乾貨 | 攜程日誌系統治理演進之路
本文將從以下五部分切入,講述日誌系統的演進之路:攜程日誌的背景和現狀、如何搭建一套日誌系統、從 ElasticSearch 到 Clickhouse 儲存演進、日誌3.0重構及未來計劃。
一、日誌背景及現狀

圖1
2012年以前,攜程的各個部門日誌自行收集治理(如圖1)。這樣的方式缺乏統一標準,不便治理管控,也更加消耗人力和物力。
從2012年開始,攜程技術中心推出基於 ElasticSearch 的日誌系統,統一了日誌的接入、ETL、儲存和查詢標準。隨著業務量的增長,資料量膨脹到 4PB 級別,給原來的 ElasticSearch 儲存方案帶來不少挑戰,如 OOM、資料延遲及負載不均等。此外,隨著叢集規模的擴大,成本問題日趨敏感,如何節省成本也成為一個新的難題。
2020年初,我們提出用 Clickhouse 作為主要儲存引擎來替換 ElasticSearch 的方案,該方案極大地解決了 ElasticSearch 叢集遇到的效能問題,並且將成本節省為原來的48%。2021年底,日誌平臺已經累積了20+PB 的資料量,叢集也達到了數十個規模(如圖2)。
2022年開始,我們提出日誌統一戰略,將公司的 CLOG 及 UBT 業務統一到這套日誌系統,預期資料規模將達到 30+PB。同時,經過兩年多的大規模應用,日誌叢集累積了各種各樣的運維難題,如叢集數量激增、資料遷移不便及表變更異常等。因此,日誌3.0應運而生。該方案落地了類分庫分表設計、Clickhouse on Kubernetes、統一查詢治理層等,聚焦解決了架構和運維上的難題,並實現了攜程 CLOG 與 ESLOG 日誌平臺統一。
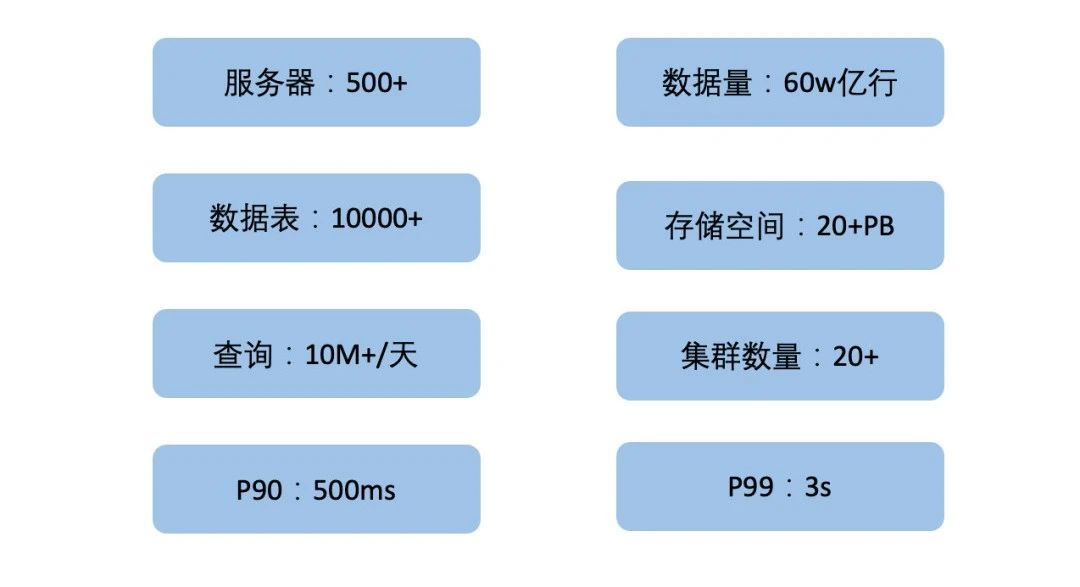
圖2
二、如何搭建日誌系統
2.1 架構圖
從架構圖來看(如圖3),整個日誌系統可以分為:資料接入、資料 ETL、資料儲存、資料查詢展示、後設資料管理系統和叢集管理系統。
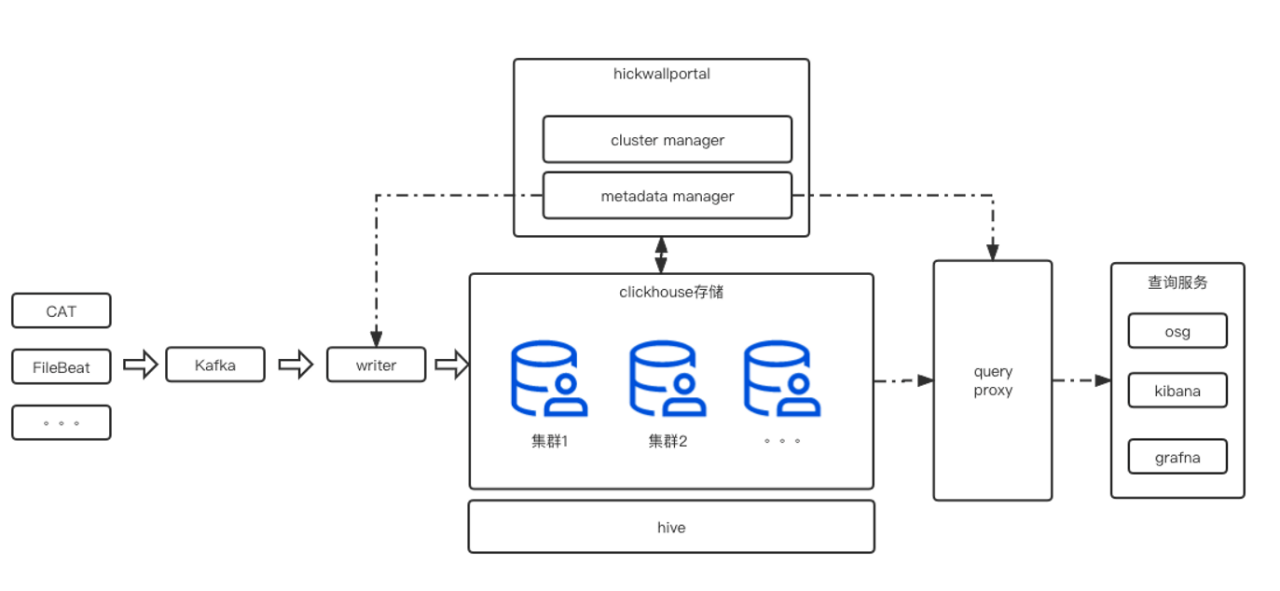
圖3
2.2 資料接入
資料接入主要有兩種方式:
第一種是使用公司框架 TripLog 接入到訊息中介軟體 Kafka(Hermes協議)(如圖4)。

圖4
第二種是使用者使用 Filebeat/Logagent/Logstash 或者寫程式自行上報資料到 Kafka(如圖5),再透過 GoHangout 寫入到儲存引擎中。
