快速認識HTTP協議
一、TCP/IP 協議族
為了使世界上的計算機可以透過網路互相通訊,就需要在不同的硬體、軟體、作業系統之間制定一種通訊規則,這種規則就稱為協議(protocol)。
為了實現全球網際網路通訊,IETF(The Internet Engineering Task Force,國際網際網路工程任務組) 對相關的所有硬體和軟體制定了一系列標準協議,集合起來總稱為「TCP/IP 協議族」,簡稱「TCP/IP」。
1、分層模型
TCP/IP 四層模型和 OSI 七層模型對比:

2、資料處理流程
資料在層與層之間傳輸,傳送端每到一層都會對附加一個首部資訊,接收端每到一層就會刪除一個對應首部,最終拆包出原始資料。
TCP/IP 四層協議處理資料流程:

OSI 七層協議處理資料流程:

3、HTTP 和 IP、TCP、DNS
在 TCP/IP 協議族中,與 HTTP 關係最密切的三個協議就是 IP、TCP、DNS。
IP 協議:
Internet Protocol 網際協議,位於網路層。
作用是把各種資料包傳送給對方。
為保證把資料傳送到對方,要滿足兩個重要的條件:IP地址和 MAC地址。
IP地址指明節點被分配到的地址,MAC地址是網路卡所屬的固定地址,二者配對。
IP地址可變換,但MAC地址基本不變。

TCP 協議:
位於傳輸層,提供可靠的位元組流服務,確保可靠性
三次握手確保資料能到達目標

DNS 服務:
Domain Name System,負責域名解析,位於應用層,把域名解析成IP地址


二、HTTP 協議結構
客戶端: 請求訪問文字或影像等資源的一方
伺服器端:提供資源響應的一方
HTTP:(Hyper Text Transfer Protocol) client 和 server 之間傳輸資料的超文字傳輸協議。
每個 HTTP 請求和響應都遵循相同的格式,一個 HTTP 包含 Header 和 Body 兩部分,其中 Body 是可選的。
1、HTTP 請求報文
HTTP GET 請求格式:
GET /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
HTTP POST 請求格式:
POST /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...

每個 Header 佔用一行。
當遇到空行,即連續兩個換行符 rn 時,Header 部分結束,後面的資料全部是 Body。
當請求網站首頁時,URI 為 /
URI 和 URL
URI:統一資源識別符號,用字串標識某一網際網路資源
URL:統一資源定位符,表示資源的地點(網際網路上所處的位置),是URI的子集
URI 的格式:

登入資訊:可選
伺服器埠號:當使用預設埠 80 時,可選
查詢字串:查詢指定檔案路徑時的引數,可選
片段識別符號:標記出已獲取資源中的子資源(文件內的某個位置),可選
2、HTTP 響應格式
HTTP/1.1 200 OK
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...

