本文內容說明
- 初始化配置給rdd和dataframe帶來的影響
- repartition的相關說明
- cache&persist的相關說明
- 效能優化的說明建議以及例項
配置說明
spark:2.4.0
伺服器:5臺(8核32G)
初始化配置項
%%init_spark
launcher.master = "yarn"
launcher.conf.spark.app.name = "BDP-xw"
launcher.conf.spark.driver.cores = 1
launcher.conf.spark.driver.memory = '1g'
launcher.conf.spark.executor.instances = 3
launcher.conf.spark.executor.memory = '1g'
launcher.conf.spark.executor.cores = 2
launcher.conf.spark.default.parallelism = 5
launcher.conf.spark.dynamicAllocation.enabled = False
import org.apache.spark.sql.SparkSession
var NumExecutors = spark.conf.getOption("spark.num_executors").repr
var ExecutorMemory = spark.conf.getOption("spark.executor.memory").repr
var AppName = spark.conf.getOption("spark.app.name").repr
var max_buffer = spark.conf.getOption("spark.kryoserializer.buffer.max").repr
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.monotonically_increasing_id
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType}
import org.apache.spark.sql.functions.{udf, _}
import org.apache.spark.{SparkConf, SparkContext}
object LoadingData_from_files{
def main(args: Tuple2[String, Array[String]]=Tuple2(hdfs_file, etl_date:Array[String])): Unit = {
for( a <- etl_date){
val hdfs_file_ = s"$hdfs_file" + a
val rdd_20210113 = spark.sparkContext.textFile(hdfs_file_).cache()
val num1 = rdd_20210113.count
println(s"載入資料啦:$a RDD的資料量是$num1")
}
val rdd_20210113_test = spark.sparkContext.textFile(hdfs_file + "20210328").cache()
var num1 = rdd_20210113_test.count()
println(s"載入資料啦:20210113 RDD的資料量是$num1")
rdd_20210113_test.unpersist() // 解除持久化
val df_20210420 = spark.sparkContext.textFile(hdfs_file + "20210113").toDF.cache()
num1 = df_20210420.count() // 指定memory之後,cache的數量太多之前cache的結果會被幹掉
println(s"載入資料啦:20210420 DataFrame的資料量是$num1")
}
}
// 配置引數multiple_duplicated
val hdfs_file = "hdfs://path/etl_date="
val etl_date = Array("20210113","20210112","20210112","20210112","20210112","20210112", "20210113")
LoadingData_from_files.main(hdfs_file, etl_date)
- 得到結果如下:

