線上問題排查例項分析|關於Redis記憶體洩漏
Redis 作為高效能的 key-value 記憶體型資料庫,普遍使用在對效能要求較高的系統中,同時也是滴滴內部的記憶體使用大戶。本文從 KV 團隊對線上 Redis 記憶體洩漏定位的時間線維度,簡要介紹 Linux 上記憶體洩漏的問題定位思路和工具。
16:30 問題暴露
業務反饋縮容後記憶體使用率90%告警,和預期不符合,key 只有1萬個,使用大 key 診斷,沒有超過512位元組以上的大 key。
16:40 確認記憶體洩漏
發現該系統中有部分例項記憶體明顯偏高達到300~800MB,正常例項只有10MB左右,版本號為4ce35dea,在9月份時已經有發現49bdcd0b這個較老版本有記憶體洩漏情況發生,現象看起來一樣,說明記憶體洩漏問題一直存在,未被修復,於是開始排查該問題。
17:30 開始排查社群版本
排查問題先易後難,先排除是不是社群的版本Bug問題:
不需要從最新修復一直倒敘確認到3系列的 commit 提交,因為如果是嚴重的記憶體洩漏,3系列的舊版本也一定會有 backport 修復記錄。
檢視3.2.8的commit記錄,只有一次記憶體洩漏相關提交:Memory leak in clusterRedirectBlockedClientIfNeeded.
本次提交只修復了在 cluster 出現 key 重定向錯誤時對 block client 處理時對一個指標的洩漏,不可能出現如此大的洩漏量。3.2.8的社群版已上線數年,但在社群內未搜尋到相關記憶體洩漏問題,因此推測是我們的某些定製功能開發引入的 Bug。
18:10 整理監控和日誌
整理當前已知監控和日誌資訊,分析問題的表面原因和發生時間
