《Linux是怎麼樣工作的》讀書筆記
引言
這本書是個人看過的講作業系統底層裡面講的最通俗易懂的了,但是200多頁的內容確實講不了多深的內容,所以不要對這本書抱有過高期待,當一個入門書瞭解即可。
書籍介紹
- 原富士通一線Linux核心開發工程師基於十餘年經驗執筆,專業實用
- 聚焦Linux核心功能,簡明易懂地講解作業系統是怎樣工作的
- 198張示意圖幫助理解,詳略得當,為讀懂大部頭開路
- 結合大量實驗程式,邊動手操作邊學習,真實體驗系統執行過程
個人評價
內容比較基礎,但是有關Linux的內容都有涉及,另外作者用C語言程式對於作業系統的快取,交換記憶體,CPU程式管理器,固體硬碟和機械硬碟隨機讀寫和順序讀寫做驗證和測試的程式比較有意思。
但是不得不說能把作業系統這種抽象的東西講的生動形象實屬不易,作者在日本一線大廠(可以翻翻富士通相關資料)搞Linux核心開發專業程度也毋庸置疑,另外這本書的編排是由淺入深的挺不錯。
總結:非常難以定位的一本書,建議可以參考裡面的知識,根據相關內容深入即可。
資源
2022年3月出版的一本書所以沒有找到相關資源。
下面內容為隨書一些C語言模擬作業系統底層工作的一些程式,感興趣可以下載來看一下。
連結: https://pan.baidu.com/s/1eU65... 提取碼: pghr
筆記索引
注意筆記的索引並不是按照原書的結構組織,因為個人閱讀這本書是“倒著”讀的,結合目錄發現從後往前讀比較符合個人的理解習慣,也就是從外部儲存器到內部的工作機制比較符合個人的思考。
可以點選副標題跳轉到相關的節點。
常規的認識是知識由淺入深,其實有時候用難易交叉學習的方式可能更加符合人的學習習慣
主要介紹了機械磁碟和SSD硬碟的工作機制對比,順序讀寫和隨機讀寫之間的差別,這部分使用C語言模擬磁碟的讀寫效能比較有意思。
介紹了Linux和裝置互動的檔案系統設計,一共分為7層,當然書中只是簡單歸納,如果要深入需要閱讀更多資料。
講述了IO排程器和預讀機制的相關內容。
這一節講述如何快速的瞭解一個Linux檔案系統的設計方式,檔案系統的設計當然沒有不是幾頁紙就能講清楚的,但是對於我們大致瞭解Linux整體的設計思路入門還是不錯的。
如果你對筆記電腦或者桌上型電腦主機板等等基本配置瞭解,或者對整個作業系統的工作程式有一個大致的瞭解,這一節的內容完全可以跳過。
計算機的儲存器層級結構是越靠近CPU和CPU關係越密切價格越高容量越小,我們常見的儲存器,速度從快到慢的排序是:暫存器 -> 快取記憶體 -> 記憶體 -> 外部儲存器,這一節則針對這幾個儲存層級進行介紹。
之後會介紹關於轉譯後備緩衝區,頁面快取,緩衝區快取和Linux不常見也幾乎不使用的快取調優引數。
針對記憶體的管理是作業系統程式管理核心和關鍵所在,此部分介紹了關於記憶體管理的內容,記憶體管理是整本書介紹最為詳細的部分,個人認為核心是掌握 請求分頁和 寫時複製,這兩個特性被大量使用,除此之外理解記憶體的分配方式和分配的細節過程也是必要的。
另外這部分個人筆記在補充的同時也將內容拆分為上下部分:
第五部分:程式排程器
CPU程式排程目前主流的方式是兩種,第一種是像window那樣搶佔式排程,每一個CPU可能會出現排程時間分配不等的情況,而另一種是時間分片的方式,時間分片是Linux 常見的程式排程器,特點是每一個程式有近似相等的CPU使用權,在使用完成之後立馬交給下一個程式完成工作,使用分片的方式雖然可能導致一些重要任務延遲,但這樣的處理和排程方式使得系統最為穩定。
程式排程器本身很複雜,為了減少複雜性作者沒有做過多介紹,所以個人筆記內容也相對較少。
第零部分:計算機程式概覽
理解作業系統執行我們需要了解有關計算機資訊的基礎概念,我想如果有想法去研究作業系統底層多少對於計算機的基礎理念不會陌生,所以這一部分個人當作總結。
附錄
此部分是對於第一個部分物理磁碟的分配方式資料擴充套件,感興趣可以閱讀。
注意⚠:最後個人的筆記組織形式將會是難-易-難混雜的組織方式。
Linux與外部結構介紹
HDD磁碟介紹
機械磁碟從俯瞰的邏輯結構理解為類似一個同心圓的多個圈,從外層到內層進行編號,磁碟通過順時針順序編號,逆時針轉動磁碟,這樣處理是考慮查詢磁碟的時候可以直接按照順序掃描過去,磁頭前進方向就是編號遞增方向。
在下面的結構圖中,磁軌是每一個同心圓,而扇區指的是切割磁軌所形成的“扇面”,因為切割之後的樣子很像扇子的樣子所以被稱為扇區,掃描資料需要磁頭在磁軌上滑動,同時扇區會從0開始編號,一個編號對應一個扇區。
注意這是磁碟的俯檢視,也就是說線的部分是物理磁碟上的“溝壑”,而扇區就是編號內的塊。


下面是磁碟的側面切面圖,垂直疊加的盤通過一個磁碟一個磁頭的組合,通過多磁頭加快資料的處理速度。

注意在HDD磁碟中一個扇區讀寫最小單位為512位元組,而且每一個扇區都是512位元組,不管扇區是在外層還是內層。
⚠️注意:很多框架或者資料庫會把一次讀寫的大小設定為512位元組,因為512是最小讀寫單位所以可以不需要額外的維護可以保證讀寫的原子性。
磁碟大小計算
最早期磁碟可以通過下面的公式計算出整個磁碟的大小,因為磁軌和扇區的數量是一一對應的:
儲存容量=磁頭數磁軌(柱面)數每道扇區數*每扇區位元組數
這樣的設計有一個顯而易見的問題那就是無論扇區面積大還是小都是固定大小,很顯然外層的扇區資料被白白浪費了。
針對這樣的問題後續的機械磁碟出現了改進,這項技術叫做ZBR(Zoned Bit Recording,區位記錄)技術,這項技術根據每一圈的扇區來劃分大小,同一個磁軌圈內的扇區分佈和大小相同。
這意味著越是外層的扇區數量越多,而內圈則較少,在劃分之後密度均勻分佈。
由於磁碟扇區儲存形式的改進,定址模式自然也要跟著進步,如今的硬碟大多使用 、LBA(Logical Block Addressing)邏輯塊定址模式,瞭解這個定址模式才能瞭解磁碟的大小的計算方式。
然而現在HDD的磁碟讀寫受限在隨機讀寫速度上,過去HDD磁碟比較流行的轉速為7200轉和5400轉等等,區別的話是跑的快和跑的慢一點的螞蟻。
雖然有SAS硬碟能突破15000轉,並且現在還有研究團隊研究尋找不同材料或者其他方式突破磁碟物理轉速的限制(比如雙磁碟轉動的方式加快旋轉),然而始終無法突破機械磁碟的設計的物理限制。
市面上為什麼主流販賣7200轉的磁碟和5400的轉速的磁碟而不是別的磁碟?
一方面是7200的隨機讀寫效能經過測試是最佳的,同時討論一塊磁碟的效能不能看順序讀寫的速度而是要看隨機讀寫的速度。
針對機械磁碟存在一些物理壁壘,自東芝公司在1984年研究出快閃記憶體之後,快閃記憶體技術不斷進步,又經過了5年之後的1989年,SSD磁碟逐漸走進歷史舞臺。
⚠️注意:為什麼是7200轉和5400轉等等奇怪數字?
