乾貨 | 攜程酒店實時數倉架構和案例
一、實時數倉
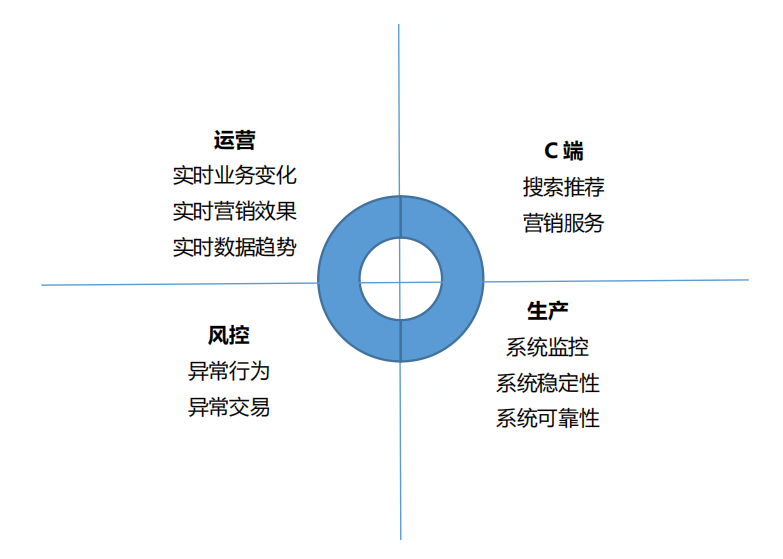
當前,企業對於資料實時性的需求越來越迫切,因此需要實時數倉來滿足這些需求。傳統的離線數倉的資料時效性通常為 T+1,並且排程頻率以天為單位,無法支援實時場景的資料需求。即使將排程頻率設定為每小時,也僅能解決部分時效性要求較低的場景,對於時效性要求較高的場景仍然無法優雅地支撐。因此,實時資料使用的問題必須得到有效解決。實時數倉主要用於解決傳統數倉資料時效性較低的問題,通常會用於實時的 OLAP 分析、實時資料看板、業務指標實時監控等場景。
二、實時數倉架構介紹
2.1 Lambda架構
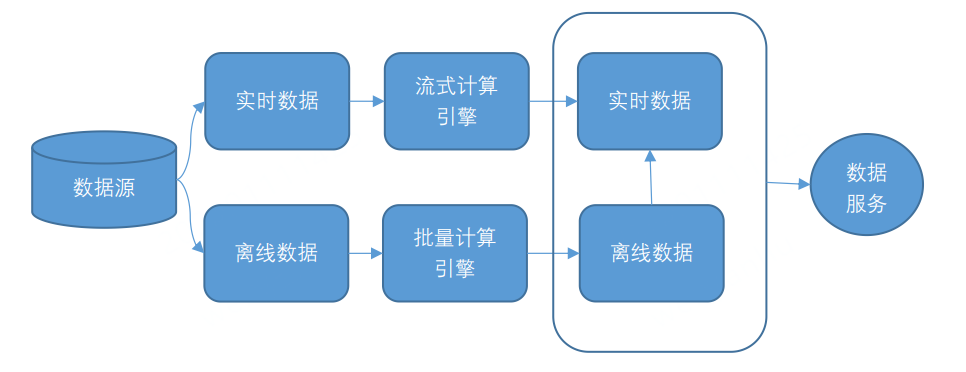
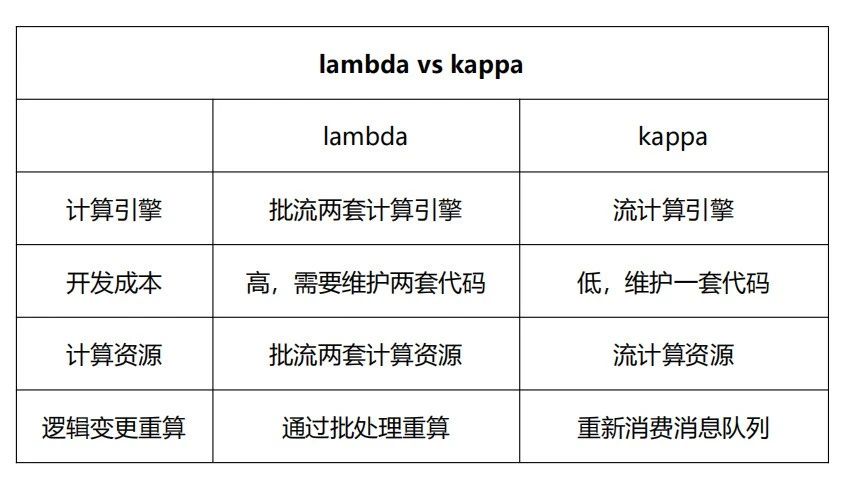
Lambda 架構將資料分為實時資料和離線資料,並分別使用流式計算引擎(例如 Storm、Flink 或者 SparkStreaming)和批次計算引擎(例如 Hive、Spark)對資料進行計算。然後,將計算結果儲存在不同的儲存引擎上,並對外提供資料服務。
2.2 Kappa架構
Kappa 架構將所有資料來源的資料轉換為流式資料,並將計算統一到流式計算引擎上。相比 Lambda 架構,Kappa 架構省去了離線資料流程,使得流程變得更加簡單。Kappa 架構之所以流行,主要是因為 Kafka 不僅可以作為訊息佇列使用,還可以儲存更長時間的歷史資料,以替代 Lambda 架構中的批處理層資料倉儲。流處理引擎以更早的時間作為起點開始消費,起到了批處理的作用。