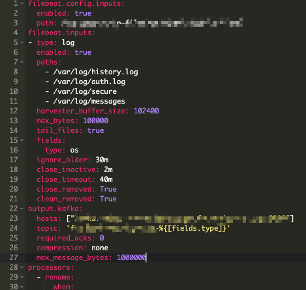
圖5
2.3 資料傳輸ETL(GoHangout)
GoHangout 是仿照 Logstash 做的一個開源應用(Github連結),用於把資料從 Kafka 消費並進行 ETL,最終輸出到不同的儲存介質(Clickhouse、ElasticSearch)。其中資料處理 Filter 模組包含了常見的 Json 處理、Grok 正則匹配和時間轉換等一系列的資料清理功能(如圖6)。GoHangout 會將資料 Message 欄位中的 num 資料用正則匹配的方式提取成單獨欄位。

圖6
2.4 ElasticSearch 資料儲存
早期2012年第一版,我們使用 ElasticSearch 作為儲存引擎。ElasticSearch 儲存主要由 Master Node、Coordinator Node、Data Node 組成(如圖7)。Master 節點主要負責建立或刪除索引,跟蹤哪些節點是叢集的一部分,並決定哪些分片分配給相關的節點;Coordinator 節點主要用於處理請求,負責路由請求到正確的節點,如建立索引的請求需要路由到 Master 節點;Data 節點主要用於儲存大量的索引資料,並進行增刪改查,一般對機器的配置要求比較高。
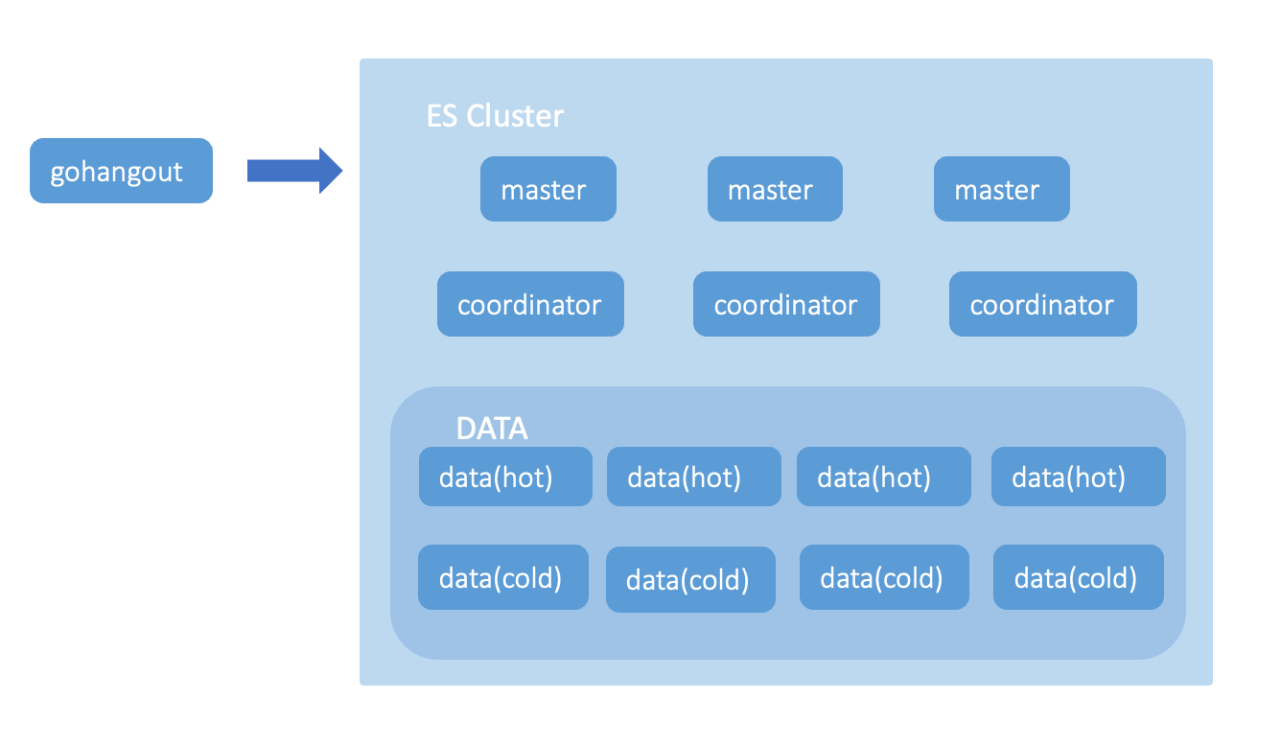
圖7
2.5 資料展示
資料展示方面我們使用了 Elastic Stack 家族的 Kibana(如圖8)。Kibana 是一款適合於 ElasticSearch 的資料視覺化和管理工具,提供實時的直方圖、線形圖、餅狀圖和表格等,極大地方便日誌資料的展示。

圖8
2.6 表後設資料管理平臺
表後設資料管理平臺是使用者接入日誌系統的入口,我們將每個 Index/ Table 都定義為一個Scenario(如圖9)。我們透過平臺配置並管理 Scenario 的一些基礎資訊,如:TTL、歸屬、許可權、ETL 規則和監控日誌等。
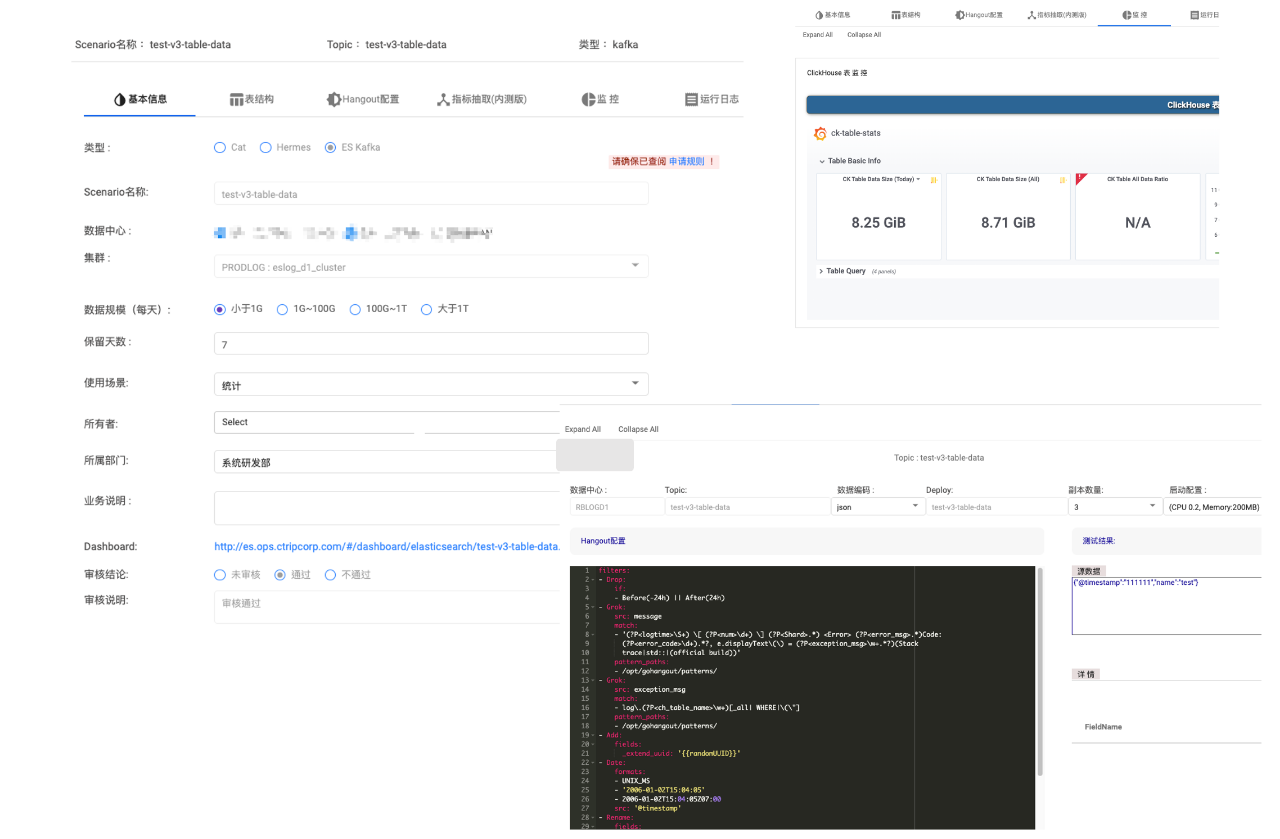
圖9
三、 從Elasticsearch到Clickhouse
我們將會從背景、Clickhouse 簡介、ElasticSearch 對比和解決方案四方面介紹日誌從 ElasticSearch 到 Clickhouse 的演進過程。2020年初,隨著業務量的增長,給 ElasticSearch 叢集帶來了不少難題,主要體現在穩定性、效能和成本三個方面。
