一次性講清楚「連線池獲取連線慢」的所有原因
一 前言
應用連線資料庫基本上都是透過連線池去連線,比如常用的 HikariCP、Druid 等,在應用執行期間經常會出現獲取連線很慢的場景,大多數同學都是一頭霧水,不知道從哪下手。而且很多時候都是偶發場景,讓人頭疼不已,彆著急,本文帶你逐步剖析獲取連線慢的所有可能的原因,以及對應的調優手段,讓你成為連線池排障大師。
二 連線池監控
排查問題的前提是發現問題,所以首先需要有連線池的詳細監控,下面我們以 HikariCP 為例,簡單介紹幾個常用的指標的含義。


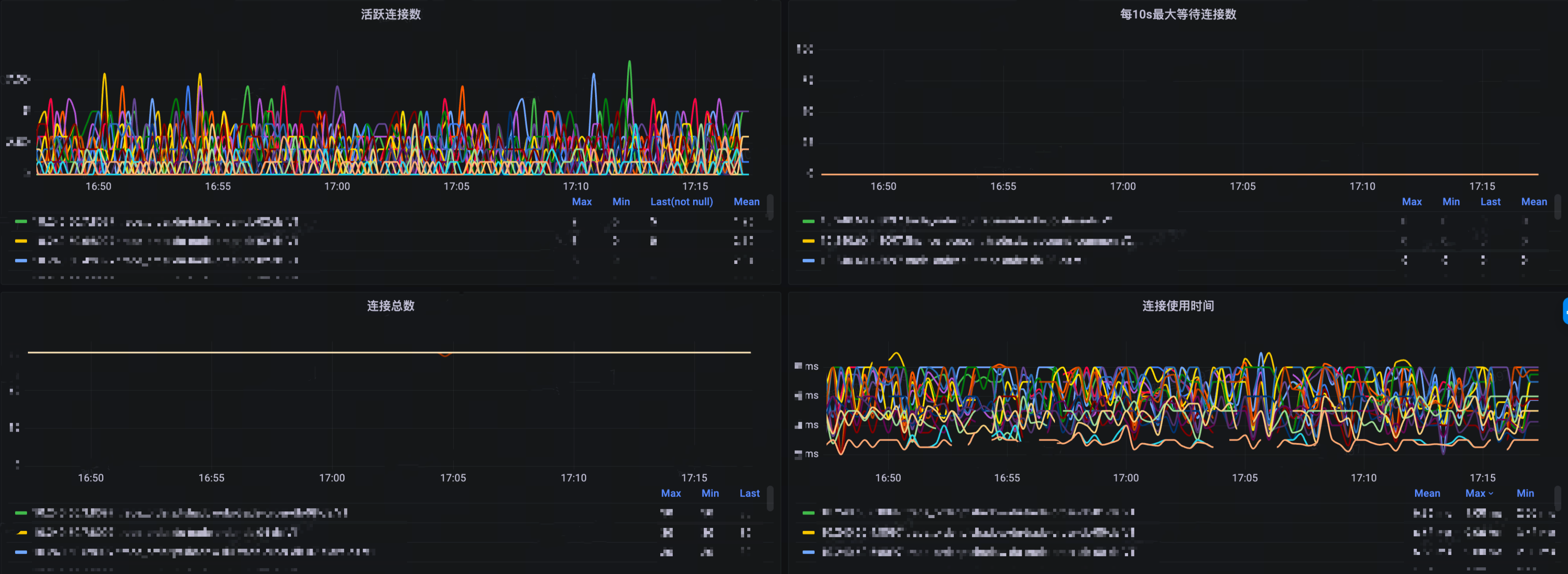
對應應用程式比較敏感的時間就是獲取連線耗時,因為它是同步的會直接影響鏈路的RT,下面我們就來逐步分析造成這個獲取連線耗時較高的所有可能性以及解決方案。
三 排查思路
連線池存在等待連線
獲取連線耗時較高最直接的原因就是存在等待連線數,這種情況直接觀測等待連線數的大盤即可

