搜尋引擎分散式系統思考實踐 |得物技術
1.引言
搜尋引擎在資料量逐步擴大之後,分散式搜尋是必經之路。搜尋引擎的分散式除了要考慮資料分片之外,更重要還需要考慮資料的有狀態以及各元件的狀態流轉。在這裡分享一下基於ZK設計分散式搜尋引擎的一些經驗和思考落地情況,包含了從單機版本到分散式版本的演進。
2.分散式系統
分散式系統(distributed system)是一個硬體或軟體元件分佈在不同的網路計算機上,彼此之間僅僅透過訊息傳遞進行通訊和協調的系統。當單機系統在請求量或者資料量無法承載的時候,需要考慮對系統進行合理的分散式改造和部署。
CAP(Consistency Availability Partition tolerance)定理是大家熟知的概念,這三個指標是不可能同時做到的,所以在實際應用中,我們需要我們總是需要針對當前的業務進行取捨,比如在核心資料庫領域為了資料強一致性那麼我們可能妥協一部分可用性,而在大流量的服務上可能會優先可用性,而在Search的搜尋和推薦的應用場景中我們應該優先選擇可用性,來優先保證效能,而在強一致性上妥協,只需要保證最終一致性即可。
3.分散式系統面臨的挑戰
構建一個完整的分散式系統需要解決如下幾個重要的問題:
可靠的節點狀態感知
在分散式系統中異常來自很多情況,包括伺服器硬體不可用導致的崩潰,系統出現嚴重異常崩潰退出,網路不穩定帶來的連結異常和不穩定、服務負載過高出現的假死等各種異常狀態。
資料更新的可靠性
搜尋服務作為有狀態的服務,需要索引大量的資料,同時更為重要的是索引資料不僅每時每刻都在寫入,而且需要保證天級別或者小時級別的全量資料更新,對於一個線上服務,又要保證檢索的穩定性。形象比喻為高速上換車輪不為過。