(1)穩定性上:
ElasticSearch 叢集負載高,導致較多的請求 Reject、寫入延遲和慢查詢。
每天 200TB 的資料從熱節點搬遷到冷節點,也有不少的效能損耗。
節點間負載不均衡,部分節點單負載過高,影響叢集穩定性。
大查詢導致 ElasticSearch 節點 OOM。
(2)效能上:
ElasticSearch的吞吐量也達到瓶頸。
查詢速度受到整體叢集的負載影響。
(3)成本上:
倒排索引導致資料壓縮率不高。
大文字場景價效比低,無法儲存長時間資料。
3.1 Clickhouse 簡介與 Elasticsearch 對比
Clickhouse 是一個用於聯機分析(OLAP)的列式資料庫管理系統(DBMS)。Yandex 在2016年開源,使用 C++ 語法開發,是一款PB級別的互動式分析資料庫。包含了以下主要特效:列式儲存、Vector、Code Generation、分散式、DBMS、實時OLAP、高壓縮率、高吞吐、豐富的分析函式和 Shared Nothin g架構等。
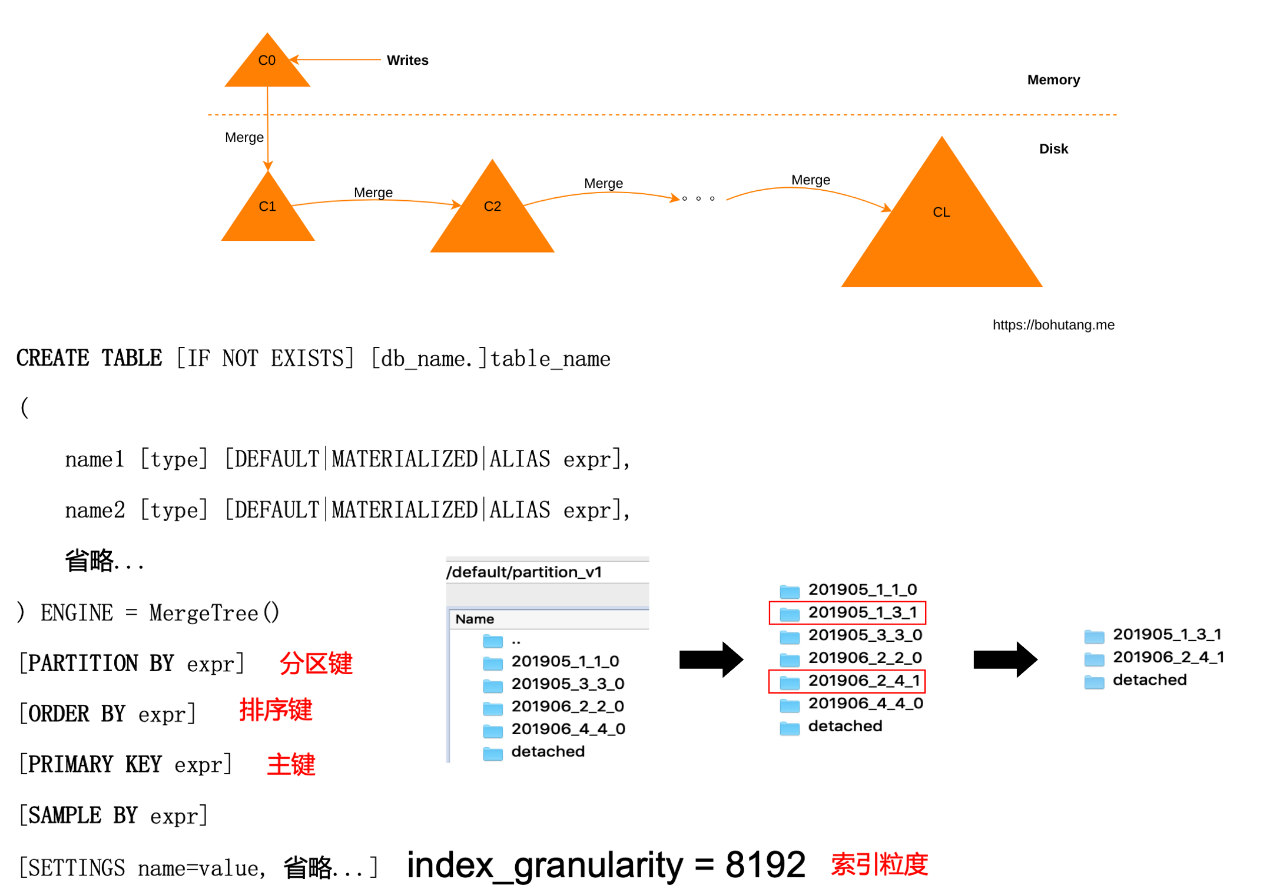
圖10
Clickhouse採用的是 SQL 的互動方式,非常方便上手。接下來,我們將簡單介紹一下 Clickhouse 的類 LSM、排序鍵、分割槽鍵特效,瞭解 Clickhouse 的主要原理。
首先,使用者每批寫入的資料會根據其排序鍵進行排序,並寫入一個新的資料夾(如201905_1_1_0),我們稱為 Part C0(如圖10)。隨後,Clickhouse 會定期在後臺將這些 Part 透過歸併排序的方式進行合併排序,使得最終資料生成一個個資料順序且空間佔用較大的 Part。這樣的方式從磁碟讀寫層面上看,能充分地把原先磁碟的隨機讀寫巧妙地轉化為順序讀寫,大大提升系統的吞吐量和查詢效率,同時列式儲存+順序資料的儲存方式也為資料壓縮率提供了便利。201905_1_1_0與201905_3_3_0合併為201905_1_3_1就是一個經典的例子。
另外,Clickhouse 會根據分割槽鍵(如按月分割槽)對資料進行按月分割槽。05、06月的資料被分為了不同的資料夾,方便快速索引和管理資料。
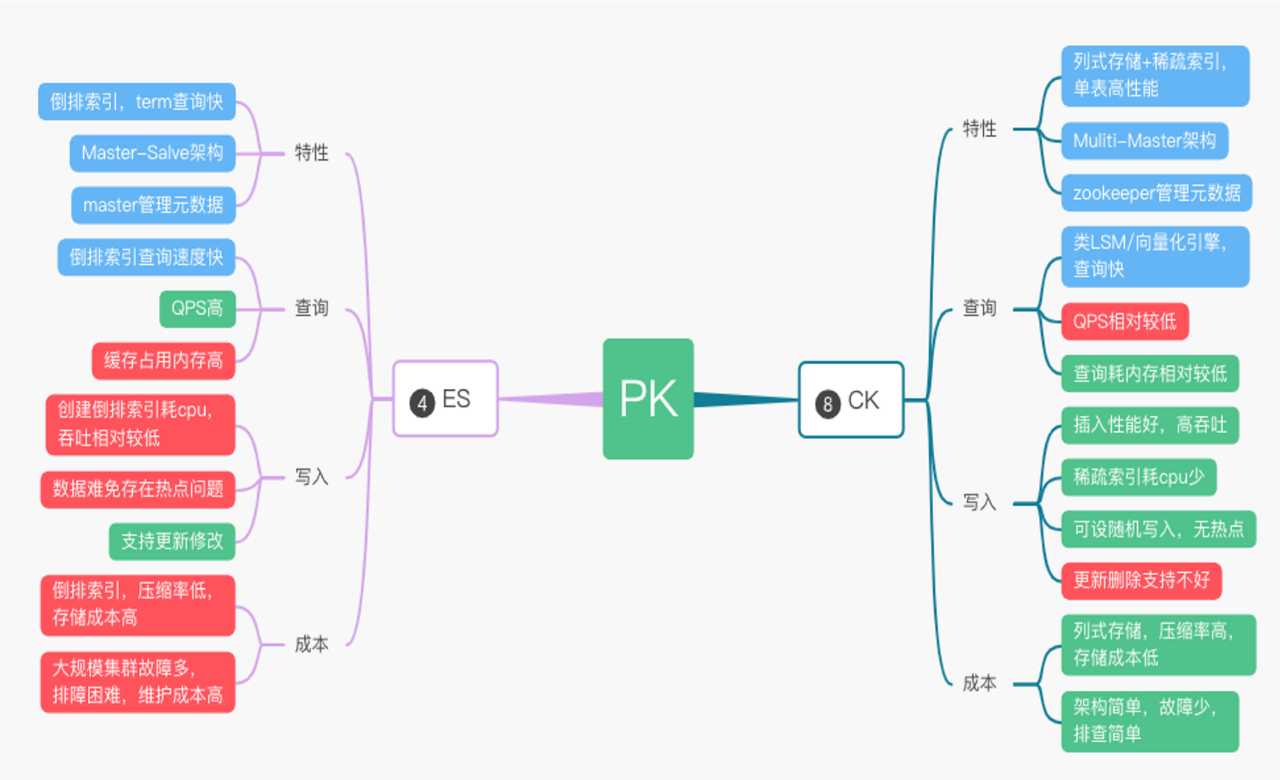
圖11
