一文詳解BI平臺——火山引擎DataWind架構和實踐
導讀:DataWind 是火山引擎數智平臺VeDI旗下的一站式資料分析與協作平臺,主要有三個使用場景:第一,資料探索與分析;第二,資料協作與整合;第三, AI 能力融合。
DataWind覆蓋的人群非常廣泛,幾乎支援位元組跳動內部所有業務線,覆蓋絕大多數員工使用需求,每天執行20萬張以上活躍的儀表盤,支援超過500萬次巨大資料量的查詢,每天有超過5萬人在使用 DataWind。
01 DataWind 在位元組跳動的使用場景

DataWind 主要有三個使用場景:
第一,資料探索與分析。使用者可以透過視覺化查詢,進行資料分析和製作儀表盤。在巨大資料量下,DataWind 可以實現秒級查詢結果返回,因此使用者更習慣用明細表去做資料分析。
第二,資料協作與整合。使用者可以在別的工具或平臺上與 DataWind 互動。例如,使用者可以把關心的儀表盤推送到自己的郵箱或者辦公軟體上,或者在某些指標出現異常或者劇烈波動的時候,透過飛書或者郵件進行通知。除此之外,有一些業務方的資料分析場景是相對定製化的,業務方也會透過 DataWind 比較強的開放能力去整合,透過一系列的開放介面去實現定製化訴求。
第三,AI 能力融合。近兩年,位元組跳動內部對 AI 能力的訴求越來越強,越來越多的使用者希望透過 AI 的能力,讓資料分析變得更加智慧。一種訴求是希望藉助機器學習的方法,對資料進行分析和預測;另外一種則是希望這個平臺能夠幫使用者找到值得關注的指標維度,實現更智慧的資料洞察。
02 DataWind發展歷程

DataWind 是一個相對年輕的產品。
第一個版本誕生於2018 年,那時它還是一個簡單的 SQL 查詢工具,使用者透過寫 Query 提交去查詢結果,但等待時間相對比較久。後來逐步擴充了視覺化查詢的能力,讓越來越多沒有技術背景的人透過拖拉拽的方式,去上手資料分析和儀表盤製作。