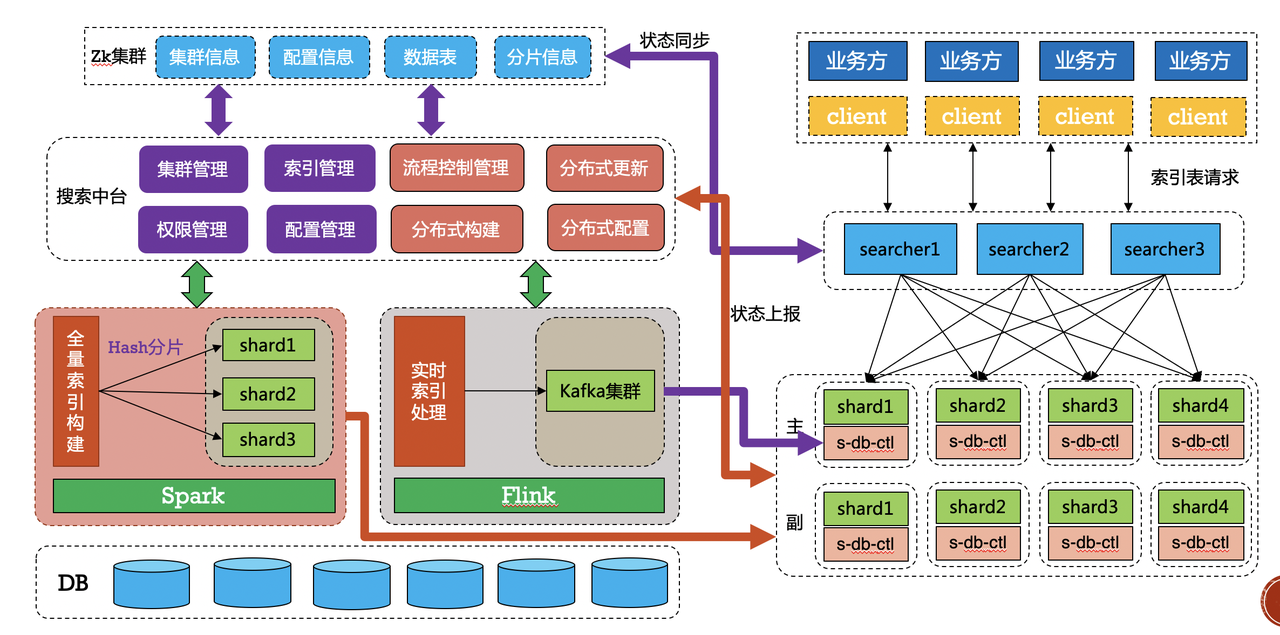
4.Search分散式總體結構
Search分散式總體包括了幾大元件:
shard(核心檢索邏輯和索引分片)
searcher(檢索和請求分發)
indexbuild(離線索引構建)
search-client(服務發現客戶端)
Search分散式框架:
5.shard模組
Search的shard模組是整個搜尋引擎的核心部分,其主要的功能包含了每個獨立的檢索單元,主要的框架模組包含以下部分:
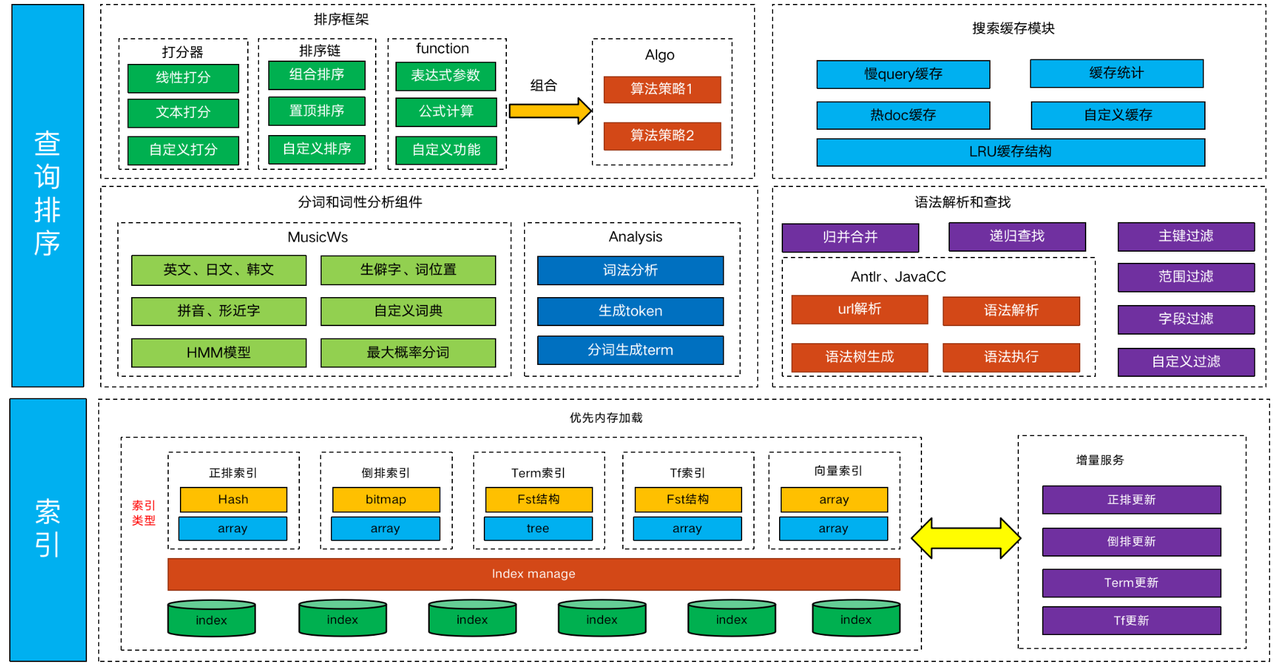
5.1 索引
Search的索引包含多種種類,每種種類資料結構不一樣當前已有的內部索引有正排索引、倒排索引、Term索引、Tf的索引、向量索引等多種索引形式。
正排索引
Search的正排索引存放了從引擎內每個主鍵ID到每條doc完整資料的對映,索引的結構是一個Hashmap結構,每個Key是主鍵ID的Hash值,value是指向每個完整doc的指標。引擎內部使用兩個Hashmap,一個是主鍵ID到docid對映另一個是docid到完整doc的指標對映。
倒排索引
倒排索引本質上是記錄Key到每個doc的對映,在檢索中需要保證倒排鏈有高效的讀寫能力,讀能力利於高效進行復雜的檢索語法操作,比如AND、OR、NOT等複雜的操作。同時倒排鏈的資料結構還需要高效的寫能力,在引擎檢索的同時需要將實時資料寫入到引擎,不可避免的需要修改倒排鏈,所以高效的寫能力也比較關鍵。
陣列
使用陣列來作為索引的結構,好處是讀很快,邏輯操作也快,cache友好,但是寫操作不行,只能用於離線固定的資料,不寫入增量的方式。
跳錶(SkipList)