我們看中了 Clickhouse 的列式儲存、向量化、高壓縮率和高吞吐等特效(如圖11),很好地滿足了我們當下日誌叢集對效能穩定性和成本的訴求。於是,我們決定用Clickhouse來替代原本 ElasticSearch 儲存引擎的位置。
3.2 解決方案
有了儲存引擎後,我們需要實現對使用者無感知的儲存遷移。這主要涉及了以下的工作內容(如圖12):自動化建表、GoHangout 修改、Clickhouse 架構設計部署和 Kibana 改造。
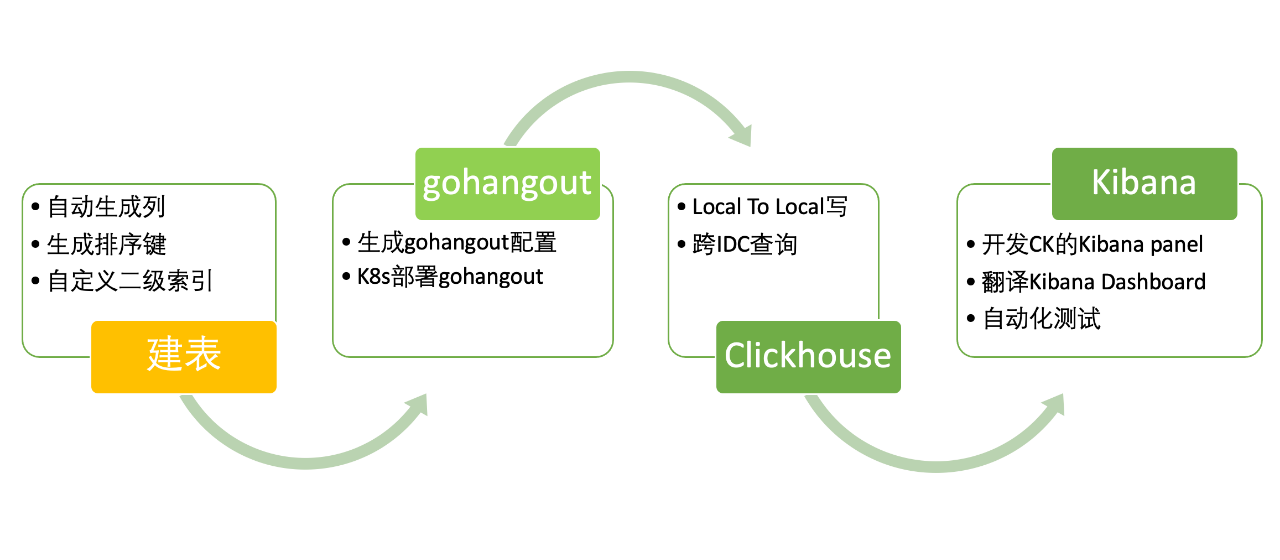
圖12
(1)庫表設計
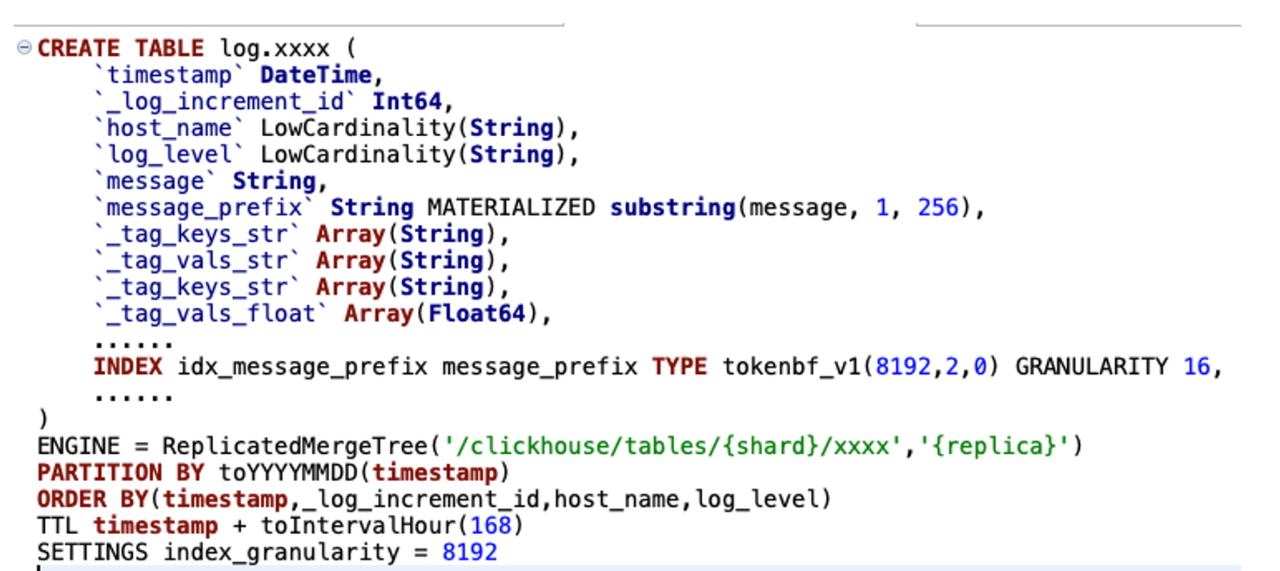
圖13
我們對ck在日誌場景落地做了很多細節的最佳化(如圖13),主要體現在庫表設計:
我們採用雙 list 的方式來儲存動態變化的 tags(當然最新的版本22.8,也可以用map和新特性的 json 方式)。
按天分割槽和時間排序,用於快速定位日誌資料。
Tokenbf_v1 布隆過濾用於最佳化 term 查詢、模糊查詢。
_log_increment_id 全域性唯一遞增 id,用於滾動翻頁和明細資料定位。
ZSTD 的資料壓縮方式,節省了40%以上的儲存成本。
(2)Clickhouse 儲存設計
Clickhouse 叢集主要由查詢叢集、多個資料叢集和 Zookeeper 叢集組成(如圖14)。查詢叢集由相互獨立的節點組成,節點不儲存資料是無狀態的。資料叢集則由Shard組成,每個 Shard 又涵蓋了多個副本 Replica。副本之間是主主的關係(不同於常見的主從關係),兩個副本都可以用於資料寫入,互相同步資料。而副本之間的後設資料一致性則有 Zookeeper 叢集負責管理。
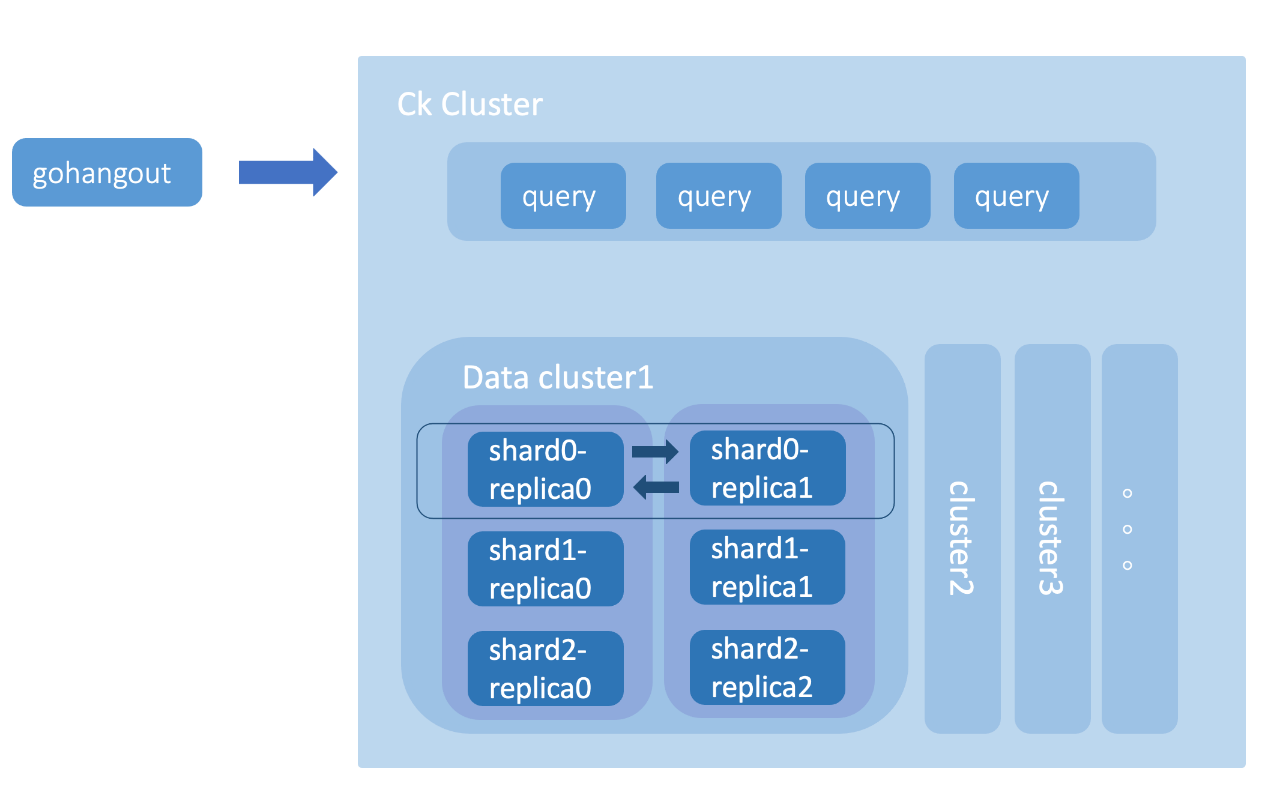
圖14
(3)資料展示
為了實現使用者無感知的儲存切換,我們專門實現了 Kibana 對 Clickhouse 資料來源的適配並開發了不同的資料 panel(如圖15),包括:chhistogram、chhits、chpercentiles、chranges、chstats、chtable、chterms 和 chuniq。透過 Dashboard 指令碼批次生產替代的方式,我們快速地實現了原先 ElasticSearch 的 Dashboard 的遷移,其自動化程度達到95%。同時,我們也支援了使用 Grafana 的方式直接配置 SQL 來生成日誌看板。