這兩個數字都要從3600說起,計算機的前十年幾乎所有的硬碟都是3600轉的,這個3600又是從哪裡來的呢?因為美國的交流電是60Hz的!於是就有了下面的公式:
- 60Hz × 1轉/Hz ×60秒/分鐘 = 3600轉/分鐘
- 5400 RPM = 3600 RPM × 1.5
- 7200 RPM = 3600 RPM × 2
另外還有一個原因是專利爭奪,你會發現轉速有15000卻沒有10000,9000,8000這種數字,其實都是因為整數和500的倍數轉速都被專利註冊了,但是專利註冊者估計沒想到轉速能破萬吧。
SSD磁碟介紹
SSD 的硬碟分為兩種,一種是基於快閃記憶體顆粒的快閃記憶體固態硬碟,另一種是DRAM 硬碟。
快閃記憶體顆粒的硬碟也就是我們現代膝上型電腦以及移動固態多數使用的硬碟,這種磁碟的最大優點是可以移動,同時資料的保護不依賴電源就可以儲存,在快閃記憶體顆粒中通常被分為 QLC,MLC,TLC,哪怕是壽命最短的QLC硬碟也有5-6年的壽命,而MLC壽命最長,保護得當往往可以十幾年正常工作。
⚠️注意:固態硬碟過去成本非常高所以機械磁碟是主流,廣泛普及也就這幾年時間,所以上面說的內容都是理想狀態。
在企業級的伺服器使用的固態中通常以MLC為主,SSD磁碟的最大特點是不像是HDD一樣受到物理衝擊有可能造成整塊磁碟不可用,但是SSD一旦損壞資料的修復成本很高或者說根本無法修復。
現在來看 SSD已經非常便宜了,但是HDD的大資料低成本儲存依然很受一些使用者歡迎。
DRAM是介於機械磁碟和固態硬碟中間的形式,其採用DRAM作為儲存單元,它效仿傳統硬碟的設計,可被絕大部分作業系統的檔案系統工具進行卷設定和管理,並提供工業標準的PCI和FC介面用於連線主機或者伺服器,但是最大問題應用範圍相對較窄。
HDD資料讀取方式
HDD的磁碟讀取資料順序如下:
- 裝置將需要讀寫的扇區和裝置號碼以及掃描多少個扇區告訴磁碟
- 移動磁頭和轉動碟片找到對應扇區。
- 讀取資料,把資料寫入緩衝。
- 如果所有的扇區掃描完成,讀取的操作則算是完成。
HDD磁碟讀寫的要點
從邏輯上來看計算扇區掃描位置和掃描數量計算處理速度是很快的,將扇區內的資料讀取或者寫入的資料也是相對較快的。
然而我們知道因為轉速限制的和磁頭和碟片物理掃描是非常慢的,整個讀寫的效能瓶頸是磁頭扇區定址和掃描磁碟所需的物理磁碟開銷以及最後帶來的隨機讀寫效能的權衡。
讀寫方式
磁碟掃描的幾種情況磁碟掃描的方式直接決定了資料處理讀寫速度:
- 順序掃描:順序掃描就是在一個磁軌上直接劃過連續的幾個扇區,一次掃描就可以獲取資料所以非常快。
- 多次連續順序掃描:連續順序掃描是針對連續的幾個扇區進行多次掃描,這個時間開銷主要是在碟片的轉動上,雖然依然比較快但是碟片轉動依然產生一定延遲。
- 隨機讀寫:隨機讀寫的開銷主要在磁軌來回定址上,此時不但可能會產生磁碟轉動,磁頭還需要尋找分散的扇區,隨機讀寫的效率是非常低的
⚠️注意:對於單次IO的訪問如果獲取的資料量超過磁碟請求資料量的上限,則會把請求由單次的順序讀寫,拆分為多次的順序掃描。
影響硬碟效能的因素
- 磁碟尋道時間:磁碟的平均尋道時間一般在3-15ms。
- 磁碟轉速:轉速越快
- 磁碟本身的讀寫效能:和磁碟的設計廠商也有關係,隨機讀寫強的HDD硬碟通常具備更好的IO效能,同時磁碟資料傳輸的越快傳輸量越大效果越好(廢話)。
機械磁碟需要關注尋道時間和旋轉延遲,當然HDD的羸弱的讀寫效能實際上大同小異。
通用塊層
通用塊層:指的是在Linux系統對於HDD和SSD的抽象。
HDD和SDD它們被稱為塊裝置。塊裝置的訪問方式有兩種,第一種是直接通過掛載的方式通過裝置檔案直接讀寫,第二種是根據檔案系統對於磁碟進行封裝以及提供引匯入口,當然大部分的軟體使用第二種方式。
由於不同型別的塊裝置處理方式不同,這些裝置的處理的需要依賴驅動程式的控制才能實現訪問,但是以我們日常使用Windows系統的經驗,不可能是一個塊裝置一個驅動程式,不然我們每一次加入新硬碟都要裝一遍驅動,這樣也太麻煩了。
那麼作業系統如何解決這個問題?這也就是通用塊層的作用了:

Linux和裝置的互動流程
這一個流程圖有很多細節可以瞭解,抽出任何一個層都能寫一篇長文出來,這裡我們以簡單瞭解IO排程器和磁碟預讀機機制為主。

IO排程器和預讀機制
在HDD中還有兩個十分影響效能的機制,IO排程器和預讀機制,但是注意針對HDD的預讀要比 SSD的預讀效果要好很多,因為有時候因為排序和預讀容易導致SSD的負面優化。
⚠️注意:有時候我們升級老裝置將機械磁碟換固態的時候重灌系統有可能出現黑屏,這是因為部分舊主機板會通過BIOS對機械磁碟調優,類似對於磁碟“預熱”,然而這種預熱會影響固態的啟動,所以出現類似情況可以檢查BIOS是否有勾選類似的加速機械磁碟啟動的選項。
IO排程器
IO排程器:是針對塊裝置訪問的時候將請求積攢到一定的時間之後在進行一次請求。
所以針對IO排程器主要有下面兩個重要的工作:
- 合併:把對於多個扇區的訪問IO請求合併為一個請求。
- 排序:因為每個扇區都有編號,IO排程器會把連續的扇區訪問的IO進行排序之後再進行訪問,使得磁碟掃描更加趨近順序掃描。
⚠️注意:IO排程器一般針對併發執行緒讀寫或者非同步IO過程中等待IO結果的時候使用IO排程器,
預讀機制
磁碟的磁頭在掃描資料的時候,不會只掃描裝置要求的幾個扇區,而是會多掃描周邊的扇區,注意這個預讀只有在順序掃描的時候發揮作用,當預讀機制生效的時候如果發現預讀的扇區在下一次訪問不會用到,直接丟棄即可。
Linux檔案系統設計
簡單的檔案系統如何設計
從最簡單的角度考慮設計基本的檔案系統我們可以用一個常規的檔案讀寫舉例。
最簡單的檔案系統包含下面的處理流程:
- 首先檔案資料從0開始記錄,每一 個檔案在檔案系統中有名稱,大小和位置三條基本資訊。
- 如果沒有檔案系統的輔助我們需要自行考慮檔案的磁碟儲存位置,需要從磁碟區域1到區域10根據檔案的大小儲存到塊裝置的對應位置,並且需要記錄當前塊的檔案寫入開始結束和結束為止,記錄儲存的資料大小。

為什麼會有“態”?
顯然在早期的單程式單使用者作業系統中,是不存在態這個概念的。然而隨著程式和使用者的出現,當時的計算機面臨著一個重要問題,就是如何限制不同程式的操作的許可權。
並不是所有的程式都能允許所有的外部使用者操作的,因為不知道未來會出現哪些新的程式運作,所以工程師為了讓系統和使用者的程式可以分開,就準備讓一些危險的操作只允許作業系統的程式去做,使用者程式如果要做一些危險操作必須經過作業系統的“盤問”,之後再由作業系統去做。
最後“態”被設計為下面的形式:

模式切換
下面是Linux中使用者態核心態硬體三者的關係:
使用者態
是使用者看得見的操作,比如想要讀取某一個檔案或者想要某一個檔案改幾個字,使用者傳送的這些指令通過核心轉為機器碼命令,然後在核心態對於磁碟進行IO操作。
也就是說 使用者模式:傳送指令操作 -> 核心模式,翻譯使用者指令為塊裝置可以識別的命令 -> 硬體。
在上面設計的最簡單的檔案系統中,使用者模式切換到核心模式進行檔案管理只需要關心檔案大小,檔案位置和檔名稱。
核心態
只有擁有系統操作許可權的作業系統才有權進行操作和訪問,一般都是執行一些系統的核心工作。
硬體
硬體又被稱為外部儲存,這些操作只會和核心互動。
Linux檔案系統結構
Linux的檔案系統是樹狀結構設計,檔案系統可以支援不同格式,不同檔案系統的差別主要在最大支援操作檔案大小,檔案系統本身大小以及各種檔案操作速度差別上。
檔案系統存在ext2、ext3、ext4,它們的檔案大小和儲存形式和儲存的位置都有差別,那麼Linux是如何處理的呢?
Linux檔案系統將使用介面的形式將檔案IO操作進行抽象,無論檔案系統的結構形式如何變動,最終都是通過和下面提到相關的介面來完成互動的。
吐槽:有點像是設計模式的外觀模式
- 建立刪除:
create/unlink - 開啟關閉:
open/close - 開啟檔案讀資料:
read - 開啟檔案寫資料:
write - 開啟檔案移動到指定位置:
lseek - 特殊檔案系統特殊操作:....
這一點和Linux塊裝置管理類似,在Linux與外部結構介紹中提到了塊裝置對於檔案系統提供了通用層塊進行抽象,對於使用者模式角度所看到的單塊裝置之間是沒有差別的,而真正的驅動處理出現在核心態中。
讀取檔案資料流程
在Linux中讀取檔案的流程如下:
- 各個檔案系統通用處理。
- 檔案系統專用處理,請求系統呼叫對應處理指令。
- 裝置驅動執行讀寫資料操作。
- 塊裝置驅動完成讀寫指令操作。
從邏輯結構來看整個互動流程很簡單,然而實際上這都是Linux的工程師們不斷努力的成果。
資料和後設資料
在Linux資料的種類分為後設資料和資料,後設資料和檔名稱,檔案大小,檔案位置相關,這些引數用於核心態讀取塊裝置作為參考,而資料則是我們日常使用的視訊資料,文字資料。
後設資料除了上面的資訊種類之外還包含下面的內容:
- 種類:判斷檔案是儲存資料的普通檔案還是目錄還是其他檔案,也就是檔案型別。
- 時間資訊:檔案的建立時間、最後一次訪問時間、最後一次修改時間。
- 許可權資訊:Linux許可權控制使用者訪問。
我們可以通過df命令和相關引數可以詳細的瞭解檔案系統的引數和執行情況,df是重要的運維命令,可以通過它瞭解到磁碟的容量情況。
g@192 ~ % df
Filesystem 512-blocks Used Available Capacity iused ifree %iused Mounted on
/dev/disk3s1s1 965595304 29663992 73597064 29% 500637 367985320 0% /
devfs 711 711 0 100% 1233 0 100% /dev
/dev/disk3s6 965595304 48 73597064 1% 0 367985320 0% /System/Volumes/VM
/dev/disk3s2 965595304 1034480 73597064 2% 2011 367985320 0% /System/Volumes/Preboot
/dev/disk3s4 965595304 31352 73597064 1% 48 367985320 0% /System/Volumes/Update
/dev/disk1s2 1024000 12328 985672 2% 3 4928360 0% /System/Volumes/xarts
/dev/disk1s1 1024000 15040 985672 2% 27 4928360 0% /System/Volumes/iSCPreboot
/dev/disk1s3 1024000 1240 985672 1% 39 4928360 0% /System/Volumes/Hardware
/dev/disk3s5 965595304 859395304 73597064 93% 1212174 367985320 0% /System/Volumes/Data
/dev/disk6s1 1000179712 807402240 192777472 81% 3153915 753037 81% /Volumes/Untitled
/dev/disk7s1 1953443840 1019557888 933885952 53% 497831 455999 52% /Volumes/Extreme SSD
map auto_home 0 0 0 100% 0 0 100% /System/Volumes/Data/home
//GUEST:@Windows%2011._smb._tcp.local/%5BC%5D%20Windows%2011 535375864 212045648 323330216 40% 26505704 40416277 40% /Volumes/[C] Windows 11.hidden
/dev/disk5s2 462144 424224 37920 92% 596 4294966683 0% /private/var/folders/wn/dvqxx9sx4y9dt1mr9lt_v4400000gn/T/zdKbGy磁碟配額
容量配額是磁碟管理中的核心,對於Linux檔案管理系統來說有下面幾種磁碟的配額方式:
- 使用者配額:使用者配額通常指的是/home,通常每一個使用者家目錄有固定的額度配比
- 子卷配額:限制名字為子卷的單元可用容量。
- 目錄配額:可以通過特定目錄的可用容量,比如共享目錄的使用者可用容量,ext4和xfs可以設定目錄配額。
除了對於針對不同型別的配額之外,還需要考慮系統正常執行運作的系統配額,也就是說如果給使用者和系統按照一刀切的方式配比100%的方式劃分磁碟是一件危險的操作,對於一塊磁碟保持不超過80%是比較常見設定。
檔案系統意外恢復
資料管理最常見的問題是資料不一致,諸如在沒有完成寫入的時候突然斷電,這種情況並不算特別少見,Linux提供了下面的兩種方式解決斷電資料狀態不一致的問題:
- 日誌:通常出現在ext4和xfs的檔案系統。
- 寫時複製:通常為btrfs的實現。
日誌方式:
使用日誌處理情況要多一些,因為日誌的方式具備一定的可讀性也方便恢復,操作主要分為下面兩個步驟:
- 資料修改之前把原子操作記錄到日誌當中。
- 當機恢復的時候根據日誌記錄內容還原檔案狀態。
如果異常情況發生在日誌記錄之前,可以直接丟棄寫入一部分的日誌並且回滾,當作檔案狀態沒有更改過。而如果異常狀態發生在原子操作的過程之後,則根據日誌的記錄把操作重新執行一遍即可。
現代檔案系統更多的是來自於系統的BUG產生的資料不一致問題,現代多使用SSD硬碟,SSD硬碟寫入都非常快基本不會出現寫入時資料不一致問題。
寫時複製方式:
不同檔案系統對於寫時複製的實現不同,介紹寫時複製需要了解一些傳統的比如ext4和xfs的檔案系統工作機制。
這些檔案系統在檔案建立之後就會固定存放到磁碟的某個位置,哪怕刪除或者更新檔案內容也只是在原有空間上進行操作。
而btrfs的寫時複製的檔案系統管理方案則比較特殊,建立之後的檔案每次更新都會放到不一樣的位置。
寫時複製就是說更新和寫入都是一次類似“複製”的操作,當新資料寫入完成再把引用更新即可,原有的內容只要不被新檔案覆蓋還是可以被找到。
如果在寫入的時候突然斷電怎麼辦?