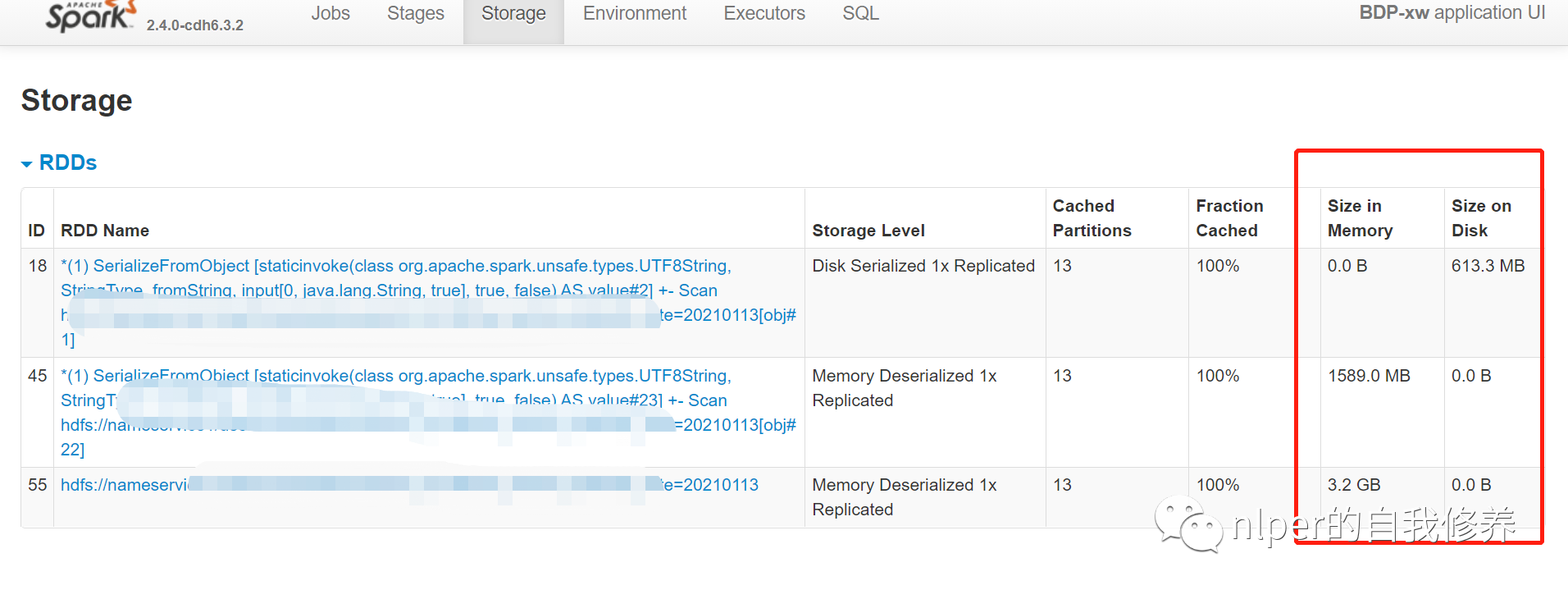
- 結果分析
- 可以看到預設情況下,RDD的快取方式都是到
Memory的,而DataFrame的快取方式都是Memory and Disk的 - 指定memory之後,cache的數量太多之前cache的結果會被幹掉
- 可以看到預設情況下,RDD的快取方式都是到
無特定配置項
import org.apache.spark.sql.SparkSession
var NumExecutors = spark.conf.getOption("spark.num_executors").repr
var ExecutorMemory = spark.conf.getOption("spark.executor.memory").repr
var AppName = spark.conf.getOption("spark.app.name").repr
object LoadingData_from_files{
def main(args: Tuple2[String, Array[String]]=Tuple2(hdfs_file, etl_date:Array[String])): Unit = {
for( a <- etl_date){
val hdfs_file_ = s"$hdfs_file" + a
val rdd_20210113 = spark.sparkContext.textFile(hdfs_file_).cache()
val num1 = rdd_20210113.count
println(s"載入資料啦:$a RDD的資料量是$num1")
}
val rdd_20210113_test = spark.sparkContext.textFile(hdfs_file + "20210328").cache()
var num1 = rdd_20210113_test.count()
println(s"載入資料啦:20210328 RDD的資料量是$num1")
rdd_20210113_test.unpersist() // 解除持久化
val df_20210420 = spark.sparkContext.textFile(hdfs_file + "20210113").toDF.cache()
num1 = df_20210420.count() // 指定memory之後,cache的數量太多之前cache的結果會被幹掉
println(s"載入資料啦:20210420 DataFrame的資料量是$num1 \n當前環境下cache的個數及id為:")
spark.sparkContext.getPersistentRDDs.foreach(i=>println("cache的id:" + i._1))
}
}
// 無配置引數multiple_duplicated
val hdfs_file = "hdfs://path/etl_date="
val etl_date = Array("20210113","20210112","20210112","20210112","20210112","20210112", "20210113" )
LoadingData_from_files.main(hdfs_file, etl_date)
-
得到結果如下:
-