資料分析本身是離不開資料的。有一個常見的場景,想要分析的資料在數倉還沒有,或者已有的不是你想要的,這對一個沒有技術背景的使用者來說,做資料分析的過程可能就會被卡住。所以,我們又構建了一系列的資料準備能力,以零程式碼低門檻的方式幫助沒有技術背景的業務人員輕鬆完成 ETL。
為了適應不同場景的資料展示訴求,我們引入了完善的移動端駕駛艙大屏能力。在 2021年左右,為了更方便的被第三方系統整合,DataWind開放平臺正式構建。
03 DataWind產品能力
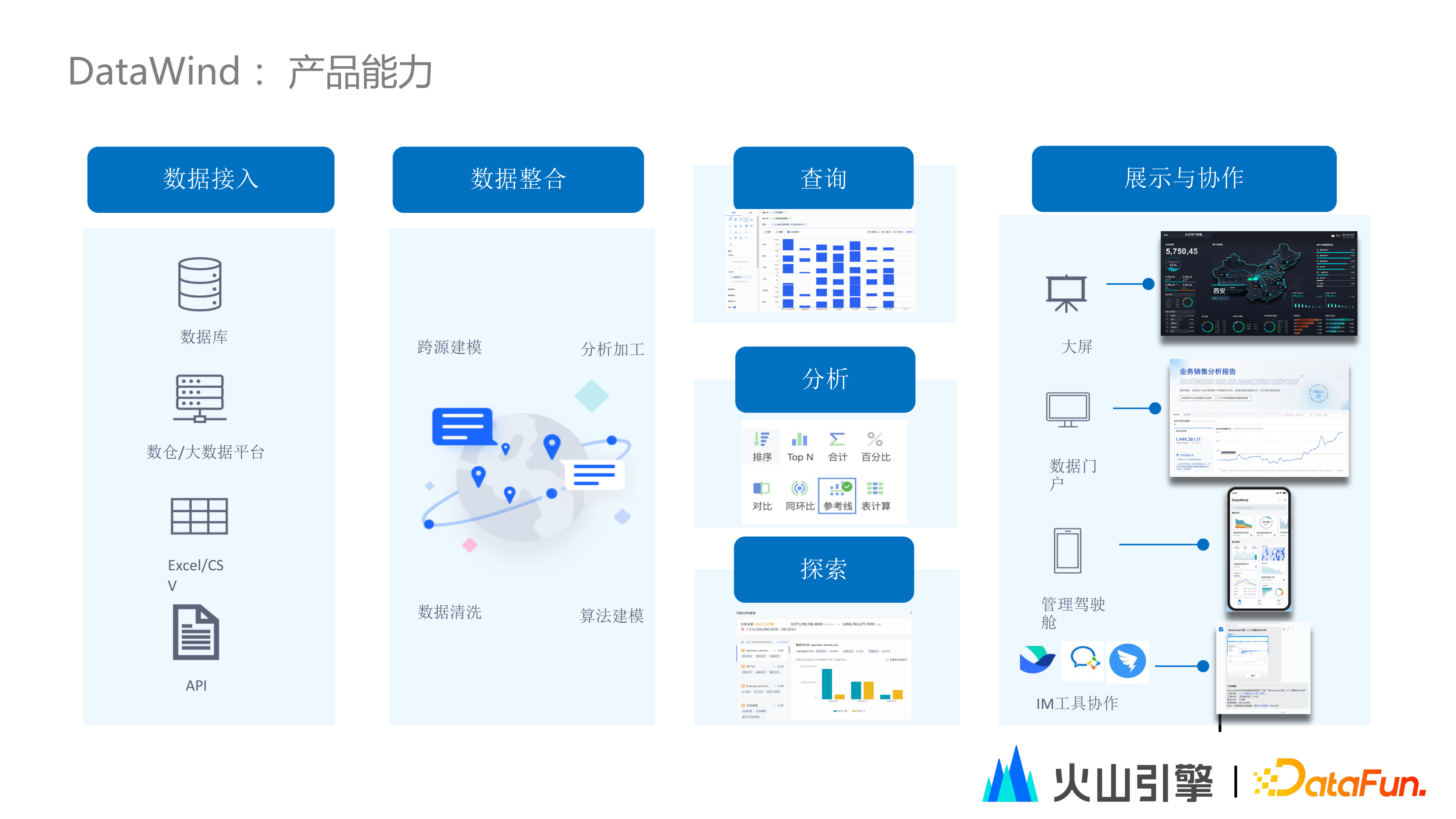
目前,DataWind 平臺基本上已具備了一站式的資料服務和分析能力,包含資料接入、資料整合、資料整合、查詢、分析、探索、協作等一系列功能。
04 DataWind 與火山引擎

瞭解火山引擎的朋友可能都知道,火山引擎包含了很多資料產品,也不乏資料分析類的產品,那麼 DataWind 跟其它產品的區別和聯絡是什麼呢?
從產品定位來講,特定領域的分析產品都會有一些場景相對固定的深入的資料分析和展示方法,如 AB測試中的顯著性、使用者行為分析的留存分析、某個使用者的行為重放等等。DataWind則是更關注通用場景下的資料分析訴求的滿足情況。
另外,DataWind能夠打通企業內部絕大多數的資料資產,與火山引擎的其它資料產品保持緊密聯動,如分析型資料庫 ByteHouse、湖倉一體分析服務LAS 等,也可以跟 VeCDP、DataFinder 等產品的資料直接打通實現資料查詢。透過打通各類資料,使用者可以很便捷地把使用者行為資料和數倉其他資料融合在一起,用DataWind進行分析。
05 資料洞察

DataWind之所以力求對常用的分析場景、分析方法和資料資產做到全覆蓋,是因為資料分析過程本來就是一個靈活、啟發式的探索過程,這與做問題排查非常類似。
