騰訊廣告模型基於"太極"的訓練成本最佳化實踐
近年來,大資料加大模型成為了 AI 領域建模的標準正規化。在廣告場景,大模型由於使用了更多的模型引數,利用更多的訓練資料,模型具備了更強的記憶能力和泛化能力,為廣告效果向上提升開啟了更大的空間。但是大模型在訓練過程中所需要的資源也是成倍的增長,儲存以及計算上的壓力對機器學習平臺都是巨大的挑戰。
騰訊太極機器學習平臺持續探索降本增效方案,在廣告離線訓練場景利用混合部署資源大大降低了資源成本,每天為騰訊廣告提供 50W 核心廉價混合部署資源,幫助騰訊廣告離線模型訓練資源成本降低 30%,同時透過一系列最佳化手段使得混部資源穩定性和正常資源持平。
1. 引言
近年來, 隨著大模型在 NLP 領域橫掃各種大資料磅單取得巨大成功之後,大資料加大模型成為了 AI 領域建模的標準正規化。搜尋、廣告、推薦的建模也不例外,動輒千億引數,上 T 大小的模型成為各大預估場景的標配,大模型能力也已經成為各大科技公司軍備競賽的焦點。
在廣告場景,大模型由於使用了更多的模型引數,利用更多的訓練資料,模型具備了更強的記憶能力和泛化能力,為廣告效果向上提升開啟了更大的空間。但是大模型在訓練過程中所需要的資源也是成倍的增長,儲存以及計算上的壓力對機器學習平臺都是巨大的挑戰。同時平臺能夠支撐的試驗數量直接影響演算法迭代效率,如何用更小的成本,提供更多的試驗資源,是平臺努力的重點方向。
騰訊太極機器學習平臺持續探索降本增效方案,在廣告離線訓練場景利用混合部署資源大大降低了資源成本,每天為騰訊廣告提供 50W 核心廉價混合部署資源,幫助騰訊廣告離線模型訓練資源成本降低 30%,同時透過一系列最佳化手段使得混部資源穩定性和正常資源持平。
2. 太極機器學習平臺介紹
太極機器學習平臺,致力於讓使用者更加聚焦業務AI問題解決和應用,一站式的解決演算法工程師在 AI 應用過程中特徵處理,模型訓練,模型服務等工程問題。目前支援公司內廣告,搜尋,遊戲,騰訊會議,騰訊雲等重點業務。
太極廣告平臺是太極為廣告系統設計的集模型訓練和線上推理的高效能機器學習平臺,平臺具備萬億引數模型的訓練和推理能力。目前該平臺支援騰訊廣告召回,粗排,精排數十個模型訓練和線上推理;同時太極平臺提供一站式特徵註冊,樣本補錄,模型訓練,模型評估以及上線試驗的能力,極大提升了開發者效率。
訓練平臺:目前模型訓練支援 CPU 和 GPU 兩種訓練模式,利用自研高效運算元,混合精度訓練,3D 並行等技術,訓練速度和業界開源系統相比提升 1 個量級。
推理框架:太極自研的 HCF(Heterogeneous Computing Framework) 異構計算框架,透過硬體層,編譯層和軟體層聯合最佳化,提供極致效能最佳化。