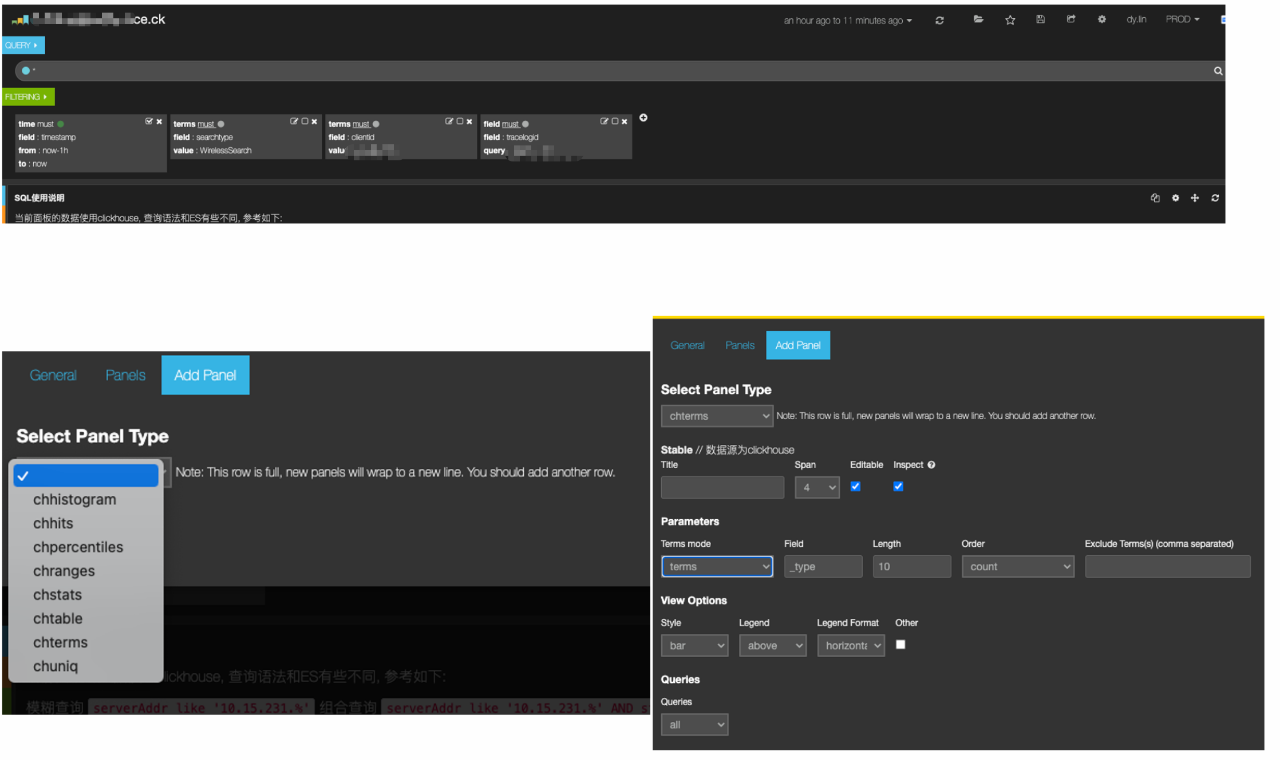


圖15
(4)叢集管理平臺
為了更好地管理 Clickhouse 叢集,我們也做了一整套介面化的 Clickhouse 運維管理平臺。該平臺覆蓋了日常的 shard 管理、節點生成、繫結/解綁、權重修改、DDL 管理和監控告警等治理工具(如圖16)。

圖16
3.3 成果
遷移過程自動化程度超過95%,基本實現對使用者透明。
儲存空間節約50+%(如圖17),用原有ElasticSearch的伺服器支撐了4倍業務量的增長。
查詢速度比ElasticSearch快4~30倍,查詢P90小於300ms,P99小於1.5s。
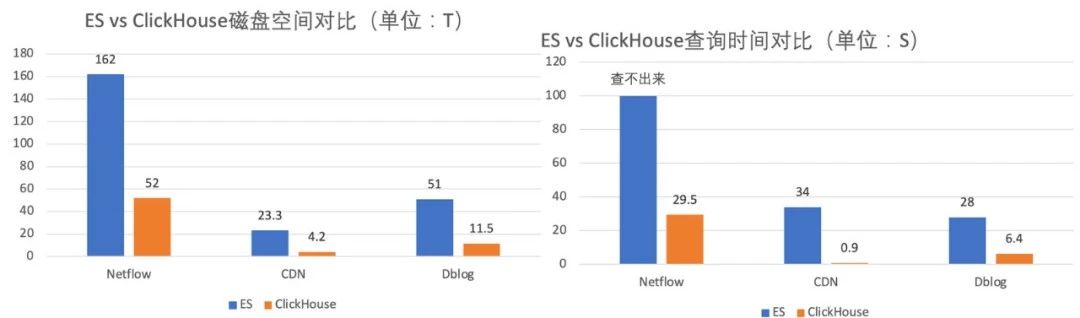
圖17
四、日誌3.0構建
時間來到2022年,公司日誌規模再進一步增加到 20+PB。同時,我們提出日誌統一戰略,將公司的 CLOG 及 UBT 業務統一到這套日誌系統,預期資料規模將達到 30+PB。另外,經過兩年多的大規模應用,日誌系統也面臨了各種各樣的運維難題。
(1) 效能與功能痛點
單叢集規模太大,Zookeeper 效能達到瓶頸,導致 DDL 超時異常。
當表資料規模較大時,刪除欄位,容易超時導致後設資料不一致。
使用者索引設定不佳導致查詢慢時,重建排序鍵需要刪除歷史資料,重新建表。
查詢層缺少限流、防呆和自動最佳化等功能,導致查詢不穩定。
(2) 運維痛點
表與叢集嚴格繫結,叢集磁碟滿後,只能透過雙寫遷移。
叢集搭建依賴 Ansible,部署週期長(數小時)。
Clickhouse 版本與社群版本脫節,目前叢集的部署模式不便版本更新。
面對這樣的難題,我們在2022年推出了日誌3.0改造,落地了叢集 Clickhouse on Kubernetes、類分庫分表設計和統一查詢治理層等方案,聚焦解決了架構和運維上的難題。最終,實現了統一攜程 CLOG 與 ESLOG 兩套日誌系統。
4.1 ck on k8s
我們使用 Statefulset、反親和、Configmap 等技術實現了 Clickhouse 和 Zookeeper 叢集的 Kubernetes 化部署,使得單叢集交付時間從2天最佳化到5分鐘。同時,我們統一了部署架構,將海內外多環境部署流程標準化。這種方式顯著地降低了運維成本並釋放人力。更便利的部署方式有益於單個大叢集的切割,我們將大叢集劃分為多個小叢集,解決了單叢集規模過大導致 Zookeeper 效能瓶頸的問題。