分析原因之前,要設定多個假設。驗證一個假設後,會排除一些可能性,又會產生新的想法。在這個過程中,問題的領域有可能發生變化,如營收資料異常、或重新分析使用者行為資料、檢視監控資料、發現使用者留存或者使用者行為有異常等。
在啟發式的探索過程中,快速響應非常重要的。如果不能做到快速響應,驗證其中某種假設將耗費很長時間,等結果出來時可能已經忘了之前的分析思路。因此,理想情況是有一個強大的資料分析系統,只要問問題,就能快速準確地產出結果。
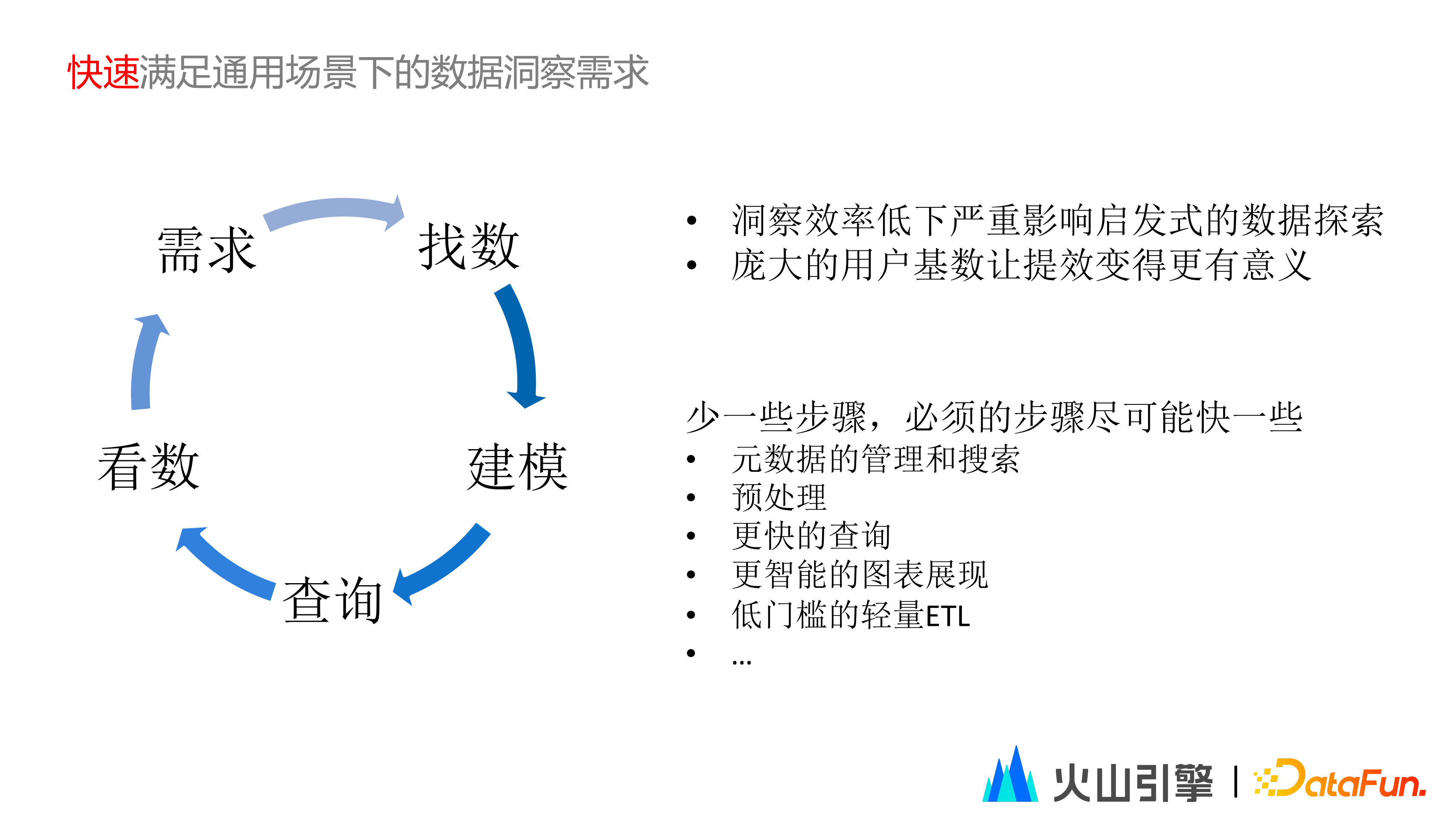
要達到快速響應,背後需要很多工作。
要知道到哪裡能找到相應的資料,這些資料要如何組合起來,基於這些資料,要構建出什麼樣的資料模型來做查詢,去分析結果。分析完結果以後,又可能會產生新的問題,這個鏈路很容易變得非常耗時,甚至有時候在一個團隊內都很難去做到閉環,影響整個資料洞察的效率。
考慮到 DataWind 在位元組內部有眾多使用者,對整個公司的效率影響非常明顯,這條鏈路需要變得更快、更簡單。思路其實也很明確,就是要省掉一些不必要去做的事情,同時讓必須要做的步驟更快地完成。按照這個思路,有很大的最佳化空間,比如把後設資料的管理、指標維度體系做好,最佳化後設資料的搜尋、排序和推薦。
當使用者有一個新想法時,可能發現已經有人做好了相應的圖表和儀表盤,就可以直接查或者申請一下許可權。又或是相應的儀表盤雖然沒有,但是相應資料的底表在數倉裡已經有了,可以直接去查詢。
這些都能夠讓鏈路變得更快。
大多數的場景下,查詢是不能省略的,所以提升查詢效能非常重要,尤其是在巨大資料量上實現更快的查詢,其重要性更為突出。這方面如果不能得到改善,通常來講,就只能做兩種選擇,一是減少資料量,或者去做一些預聚合,但問題是在啟發式的資料探索過程中,會不斷產生新問題,很容易發現維度、指標或力度不滿足需求,又需要去跑資料;二是用大資料量的細粒度資料去查,需要使用者等待時間較長。所以,近年來,DataWind 一直在想方設法地提升查詢效能。
06 使用者特徵
1. 海量資料的明細查詢

