分散式塊儲存 ZBS 的自主研發之旅 | 架構篇
作者:深耕行業的 SmartX 金融團隊
背景
ZBS 是由 Z Block Storage 縮寫而來,Z 代表 The Last Word,有最後/最終之意。ZBS 是 SmartX 自主設計、研發並且成功商業化的一款分散式塊儲存產品。一直以來,ZBS 作為 SmartX 超融合軟體(SMTX OS)的重要組成部分,為上層虛擬化提供高效能、高可用和高可靠的資料持久化儲存支撐。
在日常與金融客戶交流過程中,客戶對 ZBS 架構原理都表現出了不同程度的興趣和疑惑,這也是本文編寫的初衷,希望透過這樣的一篇文章,可以給讀者一個全面的視角來了解 ZBS。
緣起
SmartX 公司創立之初(2013 年),定位是為企業雲構建易用、可靠、按需擴充套件的資料中心基礎架構。在分散式儲存(公司第一款產品 HCI 儲存底座)早期技術路線選擇上,其實也調研過開源類產品,例如 Sheepdog 和 Ceph 等。使用開源產品的好處是啟動快(產品可以快速商業化),如同蓋房子,站在 10 樓向上蓋速度很快,但隨著房子越來越高,問題會越來越多:整體結構和地基是否可以適應不斷變化的需求;是否可以靈活按需最佳化迭代;對於像 Ceph 類程式碼量偏重且複雜的開源產品,遇到核心問題,是否可以及時解決;以及開源產品的 License 等等。綜合評估下,SmartX 決定走自主研發的技術路線,從圖紙設計到基建再到交付房子,這條路雖慢,但符合初創團隊的產品基因:做難做的事,做有價值的事。
做完第一個選擇後,馬上就要思考第二個問題:分散式儲存的架構應該如何選擇?在當時,可供選擇和參考的架構大致有兩類:
- DHT – Distributed Hash Table(Ceph 即典型的 DHT 代表)
- 集中管理後設資料(以 GFS – Google File System 為代表)