1、監控資訊
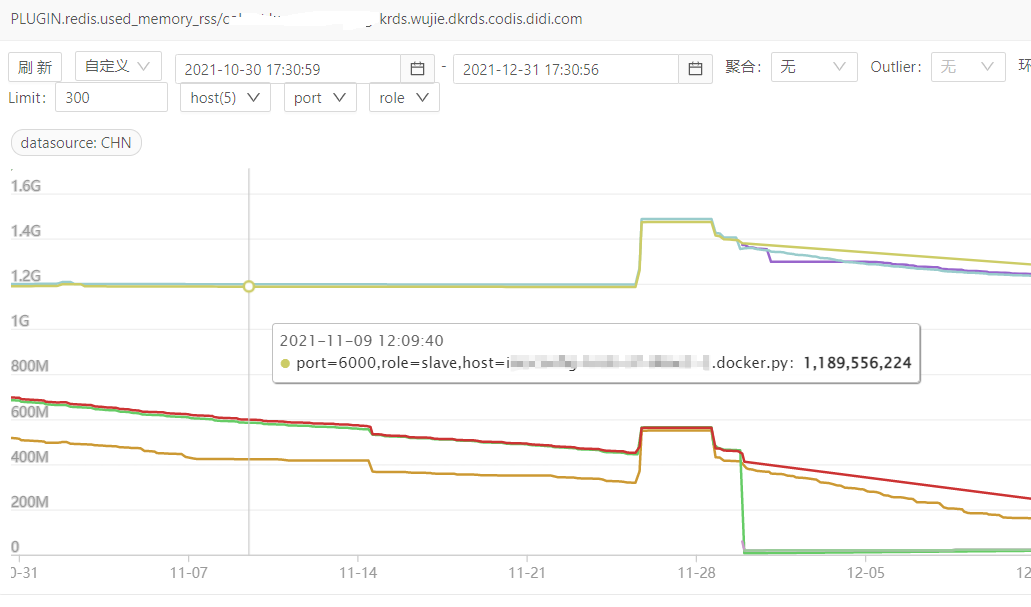
odin 監控只能看到最近兩個月的記憶體使用曲線,從監控上可以得到三點資訊:
兩個月前已經發生記憶體洩漏
記憶體洩漏不是持續發生的,是由於某次事件觸發的
記憶體洩漏量大,主例項使用記憶體800MB,從例項使用記憶體10MB
2、日誌資訊
排查發生記憶體洩漏的容器日誌:
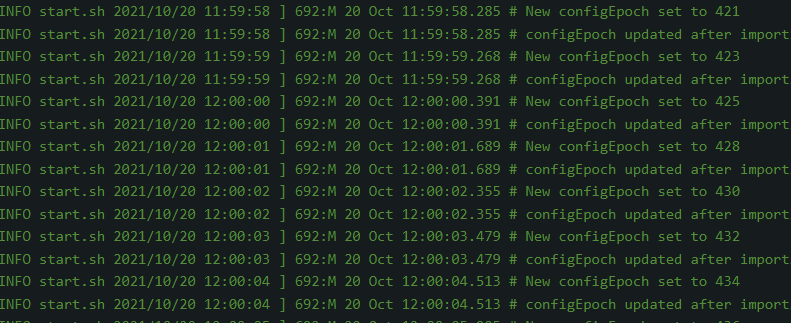
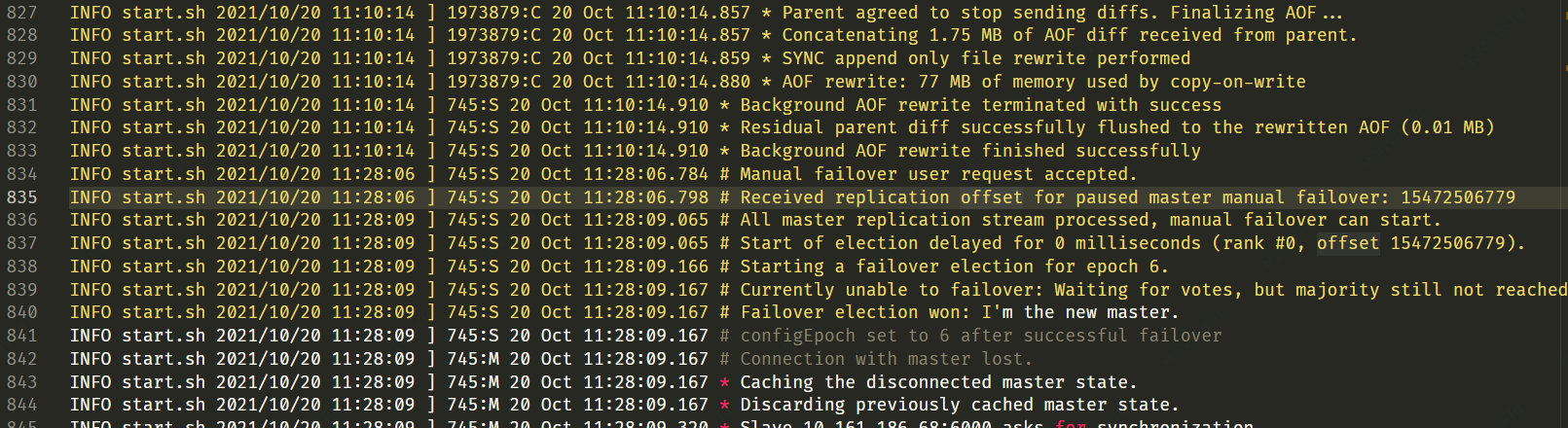
Redis 在10月11日被建立後,只有在20日出現有大量日誌,之後無日誌,日誌有以下內容:
Redis 橫向擴容 slot 遷移
主從切換
AOF 重寫
搜尋該系統的歷史簡訊告警,在10月11日11:33分出現三次記憶體使用率達到100%的告警,因此可以推測出現 key 淘汰
Manager平臺操作資訊:
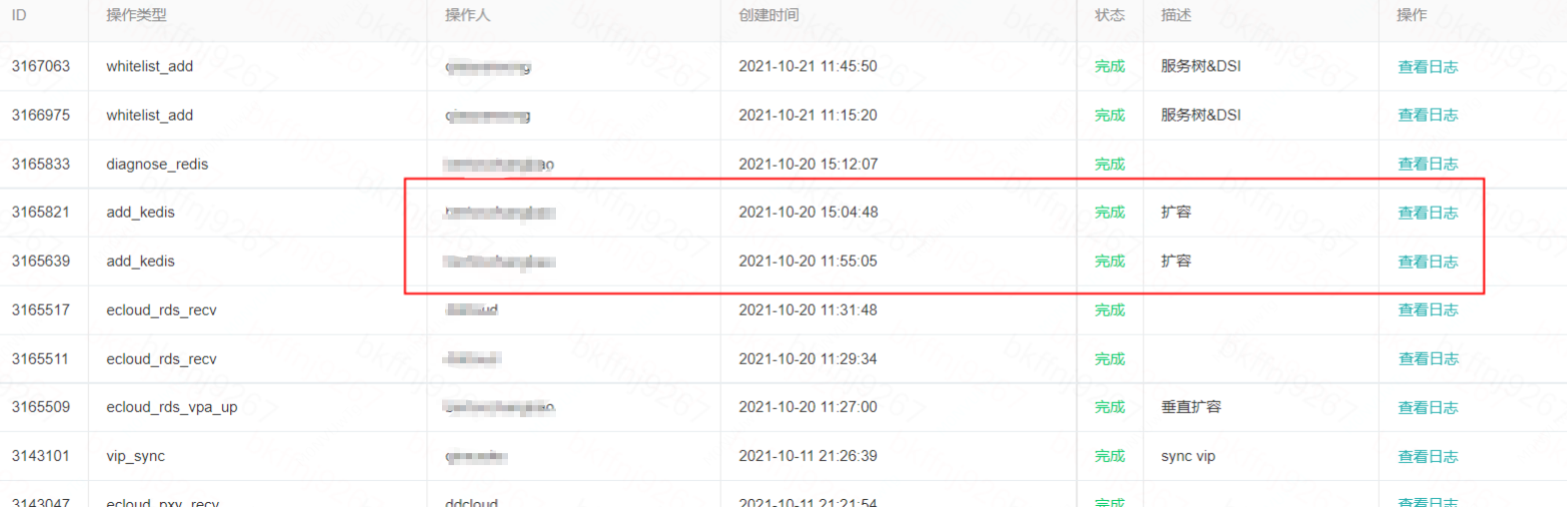
垂直擴容
橫向擴容
Redis 重啟
綜合 Redis 的日誌和平臺日誌資訊,雖然未能直接發現問題原因,可以確定記憶體洩漏發生在10月20日11:30左右,由以下單個事件或者混合觸發的:
主從切換
key 遷移
key 驅除
18:00 列印記憶體 dump 資訊
在例項上使用 GDB 把洩漏例項的所有記憶體 dump 出來,初步發現記憶體上有很多 key(647w個),不屬於本節點,info 裡資料庫只有1.6W個 key, 懷疑是slot 遷移有問題。
18:30 第一次 diff 程式碼
由於3.2.8自研版本有兩個重大修改:
slot 的所屬 key 集合記錄,把跳躍表改為了4.0以後的基數樹結構,從社群的 unstable 分支 backport 下來的;
支援多活
由於出問題的系統沒有使用多活功能,且恰巧事發時有 slot 遷移,因此重點懷疑 slot 遷移中 rax 樹相關操作有記憶體洩漏,首先檢視了相關程式碼,有幾個疑似的地方,但都排除掉了。
20:30 嘗試使用工具定位
memory doctor
Redis4 引入的記憶體診斷命令,3系列未實現
3.2.8版本使用 jemalloc-4.0.3作為記憶體分配器,嘗試使用 jeprof 工具分析記憶體使用情況,發現 jemalloc 編譯時需要提前新增--enable-prof編譯選項,此路不通
使用 perf 抓取 brk 系統呼叫,未發現異常(實際上最近兩個月也未發生洩漏)
valgrind 作為最後手段,不確定是否可以復現
22:00 組內溝通進展
和組內同學溝通下午的調查情況,仍然懷疑 rax 洩漏,其次多活或者 failover 混合動作觸發的 case 導致洩漏。
第二天10:00 重新整理思路
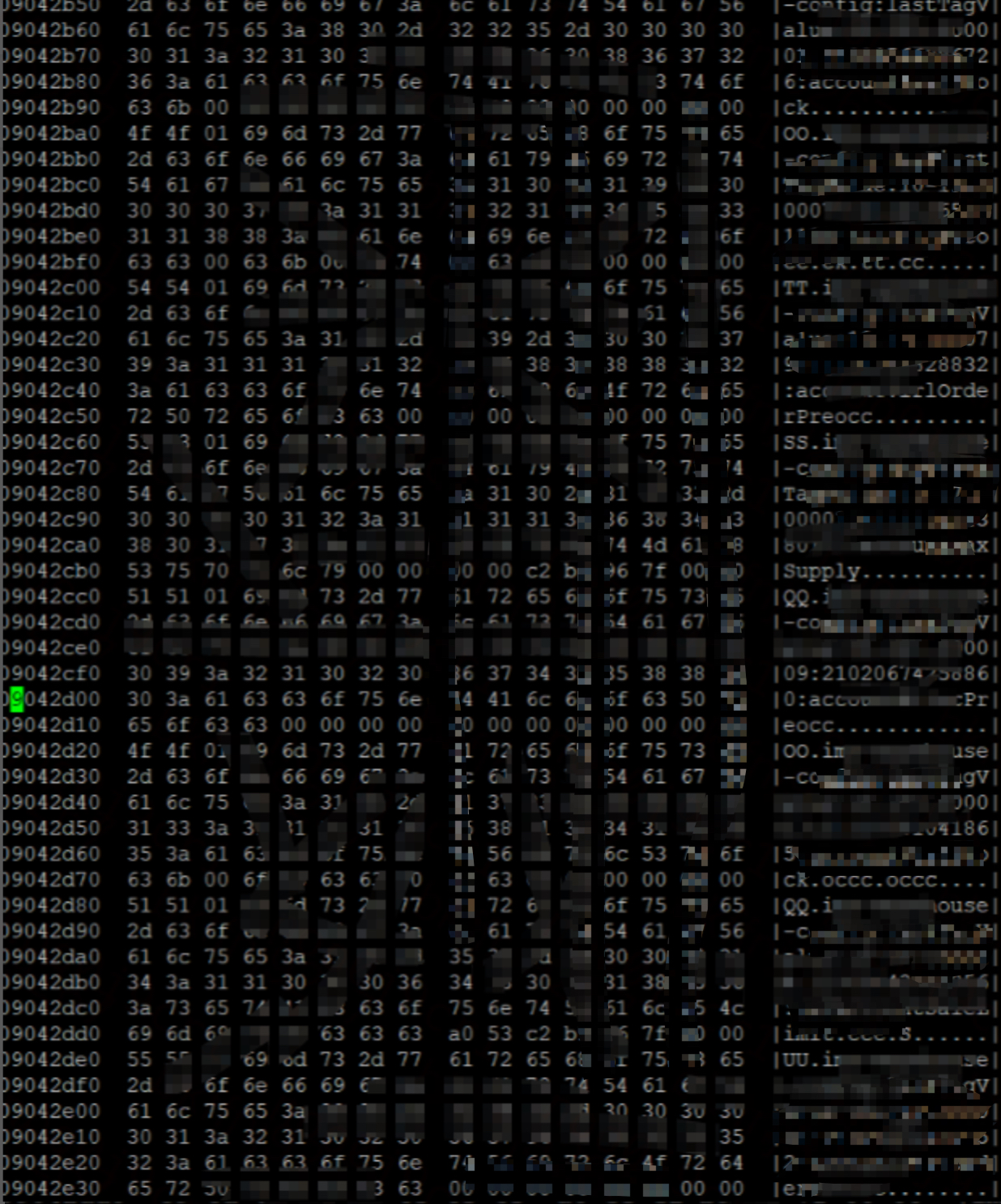
使用 hexdump 觀察昨天的記憶體 dump 檔案,發現洩漏記憶體為 SDS 字串資料型別,且連續分佈。
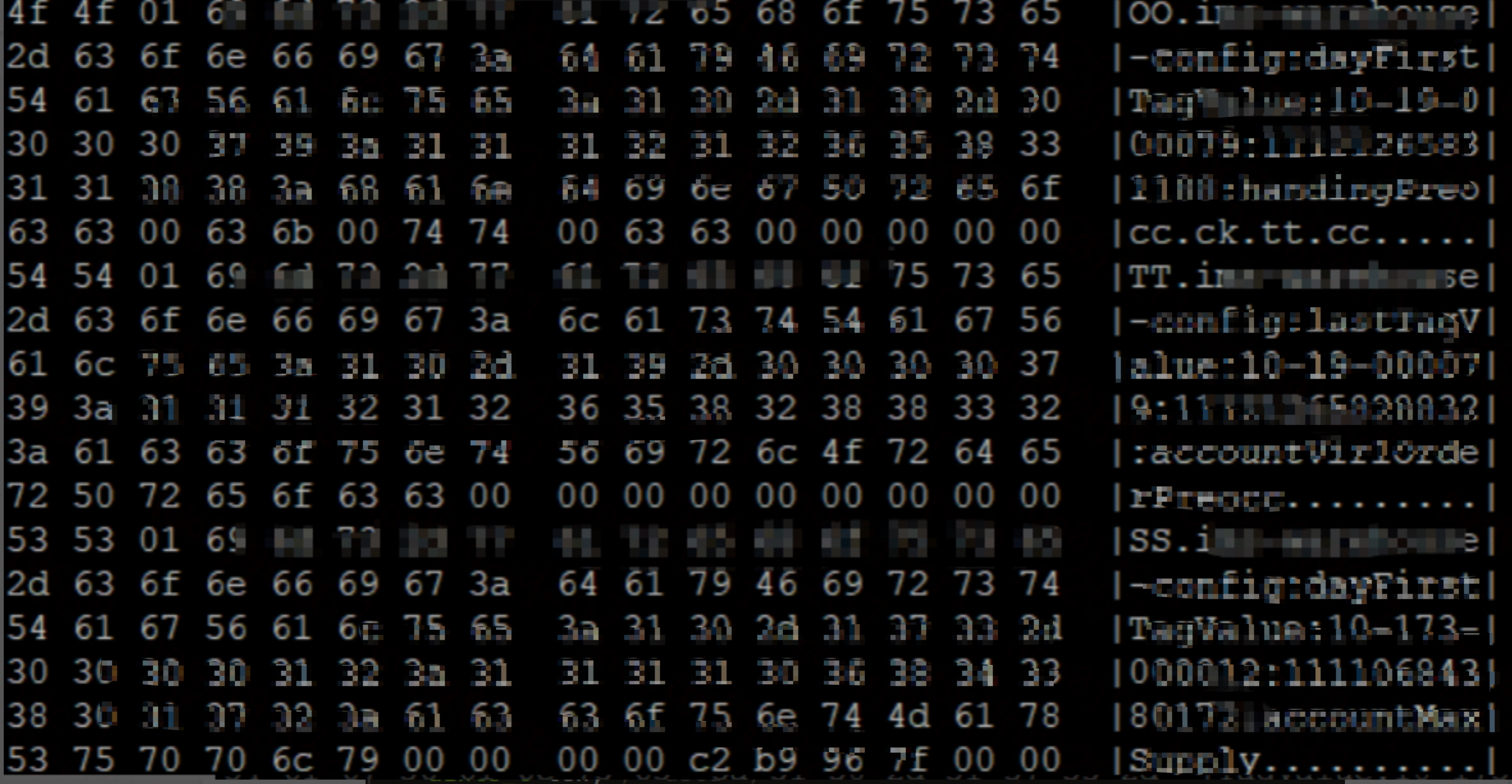
每隔4、5行都會出現OO TT SS等字元,對應 SDS 型別的 sdshdr 結構體。
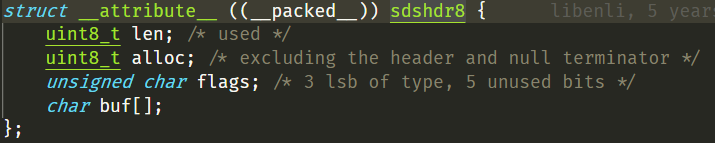