3. 成本最佳化具體實現
3.1 整體方案介紹
隨著太極平臺的不斷髮展,任務數和任務型別日益增多,資源需求也隨之增多。為了降本增效,太極平臺一方面提升平臺效能,提升訓練速度;另一方面,我們也尋找更加廉價的資源,以滿足不斷增長的資源需求。
峰巒——騰訊公司內部雲原生大資料平臺,利用雲原生技術,對公司整個大資料架構進行升級。為滿足大資料業務持續增長的資源需求,峰巒引入混部資源,在滿足資源需求的同時,又可極大降低資源成本。峰巒針對不同場景下的混部資源,提供了一系列的解決方案,把不穩定的混部資源變成對業務透明的穩定資源。峰巒混部能力支援3類混部資源:
複用線上空閒資源。線上資源因波峰波谷現象、資源使用預估過高和叢集資源碎片等原因,導致叢集資源利用率不高,有大量的空閒資源。峰巒挖掘這部分臨時空閒資源,來執行大資料任務,目前已在線上廣告、儲存、社交娛樂和遊戲等場景混部。
離線資源彈性借出。大資料平臺有些任務也具有潮汐現象,在白天大資料叢集資源使用率低的時候,峰巒支援把部分資源臨時彈性借出,待大資料叢集高峰到來之前,再拿回這部分資源。這種場景非常適合解決節假日和大促期間線上任務臨時需要大量資源問題,峰巒當前已支援春節和 618 等重大節假日。
複用算力資源。算力資源是以低優 CVM 方式挖掘雲母機的空閒資源,所謂低優 CVM 是指在雲母機上啟動具有更低 CPU 優先順序的 CVM 虛擬機器,該虛擬機器可實時被其他的虛擬機器搶佔資源。峰巒基於底層算力提供的資源資訊,在排程、過載保護、算力遷移等方面做了大量的最佳化,目前已有百萬核的大資料任務在算力資源上穩定執行。
同時,峰巒引入雲原生虛擬叢集技術,遮蔽底層混部資源來自不同的城市和地域導致的分散性特點。太極平臺直接對接峰巒租戶叢集,該租戶叢集對應底層多種混部資源,而且租戶叢集擁有獨立和完整的叢集視角,太極平臺也可無縫對接。
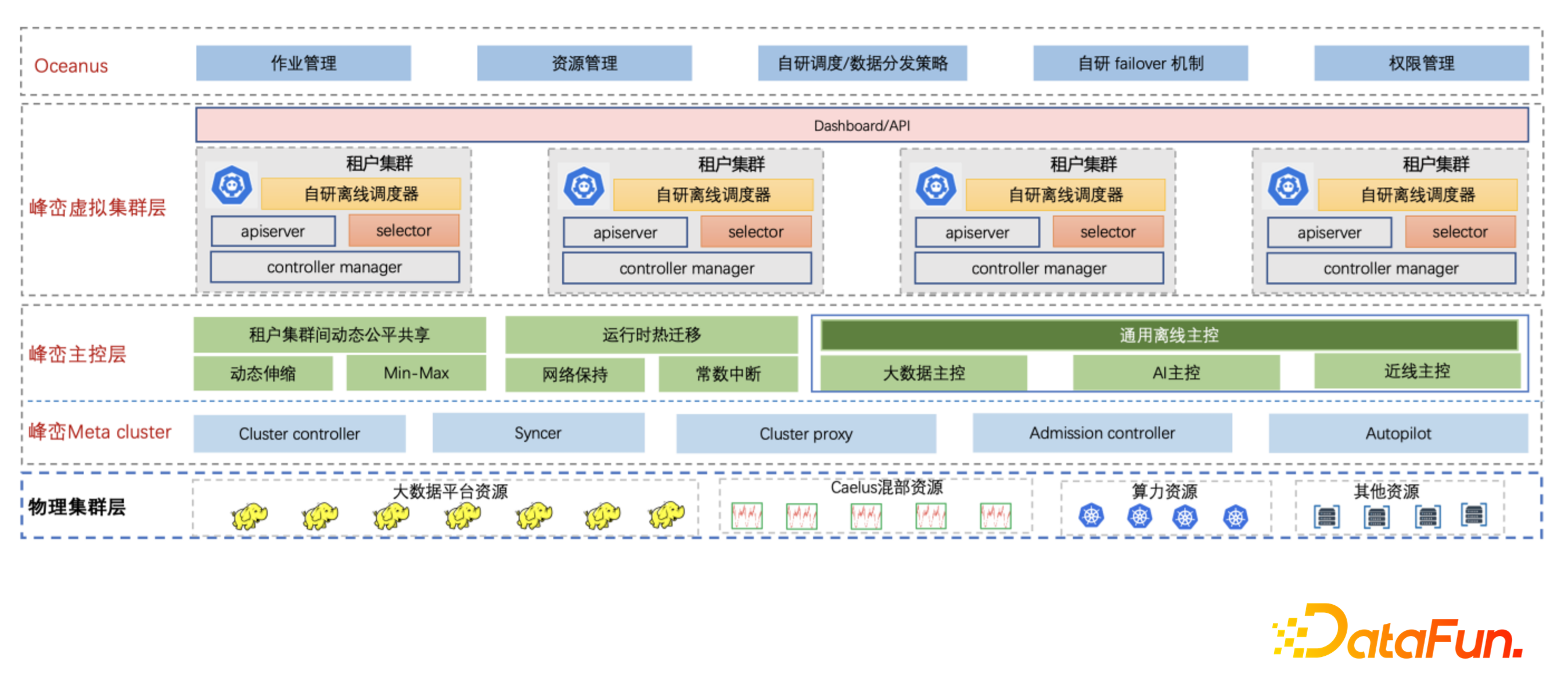
3.2 資源混部方案
3.2.1 線上空閒資源
峰巒自研了 Caelus 全場景在離線混部方案,透過將線上作業和離線作業混部的方式,充分挖掘線上機器的空閒資源,提升線上機器資源利用率,同時降低離線作業的資源成本。
如下圖所示,是 Caelus 的基本架構,各個元件和模組相互配合,從多方面保證了混部的質量。
首先,Caelus 全方位保證了線上作業的服務質量,這也是混部的重要前提之一,比如:透過快速的干擾檢測與處理機制,主動感知線上服務質量,及時進行處理,並且支援外掛化的擴充套件方式支援業務的特定干擾檢測需求;透過全維度的資源隔離、靈活的資源管理策略等,保證線上服務的高優先順序。