那麼又有哪幾種情況會導致存在等待連線數呢?
連線池容量過小
如果日常的活躍連線數/總連線比例持續很高,或者 QPS * AVG-RT(s) > 連線總數說明當前連線池的最大連線數已經不足以支撐當前的流量,如何解決?
適當增加連線池最大連線數:連線數也不是越大越好,一般是根據 CPU 核數決定,HikariCP 官方給出了一個公式可以做一下參考,最大連線數一般不要超過 50。
connections = ((core_count * 2) + effective_spindle_count)
core_count 為core的數量 effective_spindle_count 為掛載的磁碟數量。
應用擴容:如果連線數調大後,仍然無法解決,說明單機的連線數已經達到上限,需要對應用進行擴容,但是需要注意擴容節點的數量,單機連線數*節點數量不要超過資料庫支援的最大連線數
有慢查詢&長事務
慢SQL
慢 SQL 相對來說比較好排查,資料庫或者資料庫中介軟體都有成熟的慢 SQL 採集工具。只需要分析一下指定時間段內是否有慢 SQL 即可。 如果SQL 最佳化空間比較低,可以把慢 SQL 和核心業務分 2 個資料來源,防止慢 SQL 影響正常核心業務。
長事務
長事務是很容易忽略的一種 case,可以透過觀測連線使用時間指標和 SQL 耗時來分析,如果連線使用平均耗時遠大於 SQL 平均耗時,那麼說明有長事務。還可以根據 HikariCP 自帶的連線洩露檢測來分析,當連線被借出後長時間未歸還(超過配置的閾值 leak-detection-threshold=30000)會列印借出時的堆疊,可以幫助我們快速定位。
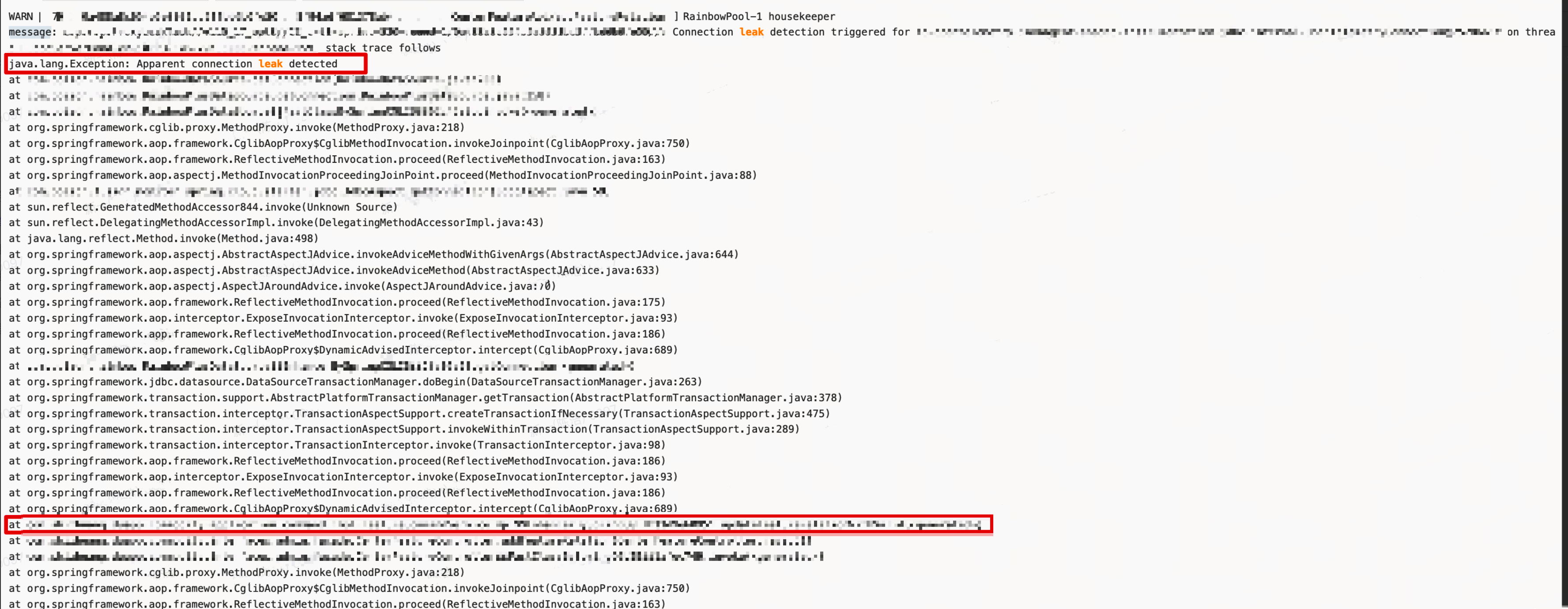
還可以透過 RDS 的 SQL 洞察來分析是否有長事務,如果使用 Spring+JDBC 管理事務的情況下,開啟事務的命令是 SET autocommit=0,提交事務是 commit,這裡根據資料庫執行緒 ID 來逐個分析,提交事務的時間-開啟事務的時間=事務持續時間。

