分散式系統設計中的併發訪問解決方案
引言
隨著網際網路資訊科技的飛速發展,資料量不斷增大,業務邏輯也日趨複雜,對系統的高併發訪問、海量資料處理的場景也越來越多。如何用較低成本實現系統的高可用、易伸縮、可擴充套件等目標就顯得越發重要。
為了解決這一系列問題,系統架構也在不斷演進。傳統的集中式系統已經逐漸無法滿足要求,分散式系統被使用在更多的場景中。分散式系統由獨立的伺服器透過網路鬆散耦合組成。在這個系統中每個伺服器都是一臺獨立的主機,伺服器之間透過內部網路連線。分散式系統有以下幾個特點:
可擴充套件性:可透過橫向水平擴充套件提高系統的效能和吞吐量。
高可靠性:高容錯,即使系統中一臺或幾臺故障,系統仍可提供服務。
高併發性:各機器並行獨立處理和計算。
廉價高效:多臺小型機而非單臺高效能機。
然而,在分散式系統中,其環境的複雜度、網路的不確定性會造成諸如時鐘不一致、"拜占庭將軍問題"等。存在於集中式系統中的機器當機、訊息丟失等問題也會在分散式環境中變得更加複雜。
基於分散式系統的這些特徵,有兩種問題逐漸成為了分散式環境中需要重點關注和解決的典型問題:
互斥性問題。
冪等性問題。
今天我們就針對這兩個問題來進行分析探討。
併發訪問互斥問題
先看一個常見的例子:
例1:某服務記錄關鍵資料X,當前值為100。A請求需要將X增加200;同時,B請求需要將X減100。
在理想的情況下,A先讀取到X=100,然後X增加200,最後寫入X=300。B請求接著從讀取X=300,減少100,最後寫入X=200。
然而在真實情況下,如果不做任何處理,則可能會出現:A和B同時讀取到X=100;A寫入之前B讀取到X;B比A先寫入等情況。
以上的這個例子是典型的存在操作互斥性的問題,互斥性問題用通俗的話來講,就是對共享資源的搶佔問題。如果不同的請求對同一個或者同一組資源讀取並修改時,無法保證按序執行,無法保證一個操作的原子性,那麼就很有可能會出現預期外的情況。因此操作的互斥性問題,也可以理解為一個需要保證時序性、原子性的問題。
在傳統的基於資料庫的架構中,對於資料的搶佔問題往往是透過資料庫事務(ACID)來保證的。在分散式環境中,出於對效能以及一致性敏感度的要求,使得分散式鎖成為了一種比較常見而高效的解決方案。事實上,操作互斥性問題也並非分散式環境所獨有,在傳統的多執行緒、多程式情況下已經有了很好的解決方案。因此在研究分散式鎖之前,我們先來分析下這兩種情況的解決方案,以期能夠對分散式鎖的解決方案提供一些實現思路。
1.1 多執行緒環境解決方案及原理
基本上所有的併發模式在解決執行緒衝突問題的時候,都是採用序列化訪問共享資源的方案。
在多執行緒環境中,執行緒之間因為公用一些儲存空間,衝突問題時有發生。解決衝突問題最普遍的方式就是用互斥鎖把該資源或對該資源的操作保護起來。
Java JDK中提供了兩種互斥鎖Lock和synchronized。不同的執行緒之間對同一資源進行搶佔,該資源通常表現為某個類的普通成員變數。因此,利用ReentrantLock或者synchronized將共享的變數及其操作鎖住,即可基本解決資源搶佔的問題。下面來簡單聊一聊兩者的實現原理。
1.2 多執行緒環境實現原理
1.2.1 ReentrantLock
ReentrantLock主要利用CAS+CLH佇列來實現。它支援公平鎖和非公平鎖,兩者的實現類似。
CAS:Compare and Swap,比較並交換。CAS有3個運算元:記憶體值V、預期值A、要修改的新值B。當且僅當預期值A和記憶體值V相同時,將記憶體值V修改為B,否則什麼都不做。該操作是一個原子操作,被廣泛的應用在Java的底層實現中。在Java中,CAS主要是由sun.misc.Unsafe這個類透過JNI呼叫CPU底層指令實現。
CLH佇列:帶頭結點的雙向非迴圈連結串列。
ReentrantLock的基本實現可以概括為:先透過CAS嘗試獲取鎖。如果此時已經有執行緒佔據了鎖,那就加入CLH佇列並且被掛起。當鎖被釋放之後,排在CLH佇列隊首的執行緒會被喚醒,然後CAS再次嘗試獲取鎖。在這個時候,如果:
非公平鎖:如果同時還有另一個執行緒進來嘗試獲取,那麼有可能會讓這個執行緒搶先獲取;
公平鎖:如果同時還有另一個執行緒進來嘗試獲取,當它發現自己不是在隊首的話,就會排到隊尾,由隊首的執行緒獲取到鎖。