其次,Caelus 從多方面保證了離線作業的 SLO,比如:透過混部資源與離線作業畫像,為作業匹配合適的資源,避免資源競爭;最佳化離線作業驅逐策略,優先排序驅逐,支援優雅退出,策略靈活可控。與大資料離線作業大多是短作業(分鐘級甚至秒級)的特點不同的是,太極作業的執行時間大多較長(小時級甚至天級)。透過長週期的資源預測與作業畫像更好地指導排程,為不同執行時長、不同資源需求的作業找到合適的資源,避免作業執行幾小時甚至幾天後被驅逐,導致作業狀態丟失,浪費資源與時間。當出現需要驅逐離線作業的情況時,會優先透過執行時熱遷移,將作業例項從一個機器遷移到另一個機器,並且保持記憶體狀態和IP等不變,作業幾乎無影響,極大地提升了作業的 SLO。為了更好地把混部資源利用好,Caelus 還具備其他更多的能力,詳見 Caelus 全場景在離線混部方案()。

3.2.2 潮汐資源
大資料任務一般是白天任務量相對少,晚上任務量多,峰巒把白天部分空閒的大資料資源出讓給太極平臺,夜間再回收這部分資源,我們把這種資源稱為潮汐資源。潮汐資源的特點是節點上的大資料任務幾乎是完全退出的,但節點上還保留著大資料的儲存服務 HDFS,執行太極作業時不能影響到 HDFS 服務。太極平臺使用潮汐資源時需要和峰巒平臺協商一致,峰巒平臺在固定時間點提前根據歷史資料篩選一批節點,待大資料任務優雅退出後,通知太極平臺有新的節點加入,太極平臺開始在峰巒租戶叢集提交更多的任務。借用時間到達前,峰巒通知太極平臺部分節點要回收,太極平臺有序歸還節點。
如下圖所示,潮汐資源的挖掘、管理和使用涉及到多個系統的分工配合:

大資料資源出讓系統:該系統會根據各個機器上不同的作業執行情況以及叢集過去一段時間的執行資料,基於機器學習演算法,找到最合適的待下線的機器節點,以滿足特定的資源需求並且對正在執行的作業影響最小,然後禁止排程新的作業到這些節點上,等待節點上正在執行的作業執行完畢,最大限度地降低對大資料作業的影響。
Caelus 混部系統:雖然出讓系統騰挪出來的機器資源上沒有執行大資料作業了,但上面還執行著 HDFS 服務,還提供著資料讀寫服務。為了保護 HDFS 服務,引入Caelus混部系統,將 HDFS 作為線上服務,透過 Caelus 一系列的線上服務保證手段(如:透過 HDFS 關鍵指標檢測其是否受到影響)保證 HDFS 服務質量不受影響。
透過虛擬叢集的方式使用潮汐資源:這些出讓的機器資源會由峰巒統一管理和排程,並以虛擬叢集的方式提供給太極平臺使用,提供 K8S 原生介面,這樣做到了對上層平臺遮蔽底層資源的差異性,保證應用使透過相同的使用方式使用資源。
與應用層斷點續訓打通:潮汐資源在晚上會被回收以用於執行大資料作業,為了減少回收的影響,峰巒和應用層的斷點續訓功能進行了打通,實現資源切換不中斷訓練,切換後不影響業務的繼續執行。