提高查詢效能後,位元組跳動的使用者更加喜歡用明細表來做資料分析,內部一週內被查到的資料量,基本上維持在400PB以上。每天會有 500 萬次以上的查詢,查詢資料量過億甚至過10億行的這種查詢是司空見慣的,基本上查詢都可以在 10 秒內完成。
保持這樣的水準其實是比較困難的,因為內部業務在快速的發展,分析需求也在快速增長,表規模也變得越來越大。在過去半年,查詢量增長了 50% 以上。在不久之前,像抖音等業務方的查詢資料量在 10 億行左右,而現在很多資料分析已經是基於千億行的規模。
在硬體資源基本不增加的情況下,可能很努力的把大查詢從30秒左右提升到了10秒,甚至5秒內,使用者覺得體驗變好了,又會上更大規模的資料。這也促使DataWind不斷地去提升查詢效能,關注的指標是 10 秒內的查詢佔比,內部認為在這個時間量級內完成響應,通常不會阻礙啟發式的資料分析和探索的過程。

為了實現在大資料量下快速返回查詢結果,DataWind在很多方向上做了努力。
首先,在硬體與引擎方面,收益是非常可觀的。更高的機器與網路配置,加上在大資料量查詢上面更有優勢的引擎,往往已經能夠帶來非常明顯的體驗提升。火山引擎的 Bytehouse 是我們目前使用最頻繁的引擎,其效能比開源版本 Clickhouse 更加突出,也會拿Datawind的查詢場景去做最佳化,為整體的查詢性提供基本的保障。
其次,在應用層面,我們也會做各種各樣的最佳化嘗試,比如儘量減少需要掃描的資料量,減少不必要的消費。我們儘可能的讓資料的儲存方式,更匹配其查詢方式,因為 DataWind 本身就是在通用場景下的資料分析平臺,要做到這一點是有一定難度的,根據使用者的查詢方式,去重新調整資料的分割槽分片方式,以及索引等,就會有明顯的提升。
此外,還有一些常用的場景,如 join或者是在BI領域使用得很頻繁的計數去重。對這些頻繁使用,但是效能往往比較差的場景, DataWind做了特定的最佳化,能很顯著地改善使用者體驗。
