 快取註解這樣用,實在是太香了!Spring快取
- 【CIKM 2023】擴散模型加速取樣演算法OLSS,大幅提升模型推理速度模型演算法
- 大模型在新能源汽車行業的應用與實踐大模型行業
- LLM 大模型學習必知必會系列(三):LLM和多模態模型高效推理實踐大模型
- Android快取機制-LRU cache原理與用法Android快取
- AI浪潮下,大模型如何在音影片領域運用與實踐?AI大模型
- 大模型儲存實踐:效能、成本與多雲大模型
- 大模型缺乏基本推理能力?大模型
- 基於序列模型的隨機取樣模型隨機
- Django效能之道:快取應用與最佳化實戰Django快取
- 低程式碼與大語言模型的探索實踐模型
- mysql 複製原理與實踐MySql
- 華為盤古大模型5.0技術解密:更多模態,複雜推理大模型解密
- Java快取機制:Ehcache與Guava Cache的比較Java快取Guava
- 《ASP.NET開發與應用實踐》例題複習用ASP.NET
- 美團視覺GPU推理服務部署架構最佳化實踐視覺GPU架構
- Glide 快取與解碼複用IDE快取
- RecyclerView快取機制(咋複用?)View快取
- HarmonyOS:應用效能最佳化實踐
- Redis 在 vivo 推送平臺的應用與最佳化實踐Redis
- Serverless 工程實踐 | Serverless 應用最佳化與除錯秘訣Server除錯
- 璞華AI大模型應用的探索之路:從AI大模型開發與運營平臺到應用寶庫的最佳實踐AI大模型
- guava cache過期方案實踐Guava
- 影片生產大映象最佳化實踐
- GPT大語言模型Alpaca-lora本地化部署實踐【大語言模型實踐一】GPT模型