這時候資料是在另一個地方操作的,資料寫入到一半也不會對舊資料有影響,如果是其他操作情況下比如寫入剛完成沒有更新引用的情況,此時只需要把引用更新一下即可。總之就是怎麼樣都不會影響原來的資料。
⚠️注意:其實磁碟本質上是沒有刪除這個概念的,計算機所謂的刪除只是使用者程式無法通過常規操作訪問被刪除的檔案所在地址而已,但是通過一些特殊處理還是有辦法通過檔案碎片恢復原始檔案的。
無法恢復的意外
如果是檔案系統的BUG無法恢復的意外,對於不同的檔案系統來說處理方案也不同。
幾乎所有的檔案系統都有通用的fsck命令進行恢復,但是這個命令定義是有可能恢復資料狀態。
下面是關於這個命令的介紹:
fsck 命令
Linux fsck(英文全拼:file system check)命令用於檢查與修復 Linux 檔案系統,可以同時檢查一個或多個 Linux 檔案系統。
語法
fsck [-sACVRP] [-t fstype] [--] [fsck-options] filesys [...]
引數 :
- filesys : device 名稱(eg./dev/sda1),mount 點 (eg. / 或 /usr)
- -t : 給定檔案系統的型式,若在 /etc/fstab 中已有定義或 kernel 本身已支援的則不需加上此引數
- -s : 依序一個一個地執行 fsck 的指令來檢查
- -A : 對/etc/fstab 中所有列出來的 partition 做檢查
- -C : 顯示完整的檢查進度
- -d : 列印 e2fsck 的 debug 結果
- -p : 同時有 -A 條件時,同時有多個 fsck 的檢查一起執行
- -R : 同時有 -A 條件時,省略 / 不檢查
- -V : 詳細顯示模式
- -a : 如果檢查有錯則自動修復
- -r : 如果檢查有錯則由使用者回答是否修復
案例:
檢查 msdos 檔案系統的 /dev/hda5 是否正常,如果有異常便自動修復 :
fsck -t msdos -a /dev/hda5fsck 命令存在的問題
然而這個命令看似很強大,但是存在一些很嚴重的效能問題:
- 遍歷檔案系統並且檢查檔案系統的一致性同時還會修復不一致的地方,檔案系統非常龐大恢復速度會長達幾個小時或者幾天。
- 如果中途恢復失敗,崩潰的不只是機器。
- 修復成功不一定會恢復到期望狀態,同時對於一切不一致的資料和後設資料都會刪除。
計算機儲存層次簡析
儲存元件介紹
首先我們來看看不同儲存層次的介紹,包括上面提到的暫存器,快取記憶體,記憶體以及他們三者之間的關係。
我們從整體上看一下儲存層次結構圖:

注意⚠️:小字這些引數放到現在都是比較老的了,我們只需要簡單理解從左到右速度由最快到快到慢到最慢的遞進。
快取記憶體:
快取記憶體是位於CPU與主記憶體間的一種容量較小但速度很高的儲存器。
記憶體的資料被讀取之後,資料不會直接進入暫存器而是先在快取記憶體進行儲存,快取記憶體通常分為三層,讀取的大小取決於快取塊的大小,讀取速度取決於不同層級快取記憶體的容量。
快取記憶體的執行步驟如下:
- 根據指令把資料讀取到暫存器。
- 暫存器進行計算操作。
- 把運算結果傳輸給記憶體。
在上面的三個步驟中暫存器和快取記憶體基本沒有傳輸消耗,但是記憶體的傳輸就就慢不少了,所以整個流程運算的瓶頸也是記憶體的傳輸速度,這也是為什麼使用快取記憶體來解決暫存器和記憶體之間的巨大差異。
快取記憶體分為L1,L2,L3,在講述理論知識之前,這裡先舉一個形象一點的例子方便理解:
- L1 cache:就好像需要工具在我們的腰帶上可以隨時取用,所以要獲取它的步驟最簡單也最快
- L2 cache:就好像需要的工具放到工具箱裡面,我們如果需要獲取要先開啟工具箱然後把工具箱的工具掛到腰上才能使用。為什麼不能從工具箱取出來再放回去呢?其實思考一下如果你需要頻繁使用那得多累呀。另外工具箱雖然比腰上的空間大不少,但是也沒有大特別多,所以L2 cache 沒有比L1 cache大多少。
- L3 cache:L3相比L1和L2要大非常多,相當於一個倉庫,我們獲取資料需要自己走到倉庫去找工具箱然後放到身邊,然後再像是上面那樣執行一次,雖然倉庫容積很大,但是需要操作的步驟最多,時間開銷也最大。
L1 cache下面是L2 cache,L2下面是 L3 cache,根據上面介紹L2和L3都有跟L1 cache一樣的問題,要加鎖,同步,並且L2比L1慢,L3比L2慢。
這裡我們再舉例簡述快取記憶體的內部操作:
假設需要讀取快取塊是10個位元組,快取記憶體為50個位元組,R0、R1的暫存器總計為20個位元組,當R1需要讀取某個地址的資料時,在第一次讀取資料的時候將10位元組先載入到快取記憶體,然後再由快取記憶體傳輸到暫存器,此時R0有10位元組的資料,如果下次還需要讀取10個位元組,同樣因為快取記憶體發現快取中有相同資料,則直接從快取記憶體讀取10個位元組到R1中。
那麼如果此時R0資料被改寫會怎麼辦?首先CPU會先改寫暫存器的值,改寫暫存器值之後會同時改寫快取記憶體的值,此時如果存在從記憶體進來快取塊資料,在快取記憶體中會先標記這些值,然後快取記憶體會在某一個時刻把改寫的資料同步到記憶體中。
如果快取記憶體不足系統會發生什麼情況?
首先快取記憶體會根據快取淘汰機制淘汰末端最少使用的快取記憶體,但是如果快取記憶體的“變髒”速度很快並且快取記憶體的容量總是不足,此時就會發生記憶體頻繁寫入快取記憶體並且不斷變動快取記憶體的情況,此時就有可能會出現可感知的系統抖動。
注意⚠️:本部分討論的內容全部為回寫,改寫的方式分為直寫和回寫,回寫在快取記憶體中存在一定的延遲,利用時間積累的方式定時改寫的方式進行記憶體的同步重新整理,而直寫的方式則會在快取記憶體改變的那一刻立刻改寫記憶體的值。
如何衡量訪問的侷限性呢?
幾乎所有的程式都可以分為下面兩種情況:
- 時間侷限性:在一定的時間內快取可能被訪問一次,但是可以隔一小段時間再一次訪問,常見的情況是一個迴圈中不斷取值。
- 空間侷限性:訪問一段資料的同時還需要訪問它周邊的資料情況,有點類似磁碟的預讀機制。
如果程式可以衡量並且把控好上面兩個點,那麼基本可以認為是一款優秀的程式,但是現實情況往往不是如此。
小結:
- 快取記憶體是利遠遠大於弊的一個設計。
- 資料不一致和資料同步快取記憶體效能影響的主要問題。
- 快取記憶體一旦被佔滿,則系統處理速度會出現一定延遲。
暫存器:
暫存器包括指令暫存器(IR)和程式計數器(PC),它屬於中央處理器的組成部分,暫存器中包含指令暫存器和程式計數器以及累加器(數學運算)。
ARM走的是簡單指令集,X86走複雜指令集,雖然X86從現在來看是走到了盡頭,但是依然佔據市場主導地位。
複雜指令集會包含非常多的暫存器完成複雜運算,比如下面一些暫存器:
- 通用暫存器
- 標誌暫存器
- 指令暫存器
如果有感興趣可以將暫存器作為深入X86架構的入口。
記憶體:
記憶體不僅僅是我們熟知的電腦記憶體,從廣義上來說還包括只讀儲存,隨機儲存和快取記憶體儲存。
這裡可能會有疑問為什麼記憶體使用的最多卻不如暫存器和快取記憶體呢?