最後,就是不同的引擎對資源的需求也是不一樣的。比如說, Bytehouse有兩個版本,其中 CE 版可以提供比較好的效能,但儲存計算不分離,成本相對較高。CDW 雲數倉版的效能沒有 CE 版那麼卓越,但是它是存算分離的結構。我們內部也會根據使用者的資料量、對查詢響應的預期,去做資料儲存上面的分解,把硬體資源劃分成規模不同的叢集。根據資料的規模,還有查詢的方式,去選擇最適合的引擎和叢集。
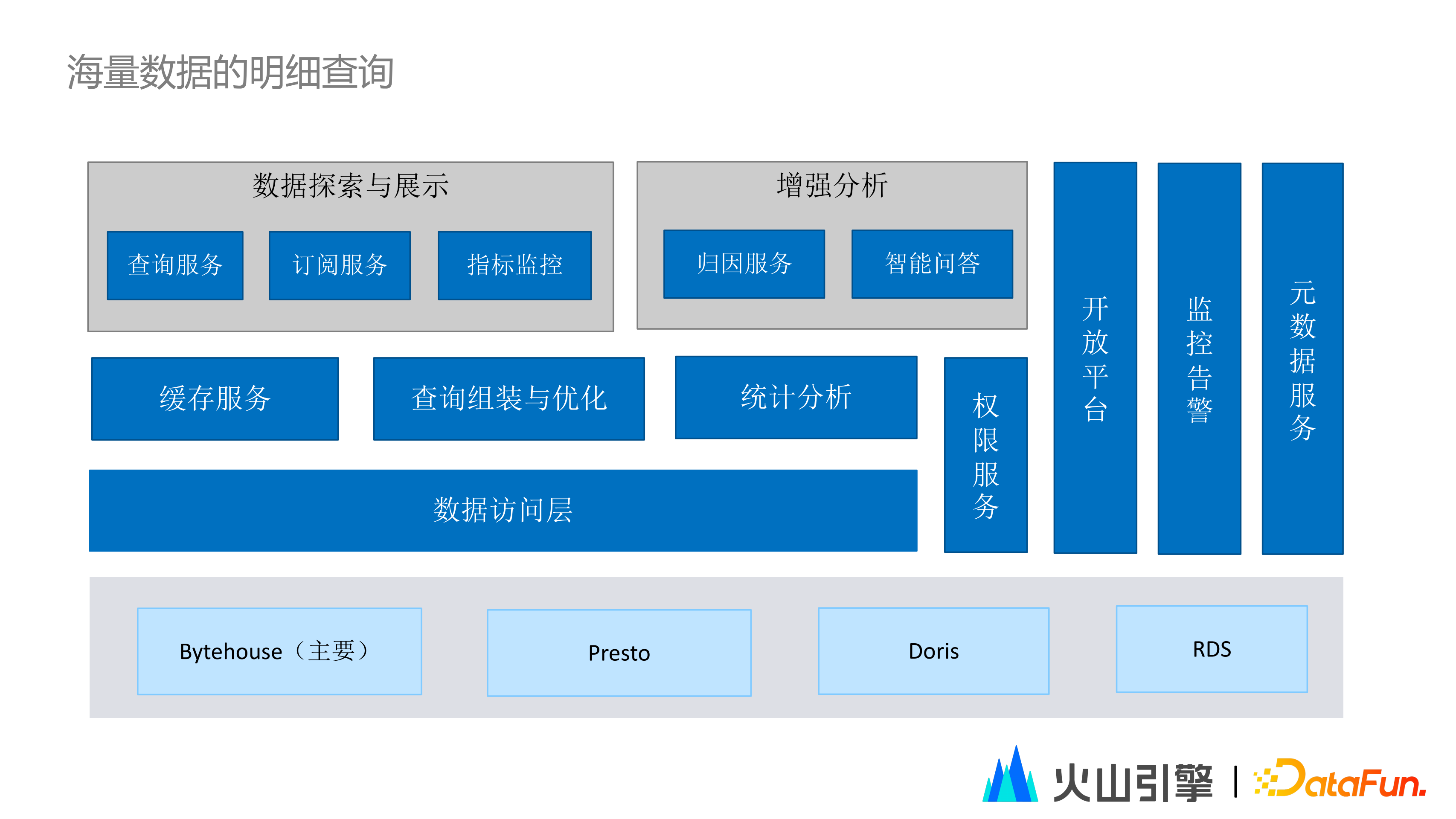
上述內容也體現在了架構中,底層有一些不同的引擎,每種引擎都由火山引擎的團隊針對場景做最佳化。資料訪問層遮蔽了這些對引擎訪問方式的差異。對一些重要程度比較高的儀表盤,DataWind會做預刷的處理和快取。對查詢的統計分析,我們希望DataWind能夠影響資料的儲存方式,進而去影響查詢的組裝和最佳化,服務於不同場景的模組。
2. 非技術人員也想做資料建模
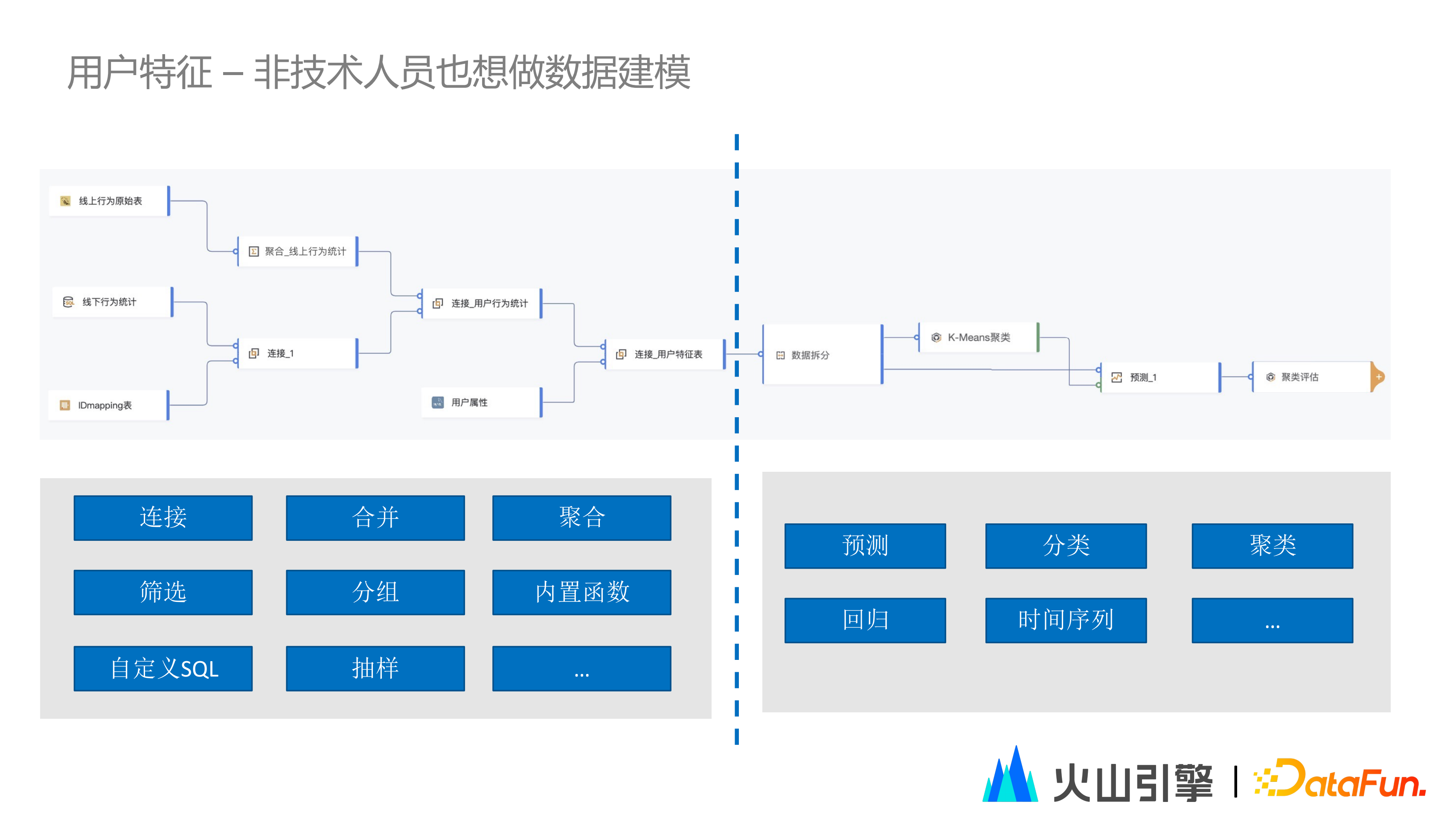
有些場景下,現有資料不能直接查詢,必須做一些處理,如篩選、連線、合併。或者在更復雜的場景下,可能需要把Mysql 的表跟 Hive 的表去做 join,這時就免不了要做一些資料模型構建。
DataWind的主要使用者大多都不具備技術背景,如果遇到資料上的卡點,往往無法獨立寫資料處理任務,再把這個任務排程起來,在實時的場景上可能就更為吃力,這樣就會影響整體效率。
因此能夠做資料建模工作,是 DataWind 使用者一個非常迫切的需求。透過打磨,DataWind滿足了這部分的需求——透過視覺化的方式構建資料模型。隨著模型的構建,還能夠探查到到每一步資料的具體內容,真正做到了所見即所得。
DataWind在資料建模的能力上也是比較完備的,能夠從超過40種資料來源中抽取資料,有豐富的運算元,甚至包含很多機器學習相關的運算元,可以完成非常複雜的模型構建工作。