基於演算法去實現大規模資料集的分散式管理,看似是完美的、智慧的,但在面對企業常態化的叢集橫向擴容和硬體故障所帶來的拓撲變化,會影響到演算法,進而導致資料位置的變化,產生不必要的資料流動,同時也會失去對副本位置的控制權,對儲存效能的最佳化也會變得複雜。這並不是 SmartX 希望看到的樣子。
GFS 在 Google 內部已經有大規模使用(2003 年論文發表時,最大叢集節點已超千臺),其後來者 HDFS 在大資料場景中的成功應用,可以證明 GFS 的框架設計理念是可靠的,是具有高度容錯的分散式儲存系統框架。以下對 GFS 簡要介紹:
- 執行在普通 PC 伺服器,可按需水平擴充套件,並處理超大規模資料集。
- 儲存大檔案(GB 級)場景,I/O 特點是檔案一次寫、多次讀,修改操作以追加為主。
- 對順序寫和順序讀模型比較友好,隨機讀寫時架構設計並不能保證效能。
- 採用和應用程式 API 協同設計的方法(簡化接入實現)。
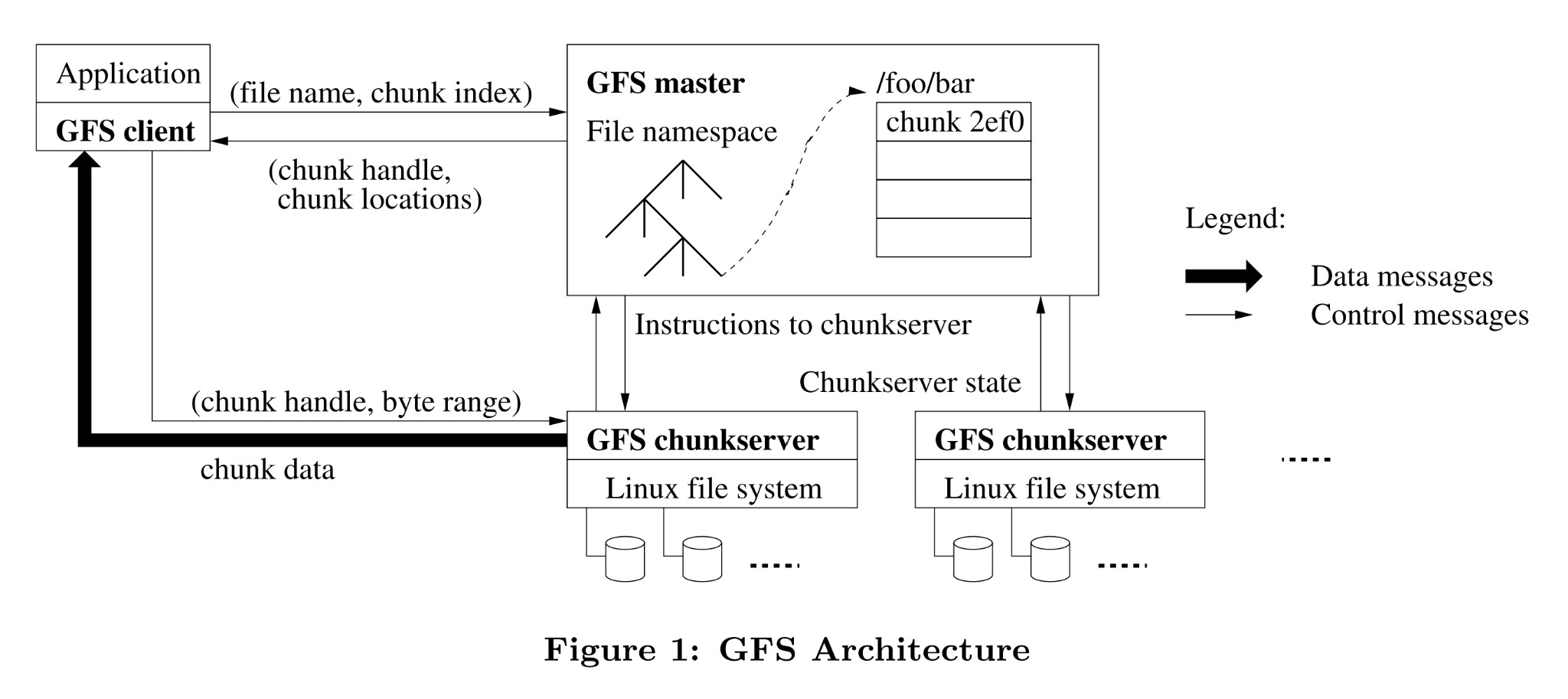
圖 1 – GFS 架構 1
圖 1 來自 GFS 論文中的架構設計,可以看出,GFS 採用 Single Master 的設計思想(容錯是需要獨立設計實現),架構由一個 Master 加多個 ChunkServer 組成,檔案被切分成多個 Chunk 塊,採用副本技術實現資料可靠性。架構將控制資訊與資料分離,減少 Master 工作負載,並透過控制 Chunk Size(64 MB),從而減少通訊開銷以及後設資料的容量開銷。如果讀者想更加深入瞭解 GFS,可以閱讀文末第一篇參考文章。
可以看出,透過合理設計,Master 集中管理後設資料,並不會成為瓶頸。結合 SmartX 自身的需求,即精細化管控資料,來實現極致的效能最佳化和靈活的資料運維能力,我們最終確定參考和借鑑 GFS 的設計理念(技術路線),去實現一款自主研發、適應於私有云/虛擬化的企業級分散式儲存產品。
確定了技術路線,下面我們透過不同的維度來一起看看,ZBS 的架構是如何設計的,在哪些地方與 GFS 相似,哪些地方不同,SmartX 又是如何思考的。