因為記憶體不僅僅需要和CPU通訊還需要和其他的控制器和硬體打交道,管的事情越多效率自然越低,同時如果記憶體吃緊CPU還需要等待記憶體傳輸,當然這也可以反過來解釋為什麼需要快取記憶體和暫存器。
除了上面提到的原因之外,還有比較關鍵的原因是主機板的匯流排頻寬是有上限的並且需要共享給各路使用,比如南橋和其他的一些外接裝置等等,同時匯流排也是需要搶佔的,並不是分片使用。
其他補充
轉譯後備緩衝區
下面的內容來自百科的解釋:
轉譯後備緩衝器(英語:Translation Lookaside Buffer,首字母縮略字:TLB),通常也被稱為頁表快取、轉址旁路快取,為CPU的一種快取,由記憶體管理單元用於改進虛擬地址到實體地址的轉譯速度。
目前所有的桌上型及伺服器型處理器(如 x86)皆使用TLB。TLB具有固定數目的空間槽,用於存放將虛擬地址對映至實體地址的標籤頁表條目。為典型的結合儲存(content-addressable memory,首字母縮略字:CAM)。
其搜尋關鍵字為虛擬記憶體地址,其搜尋結果為實體地址。如果請求的虛擬地址在TLB中存在,CAM 將給出一個非常快速的匹配結果,之後就可以使用得到的實體地址訪問儲存器。如果請求的虛擬地址不在 TLB 中,就會使用標籤頁表進行虛實地址轉換,而標籤頁表的訪問速度比TLB慢很多。
有些系統允許標籤頁表被交換到次級儲存器,那麼虛實地址轉換可能要花非常長的時間。
程式如果想要訪問特殊的資料,可以通過下面提到的方式訪問邏輯地址:
- 對照物理頁表通過查表的方式把虛擬地址轉實體地址。
- 通過訪問對應的實體地址尋找實際的實體地址。
注意⚠️:這裡的操作類似二級指標的訪問操作,如果想要快取記憶體發揮作用必須是一級指標的查詢才有意義,但是二級指標的查詢是沒有太大意義的。
轉譯後備緩衝器說白了就是用於加速虛擬地址到實體地址轉化的一塊特殊空間,目的是為了提高多級巢狀對映查詢的速度。
頁面快取
注意上面提到的內容是頁表快取,這裡是頁面快取。
頁面快取的作用是什麼呢?我們都知道外部的硬體儲存速度是最為緩慢的,通常應用程式操作硬碟中的資料都是預先把資料載入到記憶體再進行操作,然而資料並不是直接從磁碟拷貝到記憶體的,而是在記憶體和外部儲存裝置之間多了一層頁面快取。
頁面快取的讀取步驟如下:
- 程式讀取磁碟文字資料,尋找到相關資料之後將內容載入到頁面快取。
- 把頁面快取的內容複製到記憶體中,此時物理資料和記憶體以及頁面快取資料一致。
- 如果需要改寫檔案文字資料,首先會通知頁面快取標記自己為“髒頁”。
- 如果記憶體不足則空出空閒的頁面快取給記憶體使用。
- 如果頁面快取和記憶體都不足就需要重新整理“髒頁”空出空間給記憶體繼續使用。
- 通常情況下頁面快取會定期重新整理快取回寫到磁碟中保持資料同步。
另外需要注意如果頁面快取一直沒有程式訪問,頁面快取會一直“膨脹”,如果頁面快取和記憶體一直不夠用,就會不斷的回寫髒頁並且產生效能抖動問題。
緩衝區快取
緩衝區快取很容易和頁面快取搞混,我們只需要簡單理解是對原始磁碟塊的臨時儲存,也就是用來快取磁碟的資料,比如裝置檔案直連外部的儲存裝置,U盤讀寫和外接磁碟的讀寫等等,這些讀寫通過快取區快取進行管理。
需要注意緩衝區快取通常不會特別大(20MB 左右),這樣核心就可以把分散的寫集中起來,統一優化磁碟的寫入,比如可以把多次小的寫合併成單次大的寫等等。
Linux中調優引數
瞭解上面各個元件的內容和細節之後,我們來看幾個簡單的Linux調優引數。
回寫週期
回寫週期可以通過sysctl 的vm.dirty_writeback_centisecs 引數調整,但是注意這個值的單位比較特殊,釐秒,這個引數預設設定為500,也就是5秒進行一次回寫。
釐秒(英文:centisecond,符號cs),1釐秒 = 100分之1秒。
當然除非為了實驗瞭解否則不要把這個值設定為0。
除了這個引數之外,還有個百分比的引數,當髒頁的數量超過百分比之後就會觸發髒頁回寫的操作防止效能劇烈抖動,下面案例的10代表了10%。
下面是這個引數的內容:
vm.dirty_backgroud_ratio = 10如果想要使用位元組的形式控制這個閾值,可以通過引數vm.dirty_background_bytes指定,如果這個引數為0則代表不開啟這個配置。
髒頁不允許一直存在,如果髒頁積攢到一定的量的時候會核心會觸發回寫操作,可以通過vm.dirty_ratio 控制,當到達此百分比核心會阻塞使用者程式並且把所有的髒頁回寫。
vm.dirty_ratio除了設定百分比引數也可以通過位元組限制,引數是vm.dirty_bytes。
除了這些不太常用的引數之外,還有一些更為特殊的調優引數,
比如配置用於清空所有的頁面快取的操作方法是向/proc/sys/vm/drop_caches 寫入3,為什麼是寫入3,這裡留給讀者自己尋找答案。
超執行緒
超執行緒(HT, Hyper-Threading)是英特爾研發的一種技術,於2002年釋出。超執行緒的技術可以把一個核心偽裝成兩個核心看待,同時對於單核心的CPU,也可以享受模擬雙核心的優惠,當然超執行緒技術不只是有好處,還有一個明顯的缺點是多執行緒搶佔以及執行緒上下文帶來的開銷,同時哪怕在最理想的情況下超執行緒的技術最多也只能提升 20% -30%的,但是這個優化對於當年技術實力有限的情況下的技術優化和效能提升效果是非常顯著的。
<s>從此牙膏廠走向了擠牙膏的不歸路</s>
小結
這部分內容更像是對於家用電腦常見的幾個核心組建進行稍加深入的介紹,學習這些內容不僅對於計算機的深入理解是必要的,對於我們日常選配電腦一些商家說明也能有更深理解。
在其他的補充部分介紹了三個快取,分別是轉譯後備緩衝,頁面緩衝,緩衝區緩衝,這三者雖然名字相近但是內部負責的工作差別還是比較大,介紹三者之後介紹了一些關於Linux的調優引數。
對於深入X86架構來說,理解各個暫存器的核心工作機制比較關鍵,而對於戰未來的ARM使用的精簡指令集對於整個生態發展更為合適。
Linux記憶體管理
簡單介紹
下面我們就來簡單介紹Linux記憶體管理的,在Linux中記憶體管理可以大致理解為三個部分:
- 核心使用的記憶體
- 程式使用的記憶體
- 可用記憶體(空閒記憶體)
其中除開核心使用的記憶體維持系統正常執行不能被釋放之外,其他均可以由作業系統自由支配。在Linux中擁有free命令來專門檢視記憶體的使用情況,執行的效果類似如下:
/opt/app/tdev1$free
total used free shared buffers cached
Mem: 8175320 6159248 2016072 0 310208 5243680
-/+ buffers/cache: 605360 7569960
Swap: 6881272 16196 6865076各個列的含義如下:
- total:系統搭載實體記憶體總量,比如上面為8G。
- free:表面可用記憶體。
- buff/cache:緩衝區快取和頁面快取,在計算機儲存層次簡析中提到了當記憶體不夠可以使用釋放快取騰出空間給記憶體使用。
- availiable:實際可以使用的記憶體,計算公式很簡單即
核心之外的可用總記憶體 - (free + buff/cache 最大可以釋放的記憶體)。
除了列資料之外還有一個swap的行,這個引數的含義將在後文進行介紹。
Linux除了free命令之外,還有sar -r命令,可以通過這個引數指定採集週期,比如-r 1就是1秒採集一次。
個人目前使用的電腦為Mac,雖然是類Unix系統但是沒有free相關的命令,為此可以使用下面的命令進行簡單的替代,但是不如free強大。
在Mac中使用top -l 1 | head -n 10檢視整體系統執行情況。
MacBook-Pro ~ % top -l 1 | head -n 10
Processes: 604 total, 2 running, 602 sleeping, 3387 threads
2022/04/15 17:29:57
Load Avg: 2.84, 3.27, 5.68
CPU usage: 6.8% user, 14.18% sys, 79.72% idle
SharedLibs: 491M resident, 96M data, 48M linkedit.
MemRegions: 168374 total, 5515M resident, 235M private, 2390M shared.
PhysMem: 15G used (1852M wired), 246M unused.
VM: 221T vsize, 3823M framework vsize, 0(0) swapins, 0(0) swapouts.
Networks: packets: 312659/297M in, 230345/153M out.