每個洩漏的 key 字串大約在80位元組左右,因此使用時 sdshdr8(為了節約記憶體,sds 的 header 有五種 sdshdr5,sdshdr8、sdshdr16、sdshdr32、sdshdr64,其中8指的是長度小於1<<8的字串使用的 sdshdr)。
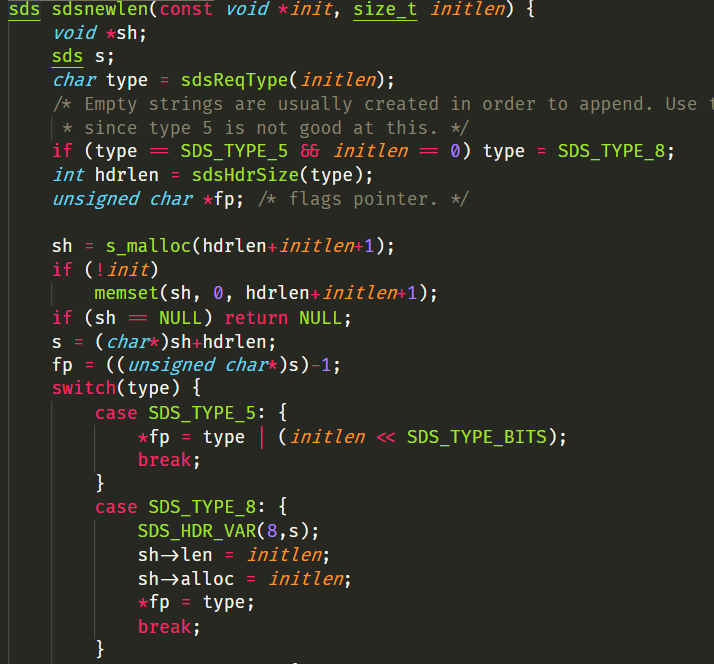
以TT那行為例,結合 SDS 字串的 new 函式分析,key 字串長度為84位元組等於0x54,結合程式碼看,sh->len和sh->alloc都是0x54,第三個位元組標識 type 型別,sdshdr8 的 type 值剛好是0x1,因此可以確認洩漏的是 sds 型別的 key 值,並且排除 rax 樹洩漏的可能,因為記憶體 dump 和 rax 樹的儲存結構不符。附典型的 rax 儲存結構:
14:00 根據dump的分析重新排查程式碼
排除了 rax 樹的洩漏,同時綜合 redis 使用 sds key 的情況,此時把懷疑重點放在了 write 等 dict 的釋放方法上,以及 rdb 的載入時 key 的臨時結構體變數。
此時 diff 程式碼,不再侷限有變更的程式碼,以功能為粒度進行走讀程式碼,但把重點放在了 failover 時的 flushdb 和 loadRDB 操作上。
17:00 排查slot遷移程式碼
在上一輪程式碼走讀中,再次排除了 failover,key 淘汰的程式碼有記憶體洩漏的可能,因此重新懷疑 slot 遷移中的某些動作導致 key 字面值的記憶體洩漏,尤其是 slot 清空等操作。
18:30 找到根因
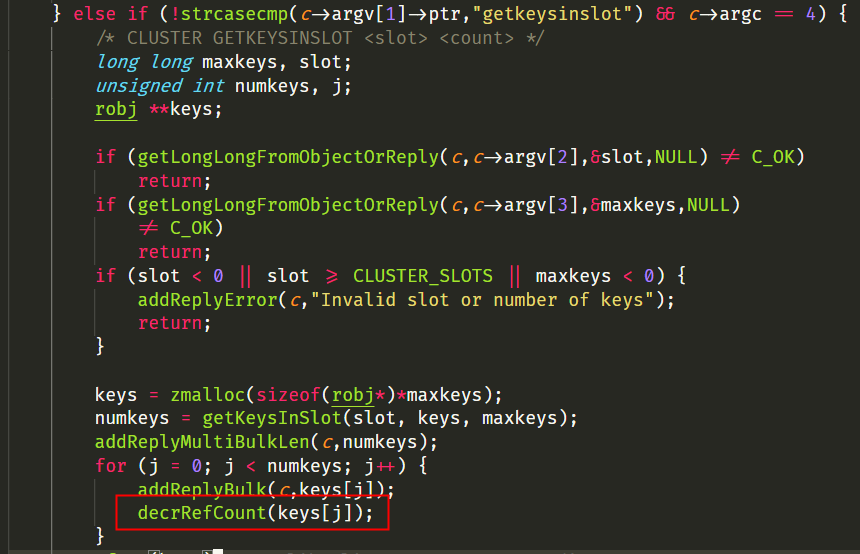