跳錶的資料結構是對連結串列的一種折中,讀寫效能都算中規中矩,CPU的cache效能比較差,記錄單個docid使用的空間比較多,需要兩個指標外加一個整型。
Bitmap
Bitmap型別是使用位來表示二值資訊,Bitmap的位數來作為Key值,搜尋引擎倒排索引結構比較適合Bitmap這種資料結構,同時Bitmap的結構對CPU的cache友好,讀和寫操作很快,但是因為Bitmap是記錄了所有Key的狀態,包括Bitmap是0的,導致空間可能浪費嚴重。
Roaring Bitmap
RoaringBitmap是帶有一定壓縮功能的Bitmap結構,在既保留了Bitmap的隨機讀寫的效能外,合理對Bitmap中1和0的稠密程度做了處理,減少了儲存空間,綜合效能比較優。
倒排索引的資料結構每個都有各自的適用場景和資料,總體來說看RoaringBitmap的綜合效能較好一些。ES搜尋引擎(Elasticsearch)中對這幾種倒排索引有一個詳細的測試,感興趣的同學可以針對每個測試下看一下各自的測試結果。
Term索引
Term的索引主要用來存放每個欄位分詞完的每個Term,因為Term數量非常大,如果按照普通的存放會有大量的空間浪費,同時搜尋引擎需要字首搜尋,所以Term詞的存放需要滿足字首查詢。Search的Term詞存放使用的資料結構是FST(Finite-State Transducer)資料結構,對應的詳細論文地址,FST的資料結構要比字首查詢樹Trie樹更加的節省空間,查詢效率兩者相比基本一致。
向量索引
向量索引內部是一種特殊的倒排索引,根據不同的近似向量查詢演算法,產出不一樣的索引,針對向量量化演算法而言,訓練後的向量索引會先聚類成一定數量的倒排索引,每個聚類結果形成一個codeID,倒排是對應這個聚類下的向量。所以向量索引是一類特殊的倒排索引。