三、攜程酒店實時數倉架構
3.1 方案選型
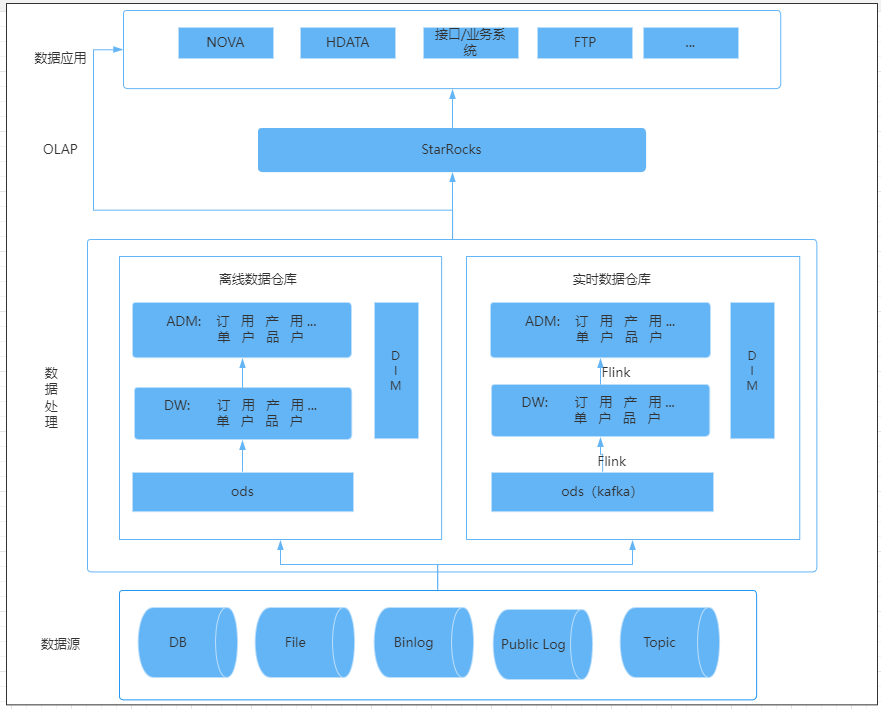
(1)架構選型:Lambda+OLAP 變體架構。Lambda 架構具有靈活性高、容錯性高、成熟度高和遷移成本低的優點,但是實時資料和離線資料需要分別使用兩套程式碼。OLAP 變體架構將實時計算中的聚合計算由 OLAP 引擎承擔,從而減輕實時計算部分的聚合處理壓力。這樣做的優點是既可以滿足資料分析師的實時自助分析需求,並且可以減輕計算引擎的處理壓力,同時也減少了相應的開發和維護成本。缺點是對OLAP 引擎的資料寫入效能和計算效能有更高的要求。
(2)實時計算引擎選型: Flink 具有 Exactly-once 的準確性、輕量級 Checkpoint 容錯機制、低延時高吞吐和易用性高的特點。SparkStreaming 更適合微批處理。我們選擇了使用 Flink。
(3)OLAP選型: 我們選擇 StarRocks 作為 OLAP 計算引擎。主要原因有3個:
StarRocks 是一種使用MPP分散式執行框架的資料庫,叢集查詢效能強大。
StarRocks 在高併發查詢和多表關聯等複雜多維分析場景中表現出色,併發能力強於 Clickhouse,而攜程酒店的業務場景需要 OLAP 資料庫支援每小時幾萬次的查詢量。
攜程酒店的業務場景眾多,StarRocks 提供了4種儲存模型,可以更好的應對各種業務場景。
四、實際案例—攜程酒店實時訂單
4.1 資料來源
Mysql Binlog,透過攜程自研平臺 Muise 接入生成 Kafka。
4.2 ETL資料處理
問題一: 如何保證訊息處理的有序性?