在 slot 遷移過程中,會遍歷舊節點中的所有 key,然後把遍歷得到的 key 從舊節點遷移到新節點中。

這個功能在3.2.8程式碼中沒有被改動,但其呼叫的 getKeysInSlot 函式有了修改。getKeysInSlot 是遍歷 rax 樹,拿到待遷移 key 列表,對每個 key 從 rax 樹中取出完整字串,來複製建立 obj 型別指向 sds 字串;這些字串作為陣列指標型別返回給了出參 keys,但在上層呼叫把這些字串返回給客戶端後,沒有釋放這些字串,導致了記憶體洩漏的發生。
原生的3.2.8程式碼中 getKeysInSlot 函式,由於使用的是跳躍表,該跳躍表中的每個節點都是一個 key 的 obj 型別,因此只需要返回這個 key 的指標即可,無需記憶體複製動作,因此上層呼叫中也就不需要記憶體釋放動作。這個根因查明,也反過來解釋了很多疑問:
為什麼剛開始只有老版本才有記憶體洩漏,新版本未發現。原因是老版本的例項上線時間長,有水平擴容的需求較多,記憶體洩漏的例項也就較多。
洩漏的記憶體為什麼連續分佈?原因是在一次 slot 遷移動作中,這些 key 遍歷動作都是連續進行的。
這個系統為什麼洩漏比例這麼高?原因是該系統中 key 佔用的記憶體比 value值更高,key 通常80位元組,而 value 大多是0、1等數值。
20:00 修復動作
相比較根因的查詢,修復就簡單多了,只需新增一行程式碼即可。
後續思考
1、程式碼 review 需要從功能視角去走讀程式碼,不能只關注 diff 不同。在本次調查中,第一遍走讀程式碼只關注 diff 點,是無法發現問題的。