下面分析下兩個片段:

在嘗試獲取鎖的時候,會先呼叫上面的方法。如果狀態為0,則表明此時無人佔有鎖。此時嘗試進行set,一旦成功,則成功佔有鎖。如果狀態不為0,再判斷是否是當前執行緒獲取到鎖。如果是的話,將狀態+1,因為此時就是當前執行緒,所以不用CAS。這也就是可重入鎖的實現原理。

該方法是在嘗試獲取鎖失敗加入CHL隊尾之後,如果發現前序節點是head,則CAS再嘗試獲取一次。否則,則會根據前序節點的狀態判斷是否需要阻塞。如果需要阻塞,則呼叫LockSupport的park方法阻塞該執行緒。
1.2.2 synchronized
在Java語言中存在兩種內建的synchronized語法:synchronized語句、synchronized方法。
synchronized語句:當原始碼被編譯成位元組碼的時候,會在同步塊的入口位置和退出位置分別插入monitorenter和monitorexit位元組碼指令;
synchronized方法:在Class檔案的方法表中將該方法的access_flags欄位中的synchronized標誌位置1。這個在specification中沒有明確說明。
透過上面的一些瞭解,我們可以概括出解決互斥性問題,即資源搶佔的基本方式為:
對共享資源的操作前後(進入退出臨界區)加解鎖,保證不同執行緒或程式可以互斥有序的操作資源。
加解鎖方式,有顯式的加解鎖,如ReentrantLock或訊號量;也有隱式的加解鎖,如synchronized。那麼在分散式環境中,為了保證不同JVM不同主機間不會出現資源搶佔,那麼同樣只要對臨界區加解鎖就可以了。
然而在多執行緒和多程式中,鎖已經有比較完善的實現,直接使用即可。但是在分散式環境下,就需要我們自己來實現分散式鎖。
1.3 分散式環境下的解決方案-分散式鎖
1.3.1 分散式鎖條件
再回顧下多執行緒和多程式環境下的鎖,可以發現鎖的實現有很多共通之處,它們都需要滿足一些最基本的條件:
1. 需要有儲存鎖的空間,並且鎖的空間是可以訪問到的。
2. 鎖需要被唯一標識。
3. 鎖要有至少兩種狀態。
仔細分析這三個條件:
儲存空間
鎖是一個抽象的概念,鎖的實現,需要依存於一個可以儲存鎖的空間。在多執行緒中是記憶體,在多程式中是記憶體或者磁碟。更重要的是,這個空間是可以被訪問到的。多執行緒中,不同的執行緒都可以訪問到堆中的成員變數;在多程式中,不同的程式可以訪問到共享記憶體中的資料或者儲存在磁碟中的檔案。但是在分散式環境中,不同的主機很難訪問對方的記憶體或磁碟。這就需要一個都能訪問到的外部空間來作為儲存空間。
最普遍的外部儲存空間就是資料庫了,事實上也確實有基於資料庫做分散式鎖(行鎖、version樂觀鎖),如quartz叢集架構中就有所使用。除此以外,還有各式快取如Redis、Tair、Memcached、MongoDB,當然還有專門的分散式協調服務Zookeeper,甚至是另一臺主機。只要可以儲存資料、鎖在其中可以被多主機訪問到,那就可以作為分散式鎖的儲存空間。
唯一標識
不同的共享資源,必然需要用不同的鎖進行保護,因此相應的鎖必須有唯一的標識。在多執行緒環境中,鎖可以是一個物件,那麼對這個物件的引用便是這個唯一標識。多程式環境中,訊號量在共享記憶體中也是由引用來作為唯一的標識。但是如果不在記憶體中,失去了對鎖的引用,如何唯一標識它呢?上文提到的有名訊號量,便是用硬碟中的檔名作為唯一標識。因此,在分散式環境中,只要給這個鎖設定一個名稱,並且保證這個名稱是全域性唯一的,那麼就可以作為唯一標識。
至少兩種狀態
為了給臨界區加鎖和解鎖,需要儲存兩種不同的狀態。如ReentrantLock中的status,0表示沒有執行緒競爭,大於0表示有執行緒競爭;訊號量大於0表示可以進入臨界區,小於等於0則表示需要被阻塞。因此只要在分散式環境中,鎖的狀態有兩種或以上:如有鎖、沒鎖;存在、不存在等,均可以實現。
有了這三個條件,基本就可以實現一個簡單的分散式鎖了。
下面以資料庫為例,實現一個簡單的分散式鎖:
資料庫表,欄位為鎖的ID(唯一標識),鎖的狀態(0表示沒有被鎖,1表示被鎖)。

問題
以上的方式即可以實現一個粗糙的分散式鎖,但是這樣的實現,有沒有什麼問題呢?