4.2 類分庫分表設計
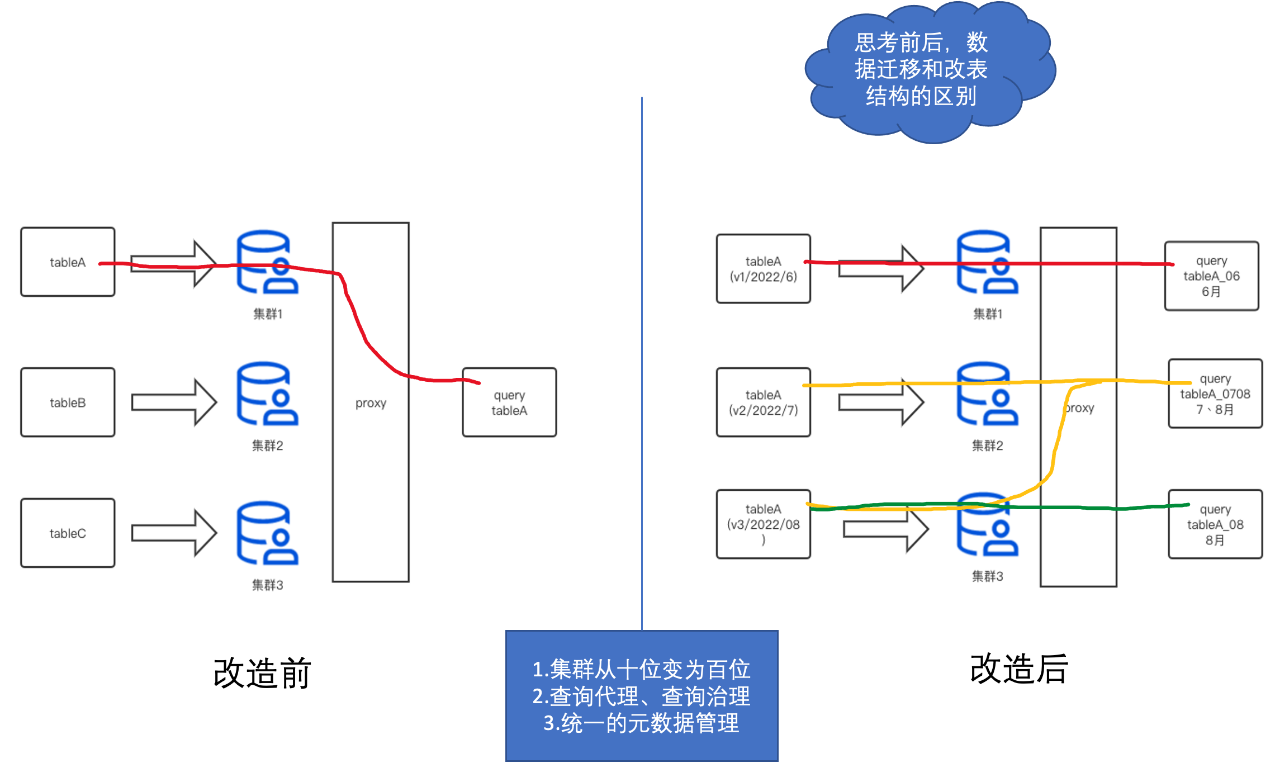
圖18
(1)資料跨如何跨叢集
假設我們有三個資料叢集1、2、3和三個表A、B、C(如圖18)。在改造之前,我們單張表(如A)只能坐落在一個資料叢集1中。這樣的設計方式,導致了當叢集1磁碟滿了之後,我們沒有辦法快速地將表A資料搬遷到磁碟相對空閒的叢集2中。我們只能用雙寫的方式將表A同時寫入到叢集1和叢集2中,等到叢集2的資料經過了TTL時間(如7天)後,才能將表A從資料叢集1中刪除。這樣,對我們的叢集運維管理帶來了極大的不方便和慢響應,非常耗費人力。
於是,我們設計一套類分庫分表的架構,來實現表A在多個叢集1、2、3之間來回穿梭。我們可以看到右邊改造後,表A以時間節點作為分庫分表的切換點(這個時間可以是精確到秒,為了好理解,我們這裡以月來舉例)。我們將6月份的資料寫入到叢集1、7月寫到叢集2、8月寫到叢集3。當查詢語句命中6月份資料時,我們只查詢叢集1的資料;當查詢語句命中7月和8月的資料,我們就同時查詢叢集2和叢集3的資料。
我們透過建立不同分散式表的方式實現了這個能力(如:分散式表tableA_06/tableA_07/tableA_08/tableA_0708,分散式表上的邏輯叢集則是是叢集1、2、3的組合)。這樣,我們便解決了表跨叢集的問題,不同叢集間的磁碟使用率也會趨於平衡。
(2)如何修改排序鍵不刪除歷史資料
非常巧妙的是,這種方式不僅能解決磁碟問題。Clickhouse 分散式表的設計只關心列的名稱,並不關心本地資料表的排序鍵設定。基於這種特性,我們設計表A在叢集2和叢集3使用不一樣的排序鍵。這樣的方式也能夠有效解決初期表A在叢集2排序鍵設計不合理的問題。我們透過在叢集3上重新建立正確的排序鍵,讓其對新資料生效。同時,表A也保留了舊的7月份資料。舊資料會在時間的推移一下被TTL清除,最終資料都使用了正確的排序鍵。
(3)如何解決刪除大表欄位導致後設資料不一致
更美妙的是,Clickhouse 的分散式表設計並不要求表A在7月和8月的後設資料欄位完全一致,只需要有公共部分就可以滿足要求。比如表A有在7月有11個欄位,8月份想要刪除一個棄用的欄位,那麼只需在叢集3上建10個欄位的本地表A,而分散式表 tableA_0708 配置兩個表共同擁有的10個欄位即可(這樣查分散式表只要不查被刪除的欄位就不會報錯)。透過這種方式,我們也巧妙地解決了在資料規模特別大的情況下(單表百TB),刪除欄位導致常見的後設資料不一致問題。