對產品設想
雖然參考 GFS 的框架,但應用場景不同(GFS 是面向大資料,對資料一致性的要求是寬鬆的,而 ZBS 的定位是面向雲端計算/虛擬化,要求強一致性)、目標不同(GFS 頻寬優先,而 ZBS 對儲存的 IOPS/BW/Latency 都非常看重),所以對產品細節的考慮及實現方式需要有自己的方法論。以下是我們對產品的一些主要定位:
- 相比使用專有黑盒硬體,需執行在標準的 PC 伺服器,使用標準通用硬體。
- 可小規模起步(3 節點),按需水平擴充套件。
- 假設失效是常態,架構需具備良好的容錯和自動恢復能力。
- 處理大規模資料集,單叢集可處理 PB 級資料。
- 儲存軟體需要將硬體的效能充分發揮出來(硬體升級換代或擴容)。
- 靈活的儲存協議接入方式和擴充套件能力。
儲存架構
構建一個企業級分散式儲存系統對於任何一個團隊來講,都是一件極具挑戰性的工作。不僅需要大量的理論基礎,還需要有良好的工程能力支撐。
從廣泛意義上講,分散式儲存中通常需要解決三個問題,分別是後設資料服務、資料儲存引擎以及一致性協議。圖 2 為 ZBS 系統架構,其元件將逐一展開介紹。
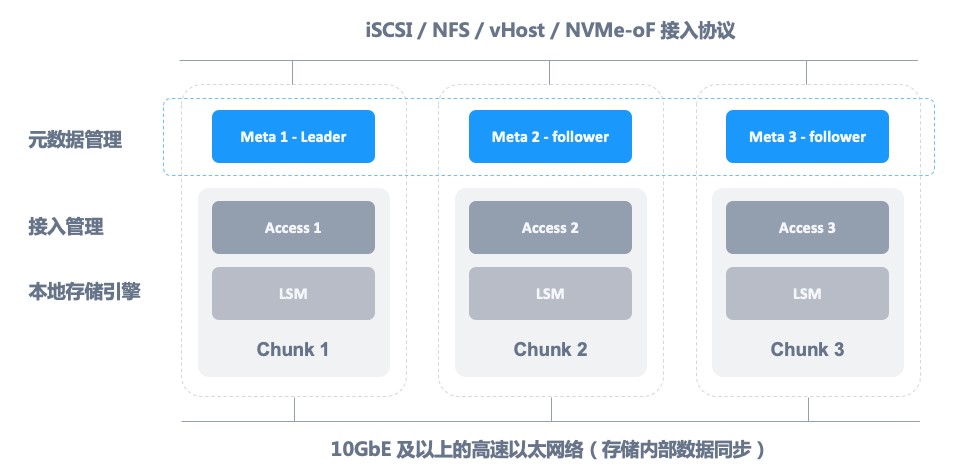
圖 2 – ZBS 系統架構
Meta 是整個分散式叢集的大腦,其功能包括:叢集成員管理、儲存物件管理、資料定址、副本分配、訪問許可權、資料一致性、負載均衡、心跳、垃圾回收等。
儲存引擎 Chunk 負責管理資料在每一個獨立節點內的儲存能力,以及本地磁碟管理、磁碟故障和亞健康處理等。每一個儲存引擎之間是獨立的,在這些獨立的儲存引擎之間,需要執行一個一致性協議,來保證對於資料的訪問可以滿足 ZBS 期望的一致性狀態。
接入管理是對外提供儲存功能服務的能力,提供可靠的、高效能的接入服務,從圖 2 中可以看到,ZBS 提供了豐富的接入協議,來滿足不同場景下的接入通道,在後面的系列文章中也會詳細介紹各種接入協議的設計實現。