Muise 保證了 Binlog 訊息的有序性,我們這要討論的是 ETL 過程中如何保證訊息的有序性。舉個例子,比如說一個酒店訂單先在同一張表觸發了兩次更新操作,共計有了兩條 Binlog 訊息,訊息1和訊息2會先後進入流處理裡面,如果這兩個訊息是在不同的 Flink Task 上進行處理,那麼就有可能由於兩個併發處理的速度不一致,導致先發生的訊息處理較慢,後發生的訊息反而先處理完成,導致最終輸出的結果不對。
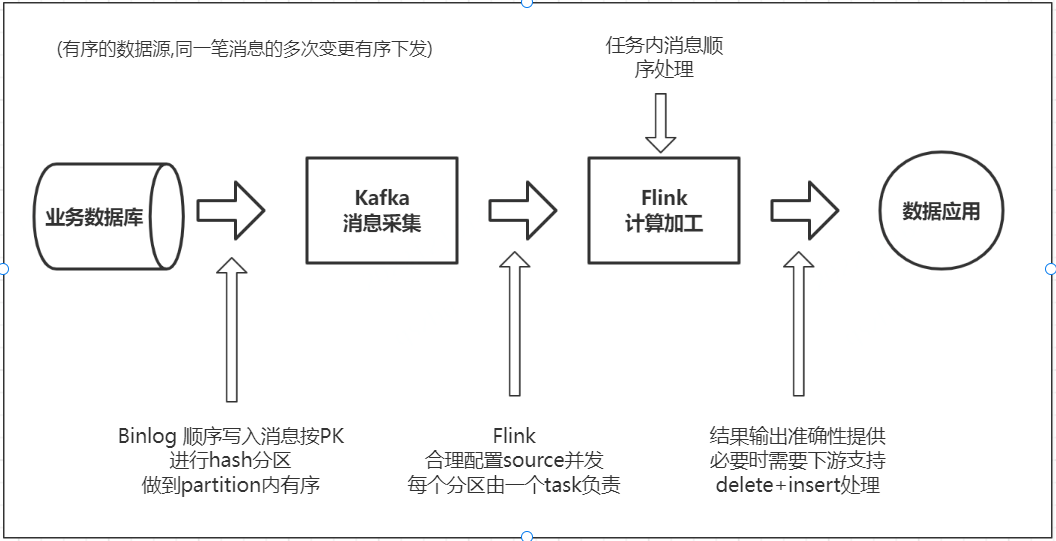
上圖是一個簡化的過程,業務庫流入到 Kafka,Binlog 日誌是順序寫入的,根據主鍵進行 Hash 分割槽,寫到 Kafka 裡面,保證同一個主鍵的資料寫入 Kafka 同一個分割槽存。Flink 消費 Kafka 時,需要設定合理的併發,保證一個分割槽的資料由一個 Task 負責,另外儘量採用邏輯主鍵來作為 Shuffle Key,從而保證 Flink 內部的有序性。最後在寫入 StarRocks 的時候,要按照主鍵進行更新或刪除操作,這樣就能保證端到端的一致性。
問題二:如何生產實時訂單寬表?