3.2.3 算力資源
算力資源的特點是給業務呈現的是一個獨佔的 CVM,對業務方使用來說比較友好。然而,使用算力資源的挑戰在於雲母機層面低優 CVM 的 CPU 資源會隨時被線上 CVM 壓制,導致算力資源非常不穩定:
算力機器不穩定:算力機器會因為碎片資源盤整、機房電力不足等原因下線。
算力資源優先順序低:為了保證正常 CVM 機器的服務質量不受影響,算力資源上的作業優先順序最低,會無條件為高優資源上的作業讓步,導致效能極不穩定。
驅逐頻率高:多種原因(算力資源效能不足、磁碟空間不足、磁碟卡住等)會觸發主動驅逐 pod,增加了 pod 的失敗機率。
為了解決算力資源的不穩定性問題,透過峰巒主控層擴充套件各項能力,從多方面對算力資源最佳化,提升算力穩定性:

① 資源畫像與預測:探索和蒐集各種機器效能指標,生成聚合指標,預測低優 CVM 未來一段時間的可用資源情況,這些資訊用於排程器排程 pod 和驅逐元件驅逐 pod,滿足 pod 的資源要求。
② 排程最佳化:為保證太極作業的服務質量,針對作業的需求和資源的特點,在排程策略上有較多的最佳化,將作業效能提升了 2 倍以上。
同城排程:將 PST 和訓練作業排程到同城同機房,將作業例項之間的網路延時降到最低,並且同城內的網路頻寬成本也更低,起到了降低成本的作用。
單機排程最佳化:結合資源預測的結果以及 CPU stealtime 等指標,為作業選擇效能更佳的 CPU 進行綁核,更好地提升作業效能。
分級排程:對所有管理的資源做自動打標和分級,把 Job Manager 等對容災要求比較高的作業自動排程到相對穩定的資源上。
調優排程引數:根據資源資源畫像和預測資料,排程器為作業優先挑選效能更優和更穩定的節點。另外為了解決步調不一致導致的梯隊過期問題,將同一個作業的例項排程到效能接近的機器
③ 執行時服務質量保證
主動驅逐階段引入執行時熱遷移,做到業務基本無感知:為了應對資源不穩定以及 pod 被驅逐導致應用被 kill 的問題,實現了執行時熱遷移,並且提供了多種熱遷移策略滿足不同場景的需求。目前從線上資料看,使用遷移優先策略時,對於大記憶體的容器來說,熱遷移的中斷時間是 10 多秒。我們還實現了與記憶體大小無關的常數中斷時間(恢復優先的策略)。當前每天成功主動遷移 pod 數 2 萬多次,且支援跨叢集熱遷移,極大地降低了驅逐的影響。
最佳化驅逐策略,將驅逐造成的影響降到最低:每臺機器每次驅逐時,優先驅逐後啟動的 pod,避免影響已啟動任;每個任務每次只驅逐一個節點,避免單任務上下游一起被驅逐,造成任務級重啟;pod 被驅逐時,和上層 Flink 框架聯動,主動告知 Flink,快速單點恢復。