有了以上這些元件,就掌握了一個分散式儲存的核心,不同的分散式儲存系統之間的區別,基本上也都來自於這些元件的不同選擇。
Meta 後設資料服務
所謂後設資料就是“資料的資料”,如果後設資料丟失了,或者後設資料服務無法正常工作,那麼整個叢集的資料都將無法被訪問。同時,後設資料服務的響應效能,也決定了整個儲存叢集的效能表現,所以 ZBS 的設計聚焦在以下三個能力:
- 可靠性 – 在單 Master 架構中,後設資料必須儲存多份,同時後設資料服務需要提供容錯和快速切換的能力,採用分散式資料庫來持久化和同步後設資料的方案,明顯會給整個架構增加複雜性。最終 ZBS 選擇採用單機 KV DB 來實現 Meta 本地後設資料持久化,利用 Log Replication 機制實現後設資料在多節點間的資料同步,當 Meta Lead 失效,Follower 節點透過選主快速接管後設資料服務。
- 高效能 – 最小化後設資料服務在儲存 I/O 路徑中的參與度。ZBS 將控制平面與資料平臺進行分離,使大部分 I/O 請求不需要訪問後設資料服務,當需要修改後設資料時,比如資料分配,後設資料操作的響應時間必須足夠快。ZBS 定義資料塊 Extent 為 256 MiB,在 2 PiB 叢集儲存容量規模下,後設資料能全部載入到記憶體中操作,提高查詢效率。
- 輕量級 – 為了讓架構簡單,ZBS 並沒有拆分成管理節點和資料節點(與 GFS 不同之處),而是透過合理的資源最佳化,將後設資料服務與資料服務混合部署在同一個節點,三節點即可部署交付,而無需獨立部署管理節點。
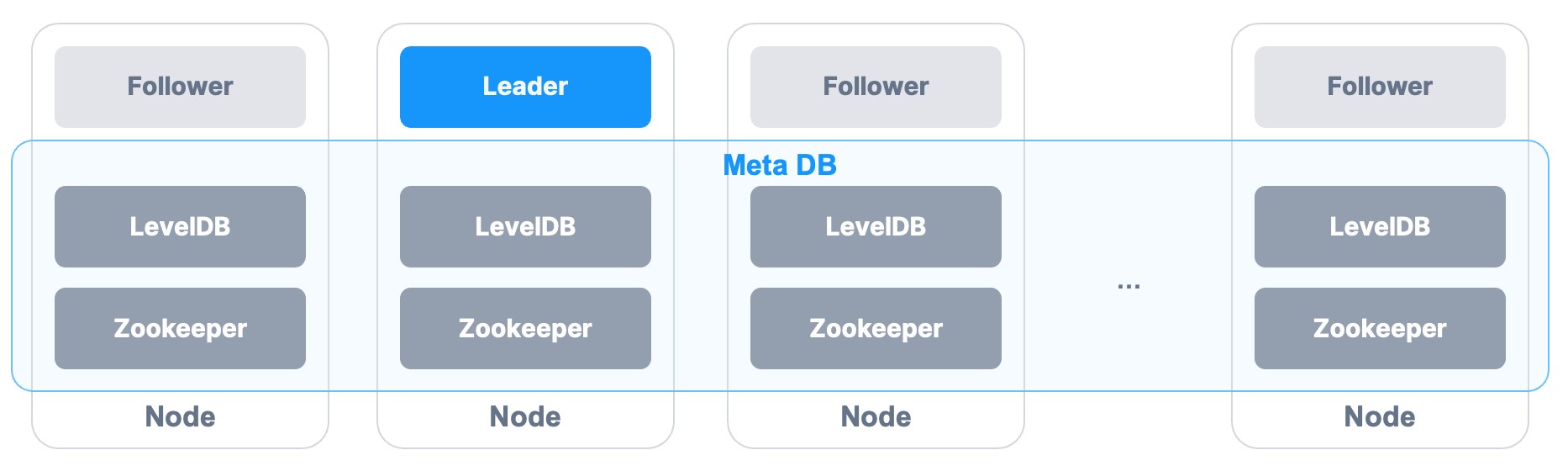
圖 3 – Meta 後設資料
儲存引擎
與後設資料服務相似,儲存引擎的設計,同樣需要關注可靠性、一致性、效能以及易於運維等幾個方面的能力。