與查詢場景類似,視覺化建模也是為了滿足通用場景設計,而增加了複雜度。使用者的使用場景、資料來源,包括資料本身的大小、構建出來的資料模型,會不會存在資料傾斜或者資料膨脹這種情況,其實都是未知的。
資源和人力都有限的情況下,我們要求整套系統具備比較好的穩定性和效能,能夠儘量做到無人值守。使用者本身沒有太多的技術背景,往往不具備大資料開發領域的知識,比如引數怎麼去調、為什麼報錯……這些都要求DataWind的平臺做得更加智慧、簡單和友好。
從結果來看,DataWind還是做得比較成功的,這個不用寫程式碼,門檻相當低的資料建模,在位元組跳動內部也被廣泛使用,任務量和資料規模也非常大。走商業化路線後,使用的客戶不僅多,還給了非常正向的評價。
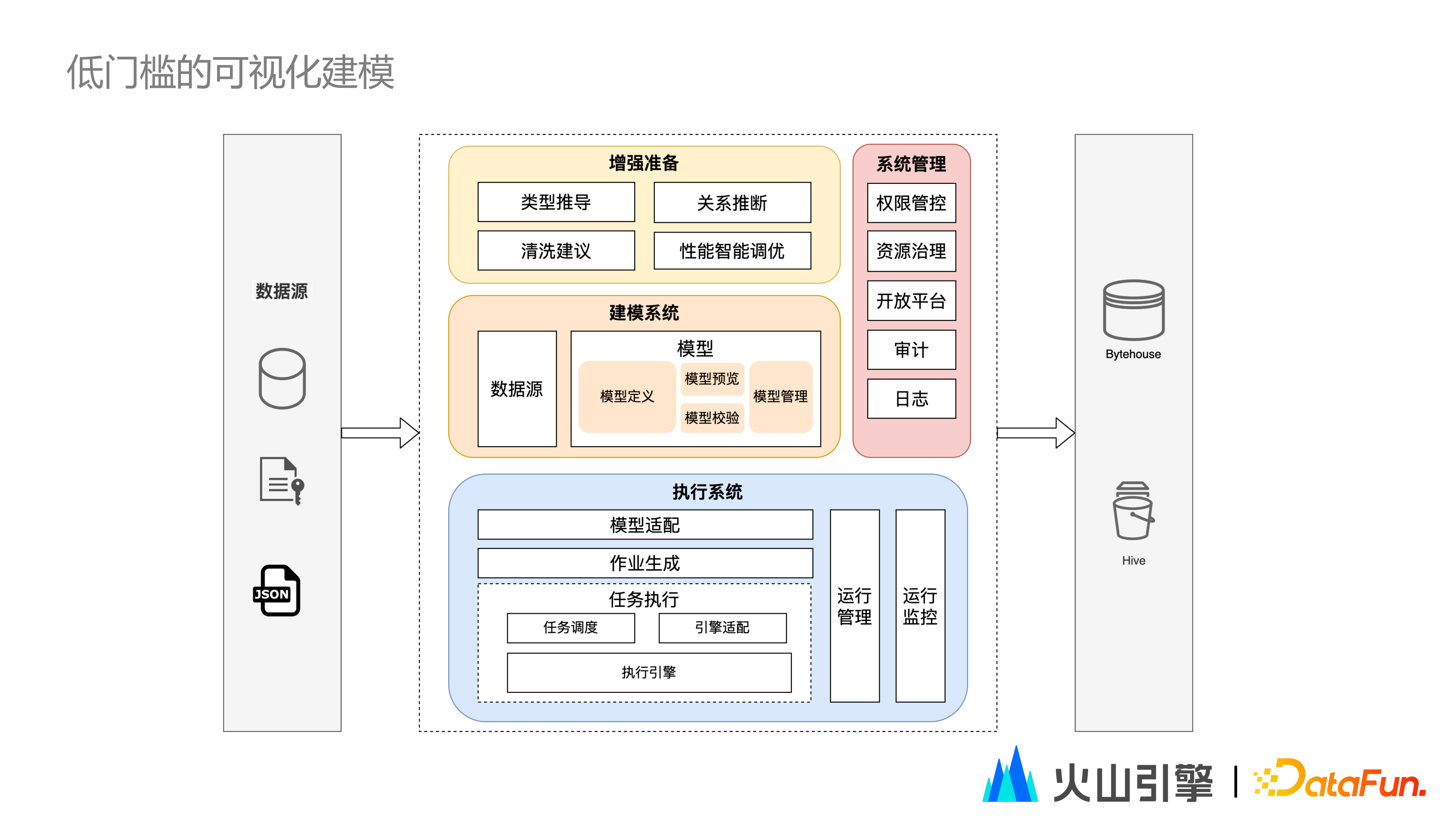
從架構上看,資料來源、執行系統、還有最終資料的儲存,其實跟一般的大資料開發平臺類似。DataWind值得強調的是執行管理和監控,為了讓內部還有客戶環境,都能夠儘可能的做到無人值守,DataWind會在任務執行當中加入一些檢測,比如資料是否發生了傾斜膨脹,再及時去調整任務的執行。
為了儘可能的讓門檻降低,DataWind會輔助使用者去做一些操作,比如說型別的推導,根據資料來源的某一個列的型別,以及後續的一些操作,去推斷其最終的型別,也會嘗試根據欄位型別、欄位名等,推斷幾張表之間是否存在關聯關係,讓使用者的操作步驟更加簡短,構建資料模型時更加方便。
3. 隨時隨地做資料分析

對移動端的支援,也是為了讓使用者能夠在更適合自己的場景下去完成資料分析和協作。使用者可以訂閱感興趣的儀表盤,或是關注某些指標移動情況,平臺還可以按照使用者的偏好,透過飛書、郵件等各類渠道推送給使用者。使用者也可以隨時隨地拿起手機來訪問 DataWind,主動的去做資料分析。DataWind也形成了移動端的管理駕駛艙,高層也可以頻繁地使用DataWind去關注他們感興趣的指標,做資料分析。