2、對記憶體洩漏的排查,在程式碼設計階段是避免此類問題的效率更優解,程式碼 review 階段比測試階段代價要小,測試階段發現要比上線後排查容易得多,越是工程後期修復 bug 越難。具體在該函式設計中,由於記憶體申請和釋放沒有內聚性,導致記憶體洩漏很容易出現,而這個函式在3系列使用跳躍表時是沒有問題的,因為不涉及到記憶體的申請釋放。開發和 QA 在測試中引入工具進行功能覆蓋測試,動態工具如 valgrind、sanitizers 等,線上工具如memleak、perf等。
來自 “ 滴滴技術 ”, 原文作者:鞠鄧;原文連結:https://server.it168.com/a2023/1121/6830/000006830488.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 線上問題排查例項分析|關於 Redis 記憶體洩漏Redis記憶體
- redisson記憶體洩漏問題排查Redis記憶體
- 關於PHP記憶體洩漏的問題PHP記憶體
- 解決記憶體洩漏(1)-ApacheKylin InternalThreadLocalMap洩漏問題分析記憶體Apachethread
- 記憶體洩漏問題分析之非託管資源洩漏記憶體
- ThreadLocal記憶體洩漏問題thread記憶體
- JVM 常見線上問題 → CPU 100%、記憶體洩露 問題排查JVM記憶體洩露
- 分析記憶體洩漏和goroutine洩漏記憶體Go
- 分析ThreadLocal的弱引用與記憶體洩漏問題thread記憶體
- valgrind 記憶體洩漏分析記憶體
- 關於記一次 Go 服務記憶體洩漏問題調查Go記憶體
- 對於記憶體洩漏問題的簡單認知記憶體
- PHP 記憶體洩漏分析定位PHP記憶體