HTTP 響應如果包含 body,也是透過 rnrn 來分隔的。
2.1 響應碼
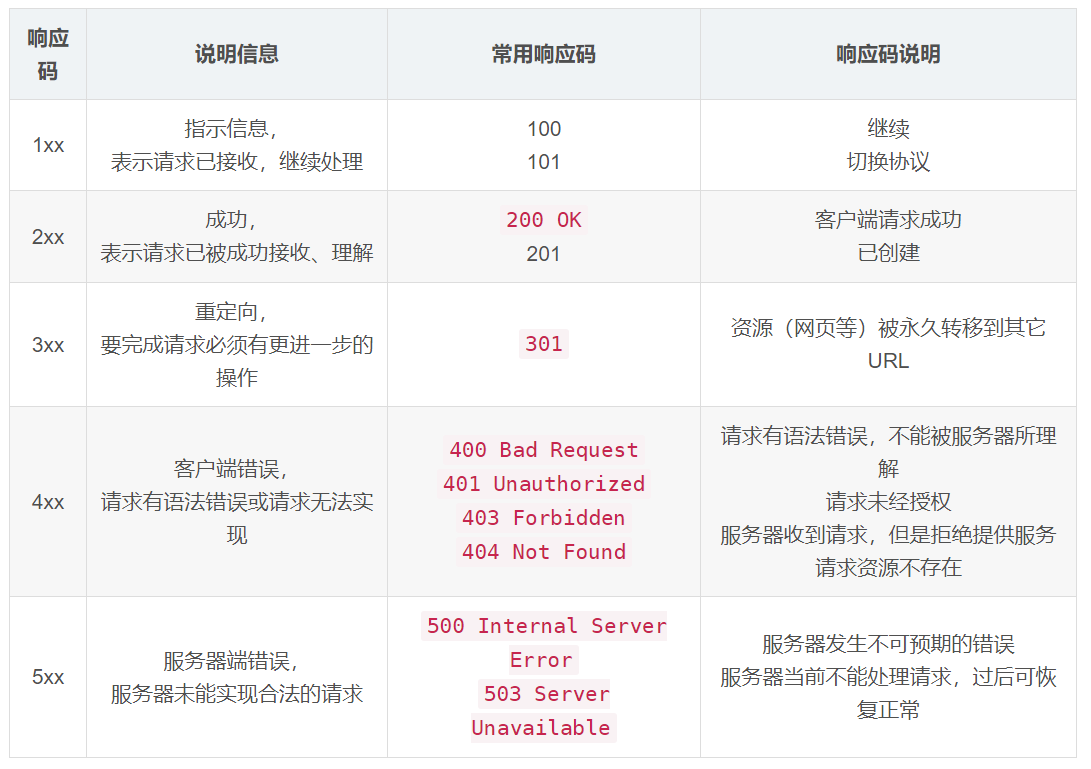
2.2 Content-Type 和 Content-Encoding
Body 的資料型別由 Content-Type 頭來確定,而不是 URL
即使 URL 是 ,也不一定就是圖片。
Content-Type:text/html;charset=utf-8:響應內容是網頁,編碼是UTF-8
Content-Type:image/png:響應內容是圖片
Content-Encoding: gzip:說明 Body 資料是被壓縮的,壓縮方式是 gzip
要先將資料解壓縮,才能得到真正的資料
壓縮的目的在於減少Body的大小,加快網路傳輸
3、檢視 HTTP 報文
我們可以透過很多工具來檢視 client 和 server 之間的報文傳輸情況,也就是常說的 「抓包」。
這裡以 Chrome 瀏覽器為例進行簡單的抓包說明:
在 Chrome 位址列輸入 ,瀏覽器將顯示新浪首頁
透過 Chrome - F12 - Network 檢視 client 和 server 之間的通訊過程
點選 Name 為 的記錄,檢視右側的 Request 和 Response 的 view source 內容。
Chrome F12 說明:
Elements: 網頁結構
Console:控制檯輸出資訊
Source:資原始檔
Network:瀏覽器和伺服器的所有通訊記錄
Headers:顯示請求頭、請求體和響應頭資訊
view source:顯示瀏覽器和伺服器之間的原始/實際通訊內容
Response:顯示響應體內容
4、HTTP 請求流程
還是以訪問新浪首頁為例,總結一下 HTTP 請求的流程:
1、 client 向 server 傳送 HTTP 請求
請求包括:方法,URI,域名,其它 headers,使用POST方法時還包括 Body
2、 server 向 client 返回 HTTP 響應
響應包括:響應碼,響應型別,其它 headers,響應 Body
3、 若 client 還要向 server 請求其它資源(如圖片),則再次傳送 HTTP 請求,重複步驟 1、2。
瀏覽器解析過程:
當瀏覽器讀取到新浪首頁的 HTML 原始碼後,它會解析 HTML 並顯示頁面,
然後,根據 HTML 裡面的各種連結,再傳送 HTTP 請求給新浪伺服器,拿到相應的圖片、影片、Flash、JavaScript指令碼、CSS等各種資源,
最終顯示出一個完整的頁面,所以我們在 Network 下面能看到很多額外的 HTTP 請求。
HTTP 協議具備極強的擴充套件性,雖然瀏覽器請求的是新浪首頁 http://,但是新浪可以在響應的 HTML 中鏈入其他伺服器的資源,比如<img src="https://n.sinaimg.cn/index/mid_article/images/ask.png">,從而將請求壓力分散到各個伺服器上。
並且一個站點可以連結到其他站點,無數個站點互相連結起來,就形成了 WWW(World Wide Web) 。
三、HTTP 版本發展