4. 複用意識碰上定製化需求

位元組跳動強調效率,內部團隊也有比較強的複用意識。大家在使用過程當中會遇到DataWind 無法滿足的特殊場景。
從 DataWind 團隊的視角來講,明顯帶有定製化色彩的需求,如果沒法支援,就意味著公司業務方要花比較大的代價實現平臺已經支援的功能,做平臺類產品的同學可能都會有這樣的困擾。
DataWind 透過打造自己的開放能力解決以上訴求,如提供白標能力、主題配色能力等。甚至對於一些深度整合場景,為整合方提供了一系列的控制點位,允許整合方做深入定製化,如許可權控制、查詢控制,甚至篩選條件控制。
目前,內部已經有眾多業務方用以上方法複用 DataWind。在商業化過程中,客戶也會基於以上開放能力完成二次開發。
07 DataWind 架構回顧
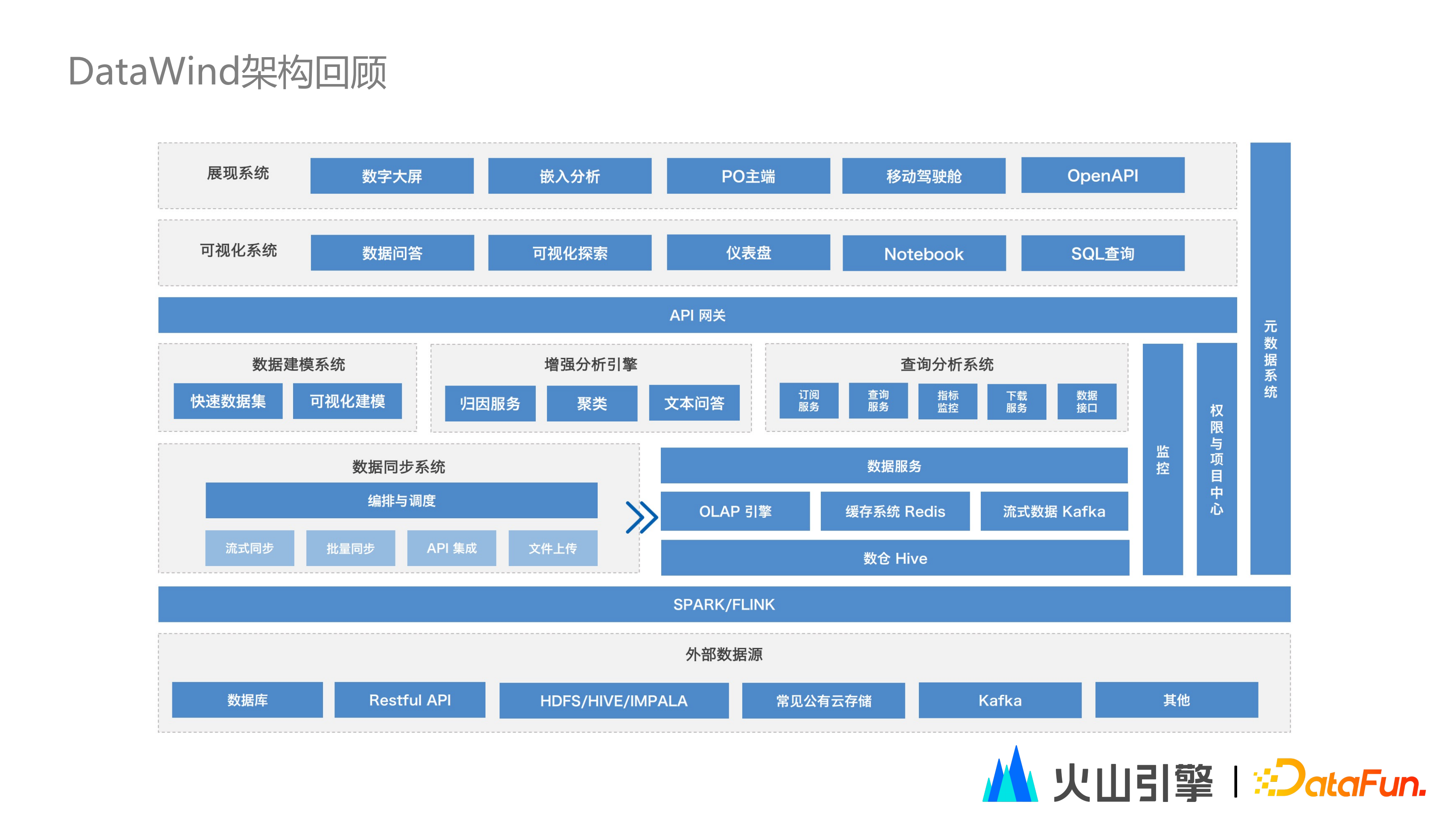
最後,上圖為 DataWind 整體架構。前文提到的大多數內容在這裡都有所體現,包括零程式碼、低門檻的視覺化建模,以及支撐海量資料快速查詢的關鍵元件。
基於產品定位、目標以及技術架構, DataWind 已經有效提升了位元組跳動內部分析效率,並且透過火山引擎數智平臺VeD對外輸出。未來,我們也會繼續從讓資料分析更快、更簡單的角度,進一步最佳化 DataWind。
來自 “ DataFunTalk ”, 原文作者:徐冰泉;原文連結:http://server.it168.com/a2023/0128/6787/000006787341.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 火山引擎A/B測試平臺的實驗管理重構與DDD實踐
- 火山引擎數智平臺:高效能ChatBI的技術解讀和落地實踐
- 網易考拉規則引擎平臺架構設計與實踐架構
- 火山引擎基於 Dragonfly 加速實踐Go
- DKHadoop大資料平臺架構詳解Hadoop大資料架構