- 一次 Java 記憶體洩漏的排查Java記憶體
- BufferedImage記憶體洩漏和溢位問題記憶體
- 使用 Chrome Dev tools 分析應用的記憶體洩漏問題Chromedev記憶體
- MAT工具定位分析Java堆記憶體洩漏問題方法Java記憶體
- JAVA服務例項記憶體高問題排查及解決Java記憶體
- linux程式之記憶體洩漏分析Linux記憶體
- 如何解決JVM OutOfMemoryError記憶體洩漏問題?JVMError記憶體
- 關於redis記憶體分析,記憶體優化Redis記憶體優化
- 記憶體洩漏與排查流程——安卓效能優化記憶體安卓優化
- 記憶體洩漏引起的 資料庫效能問題記憶體資料庫
- js記憶體洩漏JS記憶體
- Android記憶體洩漏Android記憶體
- Android 記憶體洩漏Android記憶體
- jvm 記憶體洩漏JVM記憶體
- Java記憶體洩漏Java記憶體
- Handler記憶體洩漏分析及解決記憶體
- Flutter 上的記憶體洩漏監控Flutter記憶體
- 記一次 Ruby 記憶體洩漏的排查和修復記憶體
- 記一次使用windbg排查記憶體洩漏的過程記憶體
- 例項解析網路程式設計中的另類記憶體洩漏程式設計記憶體
- 記一次堆外記憶體洩漏分析記憶體
- 記憶體洩漏的定位與排查:Heap Profiling 原理解析記憶體
- Java動態編譯優化——ZipFileIndex記憶體洩漏問題分析解決Java編譯優化Index記憶體
- 執行在 SSR 模式下的 Angular 應用的記憶體洩漏問題分析模式Angular記憶體
- C++--問題27--如何檢測記憶體洩漏C++記憶體