應用負載過高
由於 HikariCP、Druid 在從連線池借出連線時,會有一個同步探活的操作,比如直接 MySQL 的 PING 命令或執行 select 'X' 等,因為有網路 IO,所以這裡會讓當前執行緒進入阻塞狀態讓出 CPU 時間片。

在 CPU 繁忙時,執行完網路 IO 後等待獲取 CPU 時間片的時間較長,最終表現的結果就是獲取連線時間拉長。這種 case 的分析手段比較簡單,直接透過觀測應用的 CPU 和 Load 指標即可。
應用STW
在獲取連線方法開始到結束期間,如果應用發生了 STW,就會導致獲取連線耗時升高,需要結合 JVM 監控 &GC 日誌來分析,關於 GC 分析不是本文重點,這裡簡單列舉幾個重點說明一下(以 ZGC 舉例)。
JVM 監控存在 Allocation Stall(垃圾回收阻塞,會暫停執行緒)或者暫停時間較長。

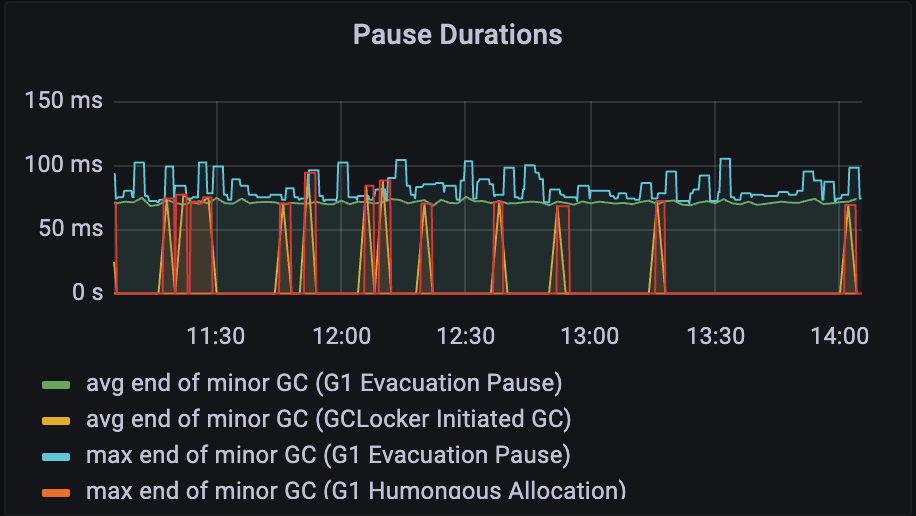
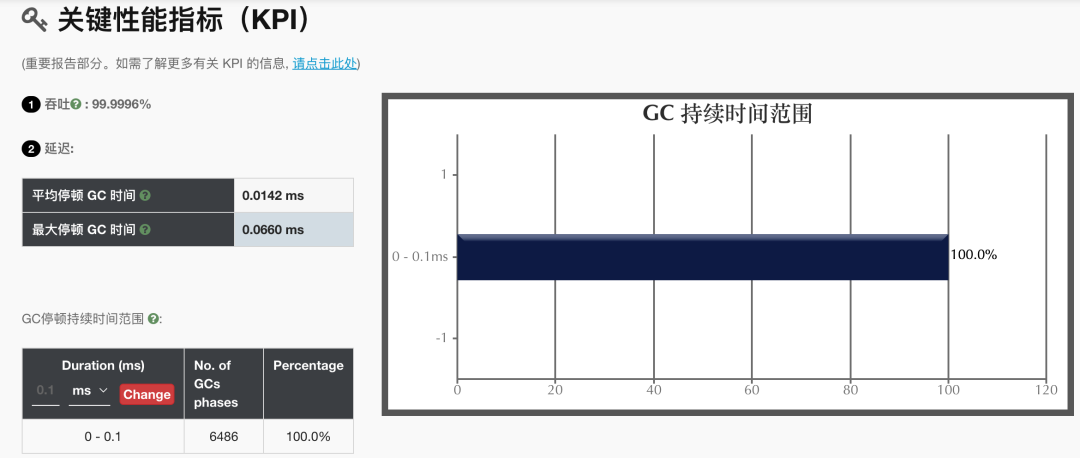
GC 日誌相對於監控會更為準確一點,把日誌檔案直接丟到 裡面分析一下即可,會輸出詳細的報告,重點關注一下 STW 時間和分配阻塞。