問題1:鎖狀態判斷原子性無法保證
從讀取鎖的狀態,到判斷該狀態是否為被鎖,需要經歷兩步操作。如果不能保證這兩步的原子性,就可能導致不止一個請求獲取到了鎖,這顯然是不行的。因此,我們需要保證鎖狀態判斷的原子性。
問題2:網路斷開或主機當機,鎖狀態無法清除
假設在主機已經獲取到鎖的情況下,突然出現了網路斷開或者主機當機,如果不做任何處理該鎖將仍然處於被鎖定的狀態。那麼之後所有的請求都無法再成功搶佔到這個鎖。因此,我們需要在持有鎖的主機當機或者網路斷開的時候,及時的釋放掉這把鎖。
問題3:無法保證釋放的是自己上鎖的那把鎖
在解決了問題2的情況下再設想一下,假設持有鎖的主機A在臨界區遇到網路抖動導致網路斷開,分散式鎖及時的釋放掉了這把鎖。之後,另一個主機B佔有了這把鎖,但是此時主機A網路恢復,退出臨界區時解鎖。由於都是同一把鎖,所以A就會將B的鎖解開。此時如果有第三個主機嘗試搶佔這把鎖,也將會成功獲得。因此,我們需要在解鎖時,確定自己解的這個鎖正是自己鎖上的。
進階條件
如果分散式鎖的實現,還能再解決上面的三個問題,那麼就可以算是一個相對完整的分散式鎖了。然而,在實際的系統環境中,還會對分散式鎖有更高階的要求。
1. 可重入:執行緒中的可重入,指的是外層函式獲得鎖之後,內層也可以獲得鎖,ReentrantLock和synchronized都是可重入鎖;衍生到分散式環境中,一般仍然指的是執行緒的可重入,在絕大多數分散式環境中,都要求分散式鎖是可重入的。
2. 驚群效應(Herd Effect):在分散式鎖中,驚群效應指的是,在有多個請求等待獲取鎖的時候,一旦佔有鎖的執行緒釋放之後,如果所有等待的方都同時被喚醒,嘗試搶佔鎖。但是這樣的情況會造成比較大的開銷,那麼在實現分散式鎖的時候,應該儘量避免驚群效應的產生。
3. 公平鎖和非公平鎖:不同的需求,可能需要不同的分散式鎖。非公平鎖普遍比公平鎖開銷小。但是業務需求如果必須要鎖的競爭者按順序獲得鎖,那麼就需要實現公平鎖。
4. 阻塞鎖和自旋鎖:針對不同的使用場景,阻塞鎖和自旋鎖的效率也會有所不同。阻塞鎖會有上下文切換,如果併發量比較高且臨界區的操作耗時比較短,那麼造成的效能開銷就比較大了。但是如果臨界區操作耗時比較長,一直保持自旋,也會對CPU造成更大的負荷。
保留以上所有問題和條件,我們接下來看一些比較典型的實現方案。