- 可靠性 – 資料的可靠和一致性是最核心的能力,沒有任何妥協的空間。ZBS 採用副本的資料保護技術,透過副本(Extent)版本號實現資料一致性的檢查,資料副本數低於預期時,將自動觸發資料重構。對於髒資料,由 Meta 定期完成 GC(垃圾回收)。
- 效能 – ZBS 設計提供兩種儲存形態「全閃和混閃」來適應不同場景下的效能需求。隨著新型硬體的速度越來越快(NVME、DCPMM、25 GbE……),效能的瓶頸會從硬體轉移到軟體,尤其對於儲存引擎,效能至關重要。ZBS 在軟體層面追求極致最佳化(程式鎖、上下文切換等),來提高效率。
- 裸裝置管理 – ZBS 並沒有使用現成的檔案系統作為儲存引擎,而是結合自身對效能的需求,在裸裝置上實現資料分配、空間管理、I/O 等邏輯。這樣做的好處是可以避免檔案系統帶來的效能 Overhead 以及 Journal 寫放大。
- 運維 – 易於使用、易於升級,可以讓客戶日常運維更加簡便;易於排錯、發現問題,可以使工程師快速定位並修復。使用 Kernel Space,優勢是效能更好,但同時也存在很多嚴重的問題,如 Debug 和升級麻煩,Kernel 模組故障域變大,很可能汙染 Kernel。最終,ZBS 採用 User Space 實現儲存引擎(軟體升級方便,程式問題並不會影響 Kernel)。

圖 4 – 儲存引擎
資料路徑
透過圖 5 可以瞭解到 ZBS 接入資料完整 I/O 過程。
- Client 發起 I/O 請求,不同的接入協議(iSCSI、NFS、vhost、NVMe-oF)會使用不同的互動方式,這裡並不展開,Access 接收 I/O 請求。
- 超融合架構計算與儲存融合,在節點狀態正常下,I/O 請求傳送給本地 Access。
- 存算分離架構,I/O 接入的 Access,在首次連線由 Meta 進行分配。
- Access 向 Meta 請求授權,透過 Lease 實現對 Extent(資料塊)操作許可權,同時快取 Extent 的位置資訊。
- Access 向多個 Extent 所在位置發起強一致性的 I/O 操作。