5.2 查詢排序
查詢模組是Search核心的功能模組,包括了檢索的眾多核心業務邏輯,其中包括自研的分詞器MusicWs、analysis詞性分析模組、語法解析和邏輯查詢模組、Search排序框架以及快取模組等各部分模組。
6.searcher模組
searcher模組是Search核心部分,shard模組的上游,主要的功能包含了對請求的分片和Merge以及對資料的重排序等功能。searcher的整體結構如下:
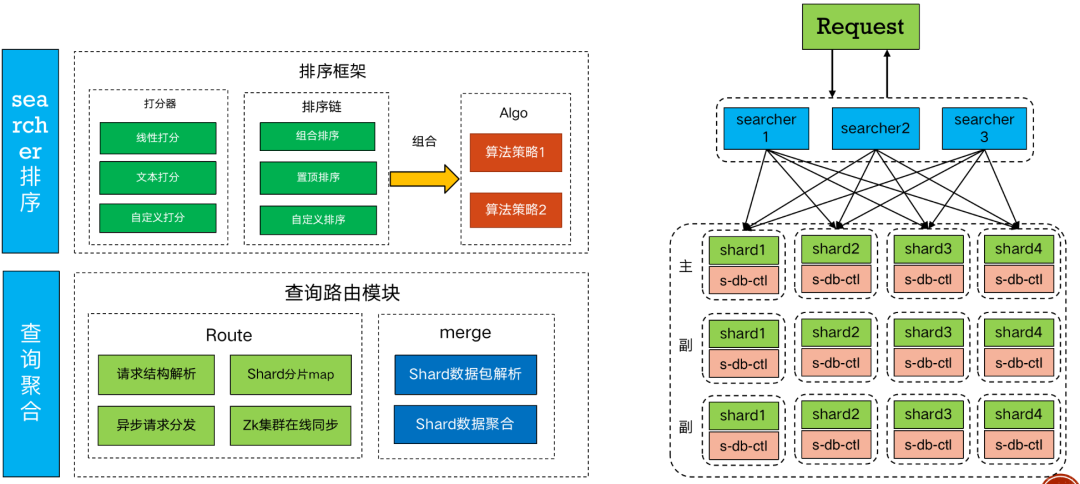
6.1 查詢路由
Route模組
Route模組主要功能是對請求的原始Query進行橫向切分,Route會根據在ZK路徑中儲存的分片資訊來對請求進行分片,比如請求中會帶最大召回截斷fulllimit,Route會根據fulllimit的值同時根據分片個數進行分配,然後分發到各個shard節點上去。
Merge模組
Merge模組是對shard的資料回包進行處理聚合和處理,對各個shard模組回包資料進行處理和聚合。
6.2 排序框架
searcher中排序框架,主要是對全域性的最後結果進行重新的排序,比如歌曲中會對最終的歌曲檢索統一進行打分,每個shard將對應的歌曲歸一化分數上傳給searcher模組,最終將分數進行統一的排序。同時,排序框架支援自定義開發的打分器和排序外掛。
7.Search客戶端和服務發現機制
Search的服務發現機制是溝通各個服務之間的核心模組,除了保證正常的RPC資料呼叫外,還要保證服務異常時候流量正常的切換的排程。Search服務發現功能模組:
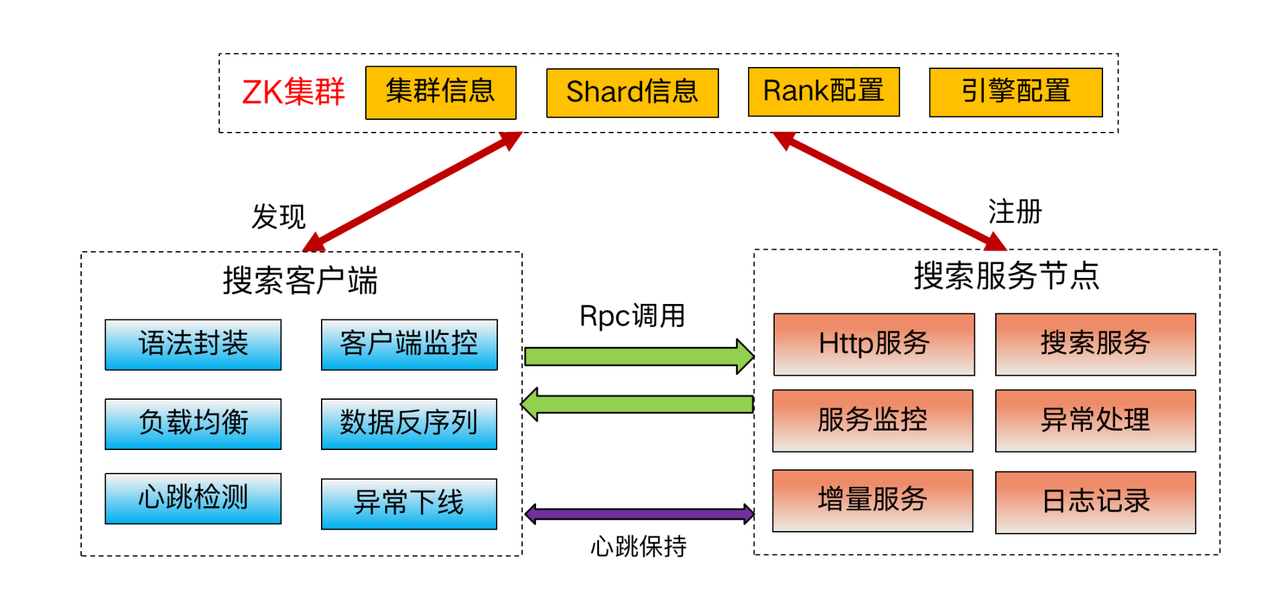
Search的服務發現包含兩部分,服務端和客戶端,透過ZK來互動,ZK上存放了每個叢集的機器IP和埠,客戶端來監聽該路徑的變化,當任意列表中IP刪除後,ZK回撥客戶端來感知,客戶端將流量從該臺機器切走。同時客戶端和服務端之間存在心跳,用於服務端服務卡死等異常情況下流量切流。
8.Search分散式節點的設計
帶有狀態的分散式系統最複雜的莫過於對於異常的處理了,包括資料的更新和節點異常的處理,對於Search來言資料的更新會導致節點的上下線,包括狀態的變化,而叢集的擴縮容會導致各個節點劇烈變化帶來異常,同時某個節點出了問題,也需要叢集智慧進行處理和路由,所以前期必須設計一套可靠的處理機制。
8.1 各個節點的設計
shard和searcher的節點是整個Search系統中的重中之重,首選需要設計一個合理的層次結構來元件整體的分散式系統。
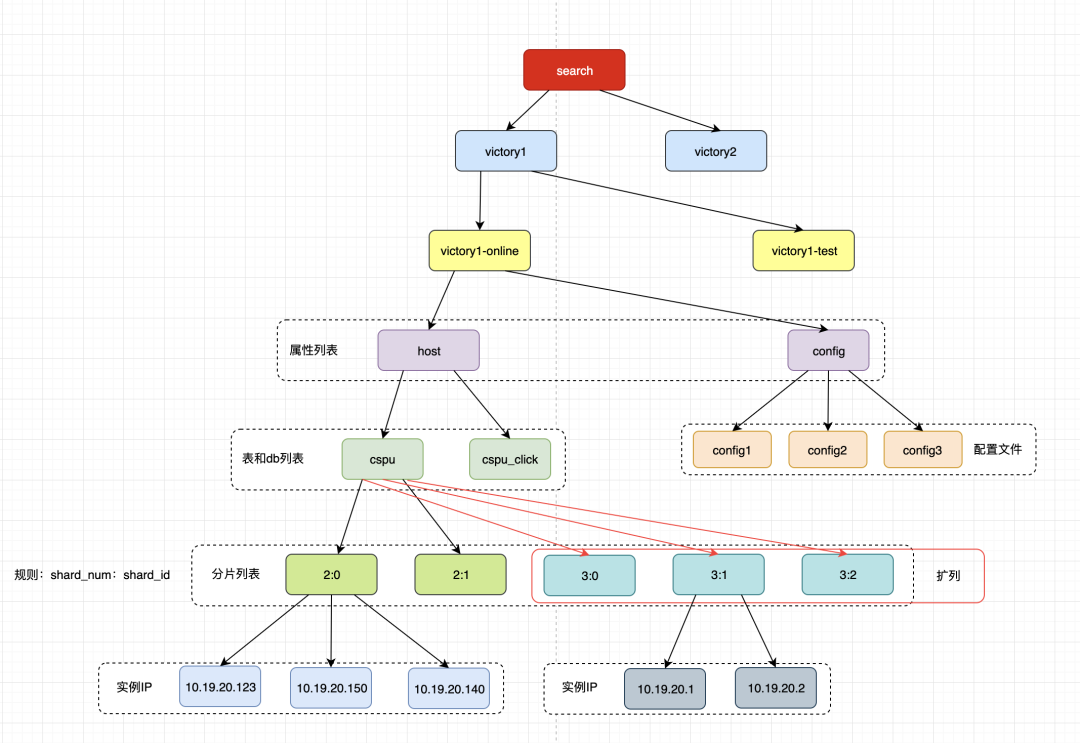
上圖是shard節點在ZK中的路徑分佈,按照叢集名應用名逐層分佈,在路徑的末尾節點存放的是每個shard的自己的分片資訊,首先是總的分片,第二位是第幾個分片的ID,該路徑下注冊的是所有shard的叢集IP和埠列表。searcher服務透過監聽這個路徑來獲取當前分發的具體分片數,已經對應的分片ID。
當需要擴容的時候,新的節點服務更新完資料後將自己的對應IP和埠註冊到新的節點上,隨著老的分片機器逐步更新資料到新的分片中,對應的老的節點中分片叢集IP越來越少,最後逐步全部遷移到新的節點中。這是完成了擴容,同理縮容的時候shard節點反向操作完成縮容。
8.2 shard節點和searcher節點的請求設計