1.3.2 分散式鎖的典型實現
ZooKeeper的實現
ZooKeeper(以下簡稱"ZK")中有一種節點叫做順序節點,假如我們在/lock/目錄下建立3個節點,ZK叢集會按照發起建立的順序來建立節點,節點分別為/lock/0000000001、/lock/0000000002、/lock/0000000003。
ZK中還有一種名為臨時節點的節點,臨時節點由某個客戶端建立,當客戶端與ZK叢集斷開連線,則該節點自動被刪除。EPHEMERAL_SEQUENTIAL為臨時順序節點。
根據ZK中節點是否存在,可以作為分散式鎖的鎖狀態,以此來實現一個分散式鎖,下面是分散式鎖的基本邏輯:
客戶端呼叫create()方法建立名為"/dlm-locks/lockname/lock-"的臨時順序節點。
客戶端呼叫getChildren("lockname")方法來獲取所有已經建立的子節點。
客戶端獲取到所有子節點path之後,如果發現自己在步驟1中建立的節點是所有節點中序號最小的,那麼就認為這個客戶端獲得了鎖。
如果建立的節點不是所有節點中需要最小的,那麼則監視比自己建立節點的序列號小的最大的節點,進入等待。直到下次監視的子節點變更的時候,再進行子節點的獲取,判斷是否獲取鎖。
釋放鎖的過程相對比較簡單,就是刪除自己建立的那個子節點即可,不過也仍需要考慮刪除節點失敗等異常情況。
Redis的實現
Redis的分散式快取特性使其成為了分散式鎖的一種基礎實現。透過Redis中是否存在某個鎖ID,則可以判斷是否上鎖。為了保證判斷鎖是否存在的原子性,保證只有一個執行緒獲取同一把鎖,Redis有SETNX(即SET if Not
eXists)和GETSET(先寫新值,返回舊值,原子性操作,可以用於分辨是不是首次操作)操作。
為了防止主機當機或網路斷開之後的死鎖,Redis沒有ZK那種天然的實現方式,只能依賴設定超時時間來規避。
以下是一種比較普遍但不太完善的Redis分散式鎖的實現步驟(與下圖一一對應):
執行緒A傳送SETNX lock.orderid嘗試獲得鎖,如果鎖不存在,則set並獲得鎖。
如果鎖存在,則再判斷鎖的值(時間戳)是否大於當前時間,如果沒有超時,則等待一下再重試。
如果已經超時了,在用GETSET lock.{orderid}來嘗試獲取鎖,如果這時候拿到的時間戳仍舊超時,則說明已經獲得鎖了。