-
結果分析
- spark的配置檔案中,設定的也是動態分配記憶體;
- cache的結果也是到達memory限制的時候,已經cache的結果會自動消失;
- 上述例子中,我們增加了8個檔案,但最終只保留了5個cache的結果;
- 通過for重複從一個檔案取數,並val宣告給相同變數並cache,結果是會被多次儲存在memory或者Disk中的;
檢視當前服務下的所有快取並刪除
spark.sparkContext.getPersistentRDDs.foreach(i=>println(i._1))
spark.sparkContext.getPersistentRDDs.foreach(i=>{i._2.unpersist()})
repartition
- repartition只是coalesce介面中shuffle為true的實現
- repartition 可以增加和減少分割槽,而使用 coalesce 則只能減少分割槽
- 每個block的大小為預設的128M
//RDD
rdd.getNumPartitions
rdd.partitions.length
rdd.partitions.size
// For DataFrame, convert to RDD first
df.rdd.getNumPartitions
df.rdd.partitions.length
df.rdd.partitions.size
RDD
- 預設cache的級別是
Memory
val hdfs_file = "hdfs://path1/etl_date="
val rdd_20210113_test = spark.sparkContext.textFile(hdfs_file + "20210113").cache()
// 檔案大小為1.5G
rdd_20210113_test.getNumPartitions
// res2: Int = 13
val rdd_20210113_test_par1 = rdd_20210113_test.repartition(5)
rdd_20210113_test_par1.partitions.size
// res9: Int = 5
val rdd_20210113_test_par2 = rdd_20210113_test_par1.coalesce(13)
rdd_20210113_test_par2.partitions.length
// res14: Int = 5 增加分割槽沒生效
val rdd_20210113_test_par3 = rdd_20210113_test_par1.coalesce(3)
rdd_20210113_test_par3.partitions.length
// res16: Int = 3 增加分割槽生效
DataFrame
預設cache的級別是Memory and Disk
val hdfs_file = "hdfs://path1/etl_date="
val df_20210420 = spark.sparkContext.textFile(hdfs_file + "20210113").toDF().cache()
df_20210420.rdd.getNumPartitions
// res18: Int = 13
val df_20210420_par1 = df_20210420.repartition(20)
df_20210420_par1.rdd.getNumPartitions
// res19: Int = 20 增加分割槽生效
val df_20210420_par2 = df_20210420_par1.coalesce(5)
df_20210420_par2.rdd.getNumPartitions
// res20: Int = 5
cache&persist對比
- cache呼叫的是無引數版本的persist()
- persist的說明
import org.apache.spark.storage.StorageLevel._
// MEMORY_AND_DISK
val hdfs_file = "hdfs://path1/etl_date="
var etl_date = "20210113"
var hdfs_file_ = s"$hdfs_file" + etl_date
val rdd_20210113_DISK_MEMORY = spark.sparkContext.textFile(hdfs_file_).persist(MEMORY_AND_DISK)
println("DISK_ONLY資料量為" + rdd_20210113_DISK_MEMORY.count())
// MEMORY_ONLY
etl_date = "20210112"
hdfs_file_ = s"$hdfs_file" + etl_date
val rdd_20210113_MEMORY_ONLY = spark.sparkContext.textFile(hdfs_file_).persist(MEMORY_ONLY)
println("MEMORY_ONLY資料量為" + rdd_20210113_MEMORY_ONLY.count())
// DISK_ONLY
etl_date = "20210328"
hdfs_file_ = s"$hdfs_file" + etl_date
val rdd_20210113_DISK_ONLY = spark.sparkContext.textFile(hdfs_file_).persist(DISK_ONLY)
println("DISK_ONLY資料量為" + rdd_20210113_DISK_ONLY.count())
// DISK_ONLY資料量為4298617
// MEMORY_ONLY資料量為86340
// DISK_ONLY資料量為20000

效能優化
引數說明

引數配置建議
-
優化方面說明

-
tips
- yarn叢集中一般有資源申請上限,如,executor-memory*num-executors < 400G 等,所以除錯引數時要注意這一點
- 如果GC時間較長,可以適當增加--executor-memory的值或者減少--executor-cores的值
- yarn下每個executor需要的memory = spark-executor-memory + spark.yarn.executor.memoryOverhead.
- 一般需要為,後臺程式留下足夠的cores(一般每個節點留一個core)。
- Yarn ApplicationMaster (AM):ApplicationMaster負責從ResourceManager申請資源並且和NodeManagers一起執行和監控containers和它們的資源消耗。如果我們是spark on yarn模式,那麼我們需要為ApplicationMaster預留一些資源(1G和1個Executor)
- num-executors大(30),executor-cores小(1)→ 每個executor只分配了一個核,將無法執行多個任務的優點
- num-executors小(5),executor-cores大(7)→ 每個executor分配了7個核,HDFS吞吐量會受到影響。同時過大的記憶體分配也會導致過多的GC延遲
- Spark shell required memory = (Driver Memory + 384 MB) + (Number of executors * (Executor memory + 384 MB))
設定資源的示例
- 資源分配情況【非動態分配資源模式下】
- contain、CPUVcores、AllocaMemory為hdfs下對具體的application的資源佔用情況
- executors、storage-memory為spark web-ui下的executor情況