(4)叢集升級
同時,這種多版本叢集的方式,也能方便地實現叢集升級迭代,如直接新建一個叢集4來儲存所有的09月的表資料。叢集4可以是社群最新版本,透過這種迭代的方式逐步實現全部叢集的升級。
4.3 後設資料管理
為了實現上述的功能,我們需要維護好一套完整的後設資料資訊,來管理表的建立、寫入和 DDL(如圖19)。該後設資料包含每個表的版本定義、每個版本資料的資料歸屬叢集和時間範圍等。
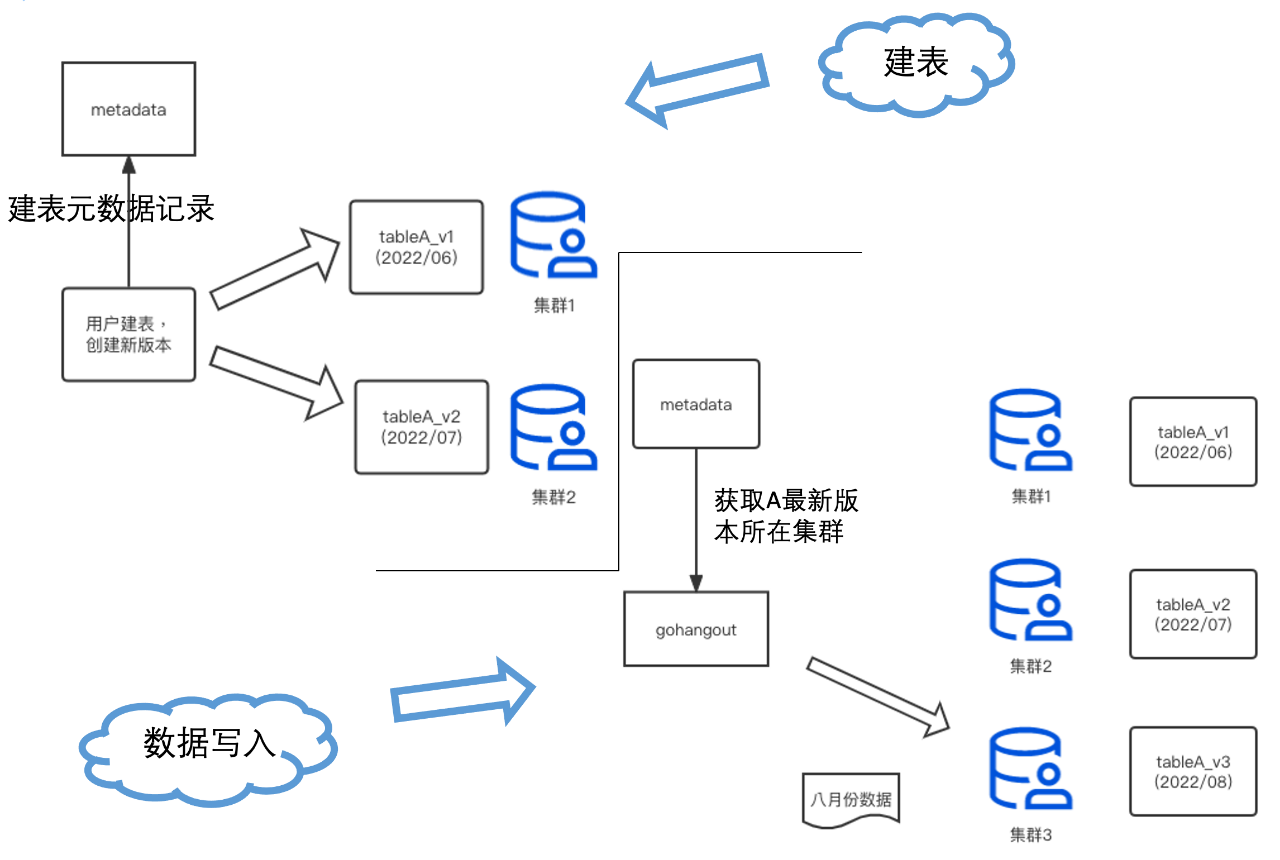
圖19
4.4 統一查詢治理層
(1)Antlr4 的 SQL 解析
在查詢層,我們基於 Antlr4 技術,將使用者的查詢 SQL 解析成 AST 樹。透過 AST 樹,我們能夠快速地獲得 SQL 的表名、過濾條件、聚合維度等(如圖20)。我們拿到這些資訊後,能夠非常方便地對 SQL 實時針對性的策略,如:資料統計、最佳化改寫和治理限流等。
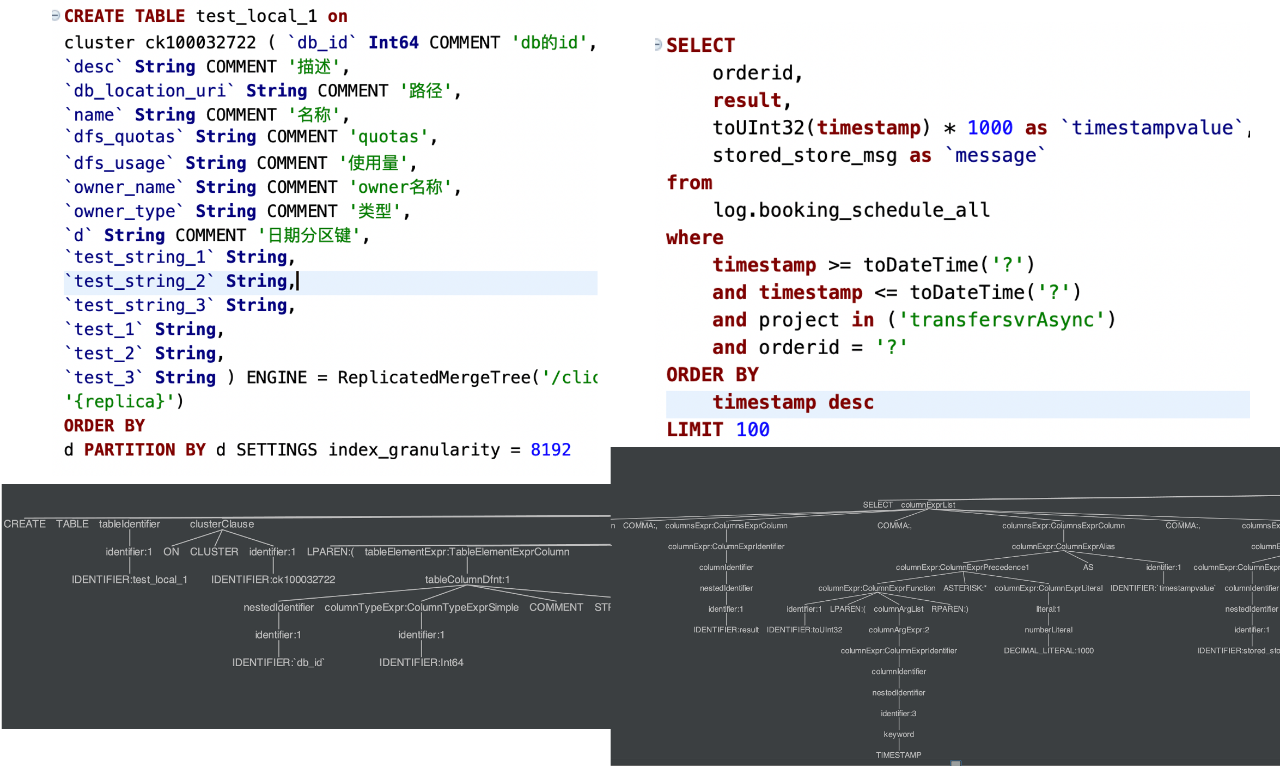
圖20
(2)查詢代理層

圖21
我們對所有使用者的SQL查詢做了一層統一的查詢閘道器代理(如圖21)。該程式會根據後設資料資訊和策略對使用者的 SQL 進行改寫,實現了精準路由和效能最佳化等功能。同時,該程式會記錄每次查詢的明細上下文,用於對叢集的查詢做統一化治理,如:QPS 限制、大表掃描限制和時間限制等拒絕策略,來提高系統的穩定性。
五、未來計劃
透過日誌3.0的構建,我們重構了日誌系統的整體架構,實現叢集 Kubernetes 化管理,併成功地解決了歷史遺留的 DDL 異常、資料跨叢集讀寫、索引重構優、磁碟治理和叢集升級等運維難題。2022年,日誌系統成果地支撐了公司 CLOG 與 UBT 業務的資料接入,叢集資料規模達到了30+PB。
當然,攜程的日誌系統演進也不會到此為止,我們的系統在功能、效能和治理多方面還有不少改善的空間。在未來,我們將進一步完善日誌統一查詢治理層,精細化地管理叢集查詢與負載;推出日誌預聚合功能,對大資料量的查詢場景做加速,並支援 AI智慧告警;充分地運用雲上能力,實現彈性混合雲,低成本支撐節假日高峰;推到日誌產品在攜程系各個公司的使用覆蓋等。讓我們一起期待下一次的日誌升級。