在shard的節點設計中沒有進行區分主副本,各個副本之前都是有請求流量,之所以這麼考慮是因為提高機器利用率,只是簡單副本價值不大,所以所有副本權重平衡全部接流量。
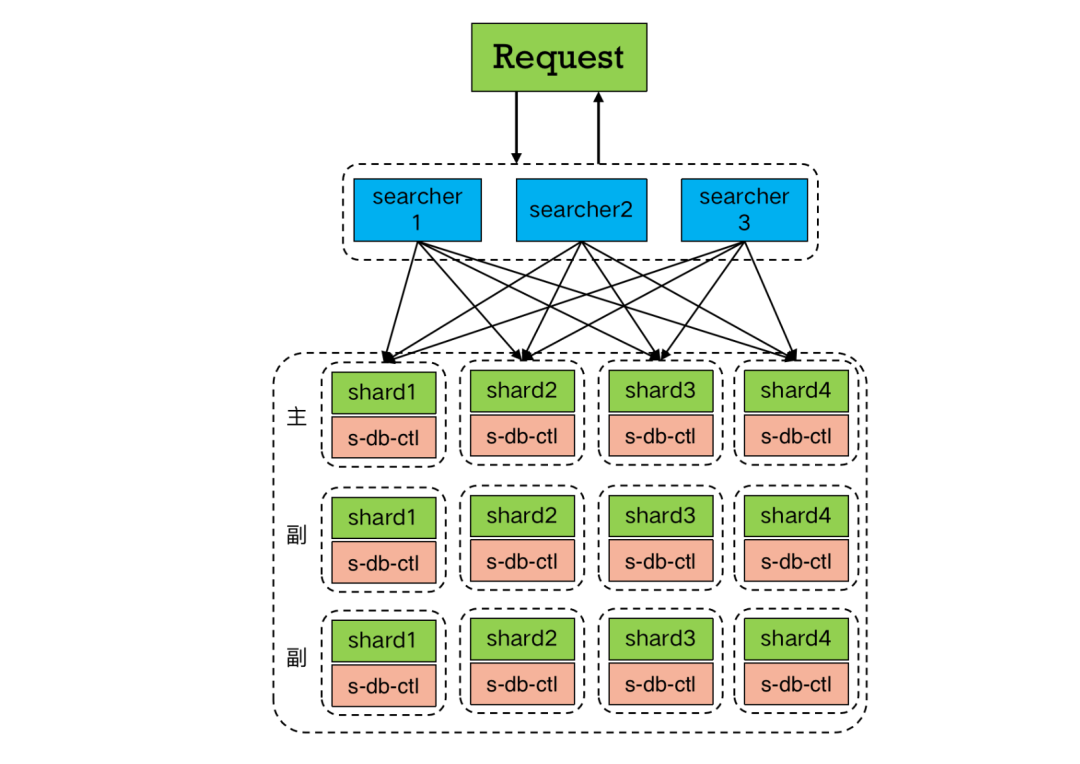
部署的時候,每一行是一個完整的資料集合,也是整體的一個最小請求行。而每一列是相同的資料集合,沒有主從之分,任何一個節點上面都有流量。當其中一個節點出了問題,比如節點崩潰,程式退出,在崩潰的時候shard端內部機制會在崩潰前主動進行下線,那麼searcher會將流量自動分發到剩餘的shard列節點中。
9.Search分散式資料流的設計
Search是有狀態的檢索服務,會有一直寫入的實時資料也有每天或者每小時更新的離線資料到引擎中,資料的可靠更新非常重要,對於分散式而言,各個分片的產出更新和實時資料的寫入都是非常重要的一環。
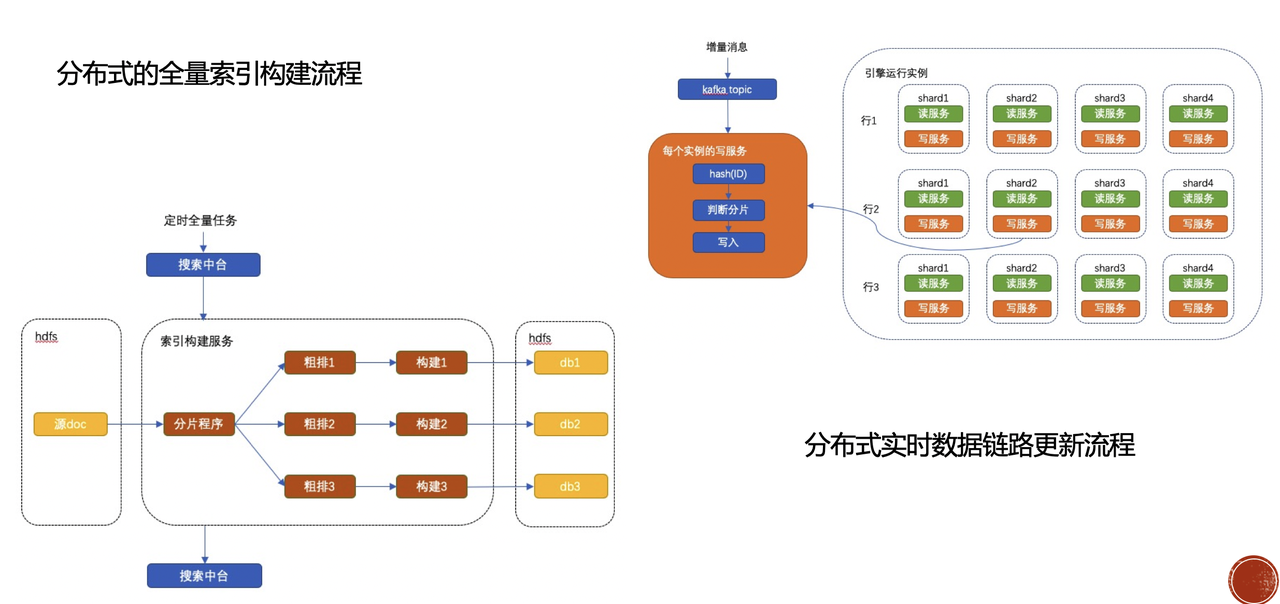
引擎分為實時和離線,在引擎的構建系統中會根據中臺中設定的總分片數來對原始資料進行平均分片,分片邏輯是根據每條資料的主鍵ID取Hash然後同餘,然後給構建系統進行構建索引,最後構建完的索引統一放在Search的HDFS路徑下。
實時資料透過Kafka彙總後,各個shard分片會統一消費Kafka中的資料,然後根據資料中的主鍵ID進行Hash後同餘判斷是不是自己所在的分片最後判斷是否寫入自己所在的索引。