Disks: 788193/14G read, 161767/3167M written.除此之外,可以在Mac中使用使用diskutil list:
~ > diskutil list
/dev/disk0 (internal):
#: TYPE NAME SIZE IDENTIFIER
0: GUID_partition_scheme 500.3 GB disk0
1: Apple_APFS_ISC 524.3 MB disk0s1
2: Apple_APFS Container disk3 494.4 GB disk0s2
3: Apple_APFS_Recovery 5.4 GB disk0s3
/dev/disk3 (synthesized):
#: TYPE NAME SIZE IDENTIFIER
0: APFS Container Scheme - +494.4 GB disk3
Physical Store disk0s2
1: APFS Volume mysystem 15.2 GB disk3s1
2: APFS Snapshot com.apple.os.update-... 15.2 GB disk3s1s1
3: APFS Volume Preboot 529.6 MB disk3s2
4: APFS Volume Recovery 798.6 MB disk3s3
5: APFS Volume Data 455.3 GB disk3s5
6: APFS Volume VM 24.6 KB disk3s6
/dev/disk6 (external, physical):
#: TYPE NAME SIZE IDENTIFIER
0: GUID_partition_scheme *512.1 GB disk6
1: Microsoft Basic Data 512.1 GB disk6s1
/dev/disk7 (external, physical):
#: TYPE NAME SIZE IDENTIFIER
0: GUID_partition_scheme *1.0 TB disk7
1: Microsoft Basic Data Extreme SSD 1.0 TB disk7s1
下面是`free`和`sar`這兩個命令的輸出結果對應關係:
> - total : 無對應
> - free :kbememfree
> - buff/cache :kbbufferrs + kbcached
> - available:無對應
如果記憶體使用過多,系統為了空出記憶體可能出現強制 `kill` 某個程式的操作,此操作是隨機的並且無法被監控,商用機器上執行這種操作是十分危險的,所以有部分的商用機器會開啟一旦OOM直接把整個系統強制關閉的操作。
## 記憶體分配方式及問題
核心分配記憶體的時機大致有下面兩種:
1. 建立程式。
2. 建立程式之後進行動態記憶體分配。
在程式建立之後如果程式還需要核心提供更多的記憶體,則可以向核心發出記憶體的請求申請,核心收到指令之後,則劃分可用記憶體並且把起始結束的地址給程式進行使用。
但是這種要一點給一點的方式有下面幾個常見的問題:
- 難以執行多個任務。
- 訪問其他用途的記憶體區域。
- 記憶體的碎片化。
> 注意⚠️:記憶體不僅僅需要和CPU通訊還需要和其他的控制器和硬體打交道,分配記憶體給程式只是諸多工的專案之一。
**難以執行多工**
可以理解為程式頻繁的需要申請記憶體的情況,這時候核心需要不斷的操作分配記憶體給程式,整個任務相當於被單個程式給拖累了。
另外如果多個任務出現分配記憶體的區域剛好相同,此時需要要完成記憶體分配給那個程式任務,則另一個程式等待也是可以理解的。
**記憶體碎片化**
原因是程式每次獲取記憶體都需要了解這部分內容要涵蓋多少區域否則就不能獲取這些記憶體。
記憶體碎片化的另一個重大問題是明明有很多富裕的記憶體但是卻拿不出一塊完整連續的空間給程式使用,導致不斷的回收和分配操作。
**訪問其他用途的記憶體區域**
這種情況程式訪問被叫做缺頁訪問中斷,在後續的內容會進行介紹。
## 虛擬地址和實體地址
為了解決上面的問題,作業系統使用了虛擬內容和實體記憶體的方式進行記憶體管理。
我們需要了解三個概念:**地址空間、虛擬地址、實體地址**。
地址空間:指的是可以通過地址訪問的範圍都統稱為地址空間。
虛擬地址:虛擬地址指的是程式無法直接訪問到真實的實體記憶體地址,而是訪問和實際記憶體地址對映的虛擬記憶體地址,目的是為了保護系統硬體安全。
實體地址:也就是我們實際記憶體對應的實際的實體地址。
這裡舉一個簡單的例子:如果核心給程式分配100地址的虛擬記憶體地址,那麼這個虛擬記憶體地址實上可能會指向實際的600實體地址。
**頁表**
完成虛擬地址到實體地址的對映依靠的是頁表,在虛擬記憶體當中所有的記憶體都被劃分為頁,一個頁對應的資料條目叫做**頁表項**,頁表項記錄實體地址到虛擬地址的對映關係。
在x86-64的架構中一個頁的大小為4KB,程式在記憶體是有固定的起止地址的,那麼如果出現超出地址的頁訪問,也就是訪問了沒有虛擬地址和實體地址對映的空間會出現什麼情況呢?
如果出現越界訪問,那麼此時CPU會出現**缺頁中斷**,並且終止在缺頁中進行操作的程式指令,同時啟動核心的**中斷處理機構**處理。
> 注意⚠️:對應**訪問其他用途的記憶體區域**這個問題。
## 虛擬記憶體分配操作
虛擬記憶體的分配操作步驟我們可以理解為幾個核心的步驟:
- 核心尋找實體地址並且把需要的實體地址空間計算。
- 建立程式的頁表把實體地址對映到虛擬地址。
- 如果程式需要動態記憶體管理,核心會分配新頁表以及新的可用記憶體給程式使用,當然同時提供對應的實體記憶體空間。
> 物理分頁使用的是請求分頁的方式進行處理,這個分配的操作十分複雜。
**記憶體的上層分配**
在C語言中分配記憶體的函式是`malloc`函式,而Linux作業系統中用於分配記憶體的函式是`mmap`函式,這兩者最大區別是`mmap`函式使用的是**按頁**的方式分配,而`malloc`是按照**位元組**的方式分配。
`glibc`通過系統呼叫`mmap`申請大量的記憶體空間作為記憶體池,程式則呼叫`malloc`記憶體池請求分配出具體的記憶體供程式使用,如果程式需要再次獲取記憶體則需要再次通過mmap獲取記憶體並且再次進行分配操作。
在上層程式語言也是使用了類似的操作,首先通過`glibc`向核心申請記憶體執行虛擬記憶體的分配操作,然後`malloc`函式再去請求劃分具體的記憶體使用,只不過更上層的語言使用瞭解析器和指令碼進行掩蓋而已,實際上通過層層翻譯最終的操作依然是上面提到的操作。
**虛擬記憶體是如何解決簡單分配的問題的?**
這裡我們再次把上面三個問題搬出來,再解釋虛擬記憶體是如何處理問題的:
- 難以執行多個任務:每個程式有獨立的虛擬地址空間,所以可以編寫專用地址空間程式防止多個任務阻塞等待的情況。
- 訪問其他用途的記憶體區域:虛擬地址空間是程式獨有,頁表也是程式獨有。頁表的另一個作用是限制可以防止當前的程式訪問到其他執行緒的頁表和地址空間。
- 記憶體的碎片化:記憶體碎片化使用頁表的方式進行分配,因為頁表記錄了實體地址到虛擬地址的對映,這樣就可以很好的知道未使用的空間都幹了啥。
虛擬記憶體的其他作用:
- 檔案對映
- 請求分頁
- 利用寫時複製的方式快速建立程式
- 多級頁表
- 標準大頁
**小結**
這一部分簡要闡述Linux記憶體管理的入門理解部分,這一部分主要介紹了簡要的記憶體分配方式,以及Linux對此通過頁表的方式實現實體地址和虛擬地址的分配,最後闡述了作業系統和程式語言也就是程式之間是如何分配記憶體的,具體的分配步驟和互動邏輯介紹。
# Linux記憶體管理優化
## 檔案對映
經過之前的內容我們瞭解到檔案對映通過對映虛擬記憶體的方式實現,程式訪問記憶體對時候實際是檔案對應的副本虛擬記憶體地址,既然訪問虛擬記憶體位置可以完成檔案的修改對映,那麼直接訪問實體記憶體也就是實際記憶體修改內容也是可行的。
如果知道檔案的具體地址,甚至可以直接定位到記憶體地址對於內容進行覆蓋,在書中有一個C語言寫的驗證程式比較有意思。
## 請求分頁
程式向核心申請記憶體的通過**請求分頁**的方式完成,之前提到過通過`mmap`的方式申請記憶體的方式雖然很方便但是是有問題的:
通常的記憶體分配方式有下面兩種:
- 實體記憶體的直接申請和分配,高效。
- 控制程式碼分配的方式,也就是頁表對於虛擬記憶體和實際記憶體對映之後再給程式。
這兩種分配方式都存在兩個比較明顯的問題,那就是分配的時候如果申請了卻沒有使用會大量浪費,另外一次glibc訪問需要超過程式的記憶體,但是程式此時很可能不會使用甚至可能根本不使用,此時很可能出現**很大的程式管理大量被申請未使用記憶體**。
請求分頁就是用來解決上面提到的問題的。
**請求分頁理念**
為了更好理解請求分頁需要先理解**分頁的三種狀態**:
- 未分配頁表和實體記憶體給程式。
- 已分配頁表但是未分配實體記憶體。
- 已分配頁表和實體記憶體。
為了解決分配浪費的問題,分配程式的記憶體僅使用一次分配方式,請求分頁的核心是利用核心缺頁中斷的機制,當程式初次訪問到已分配但是沒有沒有分配實體記憶體的空間,對於此時核心會進行缺頁中斷處理,同時給程式真正申請實體記憶體進行分配動作,這樣可以保證每次分配記憶體的動作都是有效的。
> 這種方式也類似懶載入的方式,即可以保證分配動作執行,程式無感知缺頁中斷的情況,依然可以正常執行。
如果使用C語言按照請求分頁的特點進行實驗,可以發現當記憶體沒有使用的時候即使顯示已經分配記憶體,但是實際**可用實體記憶體沒有變動**。
另外分配記憶體失敗分為虛擬記憶體分配失敗,實體記憶體分配失敗,這是因為“懶載入”的設計導致的,另外**虛擬記憶體不足不一定會導致實體記憶體不足**,因為只要可用物理在分配空間小於虛擬記憶體那就是沒法分配並且會分配失敗。