- 火山引擎雲原生儲存加速實踐
- 美圖大資料平臺架構實踐大資料架構
- 一文詳解微服務架構微服務架構
- 王雨舟:知乎大資料平臺架構和實踐優化大資料架構優化
- 美團容器平臺架構及容器技術實踐架構
- 螞蟻區塊鏈BaaS平臺架構與實踐區塊鏈架構
- 攜程實時計算平臺架構與實踐丨DataPipeline架構API
- 汽車之家10年系統架構演進與平臺化架構實踐架構
- 微服務架構的4大設計原則和一個平臺實踐微服務架構
- 事件驅動架構在 vivo 內容平臺的實踐事件架構
- 網易數帆雲原生日誌平臺架構實踐架構
- 一文讀懂微服務架構——【詳解】微服務架構
- 餘利華:網易大資料平臺架構實踐分享!大資料架構
- 火山引擎DataLeap資料血緣技術建設實踐
- JuiceFS 在火山引擎邊緣計算的應用實踐UI
- 華為快應用引擎技術架構詳解架構
- 火山引擎 DataTester:讓企業“無程式碼”也能用起來的 A/B 實驗平臺
- 差分隱私技術在火山引擎的應用實踐
- 火山引擎雲原生大資料在金融行業的實踐大資料行業
- 一文詳解新一代OceanBase雲平臺
- 青團社:億級靈活用工平臺的雲原生架構實踐架構
- 騰訊音樂內容庫資料平臺架構演進實踐架構
- JUST京東城市時空資料引擎2.0架構實踐架構
- 實踐400+私有云打造的雲安全高可用架構詳解架構
- 一文詳解微服務架構的資料設計微服務架構
- 從零入門 Serverless | 一文詳解 Serverless 架構模式Server架構模式
- 火山引擎 DataLeap:揭秘位元組跳動資料血緣架構演進之路架構
- SaaS架構:開放平臺架構設計架構
- Jenkins架構詳解Jenkins架構
- CQRS架構和Axon框架入門實踐架構框架
- 「技術層面」詳解供應鏈管理平臺主流技術架構方案架構
- 一文全面瞭解火山語音無監督預訓練技術的落地實踐
- 滴滴七層接入平臺實踐和探索