④ 自反饋最佳化:透過資源畫像,週期性的替換掉效能差的機器,並且與底層平臺打通,實現對 CVM 的平滑抽離,讓峰巒有機會以對業務無影響的方式逐個遷移應用例項,降低對例項的影響。
⑤ 提升 Flink 層的容災能力,支援單點重啟和層級式排程
TM(Task Manager)單點重啟能力避免 Task 失敗導致整個 DAG 失敗,可以更好適配算力搶佔式特性;分層排程避免 gang scheduling 造成過長的作業等待,並且可以避免 TM Pod 過度申請的浪費。
3.3 應用層最佳化方案
3.3.1 業務容錯
離線訓練任務要使用廉價資源一個大前提就是不能影響資源上原有任務的正常執行,所以混部資源有以下幾個關鍵挑戰:
混部資源大多是臨時資源,會頻繁下線;
混部資源會無條件為高優資源讓步,導致機器效能極不穩定;
混部資源的自動驅逐機制也極大加大了節點和 pod 的失敗機率。
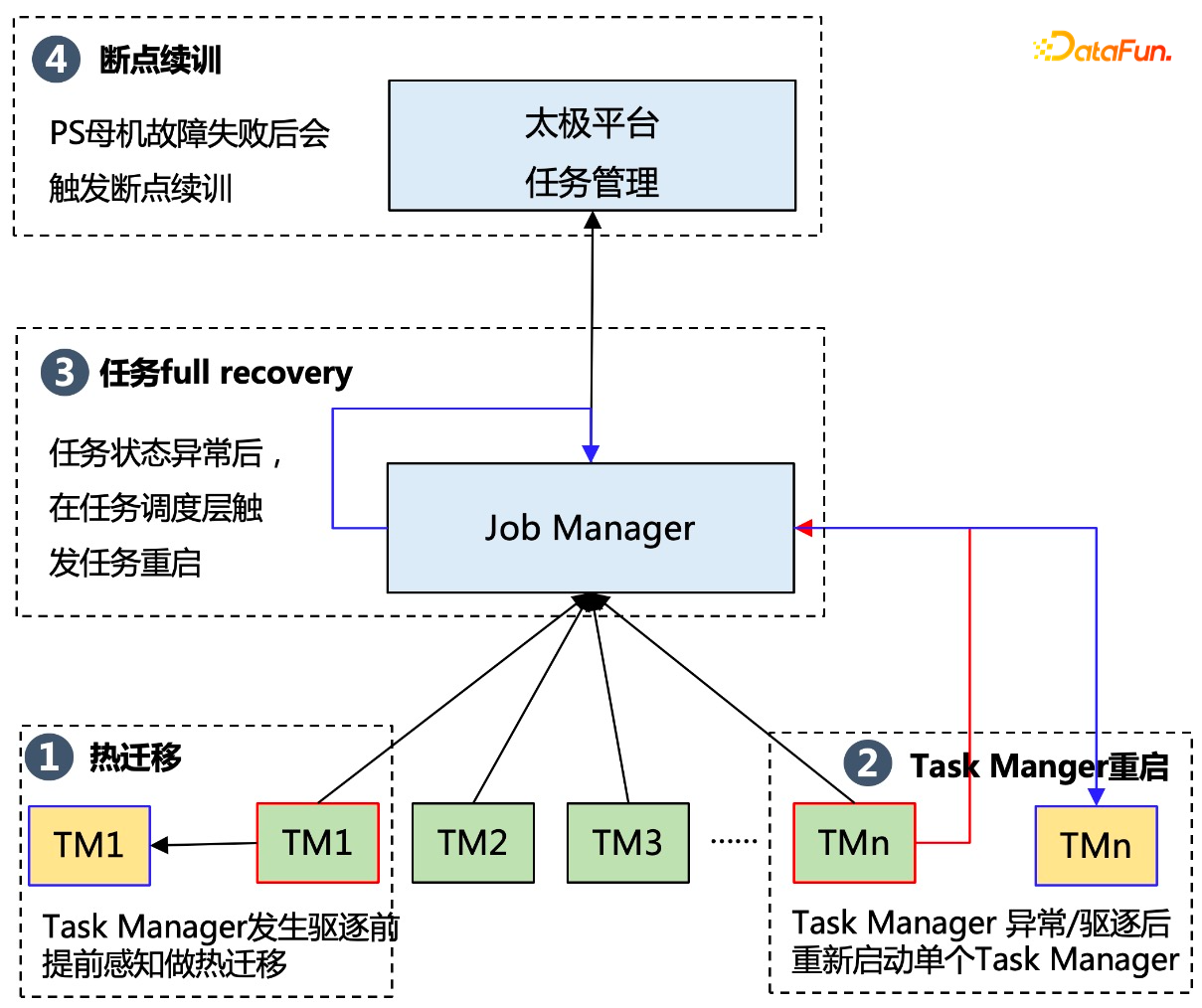
為了保證在混部資源上任務可以穩定執行,平臺使用三級容錯策略,具體解決方案如下:
熱遷移技術:在 Task Manager 將要發生驅逐前,提前感知,把相應的 Task Manager 遷移到另外一個 pod 上;同時利用記憶體壓縮,流式併發,跨叢集熱遷移等能力持續最佳化熱遷移成功率。
Task Manager 重啟:當任務當中一個 Task Manager 由於異常或者驅逐等原因導致執行失敗之後,整個任務不會直接失敗退出,而是先儲存該 Task Manager 的狀態,然後重新啟動該 Task Manager,從而降低整個任務失敗的機率。
任務 Full Recovery: 當一個任務的由於 Flink 狀態異常,處於無法恢復狀態時,會觸發 Job Manager 的重啟,為了保證 Job Manager 的穩定性,平臺把 Job Manager 部署在穩定性較好的獨立資源上,保證任務狀態正常。
斷點續訓:如果前面幾個容錯策略都失敗了,平臺會基於歷史的某一個 ckpt 重新啟動任務。
透過業務層的容錯,執行在混部資源上的任務穩定性從最初的不到 90% 提升到最終的 99.5%,基本和普通獨佔資源上任務穩定性持平。
3.3.2 任務潮汐排程
針對潮汐資源要求離線訓練任務只能白天使用,晚上需要提供給線上業務使用,所以太極平臺需要在白天時根據資源到位情況,自動啟動訓練任務;在晚上對任務做冷備,同時停止對應的訓練任務。同時透過任務管理佇列來管理每個任務排程的優先順序,對於晚上新啟動的任務會自動進入排隊狀態,等第二天早上再啟動新的任務。

核心挑戰:
潮汐現象:資源白天的時候可以提供給離線任務使用,晚上的時候需要回收。