## 寫時複製
寫時複製是利用`fork`的函式提高虛擬記憶體分配效率。
在檔案系統的體現是`update`或者`delete`操作不會動原資料,而是用副本完成操作,當操作完成再更新引用,如果中間當機斷電,則用日誌恢復狀態即可。
Linux 系統的記憶體管理中呼叫 `fork` 系統呼叫建立子程式時,並不會把父程式所有佔用的記憶體頁複製一份,而是首先與父程式共用相同的頁表,而當子程式或者父程式對記憶體頁進行修改時才會進行復制 —— 這就是著名的 `寫時複製` 機制。
寫時複製的流程如下:
- 在父程式呼叫`fork`的時候,並不是把所有記憶體複製給子程式而是遞交自己的頁表給子程式,如果子父程式只進行**只讀**操作雙方都會共享頁表,但是一旦一方要改變資料,就會立馬**解除共享**。
- 在解除共享的時候會有如下操作
- 由於寫入失去許可權,所以會出發缺頁中斷,此時會切斷使用者態,儲存當前程式狀態並且進行核心態。
- 切換至核心態,核心干預,執行缺頁中斷。
- 寫入方的資料複製到另一處,並且把寫入方的頁表全部更新為新複製的記憶體並且賦予寫入方寫入許可權,同時把之前共享的頁表更新,並且把另一方重新整理之後的頁表重新連線即可。(關鍵)
- 最後父子程式徹底寫入許可權和頁表獨立。但是之前解除共享的頁表依然可以自由讀寫。
> 注意⚠️:注意解除共享並不是所有的共享都解除,而是解除共享需要獨立的部分,這種處理是。
另外還需要強調進行`fork`呼叫的時候並不會複製頁表和內容,而是真正寫入的時候會觸發複製動作,這也是寫時複製名字由來。
寫時複製中如果只進行只讀操作雙方都會共享頁表,但是一旦一方要改變資料,就會立馬解除共享。
## 交換記憶體
交換記憶體是Linux核心一種OOM情況下的補償機制,作用也是為了緩解記憶體溢位和不足的問題,交換記憶體的實現依靠的是**虛擬記憶體的機制**。
簡單理解就是在實體記憶體雖然不夠但是虛擬記憶體可以借用外部儲存器也就是硬碟的一部分空間來充當實體記憶體使用,這一塊分割槽叫做交換區,由於是借物理儲存空間,這個操作也叫做換出。
另外如果借用的空間被釋放則會立即歸還,這種操作叫做換入,由於交換記憶體以頁為單位,部分資料也叫頁面調入和調出都是一個意思。
交換記憶體很容易認為是擴充實體記憶體的美好方式,但是這裡有一個本質的問題,那就是硬碟的訪問速度和記憶體相比差的次方級別的差距,另外如果長期記憶體不足很容易導致交換記憶體不斷的換入換出出現明顯的效能抖動。
**硬性頁缺失和軟性頁缺失**
另外這類需要外部儲存器的缺頁中斷在術語中被稱之為**硬性頁缺失**,相對的不需要外部儲存器的頁缺失是**軟性頁缺失**,雖然本質都是核心在觸發和完整操作,但是硬性的缺失總歸比軟性缺失後果嚴重很多。
> 這裡也要吐槽一下M1的各種偷硬碟快取來提高效能的操作.....這也是為什麼要把硬碟和CPU整合的原因之一。
## 多級頁表
多級頁表的設計核心是:**避免把全部頁表一直儲存在記憶體中是多級頁表的關鍵所在,特別是那些不需要的頁表就不應該保留。**
在X86-64架構當中,虛擬地址的空間大小約為128T,一個頁的大小為4KB,頁表的專案大小為8個位元組。
所以一個程式的頁表至少需要256GB記憶體!(8 * 128T / 4KB),但是我們都知道現在的電腦一般都是16GB記憶體為主。
那麼系統應該如何維護頁表?這就引入了多層頁表來進行管理,多級頁表可以從最簡單的角度當作一個多級的指標看待。
首先我們可以思考,一個程式是否需要整個頁表來管理記憶體?很顯然是不需要的,這是引入多級頁表的理由之一。
假設一個程式需要12M空間,頂端需要4M,資料部分佔用4M,底部又是一些堆疊內容和記錄資訊,在資料頂端上方和堆疊之間是大量根本沒有使用的空閒區。
多級頁表實際上就是大目錄套小目錄,和我們的一本書一樣,小目錄負責小的程式,而遇到比較大的程式就放到空閒頁比較大的目錄中完成分配操作,多級頁表既可以高效的利用記憶體的同時,可以最大限度的減少頁表本身的資料結構在記憶體的佔用,同時上面的例子也可以發現絕大多數的程式其實根本不需要太大的頁表進行維護和管理。
最後從網上的資料翻閱中發現一張下面的圖,對於多級頁表的理解有一定幫助:
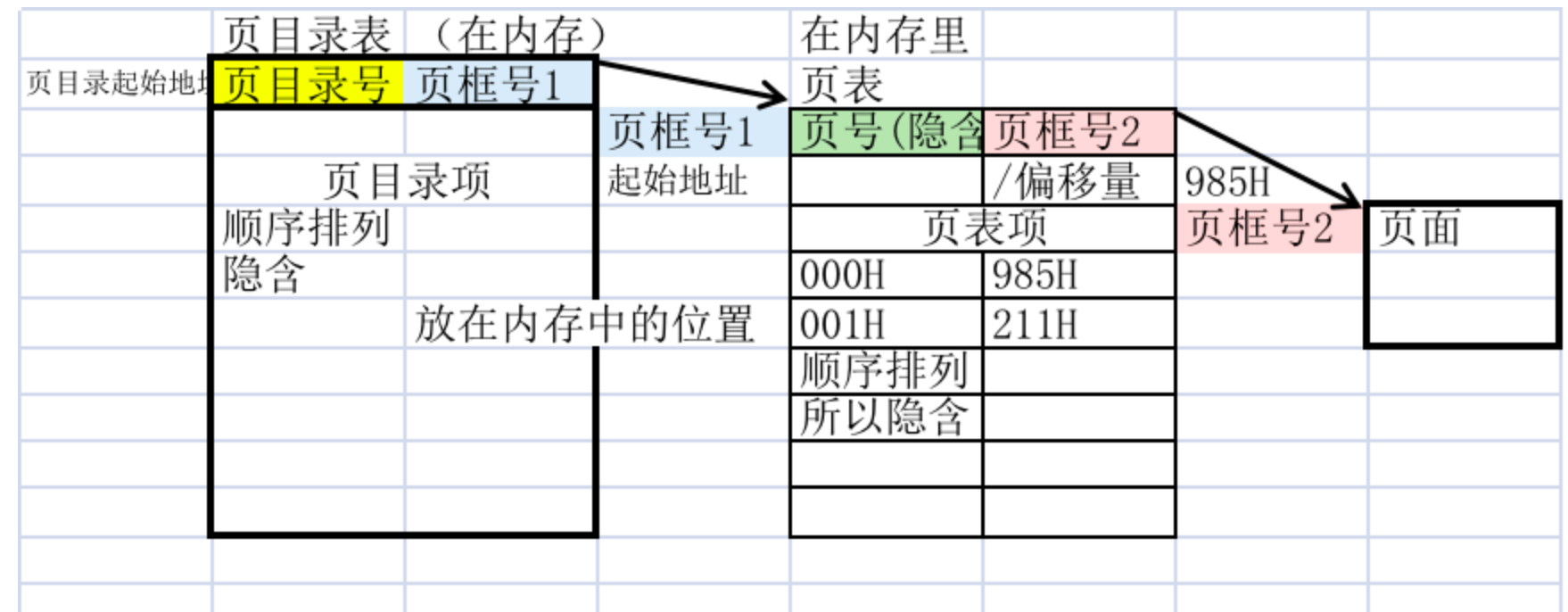
最後X86_64 使用了4層的頁表結構,直當理解就是四級指標。
## 標準大頁
隨著程式虛擬記憶體和頁表的使用,程式使用的實體記憶體也會增加。
根據請求分頁和寫時複製的概念,呼叫`fork`函式的時候會對於父子程式共享的頁表進行拷貝,雖然這個拷貝動作不會佔用實體記憶體,但是需要拷貝一份完整的頁表,當頁表很大的時候也會造成效能浪費。
為了解決這個問題,Linux提供了**標準大頁**的機制,和他名字一樣就是比普通的頁表更大的頁,利用這種頁表可以減小程式頁表所需的記憶體使用量,通過多級頁表和標準大表可以有效的減少整個頁表項的數量。
**用法**:
C語言中使用`mmap`函式引數賦予 `MAP_HUGETLB` 標誌,表示可以獲取大頁,但是更加常用的方式是使用程式允許使用使用標準大頁而不是這種手動切換的方式。
標準大頁對於虛擬機器和資料庫等需要使用大量記憶體的應用程式是很有必要的,根據實際情況決定是否使用標準大頁,通過這種設定可以減少這一類軟體記憶體佔用,還能提高`fork`效率。
**透明大頁**
透明大頁是隨著標準大頁帶來的附帶特性,主要的作用是在連續的4KB頁面如果符合指定條件就可以通過透明大頁的機制轉為一個標準大頁,以及在不滿足標準大頁條件的時候拆分為多個4KB頁面。
**小結**
這部分從檔案對映的內容引申了Linux兩個重要的機制:**請求分頁**和**寫時複製**,目的本質上都是儘量減少程式對於記憶體的浪費,但是需要注意的是這兩種方式都是使用了核心模式的系統中斷機制來進行處理的,所以對於核心的效能以及穩定性要求非常高。
在之後的內容介紹了交換記憶體以及多級頁表和標準大頁幾個內容,其中多級頁表內部的細節非常的複雜,通常需要對於作業系統底層有比較熟悉的認知才能完全的瞭解這個頁表的細節。
# 程式排程器
針對Linux程式排程有下面的思考:
- 每一個CPU同一時間只能排程一個程式。
- 每一個程式有*近乎相等的執行時間。
- 對於邏輯CPU而言程式排程使用輪詢的方式執行,當輪詢完成則回到第一個程式反覆。
- 程式數量消耗時間和程式量成正比。
對於程式排程來說不能保證一個程式是連續完成的,由於CPU排程和程式切換,上下文也會出現切換情況。
## 程式狀態
對於大部分程式來說,當我們不使用的時候多數處於睡眠狀態。
除了睡眠狀態之外,程式還有下面幾種狀態:
- 執行狀態:獲得CPU排程,執行程式任務。
- 僵死狀態:程式等待結束,等待父程式回收。
- 就緒狀態:具備執行條件,等待CPU分配。
- 睡眠狀態:程式不準備執行除非某種條件觸發才會獲得CPU排程分配。
處在睡眠態的程式觸發執行態的條件如下:
- 外部儲存器訪問。
- 使用者鍵入或者滑鼠操作觸發事件。
- 等待指定時間。
- 等待指定時間。
通過`ps ax`命令可以檢視當前的程式狀態,下面的案例以個人的Mac電腦為例:
MacBook-Pro ~ % ps ax
PID TT STAT TIME COMMAND
32615 ?? Ss 0:00.11 /usr/libexec/nearbyd
32632 ?? Ss 0:00.51 /System/Library/CoreServices/Screen Time.app/Content
32634 ?? Ss 0:00.02 /System/Library/PrivateFrameworks/Categories.framewo
32635 ?? S 0:00.12 /System/Library/CoreServices/iconservicesagent
32636 ?? Ss 0:00.05 /System/Library/CoreServices/iconservicesd
32671 ?? S 0:02.44 /Applications/Microsoft Edge.app/Contents/Frameworks
32673 ?? S 0:02.86 /Applications/Microsoft Edge.app/Contents/Frameworks
32678 ?? Ss 0:00.17 /System/Library/PrivateFrameworks/UIFoundation.frame
32726 ?? S 0:00.07 /System/Library/Frameworks/CoreServices.framework/Fr
32736 ?? S 0:00.08 /System/Library/Frameworks/CoreServices.framework/Fr
32738 ?? S 0:00.75 /System/Applications/Utilities/Terminal.app/Contents
32739 ?? Ss 0:00.02 /System/Library/PrivateFrameworks/Categories.framewo
32746 ?? Ss 0:00.03 /System/Library/Frameworks/Metal.framework/Versions/
32740 s000 Ss 0:00.02 login -pf xxxxxx
32741 s000 S 0:00.03 -zsh
32750 s000 R+ 0:00.01 ps ax
`s`表示`sleep`,`d`表示此時可能在等待磁碟IO,但是如果長時間處於`d`狀態則可能是磁碟IO等待超時或者核心可能發生故障。
下面是根據上面的介紹繪製的程式狀態流轉圖
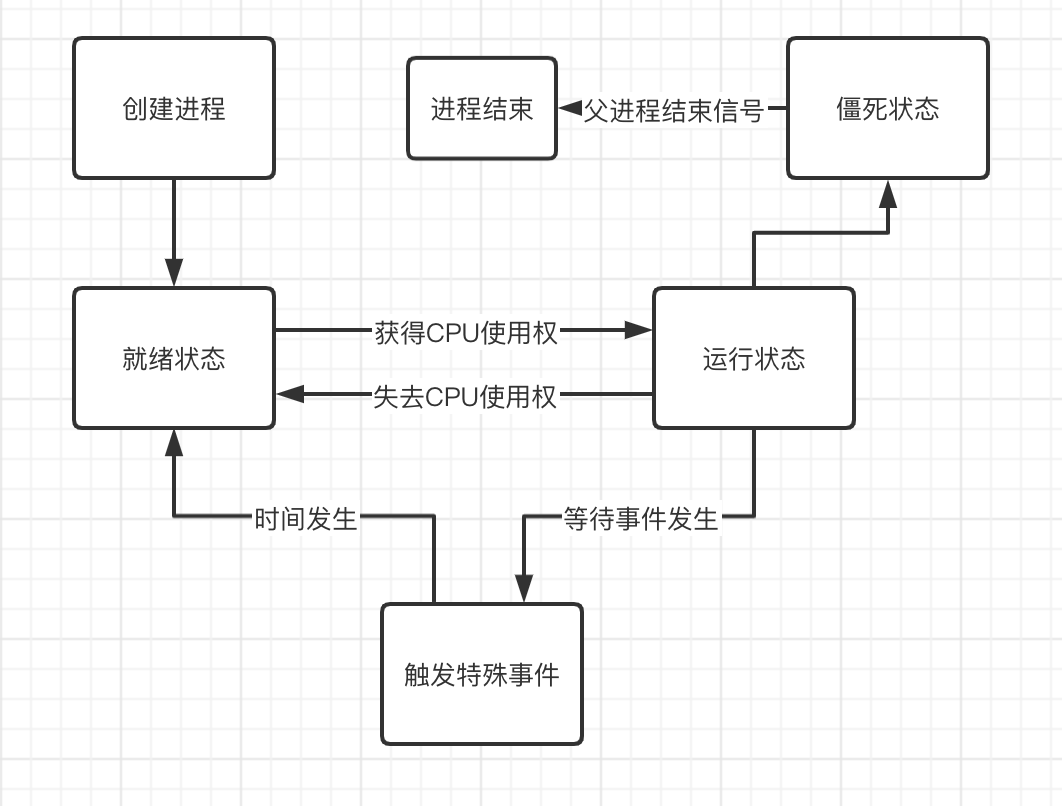
如果只執行一個程式同時在程式中間休眠過一次,那麼此時休眠的程式在幹什麼?