網路阻塞
這一類問題比較難以排查,具有偶發性和難以觀測的特點,網路阻塞也分好幾種情況。
網路抖動
這是最常見的一種情況,一般我們可以透過觀測應用所在主機的 TCP 重傳監控是否有尖刺,但這裡要注意下,TCP 重傳不代表一定是網路抖動,也可能是網路頻寬打滿或者資料庫 &DAL 異常。

除了監控還可以透過網路迴圈抓包來分析(主要磁碟容量不要保留太多檔案),可以參考以下命令。
抓取 3306 埠的網路包,儲存到 3306.pcap 檔案中,-C 50 -W 10 代表一個檔案最大 50M,最多保留 10 個 tcpdump -i eth0 port 3306 -w 3306.pcap -C 50 -W 10。
然後匯入到 WireShark 工具中分析,重點關注 TCP Retransmission 即 TCP 重傳。

網路阻塞
如機器頻寬打滿,具體表現也是 TCP 重傳,這裡可以觀測機器的頻寬監控和機器支援的最大頻寬做對比,看看是否超過限制。

資料庫&資料庫中介軟體異常
當資料庫或者資料庫中介軟體出現異常時,對於上游應用的表現大多數就是 SQL RT 增高、TCP 重傳。如果懷疑是資料庫或者資料庫中介軟體出現異常,可以先確定自己的應用連的是哪個庫,這裡可以透過應用監控(上下游 -RDS)直觀的看到應用連線的具體的庫資訊,然後再觀測對應 RDS 和資料庫中介軟體的監控進一步分析。

如果是資料庫中介軟體域名,就可以看資料庫中介軟體的監控大盤。

如果資料庫中介軟體本身沒有異常,可以繼續下鑽到 RDS。

如果是 RM/RR 開頭的,說明連的是 RDS,可以看阿里雲的 RDS 監控,把下面的 Rdsid 替換一下即可。
{替換成rdsId}/performance?region=cn-hangzhou&DedicatedHostGroupId=
重點觀測 CPU記憶體利用率 & IOPS 使用率,也可以框選指定時間段進行自動診斷。

四 總結
本文列舉了幾乎所有可能導致連線池獲取連線慢的 case,相信看完的讀者以後再遇到此類問題時,再也不會一頭霧水了。學會自助排查,不光可以提升自己的排障能力,同時也能減輕各位中介軟體 &DBA 小夥伴的客服壓力。
來自 “ 得物技術 ”, 原文作者:新一;原文連結:https://server.it168.com/a2023/1205/6832/000006832229.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 獲取連線電腦的裝置的所有埠資訊
- 連線池
- Http持久連線與HttpClient連線池HTTPclient
- 連線池和連線數詳解
- HTTP連線池HTTP
- django連線池Django
- golang連線MySQL時候的連線池設定GolangMySql
- 線上問題總結-獲取不到連線池(logback 配置+程式碼問題)
- Tomcat 的 JDBC 連線池TomcatJDBC
- 資料庫連線(2) - 為什麼C3P0連線池那麼慢資料庫
- spring和mybatis中的連線池和快取SpringMyBatis快取
- ServiceStack.Redis的原始碼分析(連線與連線池)Redis原始碼
- 自定義連線池
- ElasticSearch連線池建立Elasticsearch
- 【JDBC】java連線池模擬測試 連線oracleJDBCJavaOracle
- 【JDBC】使用OracleDataSource建立連線池用於連線OracleJDBCOracle
- HikariCP連線池的學習
- 資料庫連線池-Druid資料庫連線池原始碼解析資料庫UI原始碼
- springboot之Druid連線池講解+mybatis整合+PageHelper整合Spring BootUIMyBatis
- 如何獲取Flume連線HDFS所需要的包
- 【Azure Redis 快取 Azure Cache For Redis】Redis連線池Redis快取
- Golang SQL連線池梳理GolangSQL
- go 語言連線池Go
- 某客戶系統tomcat連線池連線異常Tomcat
- 本地無法連線Mysql的原因MySql
- 《四 資料庫連線池原始碼》手寫資料庫連線池資料庫原始碼
- Druid-目前最好的連線池UI
- C#中的連線池管理C#
- Swoole MySQL 連線池的實現MySql
- 【MySQL】自定義資料庫連線池和開源資料庫連線池的使用MySql資料庫
- 資料庫連線池原理資料庫
- Python實現MySQL連線池PythonMySql
- Flask資料庫連線池Flask資料庫
- cx_Oracle.SessionPool 連線池OracleSession
- MOSN 原始碼解析 - 連線池原始碼
- python資料庫連線池Python資料庫
- Spring系列之HikariCP連線池Spring
- Java篇-DBUtils與連線池Java