來自 “ 攜程技術 ”, 原文作者:Dongyu;原文連結:http://server.it168.com/a2023/0116/6786/000006786286.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 乾貨 | 攜程線上風控系統架構架構
- 轉轉容器日誌採集的演進之路
- 【乾貨分享】Linux系統日誌的三種型別!Linux型別
- 乾貨 | 資料為王,攜程國際火車票的 ShardingSphere 之路
- 乾貨:ANR日誌分析全面解析
- 億級流量系統架構演進之路架構
- 乾貨 | 攜程圖片服務架構架構
- 萬字乾貨:從訊息流平臺Serverless之路,看Serverless標準演進Server
- 日誌系統
- 乾貨 | 攜程酒店實時數倉架構和案例架構
- 面向平臺的智慧客服系統之實踐演進之路
- vivo服務端監控系統架構及演進之路服務端架構
- 日誌架構演進:從集中式到分散式的Kubernetes日誌策略架構分散式
- Prometheus on CeresDB 演進之路Prometheus
- AIX系統日誌AI
- Rsyslog日誌系統
- Linux系統級日誌系統Linux
- 日誌分析如何演變
- 日誌審計系統
- ELK日誌分析系統
- 日誌系統相關
- 《六週玩轉雲原生》- 微服務架構下服務治理體系的演進歷程?微服務架構
- 乾貨 | 攜程一次Redis遷移容器後Slowlog“異常”分析Redis
- DAG任務排程系統 Taier 演進之道,探究DataSourceX 模組AI
- 內部專家親自揭秘!滴滴物件儲存系統的演進之路物件
- 網易數帆資料治理演進
- jaeger的技術演進之路
- ELK-日誌分析系統
- 檢視系統的日誌
- 乾貨 | 攜程酒店排序推薦廣告高效可靠資料基座--填充引擎排序
- ELK日誌系統之通用應用程式日誌接入方案
- 乾貨 | 廣告系統架構解密架構解密
- windows10系統怎麼刪系統日誌_win10如何徹底刪除系統日誌WindowsWin10
- Win10系統日誌怎麼檢視_win10系統日誌在哪裡Win10
- 乾貨滿滿 | 美團資料庫運維自動化系統構建之路資料庫運維
- 記一次系統演變過程
- Shopee Games 遊戲引擎演進之路GAM遊戲引擎
- 許式偉:Go+ 演進之路Go