程式會進入**空程式**的模式輪詢,但是空程式不是沒有事做,而是需要呼叫一些維持系統執行的執行緒,為了保證系統正常穩定執行。
因為CPU和空閒程式,所以同樣會不斷的切換睡眠態和運動態,運動態獲取使用者輸入操作完成動作,睡眠態則執行一些輕量操作。
針對睡眠態的程式會有如下特點:
- 遵循同一時間CPU只能完成一個程式操作
- 睡眠態不佔用CPU時間。
## 吞吐量和延遲
- 吞吐量:處理完成的程式數量 / 耗費時間
- 延遲:結束處理時間 - 開始處理時間
通過這兩點可以總結幾點規則:
吞吐量的上限是程式的數量多過邏輯CPU的數量,則再增加程式無法增加吞吐量,另外程式中的延遲總是平均的,也就是說多個程式執行會獲得近似平均的延遲,最後程式越多延遲越高。
但是現實系統沒有那麼多理想情況,多數情況是下面幾種:
- **空閒程式**:此時吞吐量很低,因為很多邏輯CPU都在睡眠狀態。
- **程式執行態:此時沒有就緒**:這種狀態比較理想,CPU可以安排到下一次處理,雖然會延後開始執行提高吞吐量,但是可能會出現CPU空閒的情況。
- **程式執行態,同時就緒**:此時就好像賽跑,但是隻有一個跑道,每一個程式輪流處理一會兒,所以此時延遲變長。
另外由於很多程式編寫都是單執行緒程式,**一核執行,多核圍觀**或許在過去更普遍。
優化吞吐量和延遲的方式是使用 `sar` 命令找到執行時間和開銷最大程式,同時把一些死程式`kill`掉。
## 多CPU排程情況
分片時間每一個程式用一個CPU工作,那麼分配和排程CPU安排工作又是如何的?
主要有兩種方式,第一種是通過輪詢**負載均衡**,另一種是**全域性分配**,把任務分配給空閒程式的邏輯CPU。
負載均衡是CPU遇到程式任務依次安排工作,當最後一個CPU安排完成之後,則再回到第一個CPU進行分配,同時都是對於程式執行一定的時間,也就是說出現CPU-A處理一部分,另一部分可能是CPU-B完成。
全域性分配的方式比較簡單,就是把任務分配給處於空閒程式的邏輯CPU完成工作。
檢視系統邏輯CPU的命令如下:
`grep -c processor /proc/cpuinfo`
多核cpu通常只有在同時執行多個程式的時候才會發揮作用,但是並不是說有多少核心就有多少倍效能,因為大部分時候程式很少很多CPU都在睡眠態度
如果程式超過邏輯CPU數量,無論怎麼增加程式都不會提高處理速度
最後處於睡眠狀態的程式其實可以指定睡眠時間,通過sleep函式呼叫完成程式休眠的操作。
**小結**
程式排程器的內容遠沒有上面介紹的簡單,但是作為理解程式的切入點是不錯的。
# 計算機程式概覽
放到最後是因為個人認為算是這本書相對沒有什麼價值的部分。
## 概覽
狹義上的計算機結構是:CPU,記憶體,外部裝置,其中外部裝置包含輸入輸出和外部外儲存器以及網路介面卡。
而從廣義上來看,計算機可以用抽象化的概念進行解釋,則可以簡單講計算機分為三部分:
- 第一部分是應用程式,這些程式依託於環境和載體。
- 第二部分就是執行程式的載體,負責管理系統呼叫,程式切換和裝置驅動這些工作,同時擔任重要的硬體抽象的角色,為應用程式掩蓋掉複雜的底層維護工作。
- 最後一部分是硬體,這部分就是我們狹義的理解計算機的部分,這裡不多介紹。
在硬體裝置重複執行以下步驟:
- 輸入裝置或者網路介面卡發起請求
- 讀取記憶體命令,CPU上執行,把結果寫入負責儲存到記憶體區域
- 記憶體的資料寫入HDD、SDD等儲存器
而程式大致則分為下面幾種:
- 應用程式:讓使用者直接使用,為使用者提供幫助程式,例如計算機等辦公軟體,計算機上的辦公軟體,智慧手機和其他應用。
- 中介軟體:輔助程式執行等軟體,比如WEB伺服器和資料庫
- OS:控制硬體,為應用程式和中介軟體提供執行環境,Linux 叫做OS。
## 使用者模式和核心模式
下面的內容可以認為是把之前的內容回顧一遍:
**使用者模式**
使用者程式訪問的時候都是使用者模式,使用者模式是受到保護或者說許可權受限的,只能夠使用核心分配的記憶體和CPU進行操作,失去使用權則會處於等待的情況。
使用者程式的一大特點是使用者的空間只能使用者程式使用,所以一旦有使用者程式崩潰了,核心可以去把它給清理掉。因此增強系統的魯棒性。
**核心模式**
此模式下執行的程式碼對 CPU 和記憶體具有無限的使用許可權,這個強大的許可權使得核心可以輕易腐化和崩潰整個系統,所以核心使用的空間是隻能被核心訪問的,其他任何使用者都無權訪問。
**特點對比**
| **核心級執行緒特點** | **使用者級執行緒的特點** |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| 1.程式中的一個執行緒被阻塞,核心能排程同一程式的其他執行緒(就緒態)佔有處理器執行。<br/>2.多處理器環境中,核心能同時排程同一程式的多執行緒,將這些執行緒對映到不同的處理器核心上,提高程式的執行效率。<br/>3.應用程式執行緒在使用者態執行,執行緒排程和管理在核心實現。執行緒排程時,控制權從一個執行緒改變到另一執行緒,需要模式切換,系統開銷較大<br/> | 1.執行緒切換不需要核心模式,能節省模式切換開銷和核心資源。<br/>2.允許程式按照特定的需要選擇不同的排程演算法來排程執行緒。排程演算法需要自己實現。<br/>3.由於其不需要核心進行支援,所以可以跨OS執行。<br/>4.不能利用多核處理器優點,OS排程程式,每個程式僅有一個ULT能執行<br/>5.一個ULT阻塞,將導致整個程式的阻塞。<br/> |
> 對於使用者執行緒阻塞在後續技術的發展出現了一種叫做**Jacketing技術**。
>
> 使用Jacketing技術把阻塞式系統呼叫改造成非阻塞式的。當執行緒陷入系統呼叫時,執行jacketing程式,由jacketing程式來檢查資源使用情況,以決定是否執行程式切換或傳遞控制權給另一個執行緒。
>
> 也就是說Jacketing技術實現了當使用者執行緒阻塞的時候更加靈活的進行切換,防止出現一個執行緒的阻塞導致多執行緒阻塞這種情況。
**使用者模式切換到核心模式**:
一般是發生了中斷或者無法處理的系統異常情況下出現。
此時核心會剝奪使用者程式的控制權進行處理, 並且執行一些核心的修復操作,比如缺頁中斷申請記憶體並且分配新的頁表給程式,這種機制為請求分頁的處理方式。
> 注意⚠️:更多細節可以回顧[程式排程器]檢視有關程式排程的內容。
使用者模式切換到核心模式一般會經歷下面的步驟:
- CPU模式切換
- 儲存當前的程式狀態到核心棧。
- 中斷異常程式排程處理
**核心模式切換到使用者模式**:
當中斷異常處理排程程式完成之後,核心模式會逐漸轉為使用者模式執行,此時使用者執行緒回從核心棧找回當前到程式狀態,並且CPU執行模式也會執行為使用者模式。
**模式切換的優劣對比**
其實這兩個模式用最抽象的概念就是**應用程式和系統程式之間的差別**,因為對於使用者來說模式切換是透明的,基本使用過電腦用過電腦程式,基本都經歷過應用程式崩潰引發系統崩潰的情況,此時就是一種使用者模式到核心模式的切換。
使用者模式的好處在於訪問和空間佔用都是受到核心管控的,但是有一個很大的問題是一旦出現中斷異常就會發生使用者模式和核心模式的切換,在通常情況下看起來沒什麼問題,但是隨著程式需要的記憶體越來越大,每一次切換對於系統帶來影響和開銷都是非常嚴重的。
在很多大型程式中,因為模式切換帶來的問題也並不罕見,更多情況下是使用者編寫的低質量或者問題程式碼出現資源浪費導致的問題。
**簡單對比Windows**:
下面我們類比Windows系統的核心模式以及使用者模式的切換,這裡主要看看微軟的官方文件是如何介紹的:
使用者模式:程式享受專用的[虛擬地址空間](https://docs.microsoft.com/zh-cn/windows-hardware/drivers/gettingstarted/virtual-address-spaces),和Linux類似的 在使用者模式下執行的處理器無法訪問為作業系統保留的虛擬地址。
核心模式:在核心模式下執行的所有程式碼都共享單個[虛擬地址空間](https://docs.microsoft.com/zh-cn/windows-hardware/drivers/gettingstarted/virtual-address-spaces)。
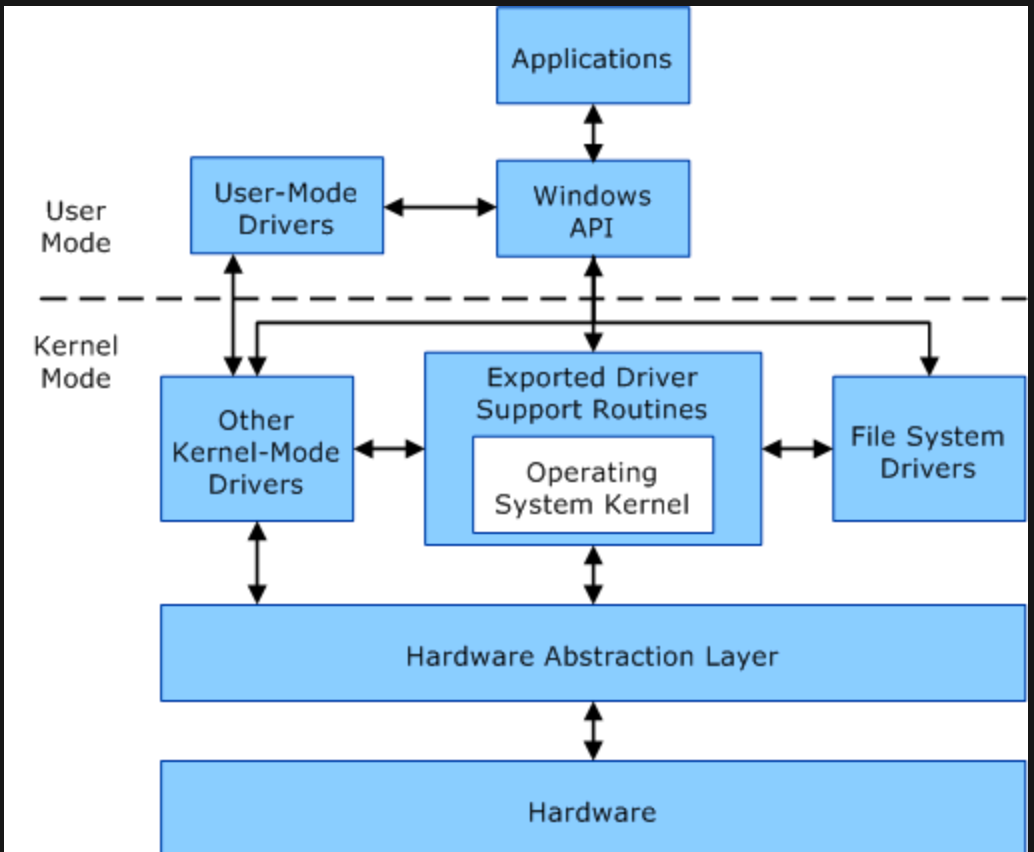
其實簡單對比一下就會發現實現機制都是類似的,只不過內部實現程式碼不同和細節不同而已,基本的特性都是相似的。
## C標準庫
C標準庫在很早就被國際設立為標準規範,哪怕過去這麼多年依然通用。
而C標準庫中較為核心的元件是`glibc`,之前介紹過`glibc`是使用者程式像核心申請記憶體的關鍵實現函式,使用glibc申請記憶體再使用mmap函式申請具體的記憶體,這部分內容可以閱讀[記憶體管理]進行了解。
> glibc通過系統呼叫向`mmap`申請大量的記憶體空間作為記憶體池,程式則呼叫`malloc`根據記憶體池分配出具體的記憶體使用,如果程式需要再次獲取記憶體則需要再次通過mmap獲取記憶體並且再次進行分配操作。
另外高階的程式語言同樣依賴或者基於C標準庫,比如Python的`ppidloop`就是如此,除此之外還有C++對於C標準庫的進一步擴充套件等。
## OS提供的程式
下面列舉一些OS提供的程式:
- 初始化系統:`init`
- 變更系統運作方式:`sysctl、nice、sync`
- 檔案操作:`touch、mkdir`
- 文字資料處理:`grep、sort、uniq`
- 效能測試:`sar、iostat`
- 編譯:`gcc`
- 指令碼語言執行環境:`perl、python、ruby`
- shell:`bash`
- 視窗系統:`x`
另外系統呼叫通常也可以分為下面幾種:
- 程式控制:[[010106 - 程式排程器]]
- 記憶體管理:[[010105 - Linux記憶體管理]]
- 程式通訊:[[010106 - 程式排程器]]
- 網路管理(本書未涉及)
- 檔案系統操作:[[010103 - Linux檔案系統設計]]
- 檔案操作:[[010101 - Linux與外部結構介紹]]
# 寫在最後
還是挺不錯的一本書,雖然沒有那些搬磚書那麼系統,但是對於初學者來說是個不錯的切入書,這本書買實體書不是很划算,因為配圖講解工作原理的內容比較多,甚至讓我覺得作者應該多一點文字描述......
# 附錄
附錄部分
## LBA(Logical Block Addressing)邏輯塊定址模式
### HDD常見定址方式
**CHS定址**
CHS定址也被稱為NORMAL 普通模式,此定址模式是最早的 IDE 方式。
在硬碟訪問時,BIOS 和 IDE 控制器對引數不做任何轉換。該模式支援的最大柱面數為 1024,最大磁頭數為 16,最大扇區數為 63,每扇區位元組數為 512,因此支援最大硬碟的容量為:
**512x63x16x1024=528MB**。
> ⚠️注意:最早期的計算機僅僅只需要500多MB就夠用,和現在確實是天差地別。
**LBA定址**
LBA的定址特點是地址不再和物理磁碟的位置一一對應,前面CHS定址使用了三個關鍵引數:磁頭位置,儲存柱面位置,扇區位置三個引數利用三維的引數來計算容量,而LBA定址則使用了一個引數進行定址,同時由IDE控制計算柱面、磁頭、扇區的引數等組成的邏輯地址轉為實體地址。
LBA可以設定最大的磁頭數為255,而其他引數和CHS定址的模式類似,所以我們對應上面的結算公式只需要把16改為255,最終結果如下:
512x63x255x1024=8.4G。
另外在早期的LBA定址中主機板上大多數是28位的LBA定址,而前面討論了LBA的三維引數和實體地址不是一一對應的,而是通過IDE計算邏輯地址尋找最終的實體地址。
根據計算機的位操作我們可以計算出邏輯塊為2的28次方= 137,438,953,472個位元組也就是137G,意味著最早期的磁碟定址極限為137G,當然這也是因為**當時的主機板技術跟不上硬碟技術導致的**,並且當時的計算機使用人員用不到137G的容量。
當然要突破這個限制也非常簡單,把28位的定址提高就可以直接支援更大容量的硬碟,經過發展,**目前使用的都是48位LBA定址方式**。
而48位LBA定址方式的理論容量極限是144,115,188,075,855,872位元組=144,000,000 GB!上億的磁碟容量基本夠目前使用。
由於LARGE、LBA定址模式採用了邏輯變換演算法看上去比CHS複雜不少,但是不少的資料、磁碟工具類軟體中採用的硬碟引數介紹和計算方法卻還是按照相對而言比較簡單的**CHS定址模式**。
而LBA定址模式說白了也是在CHS定址模式上的改進,也需要向前相容,因此CHS定址模式是硬碟定址模式的基礎,理解CHS定址模式HDD硬碟使用和維護還是很有用的。
**LARGE定址**
LARGE 大硬碟模式,**在硬碟的柱面超過 1024 而又不為 LBA 支援時採用**。LARGE 模式採用的方法非常簡單粗暴,就是把直接把**柱面數除以 2,把磁頭數乘以 2**,其結果總容量不變方式定址。
> ⚠️注意:LBA定址到現在依舊是主流。
### 容量和大小對比
- **CHS(或稱為Normal)模式**: 適應容量≤504MB的硬碟。
- **LARGE(或稱LRG)模式**: 適應504MB≤容量≤8.4GB的硬碟 。
- **LBA(Logical Block Addressing)模式**: 適應容量≥504MB的硬碟,但BIOS需支援擴充套件INT13H,否則也只能適應≤8.4GB的硬碟
**小結**
LARGE定址模式把柱面數除以整數倍、磁頭數乘以整數倍而得到的邏輯磁頭/柱面/扇區引數進行定址,所以表示的已不是硬碟中的物理位置,而是邏輯位置,但是這種計算方式顯然比較粗糙**使用比較少**。
LBA定址模式是直接以扇區為單位進行定址的,不再用磁頭/柱面/扇區三種單位來進行定址。
但為了保持與之前的CHS模式的相容,通過邏輯變換演算法,可以轉換為磁頭/柱面/扇區三種引數來表示,但表示的也和LARGE定址模式一樣已不是硬碟中的物理位置而是邏輯位置了。
# 參考資料
1. [磁碟I/O那些事](https://tech.meituan.com/2017/05/19/about-desk-io.html)
2. [為什麼硬碟轉速是5400或者7200這麼奇怪的數字?7200轉的硬碟一定比5400快嗎?](https://zhuanlan.zhihu.com/p/38847308)
3. [## 求硬碟的3種定址模式 NORMAL LBA LARGE 詳細介紹](http://www.360doc.com/content/14/0712/14/18521633_393882067.shtml)
4. [# 硬碟基本知識(磁頭、磁軌、扇區、柱面)](https://cloud.tencent.com/developer/article/1129947 )
5. [linux記憶體管理---虛擬地址、邏輯地址、線性地址、實體地址的區別](https://blog.csdn.net/yusiguyuan/article/details/9664887)