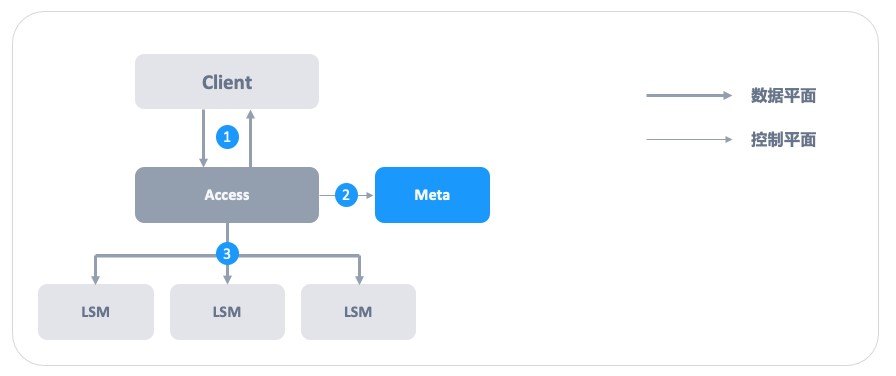
圖 5 – Access 接入
對比 ZBS 和 GFS
相信讀者對 ZBS 的設計思想已經有了一定的瞭解,雖然 ZBS 設計參考 GFS 實現,但應用場景決定了最終實現的區別。我們透過下面的表格展示兩種儲存在架構設計實現上的相同與不同。
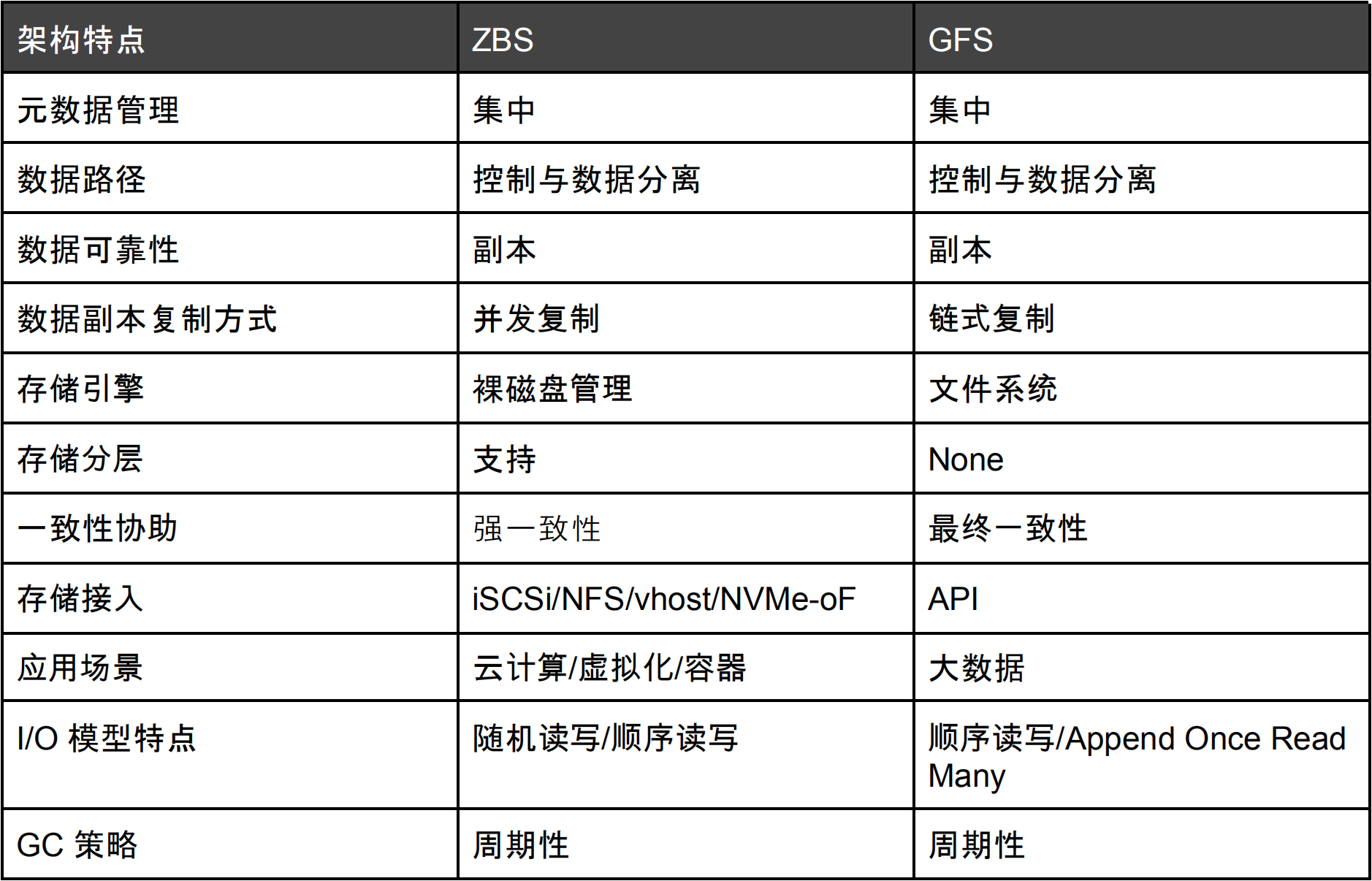
表 1 – ZBS 與 GFS 架構對比
效能表現
經過多年的產品迭代最佳化,圖 6 展示了最新版本下,ZBS 在不同儲存介質型別、網路環境以及疊加不同軟體功能條件下,發揮的儲存效能表現(基於 3 節點 HCI 叢集)。

圖 6 – ZBS 儲存效能
展望
ZBS 透過大量的客戶部署案例,積累了豐富的經驗,同時隨著近些年新技術的不斷湧現,SmartX 將結合自身的理解,在後續軟體迭代中持續最佳化 ZBS,充分發揮新型儲存介質的效能,例如儲存引擎 I/O 利用使用者態驅動 Bypass Kernel、Meta 分散式來支援更多新的特性。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/69974533/viewspace-2911878/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 分散式塊儲存 ZBS 的自主研發之旅|後設資料管理分散式
- 分散式儲存架構知識,一篇講清楚!分散式架構
- QingStor分散式儲存全線升級,踐行“為雲而生、自主研發”理念分散式
- 基於MFS高可用的分散式儲存架構分散式架構
- 杉巖PACS影像系統分散式儲存架構分散式架構
- 分散式日誌儲存架構程式碼實踐分散式架構
- DAOS 分散式非同步物件儲存|架構設計分散式非同步物件架構
- Longhorn 雲原生分散式塊儲存解決方案設計架構和概念分散式架構
- CEPH分散式儲存搭建(物件、塊、檔案三大儲存)分散式物件
