在SpringBoot中使用R2DBC連線池的原始碼和教程
隨著微服務架構的興起,反應式應用程式變得越來越流行。為了充分利用反應式系統的潛力,建議使我們所有的系統都具有反應性。
但是,在做出充分反應的應用仍然在JVM世界相當大的挑戰,因為JDBC(Java資料庫連線)是同步的,並封鎖連線到關聯式資料庫,其中大部分應用程式用來儲存資料的API。
為了解決這個問題,Pivotal(Spring 框架背後的公司)帶領社群努力建立一種連線到資料庫的非同步方式,這個專案現在稱為 R2DBC(反應性關聯式資料庫連線)。
在 R2DBC 倡議之後,Spring 團隊決定在 Spring 生態系統中支援 R2DBC,因此Spring Data R2DBC誕生了。
專案原始碼點選標題
專案設定
必須包含三個依賴項:
- Spring Data R2DBC
- PostgreSQL 驅動程式
- Spring 響應式 Web
持久層
public interface MemberRepository extends R2dbcRepository<Member, Long> {
Mono<Member> findByName(String name);
}
|
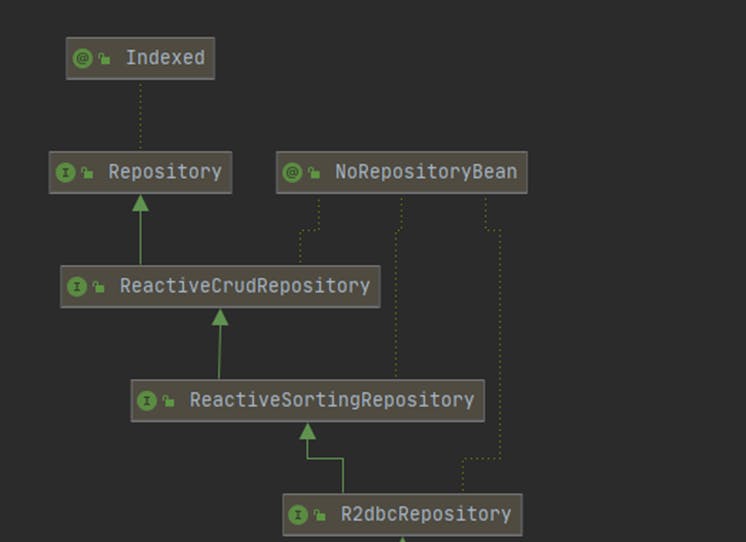
在這個 R2DBC 儲存庫中,自定義方法不是Member直接返回,而是包含在Mono. 此儲存庫中的每個方法都將使用Mono或Flux。這與Project Reactor使用的內容一致,因此我們與反應式 API 完全相容。
不僅如此R2dbcRepository,在 Spring Data R2DBC 中,我們還可以選擇使用以下兩個選項之一擴充套件介面:
- ReactiveCrudRepository, 用於您的通用 CRUD 儲存庫和,
- ReactiveSortingRepository 用於額外的排序功能。
您可以選擇這些選項中的任何一個,具體取決於您的用例。
控制器:
@RestController
@RequestMapping(value = "/api/member")
@RequiredArgsConstructor
public class MemberController {
private final MemberRepository memberRepository;
@GetMapping
public Flux<Member> getAll() {
return memberRepository.findAll();
}
@GetMapping(value = "/{name}")
public Mono<Member> getOne(@PathVariable String name) {
return memberRepository.findByName(name);
}
}
|
Spring Data R2DBC 已經包含連線池選項,我們只需從我們的properties中啟用它。
對於此示例,我們將建立 2 個單獨的端點,它們將使用Mono和Flux:
- 在method上getAll,我們使用之前建立的repository來獲取資料庫中的所有資料,因為我們會得到1個以上的資料,返回的資料被包裹在Flux.
- 在 method 上getOne,我們請求一條資料,在這種情況下,我們將返回的資料包裝在Mono.