如果在此之前,另一個執行緒C快一步執行了上面的操作,那麼A拿到的時間戳是個未超時的值,這時A沒有如期獲得鎖,需要再次等待或重試。
該實現還有一個需要考慮的問題是全域性時鐘問題,由於生產環境主機時鐘不能保證完全同步,對時間戳的判斷也可能會產生誤差。
冪等性問題
冪等(idempotent)是一個數學與電腦科學概念,常見於抽象代數中。
所謂冪等,簡單地說,就是對介面的多次呼叫所產生的結果和呼叫一次是一致的,多次呼叫方法或者介面不會改變業務狀態,可以保證重複呼叫的結果和單次呼叫的結果一致。擴充套件一下,這裡的介面,可以理解為對外發布的HTTP介面或者dubbo介面,也可以是接收訊息的內部介面,甚至是一個內部方法或操作。使用冪等性的場景有如下:
1. 前端重複提交,如在App中下訂單的時候,點選確認之後,沒反應,就又點選了幾次。在這種情況下,如果無法保證該介面的冪等性,那麼將會出現重複下單問題。
2.介面超時重試,對於給第三方呼叫的介面,有可能會因為網路原因而呼叫失敗,這時,一般在設計的時候會對介面呼叫加上失敗重試的機制。如果第一次呼叫已經執行了一半時,發生了網路異常。這時再次呼叫時就會因為髒資料的存在而出現呼叫異常。
3.訊息重複消費,在使用訊息中介軟體來處理訊息佇列,且手動 ack 確認訊息被正常消費時。如果消費者突然斷開連線,那麼已經執行了一半的訊息會重新放回佇列。當訊息被其他消費者重新消費時,如果沒有冪等性,就會導致訊息重複消費時結果異常,如資料庫重複資料,資料庫資料衝突,資源重複等。
在分散式環境中,網路環境更加複雜,因前端操作抖動、網路故障、訊息重複、響應速度慢等原因,對介面的重複呼叫機率會比集中式環境下更大,尤其是重複訊息在分散式環境中很難避免。以下是冪等控制的集中解決方案:
2.1 token 機制實現
透過token 機制實現介面的冪等性,這是一種比較通用性的實現方法。
示意圖如下:
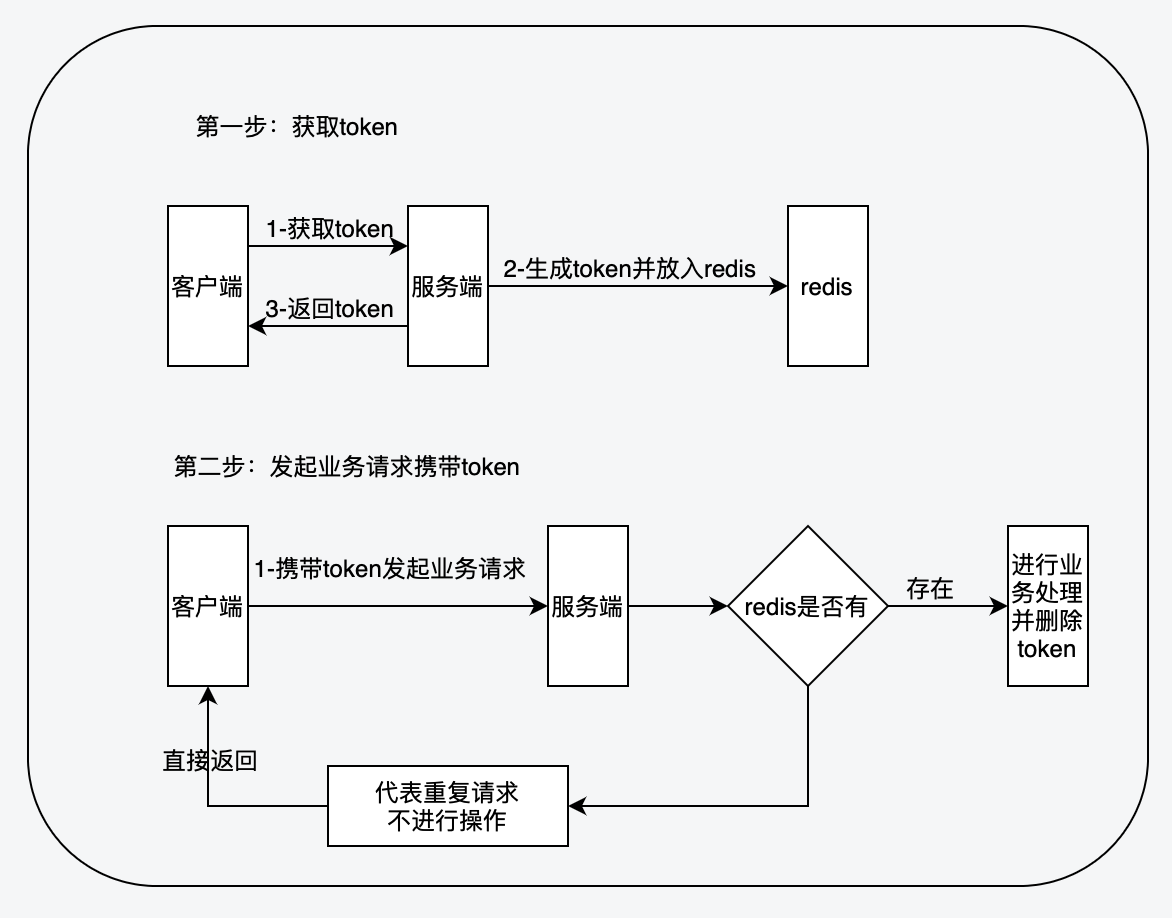
具體流程步驟:
1. 客戶端會先傳送一個請求去獲取 token,服務端會生成一個全域性唯一的 ID 作為 token 儲存在 redis 中,同時把這個 ID 返回給客戶端。
2. 客戶端第二次呼叫業務請求的時候必須攜帶這個 token。
3. 服務端會校驗這個 token,如果校驗成功,則執行業務,並刪除 redis 中的 token。