對於一致性的處理,因為同一個shard分片中的多個副本中的消費速度不同,理論上只能保證同一個分片中多個副本的最終一致性,即存在某一個時刻有一個資料先到一個分片中那一瞬間優先檢索出來,而同樣的搜尋詞可能在其他分片中檢索不出來,不過這種情況幾乎會感知不到,因為多個副本的消費速度都是在每秒處理幾萬到十萬級別的資料,也就是說Search增量寫入能力單條都在1ms以下,除非出現其中一個節點網路問題或者磁碟異常情況會出現寫入出現問題,最終出現某些節點資料檢索異常,不過這些異常都會透過報警及時報警,進行節點處理。
10.總結
本篇文章主要是對搜尋引擎分散式的設計和落地做了總結,主要的幾個重要部分是,如何設計一套有狀態的分散式系統,其中最主要的核心部分是如何對各個節點的狀態變化做處理,以及合理的對資料進行分片和處理。其中ZK的路徑節點設計,自動擴縮容的實現,客戶端的服務發現,狀態感知功能,都是其中核心部分。
來自 “ 得物技術 ”, 原文作者:蘇黎;原文連結:http://server.it168.com/a2022/1102/6772/000006772082.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 搜尋引擎分散式系統思考實踐分散式
- 分散式搜尋系統的設計分散式
- 57_初識搜尋引擎_分散式搜尋引擎核心解密之query phase分散式解密
- [技術思考]分散式儲存系統的雪崩效應分散式
- 分散式搜尋引擎Elasticsearch的架構分析分散式Elasticsearch架構
- 分散式系統設計中的併發訪問解決方案 | 得物技術分散式
- 載均衡技術全解析:Pulsar 分散式系統的最佳實踐分散式
- 得物技術多興趣召回模型實踐模型
- ElasticSearch分散式搜尋引擎——從入門到精通Elasticsearch分散式
- NLP技術如何為搜尋引擎賦能
- 中文搜尋引擎技術揭密:中文分詞中文分詞