- spark-shell下資源佔用情況
- 主要檢視指定num-executor以及total-executor-cores情況下,資源佔用是否仍然會動態變化
- 還是會動態變化

- spark-submit下資源佔用情況
- 主要檢視指定num-executor以及total-executor-cores情況下,資源佔用是否仍然會動態變化
- 還是會動態變化
- CPUVcores是因為其預設是*4

- 設定資源的方式(以我們的叢集為例,5臺8核32G的伺服器)
- 第一,給每個Executor分配3個core即executor-cores=3,一般設定5對HDFS的吞吐量會比較友好。
- 第二,為後臺程式留一個core,則每個節點可用的core數是8 - 1 = 7。所以叢集總的可用core數是7 x 5 = 35。
- 第三,每個節點上的Executor數就是 7 / 3 = 2,叢集總的可用的Executor數就是 2 * 5 = 10。為ApplicationManager留一個Executor,則num-executors=9。
- 第四,每個節點上每個Executor可分配的記憶體是 (32GB-1GB) / 2 = 15GB(減去的1GB是留給後臺程式用),除去MemoryOverHead=max(384MB, 7% * 15GB)=2GB,所以executor-memory=15GB - 2GB = 12GB。
- 所以最後的引數配置是:num-executors=9、executor-cores=3、executor-memory=12G
- 設定資源的方式(調整下,比如要降低GC,executor-memory不需要給那麼多)
- 按照上述方式,得到每個Executor分配到的記憶體是12GB,但假設8GB記憶體就夠用了
- 那麼此時我們可以將executor-cores降低為2,那麼每個節點就可以有7 / 2 = 3個Executor,那麼總共可以獲得的Executor數就是 (5 * 3) - 1 =14,每個節點上每個Executor可分配的記憶體是(32GB-1GB) / 3 = 10GB,除去MemoryOverHead=max(384MB, 7% * 10GB)=1GB,所以executor-memory=10GB - 1GB = 9GB
- 所以最後的引數配置是:num-executors=14、executor-cores=2、executor-memory=9G
檢視Memory實際分配情況
// 計算driver Memory的
// spark 分配的實際資源情況
def getSparkMemory():Float={
val driver_memory_set1 = sc.getConf.getSizeAsBytes("spark.driver.memory")/1024/1024/1024
val systemMemory = Runtime.getRuntime.maxMemory.toFloat///1024/1024/1024
// fixed amount of memory for non-storage, non-execution purposes
val reservedMemory = 300 * 1024 * 1024
// minimum system memory required
val minSystemMemory = (reservedMemory * 1.5).ceil.toLong
val usableMemory = systemMemory - reservedMemory
val memoryFraction = sc.getConf.getDouble("spark.memory.fraction", 0.6)
val maxMemory = (usableMemory * memoryFraction).toLong
import org.apache.spark.network.util.JavaUtils
val allocateMemory = JavaUtils.byteStringAsMb(maxMemory + "b")
println(f"driver_memory: $driver_memory_set1%1.1f, allocateMemory: $allocateMemory%1.1f,")
maxMemory
}
val maxMemory = getSparkMemory()
// driver_memory: 2.0, allocateMemory: 912.0,
// // 檢視 spark web ui資源情況
def formatBytes(bytes: Double) = {
val k = 1000
val i = math.floor(math.log(bytes) / math.log(k))
val maxMemoryWebUI = bytes / math.pow(k, i)
f"$maxMemoryWebUI%1.1f"
}
println(formatBytes(maxMemory))
// 956.6
def allocateMemory(executorMemory:Float=1, executors:Float=1, driverMemory:Float=1):Double={
val driver_overmemory = Array(384, driverMemory * 0.07).max
val executor_Memory = Array(384, executorMemory * 0.07).max
val allocateMemory = (driver_overmemory + driverMemory) + executors * (executor_Memory + executorMemory)
allocateMemory/1024
}
allocateMemory(1 * 1024, 16, 1 * 1024)
// res3: Double = 23.375
檢視服務環境
- 通過8088埠proxy檢視任務資訊
http://ip:8088/proxy/application_jobid/executors/ - 通過8088埠cluster檢視任務資訊
http://ip:8088/cluster/apps