為了方便分析師和資料應用使用,我們需要生成明細訂單寬表並儲存在 StarRocks 上。酒店訂單涉及業務過程相對複雜,資料來源來自於多個資料流中。且由於酒店訂單變化生命週期較長,客人可能會提前幾個月甚至更久預訂下單。這些都給生產實時訂單寬錶帶來一定的困難。
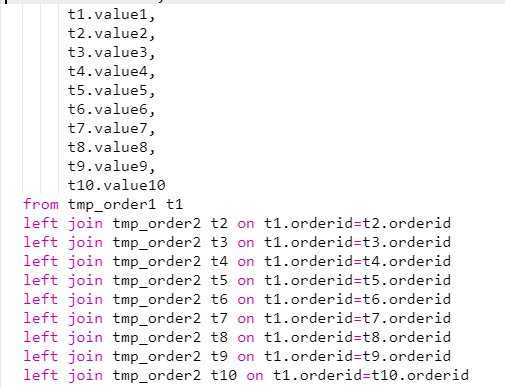
上圖中生成訂單寬表的 SQL 在離線批處理的時候通常沒有問題,但在實時處理的情景下就很難行的通。因為在實時處理時,這個 SQL 會按照雙流 Join 的方式依次處理,每次只能處理一個 Join,所以上面程式碼有9個 Join 節點,Join 節點會將左流的資料和右流的資料全部儲存下來,這樣就會導致我們這個 Join 的過程需要儲存的資料規模放大9倍。
我們採用了 Union all+Group by 的方式替代 Join;就是用 Union All 的方式,把資料錯位拼接到一起,後面加一層 Group By,相當於將 Join 關聯轉換成 Group By,這樣不會放大 Flink 的狀態儲存,而且在增加新的流時,相比 Join,狀態儲存的增加也可以忽略不計,新增資料來源的成本近乎為0。

還有一個問題,上面有介紹過酒店訂單的生命週期很長,用 union all 的方式,狀態週期只儲存了30分鐘, 一些訂單的狀態可能已經過期,當出現訂單狀態時,我們需要獲取訂單的歷史狀態,這樣就需要一箇中間層儲存歷史狀態資料來做補充。歷史資料我們選擇存放在 Redis 中,第一次選擇從離線資料匯入,實時更新資料同時更新 Redis 和 StarRocks。
問題三:如何做資料校驗?
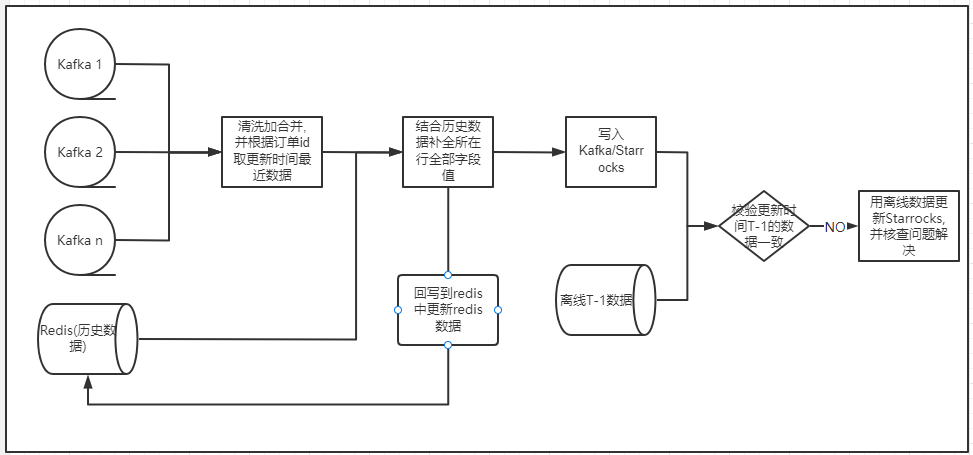
實時資料存在資料丟失或邏輯變更未及時的風險,為了保證資料的準確性,每日凌晨用資料更新時間在 T-1 和離線資料做比對,如果資料校驗不一致,會用離線資料更新 StarRocks 中這部分資料,並排查原因。
整體流程見下圖:
4.3 攜程酒店實時訂單表的應用效果
酒店實時訂單表的資料量為十億級,維表資料量有幾百萬,現已經在幾十個資料看板和監控報表中使用,資料包表通常有二三十個維度和十幾個資料指標,查詢耗時99%約為3秒。
4.4 總結
酒店實時資料具有量級大,生命週期長,業務流程多等複雜資料特徵,攜程酒店實時數倉選用 Lambda+OLAP 變體架構,再借助 Starrocks 強大的計算效能,不僅降低了實時數倉開發成本,同時達到了支援實時的多維度資料統計、分析、監控的效果,在實時庫存監控以及應對緊急突發事件等專案獲得了良好效果。
來自 “ 攜程技術 ”, 原文作者:秋石&九號&魁偉;原文連結:http://server.it168.com/a2023/0117/6786/000006786559.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 乾貨 | 攜程圖片服務架構架構