資源動態變化:在白天時,資源也是不穩定的,資源會隨時發生變化,一般是早上的時候資源比較少,然後資源逐漸增加,到晚上的時候資源到達高峰值。
解決方案:
資源感知的排程策略:早上在資源逐步增加的過程中,潮汐排程服務需要感知資源變化,同時跟進資源情況來啟動待繼續訓練的任務。
模型自動備份能力:在晚上資源回收前,需要把當前平臺上執行的所有任務逐步做備份,這對於平臺的儲存和頻寬壓力非常大,因為平臺上有幾百個任務,每個任務冷備大小從幾百 G 到數 T 大小不等,如果在同一時間做冷備的話需要在短時間傳輸和儲存數百 T的資料,對於儲存和網路 都是巨大的挑戰;所以我們需要有一套合理的排程策略,逐步做模型的儲存。
智慧資源排程能力:潮汐排程和傳統訓練相比,每個任務在晚上資源回收時的模型備份和每天早上任務新啟動的時候的開銷是額外開銷,為了降低這部分額外開銷,我們排程時需要評估哪些任務在當天就能跑完,哪些任務需要跑多天,對於當天能跑完的任務,我們優先給它分配更多資源,保證當天任務執行完成。
透過這些最佳化能夠保證任務能穩定在潮汐資源上執行,對於業務層基本無感知。同時任務的執行速度不會受太大影響,由於任務啟停排程帶來的額外開銷控制在 10% 以內。
4. 線上效果和未來展望
太極在離線混布最佳化方案在騰訊廣告場景落地,每天為騰訊廣告離線模型調研訓練提供30W 核全天候的混合部署資源,20W 核潮汐資源,支援廣告召回,粗排,精排多場景模型訓練。在資源成本上,相同計算量任務上,混合部署資源成本是普通資源的 70%。經過最佳化系統穩定性和物理叢集任務成功率基本持平。
後續一方面我們會繼續加大混合算力資源的使用,尤其會加大混合算力資源的應用;另一方面,公司線上業務在 GPU 化,所以在混合資源應用上,除了傳統的 CPU 資源之外,也會嘗試對線上 GPU 資源在離線訓練時使用。
來自 “ DataFunTalk ”, 原文作者:騰訊TEG;原文連結:http://server.it168.com/a2023/0215/6789/000006789493.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 基於 Fluid+JindoCache 加速大模型訓練的實踐UI大模型
- ML2021 | (騰訊)PatrickStar:通過基於塊的記憶體管理實現預訓練模型的並行訓練記憶體模型並行
- 大模型量化訓練極限在哪?騰訊混元提出低位元浮點數訓練Scaling Laws大模型
- CANN訓練營第三季_基於昇騰PyTorch框架的模型訓練調優_讀書筆記PyTorch框架模型筆記
- 基於雲主機的ModelArts模型訓練實踐,讓開發環境化繁為簡模型開發環境