- J2EE分散式架構整合阿里雲OSS儲存分散式架構阿里
- Longhorn,Kubernetes 雲原生分散式塊儲存分散式
- 分散式儲存單主、多主和無中心架構的特徵與趨勢分散式架構特徵
- 一塊螢幕的研發之旅
- 我的Android重構之旅:架構篇Android架構
- HDFS分散式儲存分散式
- Redis 分散式儲存Redis分散式
- 微服務分散式架構之redis篇微服務分散式架構Redis
- 分散式架構篇 | OceanBase負載均衡的魅力分散式架構負載
- 大規模分散式儲存系統:原理解析與架構實戰分散式架構
- Onchain招人啦!!!區塊鏈核心開發工程師、高階架構師、分散式儲存高階工程師快到碗裡來!AI區塊鏈工程師架構分散式
- 構建安全可靠的分散式儲存Oracle網路分散式Oracle
- 分散式架構的概述分散式架構
- 分散式儲存ceph 物件儲存配置zone同步分散式物件
- DAOS 分散式非同步物件儲存|儲存模型分散式非同步物件模型
- 超融合私有云基礎架構方案評估(架構與儲存篇)架構
- Filecoin分散式儲存,能否實現區塊鏈3.0時代?分散式區塊鏈
- 分散式儲存轉崗記分散式
- [分散式][高併發]高併發架構分散式架構
- Gartner:浪潮儲存進入分散式儲存前三分散式
- 分散式儲存產業方陣:2022年分散式儲存發展白皮書(附下載)分散式產業
- 分散式WebSocket架構分散式Web架構
- 分散式發號器架構設計分散式架構
- 哪些企業需要分散式式儲存?分散式
- 《MySQL 基礎篇》十:邏輯架構和儲存引擎MySql架構儲存引擎
- 分散式架構篇 | 如何在分散式架構下完美實現“全域性資料一致性”?分散式架構
- 效能躍升50%!解密自主研發的金融級分散式關聯式資料庫OceanBase 2.0解密分散式資料庫
- 分散式架構和微服務架構的區別分散式架構微服務
- 分散式儲存glusterfs詳解【轉】分散式