- 乾貨 | 攜程線上風控系統架構架構
- 實時數倉:Kappa架構APP架構
- 乾貨 | 攜程酒店排序推薦廣告高效可靠資料基座--填充引擎排序
- 乾貨 | 攜程酒店基於血緣後設資料的資料流程最佳化實踐
- 攜程實時計算平臺架構與實踐丨DataPipeline架構API
- 美團實時數倉架構演進與建設實踐架構
- 乾貨 | 每天十億級資料更新,秒出查詢結果,ClickHouse在攜程酒店的應用
- 乾貨分享丨攜程國際業務動態實時標籤處理平臺實踐
- 如何構建準實時數倉?
- Apache Flink X Apache Doris 構建極速易用的實時數倉架構Apache架構
- 乾貨:軟體架構詳解架構
- 乾貨 | 攜程日誌系統治理演進之路
- 【虹科乾貨】Lambda資料架構和Kappa資料架構——構建現代資料架構架構APP
- 亞馬遜雲科技潘超:雲原生無伺服器數倉最佳實踐與實時數倉架構亞馬遜伺服器架構
- 數倉架構發展史架構
- 乾貨篇:超多內容微服務架構實戰微服務架構
- 乾貨:軟體架構分析詳解架構
- 乾貨帖 | TDSQL-A核心架構揭秘SQL架構
- 乾貨 | 廣告系統架構解密架構解密
- Doris和Flink在實時數倉實踐
- Index R 時序數倉技術架構(待補充)Index架構
- 基於乾淨架構使用原始SQL和DDD實現.NET Core REST API開源案例架構SQLRESTAPI
- 實時數倉在滴滴的實踐和落地
- 雲棲乾貨回顧 | 更強大的實時數倉構建能力!分析型資料庫PostgreSQL 6.0新特性解讀資料庫SQL
- 數倉實踐:匯流排矩陣架構設計矩陣架構
- 實時數倉方案五花八門,實際落地如何選型和構建
- 乾貨:阿里大牛淺談MySQL架構體系阿里MySql架構
- GaussDB(DWS)基於Flink的實時數倉構建
- 基於Flink構建全場景實時數倉
- 乾貨分享:容器 PaaS 新技術架構下的運維實踐架構運維
- 乾貨 | 攜程一次Redis遷移容器後Slowlog“異常”分析Redis
- 乾貨 | 資料為王,攜程國際火車票的 ShardingSphere 之路
- 直播預約丨《實時湖倉實踐五講》第四講:實時湖倉架構與技術選型架構
- CCO x Hologres:實時數倉高可用架構再次升級,雙11大規模落地架構
- 直播預約丨《實時湖倉實踐五講》第二講:實時湖倉功能架構設計與落地實戰架構
- 阿里云云原生實時數倉升級釋出,助力企業快速構建一站式實時數倉阿里
- 基於SpringCloud的Microservices架構實戰案例-架構拆解SpringGCCloudROS架構