- 雲原生的彈性 AI 訓練系列之一:基於 AllReduce 的彈性分散式訓練實踐AI分散式
- 騰訊廣告,一個龐大的 AI「練兵場」AI
- 獲取和生成基於TensorFlow的MobilNet預訓練模型模型
- 手把手教你基於華為雲,實現MindSpore模型訓練模型
- 微信基於PyTorch的大規模推薦系統訓練實踐PyTorch
- 飛槳PaddlePaddle單機訓練速度最佳化最佳實踐
- 【ICDE 2022】稀疏模型訓練框架HybridBackend,單位成本下訓練吞吐提升至5倍模型框架
- 8個雲成本最佳化的最佳實踐
- Nebula 在 Akulaku 智慧風控的實踐:圖模型的訓練與部署模型
- 基於Theano的深度學習框架keras及配合SVM訓練模型深度學習框架Keras模型
- 低價策略幫助AI企業降低模型訓練成本AI模型
- 飛槳帶你瞭解:基於百科類資料訓練的 ELMo 中文預訓練模型模型
- Epoch AI:硬體佔訓練前沿AI模型成本的47-67%AI模型
- 基於Mindspore2.0的GPT2預訓練模型遷移教程GPT模型
- 基於LNMP的WordPress搭建與速度最佳化實踐LNMP
- PyTorch 模型訓練實⽤教程(程式碼訓練步驟講解)PyTorch模型
- 雲端開爐,線上訓練,Bert-vits2-v2.2雲端線上訓練和推理實踐(基於GoogleColab)Go
- 大眾點評資訊流基於文字生成的創意最佳化實踐
- 課程報名 | 基於模型訓練平臺快速打造 AI 能力模型AI
- 騰訊註冊中心演進及效能最佳化實踐
- 基於pytorch實現Resnet對本地資料集的訓練PyTorch
- 案例 | 騰訊廣告 AMS 的容器化之路
- 李飛飛團隊年度報告揭底大模型訓練成本:Gemini Ultra是GPT-4的2.5倍大模型GPT
- 新型大語言模型的預訓練與後訓練正規化,蘋果的AFM基礎語言模型模型蘋果
- 騰訊廣告&CDC:2019騰訊00後研究報告(附下載)
- 基於jQuery及騰訊NLP AI平臺的Laravel多語言站點實踐jQueryAILaravel
- Oneflow 基於重計算的動態圖視訊記憶體最佳化實踐記憶體
- 4分鐘訓練ImageNet!騰訊機智創造AI訓練世界紀錄AI
- 人工智慧的預訓練基礎模型的分類人工智慧模型
- TensorFlow 呼叫預訓練好的模型—— Python 實現模型Python
- 輕量化模型訓練加速的思考(Pytorch實現)模型PyTorch
- Android接入騰訊廣告平臺廣點通Android
- 自訓練 + 預訓練 = 更好的自然語言理解模型模型