1、HTTP 1.0
主要缺點:
短連線,一個連線只能有一個請求,即每次請求都會重新建立一個 TCP 連線
TCP 建立連線需要三次握手,加上慢啟動的特性,這將是很耗資源和效能的一步
解決辦法:
部分 HTTP 1.0 的實現版本,在請求頭中新增了一個 Connection:keep-alive標記
該標記要求伺服器不要關閉 TCP 連線,以便其他請求複用。伺服器同樣回應這個欄位。
直到客戶端或伺服器主動關閉連線。
但是,這不是標準欄位,不同實現的行為可能不一致,因此不是根本的解決辦法,並沒有被廣泛支援。
2、HTTP 1.1
HTTP 1.1 版本中引入了很多最佳化技術,這是到目前為止使用最廣泛的版本,但是大部分伺服器也支援1.0版本。
2.1 持久連線
最大的變化就是引入了持久連線(HTTP persistent connection或HTTP connection reuse)。
特點:
TCP 連線預設不關閉,可以被多個請求複用
只要任意一端沒有明確提出斷開連線,則保持連線狀態。
建立一次 TCP 連線後,可以進行多次請求和響應互動
減少了 TCP 連線的重複建立和斷開所造成的額外開銷,減輕伺服器負載,使 web 頁面顯示速度更快。
目前,對於同一個域名,大多數瀏覽器允許同時建立 6 個持久連線。
2.2 管道機制
在持久連線的基礎上還引入了管道機制(pipelining)。
特點:
在同一個 TCP 連線裡面,客戶端可以同時並行傳送多個請求,而不用等待前面請求的響應,進一步提升效率。
之前版本中,傳送一個請求後要等待並收到響應,才能傳送下一個。
2.3 Content-Length 欄位
在管道機制中,一個 TCP 連線同時傳送多個請求,伺服器依次處理並返回響應。
為了準確區分響應資料包是屬於哪一個請求的,在響應頭中加入 Content-length 欄位,宣告本次響應的資料長度。
在 1.0 版中,瀏覽器發現伺服器關閉了TCP連線,就表明收到的資料包已經全了。
如 Content-Length: 3495 表示本次回應的長度是 3495 個位元組,後面的位元組就屬於下一個回應了。
2.4 分塊傳輸編碼
使用 Content-Length 欄位的前提是,伺服器傳送回應之前,必須知道回應的資料長度。
對於一些很耗時的動態操作、或者傳輸大量資料時,伺服器要等到所有操作完成,才能傳送資料,顯然這樣的效率不高。
更好的處理方法是,產生一塊資料,就傳送一塊,採用"流模式"(stream)取代"快取模式"(buffer),使瀏覽器逐步顯示頁面。
因此,1.1 版本又引入了 “分塊傳輸編碼”(chunked transfer encoding)。只要請求或響應的頭資訊有 Transfer-Encoding 欄位,就表明回應將由數量未定的資料塊組成。
Transfer-Encoding: chunked
每個非空的資料塊之前,會有一個16進位制的數值,表示這個塊的長度。最後是一個大小為0的塊,就表示本次回應的資料傳送完了,例如:
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
This is the data in the first chunk
1C
and this is the second one
con
sequence
2.5 隊頭堵塞
雖然 1.1 版本允許複用 TCP 連線,但是同一個 TCP 連線裡面,所有的資料通訊是按次序進行的。伺服器只有處理完一個回應,才會進行下一個回應。
要是前面的回應特別慢,後面就會有許多請求排隊等著。這稱為"隊頭堵塞"(Head-of-line blocking)。
為了避免這個問題,只有兩種方法:
一是減少請求數
二是同時多開持久連線。
對應的,需要做很多網頁最佳化工作,比如合併指令碼和樣式表、將圖片嵌入CSS程式碼、域名分片(domain sharding)等等。
2.6 Cookie 機制
Cookie 技術最早是在 1994 年由 Netscape 公司的一名員工提出的,最終在 2011 年才被 IETF 正式納入規範中。
HTTP 無狀態特點:
無狀態: stateless
HTTP 協議自身不對請求和響應之間的通訊狀態進行儲存
簡單,方便,不儲存客戶端狀態,減少伺服器 CPU 及記憶體消耗
缺點:
對於要求登入認證的網站,為了使伺服器識別登入資訊,需要在每次請求報文中附加一些資訊,在連線較多時會增加頻寬壓力。
為了在特定場景中實現保持狀態的功能,引入了 Cookie 技術來實現狀態的管理。
Cookie 機制:
client 發出請求後,server 返回響應,並在響應報文中加入 Set-Cookie 欄位,用於通知 client 儲存 Cookie。
client 收到響應後,把 Set-Cookie 欄位以文字儲存在本地
client 再次向 server 傳送請求,並在請求報文中加入 Cookie 欄位。
server 收到帶 cookie 的請求,比對伺服器記錄,得到之前的狀態資訊。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/69942496/viewspace-2655021/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- HTTP的協議頭內容的認識HTTP協議
- Http協議常用知識HTTP協議
- 快速讀懂 HTTP/3 協議HTTP協議
- HTTP協議_入門知識HTTP協議
- HTTP協議知識總結HTTP協議
- HTTP協議冷知識大全HTTP協議
- Http網路協議包 (快速理解)HTTP協議
- HTTP協議知識點總結HTTP協議
- http協議HTTP協議
- HTTP 協議HTTP協議
- 認識流媒體協議,從 RTSP 協議解析開始!協議
- HTTP 協議知識點總結(二)HTTPSHTTP協議
- 02 前端HTTP協議(圖解HTTP) 之 簡單的HTTP協議前端HTTP協議圖解
- 理解http協議HTTP協議
- http協議分析HTTP協議
- HTTP協議(2)HTTP協議
- HTTP 協議類HTTP協議
- 小解http協議HTTP協議
- HTTP協議概述HTTP協議
- 網路安全網路協議知識點中,http協議是什麼?協議HTTP
- 重識TCP/IP協議族與HTTP基礎TCP協議HTTP
- 搞定PHP面試 - HTTP協議知識點整理PHP面試HTTP協議
- HTTP協議之:HTTP/1.1和HTTP/2HTTP協議
- HTTP協議簡述HTTP協議
- HTTP 協議簡介HTTP協議
- HTTP協議那些事HTTP協議
- http協議內容HTTP協議
- Http與Https協議HTTP協議
- Http協議入門HTTP協議
- 瞭解HTTP協議HTTP協議
- HTTP通訊協議HTTP協議
- HTTP和HTTPS協議HTTP協議
- HTTP 協議圖解HTTP協議圖解
- HTTP2 協議HTTP協議
- 簡述HTTP協議HTTP協議
- Http協議簡介HTTP協議
- HTTP 協議完全解析HTTP協議
- RPC和 HTTP協議RPCHTTP協議