4. 如果校驗失敗,說明 redis 中已經沒有對應的 token,則表示重複操作,直接返回指定的結果給客戶端
2.2 基於 mysql 實現
這種實現方式是利用 mysql 唯一索引的特性。示意圖如下:
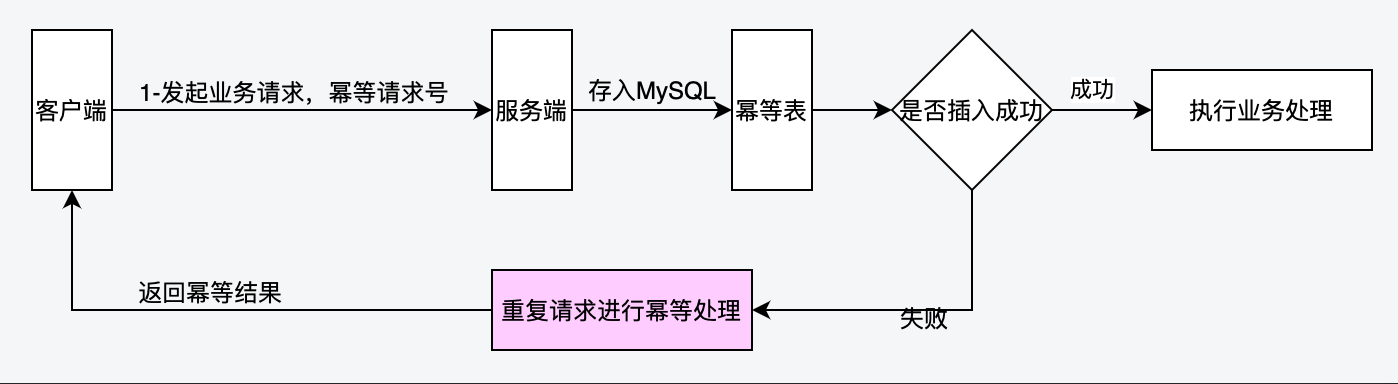
具體流程步驟:
1. 建立一張去重表,其中某個欄位需要建立唯一索引
2. 客戶端去請求服務端,服務端會將這次請求的一些資訊插入這張去重表中
3. 因為表中某個欄位帶有唯一索引,如果插入成功,證明表中沒有這次請求的資訊,則執行後續的業務邏輯
4. 如果插入失敗,則代表已經執行過當前請求,直接返回。
2.3 基於 redis 實現
這種實現方式是基於 SETNX 命令實現的。
SETNX key value:將 key 的值設為 value ,當且僅當 key 不存在。若給定的 key 已經存在,則 SETNX 不做任何動作。該命令在設定成功時返回 1,設定失敗時返回 0。示意圖如下:
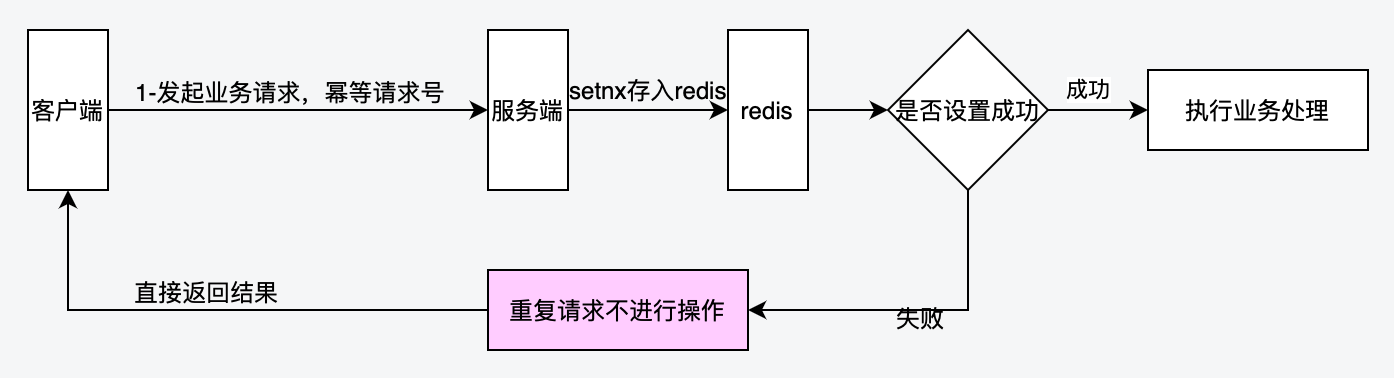
具體流程步驟:
1. 客戶端先請求服務端,會拿到一個能代表這次請求業務的唯一欄位
2. 將該欄位以 SETNX 的方式存入 redis 中,並根據業務設定相應的超時時間
3. 如果設定成功,證明這是第一次請求,則執行後續的業務邏輯
4. 如果設定失敗,則代表已經執行過當前請求,直接返回
結語
在分散式環境中,操作互斥性問題和冪等性問題非常普遍。經過分析,我們找出瞭解決這兩個問題的基本思路和實現原理,並給出了具體的解決方案。
針對操作互斥性問題,常見的做法便是透過分散式鎖來處理對共享資源的搶佔。分散式鎖的實現,很大程度借鑑了多執行緒和多程式環境中的互斥鎖的實現原理。只要滿足一些儲存方面的基本條件,並且能夠解決如網路斷開等異常情況,那麼就可以實現一個分散式鎖。
針對操作冪等性問題,我們可以透過防止重複操作來間接的實現介面的冪等性,這幾種實現冪等的方式其實都是大同小異的。總之,當你去設計一個介面的時候,冪等都是首要考慮的問題,特別是當你負責設計轉賬、支付這種涉及到 money 的介面,都需要重點設計介面操作的冪等性問題。