我們現在差不多完成了。現在我們已經設定了 API,我們需要做的就是將應用程式連線到我們的資料庫。
R2BC連線池配置
HikariCP連線池在R2BC中不可用,連線池選擇使用R2DBC Pool。
您可以將以下屬性新增到您的application.properties檔案中,R2DBC 將能夠將連線集中到我們的資料庫。
spring.r2dbc.url=r2dbc:postgresql://postgres@localhost:5432/reactive logging.level.org.springframework.r2dbc=DEBUG |
spring.r2dbc.pool.enabled=true spring.r2dbc.pool.initial-size=50 spring.r2dbc.pool.max-size=100 |
這些屬性將啟動具有 50 個可供使用的連線的池,並且在需要時可以擴充套件到最多 100 個連線。
有多種方法可以對我們的應用程式進行負載測試,您甚至可以通過ab命令直接從終端使用 Apache Benchmark 。
可以使用一個名為K6的工具:
測試一個 API,它將向我們的資料庫中插入一百條記錄。這將是對資料庫施加壓力的大量寫入操作。
如果沒有連線池,我們只能完成 140 個請求,第 95 個百分位數為 2.33s。
而使用R2DBC的連線池,我們完成了 480 次請求迭代,將吞吐量提高了近 3.5 倍,並將第 95 個百分點的延遲降低到 668 毫秒,這幾乎是延遲的 4 倍!
關於池的大小:
池大小最終非常特定於部署。
例如,混合了長時間執行的事務和非常短的事務的系統通常最難使用任何連線池進行調整。在這些情況下,建立兩個池例項可以很好地工作(例如,一個用於長時間執行的作業,另一個用於“實時”查詢)。
在主要具有長時間執行事務的系統中,所需連線數通常存在“外部”約束——例如,作業執行佇列只允許一次執行一定數量的作業。在這些情況下,作業佇列的大小應該是“合適的”以匹配池(而不是相反)。
相關文章
- MOSN 原始碼解析 - 連線池原始碼
- ServiceStack.Redis的原始碼分析(連線與連線池)Redis原始碼
- Hikari連線池原始碼解讀原始碼
- 資料庫連線池-Druid資料庫連線池原始碼解析資料庫UI原始碼
- 《四 資料庫連線池原始碼》手寫資料庫連線池資料庫原始碼
- MQTT(EMQX) - SpringBoot 整合MQTT 連線池 Demo - 附原始碼 + 線上客服聊天架構圖MQQTSpring Boot原始碼架構
- 在 Spring Boot 中使用 HikariCP 連線池Spring Boot
- spring和mybatis中的連線池和快取SpringMyBatis快取
- SpringBoot?整合mongoDB並自定義連線池的示例程式碼Spring BootMongoDB
- springboot activiti 整合專案框架原始碼 shiro 安全框架 druid 資料庫連線池Spring Boot框架原始碼UI資料庫
- SpringBoot中關於 HikariPool、Druid及常用連線池的比較Spring BootUI
- 【MySQL】自定義資料庫連線池和開源資料庫連線池的使用MySql資料庫
- 從原始碼分析DBCP資料庫連線池的原理原始碼資料庫
- 從原始碼中分析關於phpredis中的連線池可持有數目原始碼PHPRedis
- 連線池和連線數詳解
- 在Deno中使用Redis的教程和原始碼 -LogRocket部落格Redis原始碼
- SpringBoot專案整合阿里Druid連線池Spring Boot阿里UI
- OkHttp3原始碼解析(三)——連線池複用HTTP原始碼
- C#中的連線池管理C#
- Springboot 整合阿里資料庫連線池 druidSpring Boot阿里資料庫UI
- Java GenericObjectPool 物件池化技術--SpringBoot sftp 連線池工具類JavaObject物件Spring BootFTP
- spring 簡單的使用 Hikari連線池 和 jdbc連線mysql 的一個簡單例子SpringJDBCMySql單例
- mysql資料庫連線池配置教程MySql資料庫
- Springboot 連線池wait_timeout超時設定Spring BootAI
- springboot專案整合druid資料庫連線池Spring BootUI資料庫
- 【JDBC】使用OracleDataSource建立連線池用於連線OracleJDBCOracle
- 連線池
- 長連線和短連線的使用
- 執行緒池的建立和使用,執行緒池原始碼初探(篇一)執行緒原始碼
- springboot之Druid連線池講解+mybatis整合+PageHelper整合Spring BootUIMyBatis
- 雨露均沾的OkHttp—WebSocket長連線的使用&原始碼解析HTTPWeb原始碼
- springboot中如何使用執行緒池Spring Boot執行緒
- 第77節:Java中的事務和資料庫連線池和DBUtilesJava資料庫
- 資料訪問連線池和執行緒池執行緒
- 4、資料庫連線池的概念及C3P0、Uruid兩種連線池的使用資料庫UI
- Tomcat 的 JDBC 連線池TomcatJDBC
- Springboot執行緒池的使用和擴充套件Spring Boot執行緒套件
- 在Spring data中使用r2dbcSpring