- 開源搜尋技術的核心引擎 —— Lucene
- 得物技術淺談深入淺出的Redis分散式鎖Redis分散式
- 分散式搜尋引擎Elasticsearch基礎入門學習分散式Elasticsearch
- 有贊搜尋系統的技術內幕
- 得物技術時間切片的實踐與應用
- elasticsearch(五)---分散式搜尋Elasticsearch分散式
- 系統效能提升利刃 | 快取技術使用的實踐與思考快取
- 後端技術雜談2:搜尋引擎工作原理後端
- 搜尋引擎-03-搜尋引擎原理
- 商家視覺化埋點探索和實踐|得物技術視覺化
- 前端監控穩定性資料分析實踐 | 得物技術前端
- 前端監控穩定性資料分析實踐|得物技術前端
- 訂單流量錄製與回放探索實踐|得物技術
- 得物技術 NOC—SLA C 端業務監控實踐
- Elasticsearch線上搜尋引擎讀寫核心原理深度認知-搜尋系統線上實戰Elasticsearch
- 得物Tech Leader對管理授權的思考是什麼?|得物技術管理集錦
- 微軟張若非:搜尋引擎和廣告系統,那些你所不知的AI落地技術微軟AI
- 【搜尋引擎】SOLR VS Elasticsearch(2019技術選型參考)SolrElasticsearch
- 網路偵察技術(一)搜尋引擎資訊收集
- Java效能測試利器:JMH入門與實踐|得物技術Java
- 大眾點評搜尋相關性技術探索與實踐
- 揭秘淘寶搜尋API:打造你的專屬購物搜尋引擎!API
- SpEL應用實戰|得物技術
- 直播開發app,實時搜尋、搜尋引擎框APP
- 得物直播低延遲探索 | 得物技術
- 搜尋系統核心技術概述【1.5w字長文】
- 海量資料搜尋---搜尋引擎