來自 “ 得物技術 ”, 原文作者:行之;原文連結:https://server.it168.com/a2023/0518/6804/000006804230.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 分散式系統設計中的併發訪問解決方案 | 得物技術分散式
- 用分散式鎖解決併發問題分散式
- 如何用分散式鎖解決陪玩平臺原始碼中的併發問題?分散式原始碼
- 分散式鎖的解決方案分散式
- PHP利用Redis鎖解決併發訪問PHPRedis
- [分散式][高併發]訊息佇列的使用場景、概念、常見問題及解決方案分散式佇列
- 分散式系統程式設計分散式程式設計
- 分散式系統設計策略分散式
- java併發程式設計 --併發問題的根源及主要解決方法Java程式設計
- 談談高併發系統的一些解決方案
- 分散式搜尋系統的設計分散式
- 分散式下的WebSocket解決方案分散式Web
- 從併發程式設計到分散式系統-如何處理海量資料(上)程式設計分散式
- 分散式系統中的事務問題分散式
- mysql 高併發 select update 併發更新問題解決方案MySql
- 分散式鎖解決併發的三種實現方式分散式
- 分散式ID設計方案分散式
- 解析分散式系統的快取設計分散式快取
- 分散式系統2:分散式系統中的時鐘分散式
- Redis 分散式鎖解決方案Redis分散式
- Redis分散式鎖解決方案Redis分散式
- SAP HANA分散式解決方案分散式
- 分散式事務解決方案分散式
- 分散式系統中,許可權設計實踐分散式
- GitHub 不能訪問解決方案Github
- 分散式系統的問題分散式
- [分散式]架構設計原則--高併發分散式架構
- 分散式系統中常見技術解決的問題是什麼?分散式
- 聊聊分散式下的WebSocket解決方案分散式Web
- 常用的分散式事務解決方案分散式
- 使用redis分散式鎖解決併發執行緒資源共享問題Redis分散式執行緒
- 分散式系統中的一些問題分散式
- 解決資料庫高併發訪問瓶頸問題資料庫
- 高訪問量高併發問題的一部分解決方案
- 分散式系統安全設計原則分散式
- PHP高併發商品秒殺問題的解決方案PHP
- 「分散式技術專題」併發系列三:樂觀併發控制之原型系統(分散式驗證)分散式原型
- 一種基於柔性事務的分散式事務解決方案設計探究分散式