浪潮資訊釋出源2.0基礎大模型,千億引數全面開源
北京 2023年11月27日 /美通社/ -- 11 月 27 日,浪潮資訊釋出 " 源 2.0" 基礎大模型,並宣佈全面開源。源2.0基礎大模型包括1026億、518億、21億等三種引數規模的模型,在程式設計、推理、邏輯等方面展示出了先進的能力。
當前,大模型技術正在推動生成式人工智慧產業迅猛發展,而基礎大模型的關鍵能力則是大模型在行業和應用落地能力表現的核心支撐,但基礎大模型的發展也面臨著在演算法、資料和算力等方面的諸多挑戰。源2.0基礎大模型則針對性地提出了新的改進方法並獲得了能力的提升。
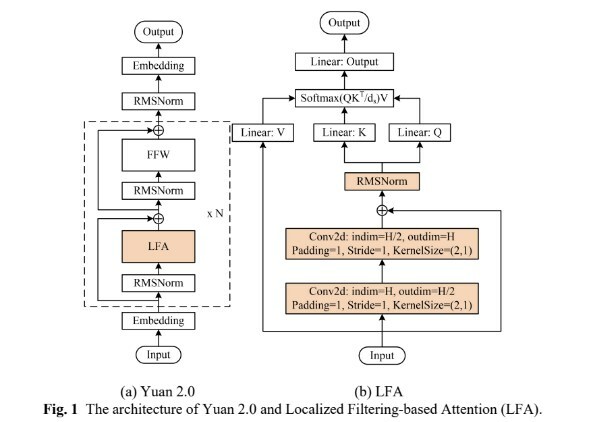
演算法方面,源2.0提出並採用了一種新型的注意力演算法結構:區域性注意力過濾增強機制(LFA:Localized Filtering-based Attention)。LFA透過先學習相鄰詞之間的關聯性,然後再計算全域性關聯性的方法,能夠更好地學習到自然語言的區域性和全域性的語言特徵,對於自然語言的關聯語義理解更準確、更人性,提升了模型的自然語言表達能力,進而提升了模型精度。
資料方面,源2.0透過使用中英文書籍、百科、論文等高質量中英文資料,降低了網際網路語料內容佔比,結合高效的資料清洗流程,為大模型訓練提供了高質量的專業資料集和邏輯推理資料集。為了獲取中文數學資料,我們清洗了從2018年至今約12PB的網際網路資料,但僅獲取到了約10GB的數學資料,投入巨大,收益較小。為了更高效地獲得相對匱乏的高質量中文數學及程式碼資料集,源2.0採用了基於大模型的資料生產及過濾方法,在保證資料的多樣性的同時也在每一個類別上提升資料質量,獲取了一批高質量的數學與程式碼預訓練資料。

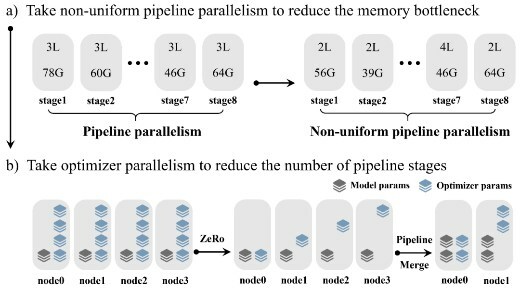
算力方面,源2.0採用了非均勻流水並行的方法,綜合運用流水線並行+最佳化器引數並行+資料並行的策略,讓模型在流水並行各階段的視訊記憶體佔用量分佈更均衡,避免出現視訊記憶體瓶頸導致的訓練效率降低的問題,該方法顯著降低了大模型對晶片間P2P頻寬的需求,為硬體差異較大訓練環境提供了一種高效能的訓練方法。
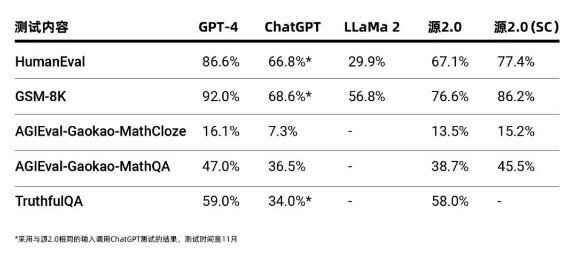
源2.0作為千億級基礎大模型,在業界公開的評測上進行了程式碼生成、數學問題求解、事實問答方面的能力測試,測試結果顯示,源2.0在多項模型評測中,展示出了較為先進的能力表現。
源 2.0 採用全面開源策略,全系列模型引數和程式碼均可免費下載使用。
程式碼開源連結
論文連結
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/70004007/viewspace-2997547/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 騰訊開源專案TARS首次全面釋出PHP版本PHP
- 技能大模式Skill Model重磅釋出 浪潮"源"大模型加速AI生產力升級模式大模型AI
- 開源React Native元件庫beeshell 2.0釋出React Native元件
- 邁向「多面手」醫療大模型,上交大團隊釋出大規模指令微調資料、開源模型與全面基準測試大模型
- 開源大模型王座再易主,1320億引數DBRX上線,基礎、微調模型都有大模型
- G6 2.0 開源釋出 — 裂變·聚變
- G6 2.0 開源釋出 -- 裂變·聚變
- 【開源】騰訊 Omio 釋出 – 全面相容 IE8 和移動端
- 【開源】騰訊 Omio 釋出 - 全面相容 IE8 和移動端
- 開源| 呼叫ARUICalling開源元元件釋出UI元件
- 開源模型 Zephyr-7B 釋出——跨越三大洲的合作模型
- 程式 · 雜談 | DeepSeek釋出最強開源數學定理證明模型模型
- 騰訊混元文生圖大模型開源訓練程式碼,釋出LoRA與ControlNet外掛大模型
- 大模型開源專案大模型
- 開源視覺大模型視覺大模型
- 開源demo| ARCall 小程式開源示例釋出
- AI浪潮下12大開源神器介紹AI
- 全面升級後的開源雲盤不瞭解一下麼?藍眼雲盤 2.0 釋出
- 開源創新 源起潮“蜥”——龍蜥社群走進浪潮資訊 MeetUp 即將開幕
- 大資料基礎軟體廠商請小心“開源”陷阱!大資料
- 開源 | Python基礎入門(視訊)課程Python
- 螞蟻集團、浙江大學聯合釋出開源大模型知識抽取框架OneKE大模型框架
- Moment:又一個開源的時間序列基礎模型模型
- Meta開源Llama 3釋出
- renren開源專案釋出
- 中國科協釋出 2021 開源創新榜,阿里巴巴 2 大開源社群、5 大開源專案上榜阿里
- 首箇中文原生DiT架構!騰訊混元文生圖大模型全面開源,免費商用架構大模型
- 騰訊混元又來開源,一出手就是最大MoE大模型大模型
- 開源醫療大模型排行榜: 健康領域大模型基準測試大模型
- DeepSeek開源數學大模型,高中、大學定理證明新SOTA大模型
- 使用jitPack釋出android開源庫Android
- 【開源】合摩 WeexBox 正式釋出
- 使用Jitpack釋出開源Java庫Java
- 人工智慧大模型之開源大語言模型彙總(國內外開源專案模型彙總)人工智慧大模型
- 雲從科技釋出國家人工智慧基礎資源公共服務平臺人工智慧
- 騰訊Node.js基礎設施TSW正式開源Node.js
- 開源大模型佔GPU視訊記憶體計算方法大模型GPU記憶體
- 基於開源IM即時通訊框架MobileIMSDK:RainbowChat v10.0版已釋出框架AI